Transformer的辅助
Transformer的辅助
转载:https://zhuanlan.zhihu.com/p/149634836
为什么Transformer需要进行Multi-head Attention
Attention is all you need论文中讲模型分为多个头,形成多个子空间,每个头关注不同方面的信息。
如果Multi-Head作用是关注句子的不同方面,那么不同的head就应该关注不同的Token;当然也有可能是关注的pattern相同,但是关注的内容不同,即V不同。
但是大量的paper表明,transformer或Bert的特定层有独特的功能,底层更偏向于关注语法;顶层更偏向于关注语义。
所以对Multi-head而言,同一层Transformer_block关注的方面应该整体是一致的。不同的head关注点也是一样。但是可视化同一层的head后,发现总有那么一两个头独一无二的,和其他头的关注不一样。
众多研究表明Multi-Head其实不是必须的,去掉一些头效果依然有不错的效果(而且效果下降可能是因为参数量下降),这是因为在头足够的情况下,这些头已经能够有关注位置信息、关注语法信息、关注罕见词的能力了,再多一些头,无非是一种enhance或noise而已。
相关paper
- A Multiscale Visualization of Attention in the Transformer Model https://arxiv.org/pdf/1906.05714.pdf
- What Does BERT Look At? An Analysis of BERT’s Attention https://arxiv.org/pdf/1906.04341v1.pdf
- Improving Deep Transformer with Depth-Scaled Initialization and Merged Attention https://arxiv.org/pdf/1908.11365.pdf
- Adaptively Sparse Transformershttps://arxiv.org/pdf/1909.00015.pdf
- Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned https://arxiv.org/pdf/1905.0941
Transformer为什么Q和K使用不同的权重矩阵生成,为什么不能使用同一个值进行自身的点乘?(注意和第一个问题的区别)
既然K和Q差不多(唯一区别是W_k和W_Q权值不同),直接拿K自己点乘就行了,何必再创建一个Q?创建了还要花内存去保存,浪费资源,还得更新参数。
为什么要计算Q和K的点乘?
我们知道K和Q的点乘是为了得到一个attention score 矩阵,用来对V进行提纯。K和Q使用了不同的W_k, W_Q来计算,可以理解为是在不同空间上的投影。正因为有了这种不同空间的投影,增加了表达能力,这样计算得到的attention score矩阵的泛化能力更高。这里解释下我理解的泛化能力,因为K和Q使用了不同的W_k, W_Q来计算,得到的也是两个完全不同的矩阵,所以表达能力更强。
但是如果不用Q,直接拿K和K点乘的话,你会发现attention score 矩阵是一个对称矩阵。因为是同样一个矩阵,都投影到了同样一个空间,所以泛化能力很差。这样的矩阵导致对V进行提纯的时候,效果也不会好。
为什么在进行softmax之前需要对注意进行scaled(为什么除以dk的平方根),并使用公式推导进行讲解
(论文中解释是:向量的点积结果会很大,将softmax函数push到梯度很小的区域,scaled会缓解这种现象。怎么理解将sotfmax函数push到梯度很小区域?还有为什么scaled是维度的根号,不是其他的数?)
以数组为例,2个长度是len,均值是0,方差是1的数组点积会生成长度是len,均值是0,方差是len的数组。而方差变大会导致softmax的输入推向正无穷或负无穷,这时的梯度会无限趋近于0,不利于训练的收敛。因此除以len的开方,可以是数组的方差重新回归到1,有利于训练的收敛。
@LinT成功人士() 以下感谢分享
1. 为什么比较大的输入会使得softmax的梯度变得很小?
对于一个输入向量$x\in R^d$, softmax函数将其映射/归一化到一个分布$\hat y\in R^d$。在这个过程中softmax先用一个自然底数$e$ 将输入中的元素检举先“拉大”,然后归一化为一个分布。假设某个输入x 中最大的元素下班是k,如果输入的数量级变大(每个元素都很大),那么$\hat y_k$会非常接近1。
举个例子$x$ 的数量级对输入最大元素对应的预测概率$\hat y_k$的影响。假定输入 $x = [a,a,2a]^T$, 我们看看不同量级的$a$ 产生的$\hat y_3$有什么区别。
时,
;
时,
;
时,
(计算机精度限制)。
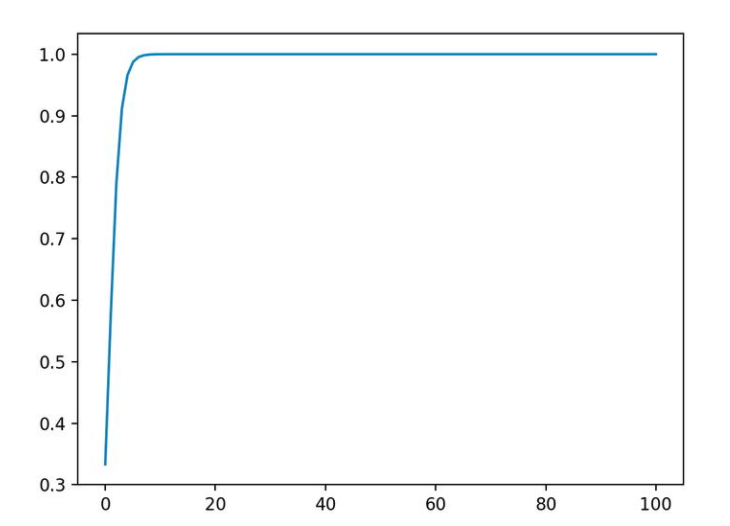
可以看出,第三个元素里的值随着数量级的增加而接近于1。而我们知道softmax层后的每个元素之后为1。也就是说,向量里最大值索引的元素基本上占据所有的概率了。为了理解方便,可视化如下。可以看出,随着向量里最大元素的数量级的增大,它就越近于1,相当于整个输出变成了one-hot编码了y = [0,0,1]
1 | import numpy as np |

2. 维度与点积大小的关系是怎么样的,为什么使用维度的根号来放缩?


在计算注意力分数的时候如何对padding做mask操作?
mask是将一些不要用的值掩盖掉,使其不产生作用。有两种mask,第一种是padding mask,在所有scaled dot-product attention都用到;第二种是sequence mask,在decoder的self-attention里面用到。
padding mask:因为一个批量输入中,所有序列的长度使不同的。为了符合模型的输入方式,会用padding的方式来填充(比如填0),使所有序列的长度一致。但填充部分是没有意义的,所以在计算注意力的时候,不需要也不应该有注意力分配到这些填充的值上面。所以解决方式就是在填充的位置赋予一个很小的负值/负无穷(-np.inf)的值,经过softmax后的得分为0,即没有注意力分配到这个上面。
1 | def padding_mask(seq_k, seq_q): |
以上方法为大部分padding mask的计算形式,但实际上,这里做了seq_q全部有效的假设(没有padding),并不够精确 。自己的看法:上述代码expand操作,只是将seq_k中padding的部分重复了L_q次,并没有注意到,seq_q也有padding的部分。即在一个(L_q,L_k)矩阵中,只有最后几列需要掩码,实际矩阵的最后几行也需要掩码。(以后上图更形象)
sequence mask:在decoder部分,因为不能见到下文信息(防止泄漏),所以用mask的方式掩盖掉当前时刻t及之后的下文信息。具体,可产生一个对角线为0的上三角矩阵,将其作用到每个decoder的输入列上。代码如下:
1 | def sequence_mask(seq): |
decoder-block有两个multi-head attention,下面的multi-head attention是目标输入的self-attention,需要用到1.padding mask:去除padding位置的影响;2.sequence mask:去掉下文穿越的影响。上面的multi-head attention只需要padding mask,因为下面的多头注意力已经磨平了下文信息。当encoder和decoder的输入序列长度一样时,可以通过padding mask+sequence mask作为scaled dot-product attention的attn_mask来实现。
其他情况的attn_mask(代码中的表达)等于padding mask
为什么在进行多头关注的时候需要对每个head进行切割?
@何妨吟啸且徐行 感谢回答
Transformer的多头注意力看上去是借鉴了CNN中同一卷积层内使用多个卷积核的思想,原文中使用了 8 个“scaled dot-product attention”,在同一“multi-head attention”层中,输入均为“KQV”,同时进行注意力的计算,彼此之前参数不共享,最终将结果拼接起来,这样可以允许模型在不同的表示子空间里学习到相关的信息,在此之前的 A Structured Self-attentive Sentence Embedding 也有着类似的思想。简而言之,就是希望每个注意力头,只关注最终输出序列中一个子空间,互相独立。其核心思想在于,抽取到更加丰富的特征信息。
回到题主的问题上来,如果只使用 one head 并且维度为 ,相较于 8 head 并且维度为
。首先存在计算量极大的问题,并且高维空间下的学习难度也会相应提升,这就难免文中实验出现的参数量大且效果不佳的情况,于是将原有的高维空间转化为多个低维空间并再最后进行拼接,形成同样维度的输出,借此丰富特性信息,降低了计算量,而且取得了更好的效果,十分巧妙。
为何在获取输入词向量之后需要对矩阵乘以embeddding size的开方?意义是什么?
embedding matrix的初始化方式是xavier init,这种方式的方差是1/embedding size,因此乘以embedding size的开方使得embedding matrix的方差是1,在这个scale下可能更有利于embedding matrix的收敛。
你还了解些关于位置编码的技术,各自的优缺点是什么?
https://zhuanlan.zhihu.com/p/105001610
Transformer 为什么使用 layer normalization,而不是其他的归一化方法?
https://www.zhihu.com/question/395811291/answer/1251829041
Transformer如何并行化的?解码器端可以做并行化吗?
Transformer的并行化主要体现在self-attention模块,在Encoder端Transformer可以并行处理整个序列,并得到整个输入序列经过Encoder端的输出,在self-attention模块,对于某个序列,self-attention模块可以直接计算
的点乘结果,而RNN系列的模型就必须按照顺序从
计算到
。
简单描述一下wordpiece model和字节对编码?
https://zhuanlan.zhihu.com/p/86965595
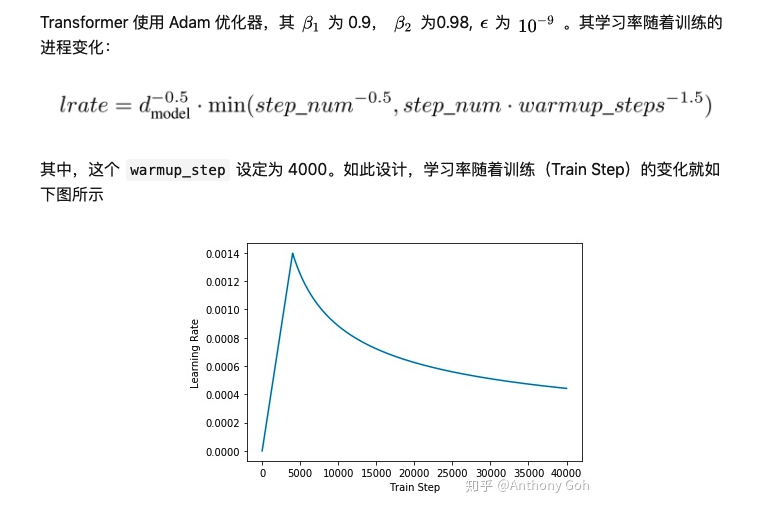
Transformer训练的时候学习率是如何设定的?
Transformer中multi-head机制是如何实现每个head提取的信息空间互斥的?
Transformer的多头注意力看上去是借鉴了CNN中同一卷积层内使用多个卷积核的思想,原文中使用了 8 个“scaled dot-product attention”,在同一“multi-head attention”层中,输入均为“KQV”,同时进行注意力的计算,彼此之前参数不共享,最终将结果拼接起来,这样可以允许模型在不同的表示子空间里学习到相关的信息。简而言之,就是希望每个注意力头,只关注最终输出序列中一个子空间,互相独立。其核心思想在于,抽取到更加丰富的特征信息。
Transformer的细节到底是怎么样的?
https://www.zhihu.com/question/362131975/answer/945357471
为什么Bert的三个Embedding可以进行相加?
(Token Embedding、Segment Embedding、Position Embedding三个向量为什么可以相加呢?相加后向量的大小和方向就变了,语义不就变了吗?) 深度神经网络里变得非常复杂,本质上神经网络中每个神经元收到的信号也是“权重”相加得来。这三个向量为什么可以相加呢?因为三个embedding相加等价于三个原始one-hot的拼接再经过一个全连接网络。 相加后向量的大小和方向就变了,语义不就变了吗?这里不是语义变了,而是在训练的时候就是这几个向量相加进行训练的,训练完之后,将lookup后的向量进行相加,就能得到比较好的表示了。 从梯度的角度解释:
为什么BERT输入的最大长度要限制为512?
个人推断是考虑了计算与运行效率综合做出的限制。
BERT输入的最大长度限制为512, 其中还需要包括[CLS]和[SEP]. 那么实际可用的长度仅为510.但是别忘了,每个单词tokenizer之后也有可能被分成好几部分. 所以实际可输入的句子长度远不足510.
BERT由于position-embedding的限制只能处理最长512个词的句子。如果文本长度超过512,有以下几种方式进行处理:
a)直接截断:从长文本中截取一部分,具体截取哪些片段需要观察数据,如新闻数据一般第一段比较重要就可以截取前边部分;
b)抽取重要片段:抽取长文本的关键句子作为摘要,然后进入BERT;
c)分段:把长文本分成几段,每段经过BERT之后再进行拼接或求平均或者接入其他网络如lstm。
另外transformer-xl 、LongFormer:用稀疏自注意力拓展模型文本容纳量等优秀设计也可以解决长文本。
为什么BERT选择mask掉15%这个比例的词,可以是其他的比例吗?
来自@海晨威的算法屋
BERT采用的Masked LM,会选取语料中所有词的15%进行随机mask,论文中表示是受到完形填空任务的启发,但其实与CBOW也有异曲同工之妙。
从CBOW的角度,这里 有一个比较好的解释是:在一个大小为
的窗口中随机选一个词,类似CBOW中滑动窗口的中心词,区别是这里的滑动窗口是非重叠的。
那从CBOW的滑动窗口角度,10%~20%都是还ok的比例。
上述非官方解释,是来自我的一位朋友提供的一个理解切入的角度,供参考。
来自@Serendipity
15%的概率是通过实验得到的最好的概率,xlnet也是在这个概率附近,说明在这个概率下,既能有充分的mask样本可以学习,又不至于让segment的信息损失太多,以至于影响mask样本上下文信息的表达。然而因为在下游任务中不会出现token“
为什么BERT在第一句前会加一个[CLS]标志?
bert在token序列之前加了一个特定的token“[cls]”,这个token对应的向量后续会用在分类任务上;如果是句子对的任务,那么两个句子间使用特定的token“[seq]”来分割。
为什么选它呢,因为与文本中已有的其它词相比,这个无明显语义信息的符号会更“公平”地融合文本中各个词的语义信息,从而更好的表示整句话的语义。
这里补充一下bert的输出,有两种:
一种是get_pooled_out(),就是上述[CLS]的表示,输出shape是[batch size,hidden size]。
一种是get_sequence_out(),获取的是整个句子每一个token的向量表示,输出shape是[batch_size, seq_length, hidden_size],这里也包括[CLS],因此在做token级别的任务时要注意它。
Bert和Transformer在loss上的差异
transformer的loss是在decoder阶段计算的。bert预训练的loss由2部分构成,一部分是NSP的loss,就是token“[cls]”经过1层Dense,然后接一个二分类的loss,其中0表示segment B是segment A的下一句,1表示segment A和segment B来自2篇不同的文本;另一部分是MLM的loss,segment中每个token都有15%的概率被mask,而被mask的token有80%的概率用“
bert在encoder之后,在计算NSP和MLM的loss之前,分别对NSP和MLM的输入加了一个Dense操作,这部分参数只对预训练有用,对fine-tune没用。而transformer在decoder之后就直接计算loss了,中间没有Dense操作。
为什么bert需要额外的segment embedding?
因为bert预训练的其中一个任务是判断segment A和segment B之间的关系,这就需要embedding中能包含当前token属于哪个segment的信息,然而无论是token embedding,还是position embedding都无法表示出这种信息,因此额外创建一个segment embedding matrix用来表示当前token属于哪个segment的信息,segment vocab size就是2,其中index=0表示token属于segment A,index=1表示token属于segment B。
为什么transformer的embedding后面接了一个dropout,而bert是先接了一个layer normalization,再接dropout?
LN是为了解决梯度消失的问题,dropout是为了解决过拟合的问题。在embedding后面加LN有利于embedding matrix的收敛。
BERT模型有什么调参技巧?
https://www.zhihu.com/question/373856698/answer/1034691809
Transformer中warm-up和LayerNorm的重要性?
https://zhuanlan.zhihu.com/p/84614490
Bert的mask为何不学习transformer在attention处进行屏蔽score的技巧?
 wechat
wechat alipay
alipay





