LongFormer:The Long-Document Transformer
LongFormer:The Long-Document Transformer
主要记录一些Longfromer的原理和使用时的细节。
摘要
针对的问题:
- 基于Transformer的模型,由于self-attention的操作,导致不能处理很长的序列。
- self-attention的处理规模和序列长度是成二次关系的。
因为self-attention对于每个token都要计算打分,也就是缩放点积中的$QK^T$ 矩阵运算。
这相当于对每个token之间都照顾到了注意信息。
每个token代表一个小格,自注意力机制的QK都是自己,所以是个正方形。
为解决这个问题,作者引入了三种具有随序列长度线性缩放的注意机制,将规模缩减成线性。
分别是局部窗口注意和任务激活的全局注意力。
并且还提供了LongFormer的预训练模型。
定义了生成结构为Long-Forward-Encoding-Decoder(LED)
引入&相关工作
熟知的Bert等预训练模型,最大长度为512,多的就要截断,这样可能会潜在地导致重要的跨分区信息丢失问题。
然而当时已有的针对解决长文本的方法,都是基于自回归语言模型的。
而LongFormer是可以应用于迁移学习环境中的文档级NLP任务的。
之后可能会读几篇。ltr从左到右的模型,其受益于双向语境(自回归或从左到右的语言建模被粗略地定义为在给定输入序列中的先前符号/字符的情况下估计现有符号/字符的概率分布)。
spare代表模型通过稀疏性来进行优化。
Generating long se-quences with sparse transformers.其使用由BlockSparse提供的大小为8x8的块的扩展滑动窗口的形式,但没有探索预训练设置。等等
LongFormer
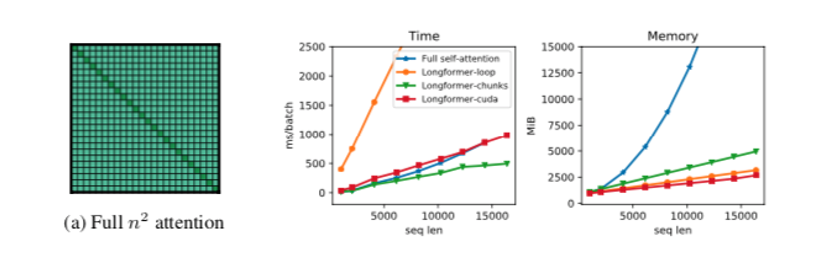
原始Transformer的自注意力机制有$O(n^2)$ 的时间和空间内存复杂度。
为了解决这个问题,作者根据指定相互关注的输入位置对的“注意模式”来稀疏完整的自我注意矩阵
与full self-attention不同的是,提出的注意力模式与输入序列成线性关系,这使得它对较长的序列是有效的。
注意力模式
滑动窗口 (Sliding Window)
设固定窗口大小为 w,transformer层数为$l$, token的每边 $\frac{1}{2}w$ 计算复杂度为$O(n\times w)$
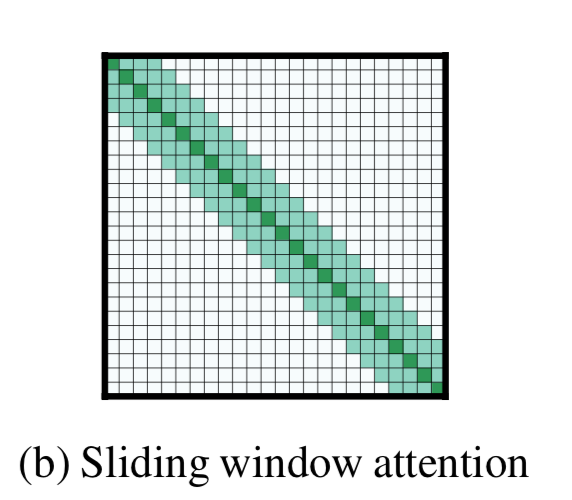
作者认为:根据应用程序的不同,为每个图层使用不同的w值可能有助于在效率和模型表达能力之间取得平衡。
空洞滑窗(Dilated Sliding Window)
类似于CNN的空洞卷积
空洞尺寸 $d$ 感受野是 $l\times d\times w$
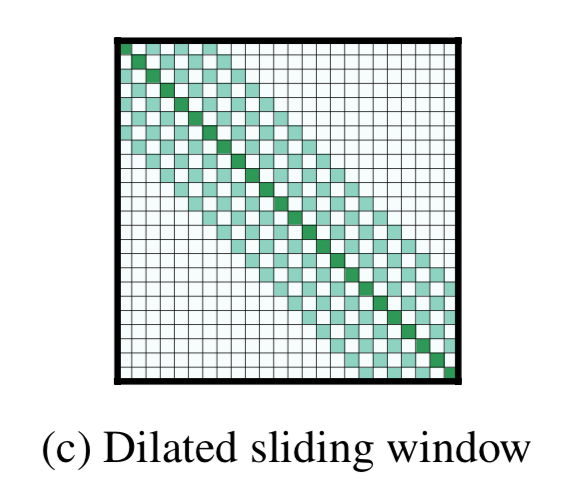
在多头注意力中,每个注意力头部计算不同的注意力分数。
作者发现,每个头具有不同扩张配置设置的话效果会好:
允许一些没有空洞的头部专注于局部语境,而另一些带空洞的则专注于更长的语境,从而提高了性能。
全局注意力(Global Attention)
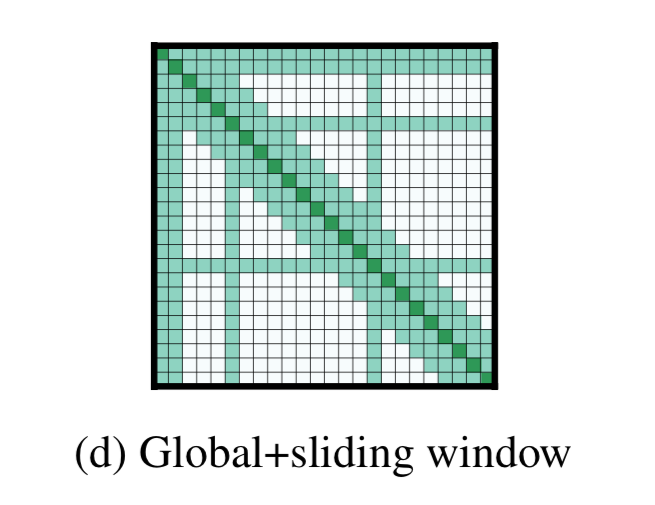
例如对于QA,问题和文档连接在一起,允许模型通过自我关注将问题与文档进行比较。
有时需要使用特殊的全局CLS作为整体的表达,所以就需要再这某些个关键点地方计算全局注意力,关注每一个token。其他的还是滑窗的形式。
我们在几个预先选择的输入位置添加了“全局关注”。
由于这样的记号token的数量相对于n很小,并且与n无关,因此组合的局部和全局注意的复杂度仍然是O(N)。
这时,计算打分函数就可以分为两组QKV,分别是全局的$Q_g,K_g,V_g$ 和 滑窗局部的 $Q_s,K_s,V_s$
昂贵的运算是矩阵乘法 $QK^T$,因为Q和K都具有n(序列长度)投影。对于LongFormer,空洞滑动窗口注意只计算固定数量$QK^T$的对角线。
在实现的时候主要用到了带状乘法。还定制了特别的CUDA内核。。
对于自回归的语言模型
可以使用空洞滑动窗口注意力,并且可以跨层使用不同尺寸的窗口,效果可能更佳。
对较低层使用较小的窗口大小,并在移动到较高层时增加窗口大小
这允许顶层了解整个序列的较高级别表示,同时使较低层捕获本地信息。此外,它还在效率和性能之间取得平衡。
(窗口大小越小,非零值越少,计算开销越小)
(窗口大小越大,表示能力更丰富,通常会带来性能提升)
实验
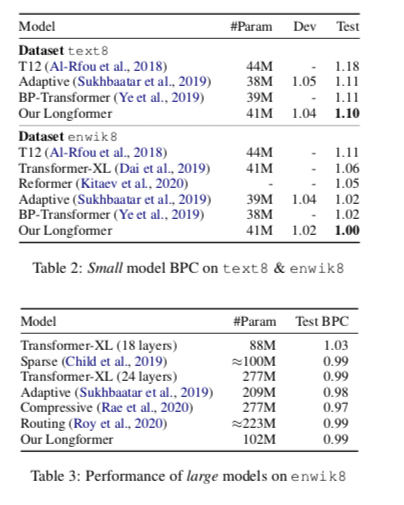
和训练长文本的模型进行对比 ,BPC值越小越好
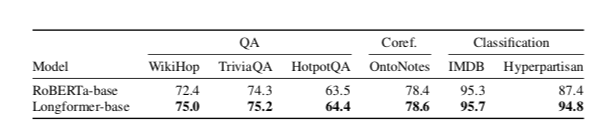
在QA上的Finetuning
分别采用了我比较关注的多文档数据集 WikiHop/HotpotQA(干扰榜)/TriviaQA
将问题和文档连接成一个长序列放入Longformer,最后加一个预测层。
WikiHop
数据特点:
候选答案个数由2个到79个不等。
文章段落数量由3段到63段不等
数据集不为多跳推理链提供任何中间注释,需要模型代之以从间接答案监督中推断它们。
数据预处理:
将问题和答案与特殊令牌连接在一起
$ [q] question [/q] [ent] candidate1 [/ent] … [ent] candidateN [/ent] $
上下文也是使用文档分隔符进行间隔
$</s> context1 </s> … </s> contextM </s>$
在准备好输入数据后,从每个模型的顶层开始计算活动。获取问题和答案候选并将它们连接到尽可能多的上下文直到模型序列长度(Roberta为512,LongFormer为4,096),在模型中运行序列,收集输出激活,并重复,直到用尽所有上下文(除了LongFormor-Large之外的所有模型,由于存储器要求,我们只包括第一个4,096长度的序列)。然后,将所有块的所有激活连接成一个长序列。在Longformer的下,使用全局注意力来关注整个问答候选序列。
最终预测,对每个[ent] 附加一个线性层,输出一个logit,最后平均所有候选答案的logits。 用softmax和交叉熵得出最终答案。
优化策略:
Adam、Linear warmup超过200梯度更新对于最大LR,然后linear decay剩余训练。
使用梯度累积最终batch达到32
其他超参Dropout weight decay 都和Roberta相同。
对LR[2e-5,3e-5,5e-5]和epoch[5,10,15]进行网格搜索。
LR=3e-5,15个epoch是最好的Longform-Base配置。
TriviaQA
TriviaQA有超过10万个问题、答案、文档。
文档是维基百科文章,答案是文章中提到的命名实体。
回答问题的跨度没有注释,但可以使用简单的文本匹配找到它。
数据预处理:
$[s] question [/s]document [/s]$
在所有问题符号上都使用全局注意力。
HotpotQA
使用两阶段首先确定相关段落,然后确定最终答案范围和证据。
这主要是因为首先删除分散注意力的段落,可以降低最终认识和范围检测的噪声,这一点也被发现非常重要此数据集中最新的最新方法。
数据预处理:
$[CLS] [q] question [/q] ⟨t⟩ title1 ⟨/t⟩ sent1,1 [s] sent1,2 [s] …⟨t⟩ title2 ⟨/t⟩ sent2,1 [s] sent2,2 [s] …$
使用全局注意力来问句标记、段落计时开始标记以及句子标记。
在段落标题顶部增加了前馈层,用于预测相关段落的开始标记,以及用于预测证据句子的句子标记。
在对第一阶段模型进行训练后,预测了训练集和开发集的相关段落得分。然后,保留最多5个原始得分高于预先指定的阈值(-3.0)的段落,并从上下文中删除其他段落。然后,根据得到的缩短上下文训练第二阶段模型。
将跨度、问题分类、句子和段落损失结合起来,使用线性损失组合对模型进行多任务训练。
使用ADAM优化器对模型进行了训练,并进行了线性warmup(1000步)和线性衰减。我们使用最小超参数调整,使用3E-5和5E-5的LR和3到7的epoch,发现LR为3E-5和5个历元的模型效果最好。
 wechat
wechat alipay
alipay





