DUMA: Reading Comprehension with Transposition Thinking
DUMA: Reading Comprehension with Transposition Thinking
DUMA:DUal Multi-head Co-Attention model
这是一篇针对解决多项选择任务的MRC网络结构。题目中的Transposition Think,被作者赋义为分别从文章和问题的角度来考虑对方的关注点。
主要特点:
- 基于预训练语言模型(得到表示编码,替代复杂的匹配网络)
- 衔接多层co-attention(从三元组中捕捉关系)
多项选择任务可以抽象为(文章P,问题q,选项a) 三元组。
针对多项选择的特点多项选择MRC尤其依赖于匹配网络的设计,它被认为是有效地捕捉文章、问题和答案三元组之间的关系。(不能只考虑推理如何做的更好,还要考虑答案出现的关键位置也就是匹配网络的作用)
文中总结的人在做阅读理解题时的特点:
- 快速通读文章的整体内容,问题和回答选项,以建立全局印象,然后进行换角度思考过程。
- 根据问答选项的特有信息,重新考虑文章的细节,收集问答选项的支持证据。
- 根据文章中的特有信息,重新考虑问题和答案选项,以确定正确的选项,排除错误的选项。
当人们重读文章时,他们倾向于根据对问答选项的印象提取关键信息,重读问答选项时也是如此
DUMA
多项选择问题可以定义模型需要学习一个概率分布$F(A_1,A_2,…,A_t|P,Q)$
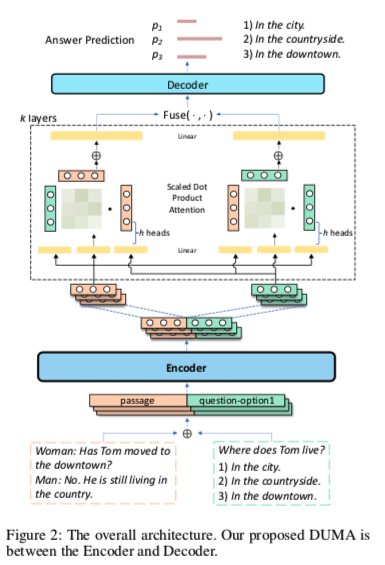
Encoder 接受文本输入生成一个全局序列表达,这个过程类似人类第一次阅读整个内容以获得总体印象。
Decoder则收集所有信息的答案预测以选择正确答案选项。
DUMA层位于encoder和decoder之间,意在模仿人类转换思考角度的过程,从问题文章和关键词中捕捉关系信息。
Encoder
作者用的是PrLMs,其将文章、问题和所有不同的候选答案拼接作为输入。
$P=[p_1,p_2,..,p_m]$ , $Q=[q_1,q_2,…,q_n]$ , $A=[a_1,a_2,…,a_k]$
这个输入到预训练的方式可能会遇到点问题,一般预训练语言模型比如bert都会限制一个输入的大小,如果文章过长的话,模型看不到问题和选项可能会导致训练效果不佳。可以改为 Q、A、P的形式,因为一般Q和A都比较短。
$E = [e1,e_2,…,e{m+n+k}]$
$ei$ 为固定维度$d{model}$ 的向量,是各自的token。
Dual Multi-head Co-Attention
使用双多头共同注意模型来计算文章和问答的attention表征。(可堆叠k层)
其实就是一个多头co-attention,定义一个Q、K、V (Q不是上面的问题Q)
先从E中分离出$E^P = [e^P1,e^P_2,…,E^P{tp}]$、$E^{QA} = [e^{qA},e^{qA},…,E^{qA}{t_{q_a}}]$
使用两种计算attention的方法:
$E^P$ 做Query ,$E^{QA}$ 做 Key和Value
$E^{QA}$ 做Query ,$E^{P}$ 做 Key和Value
其中$Wi^Q \in R^{d{model} \times dq}$ 、 $W_i^K \in R^{d{model} \times dk}$、 $W_i^V \in R^{d{model} \times dq}$ 、$W_i^O \in R^{hd_v \times d{model}}$ : h 头数
$MHA$: 多头注意力
$Fuse$ 函数先使用均值池化来汇集$MHA(·)$的序列输出,然后再聚合两个池化的输出。
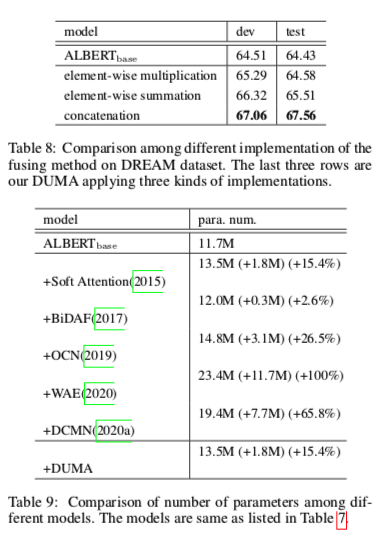
后文实验了三种聚合方法 元素乘法 元素相加 concat
表示在决定哪个是最佳答案选项之前,对所有关键信息进行混合。
Decoder
s 是选项数量
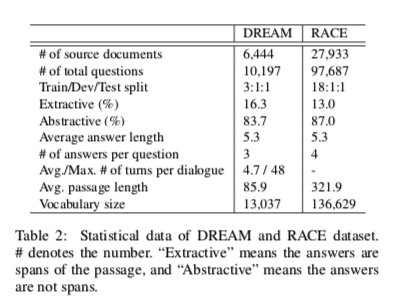
Multi-choice MRC数据集
DREAM and RACE
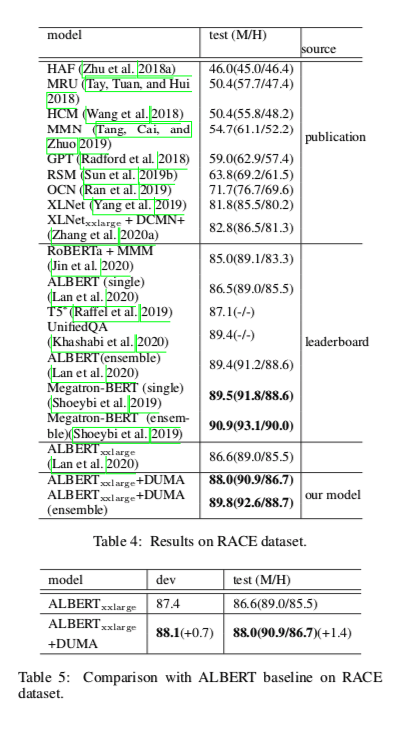
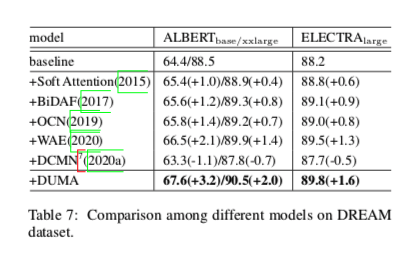
实验
 wechat
wechat alipay
alipay





