Avoiding Reasoning Shortcuts- Adversarial Evaluation, Training, and Model Development for Multi-Hop QA
Avoiding Reasoning Shortcuts- Adversarial Evaluation, Training, and Model Development for Multi-Hop QA
这篇文章作者发现在HotpotQA中经常包含Reasoning Shortcuts。也就是说模型没有真正的理解文章并进行推理,而是通过将问题与上下文中的句子进行词匹配来直接定位答案。
作者主要做了两件事:
- 构建干扰文档数据,证明了存在推理shortcut现象。
- 设计一个新模型来缓解这个问题
对抗验证

问题是What was the father of Kasper Schmeichel voted to be by the IFFHS in 1992? (卡斯珀·舒梅切尔的父亲1992年被IFFHS投票选为什么?)
模型需要从两个文档中考虑信息,找出隐含的推理链条。
Kasper Schmeichel $\rightarrow^{son}$ Peter Schemeichel $\rightarrow^{voted}$ World’s Best Goalkeeper
Kasper Schmeichel是Peter Schemeicher, Peter Schemeicher 被投票为 World’s Best Goalkeeper 世界最佳守门员。
在该示例中,也可以通过将问题中的几个关键字(“voted to be by the IFFHS in 1992——1992年投票的IFFHS”)与上下文中的相应事实相匹配来得到正确的回答,而无需通过第一跳推理来找到“Kasper Schmeichel的父亲”,因为两个distractor文档都不包含足够分散注意力的信息。
因此,一个在现有评估上表现良好的模型并不一定表明它具有很强的复合推理能力。
随着对抗扰动文本被添加到上下文中,使用单跳shotcut方式不再可能找到正确的答案,这现在导致了两个可能的答案(“世界最佳守门员”和“世界最佳防守人”)。
添加干扰后模型预测答案为 IFFHS World’s Best Defender 最佳防守人。
如何构建对抗数据
要构建这种对抗的需求
作者指出HotpotQA从维基百科中选择距离目标问题最短的bigram TF-IDF的前8个文档作为干扰项,形成总共10个文档的上下文。由于在生成问题时没有向群组工作人员提供导向文档,因此不能保证在给定整个上下文的情况下,两个支持文档都是必要的来推断答案。
多跳假设可以通过两种方式由不完整的分心文档来实现。
其中一个选定的干扰项可能包含推断答案所需的所有证据,从经验上讲,在HotpotQA中没有发现这样的情况,因为关于一个主题的Wiki文章很少讨论另一个主题的细节
整个分散注意力的文档池可能不包含真正分散读者/模型注意力的信息。
作者把绕过推理回答问题这种方式,叫做shortcut 。其经常出现在HotpotQA中的桥接问题中,比较问题一般不能匹配而得出。作者采样了50个桥接问题,发现其中26个有这种问题。
设原内容、问题答案为 $(C,q,a)$ 是可能包含shortcut问题的数据,作者是想将其变为$(C’,q,a)$
$q,a$ 不变,$C’$ 变成接近 $C$ 的文章。在HotpotQA中是提供两个支持文档$P$的, 其中$P\subset C$ 。
在构建对抗文本时也就是ADDDoc。就是利用新的 $P’$ ,混合$(C,P’)$ 构成新的数据集。
那么 $P’$ 如何来的?
假设 $p2\in P$ 是包含答案的支持文档,$p1\in P$ 是包含线索的文档。
ADDDoc是利用词或短语级别的干扰,将 $p2$ 替换成$p’2$ ,其包含满足推理快捷方式但不与整个问题的答案相矛盾的假答案。
那么词语是如何替换的?
首先,对于答案中的每个非停用词,都会在GloVe100维向量空间中找到最接近的10个替代词,它的子串与原始答案的重叠子串长度不超过3个。如(Mumbai → Delhi, Goalkeeper → Defender)。如果这个过程失败,就从HotpotQA dev集合的整个答案池中随机抽样一个候选者 。
如果原始答案有多个单词,我们将答案中的一个非停用词与相应的抽样答案单词替换,以创建假答案(“World’s Best Goalkeeper → World’s Best Defender”)。
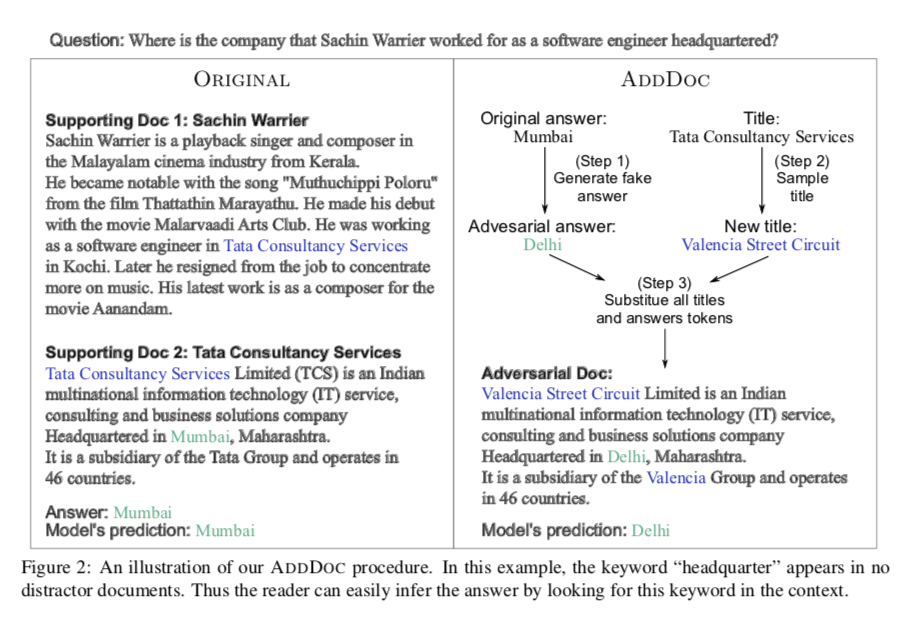
问:Sachin Wamer作为软件工程师所在的公司的总部在哪里?
由此产生的段落 $p’2$ 提供了一个满足推理捷径的答案,但也与整个问题的真实答案相矛盾,因为它形成了另一个有效的推理链,将问题与假答案连接起来 (Sachin Warrier $\rightarrow^{work}$ TCS $\rightarrow^{at}$ Delhi)。
为了打破这个矛盾的推理链,我们需要用另一个实体替换连接两个证据的桥梁实体(在这种情况下为“Tata Consultancy Services”),这样生成的答案就不再作为有效答案 。
用从 HotpotQA 开发集中所有文档标题中随机采样的候选者替换 $p’2$ 的标题。 如果 $p1$ 的标题出现在$p’2$ 中,我们也将其替换为另一个采样标题,以彻底消除 $p’2$ 和 $p1$ 之间的联系。
如上图将 Tata Consultancy Services 替换为 Valencia Street Circuit
模型方法
Encoding
对于cotnext 和question 使用v 维Highway Network 合并 字符嵌入和GloVe词嵌入。
得到 $x\in R^{J\times v}$ 和 $q\in R^{S\times v}$ 其中 J 是文章长度 S 为问题长度
整体结构和BiDAF那个文章相似。
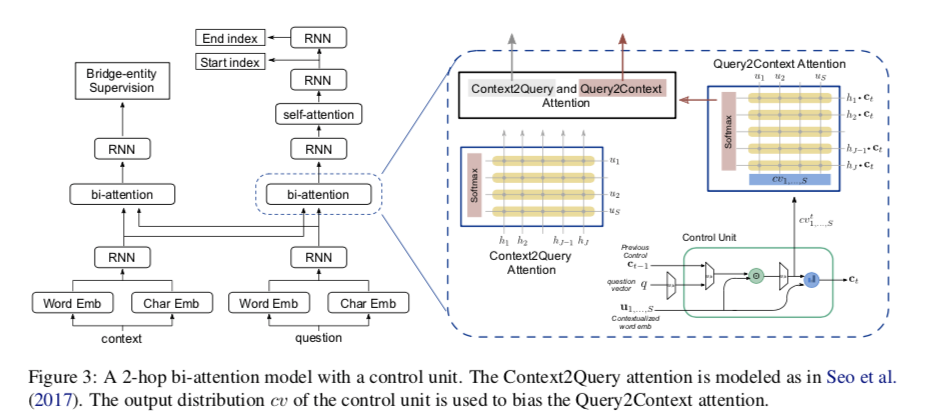
Single-Hop Baseline
使用bi-attention + self-attention ,给定上下文和问题encoding $h,u$ 经过 context-to-query $BiAttn(h,u)$ 计算得到一个相似矩阵 $M^{S\times J}$ :
$\odot$ 对应元素相乘。
然后query-to-context 注意力:
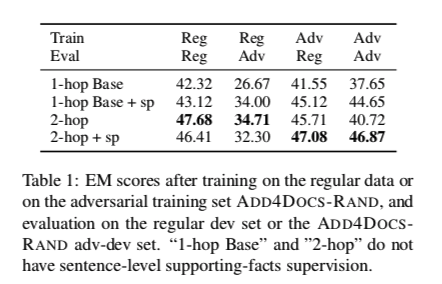
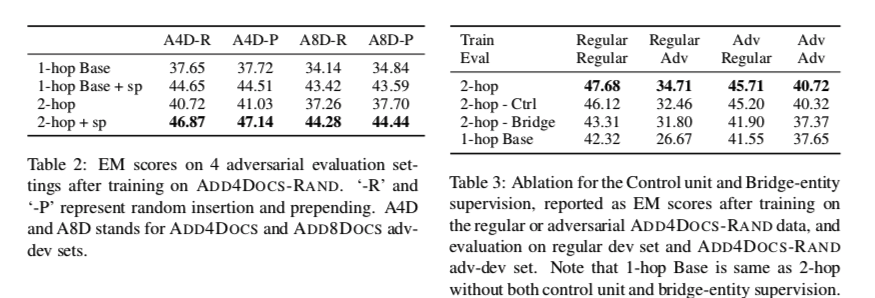
实验
 wechat
wechat alipay
alipay





