Heterogeneous Graph Transformer
Heterogeneous Graph Transformer
提出了一种用于Web规模异构图建模的异构图Transformer(HGT)体系结构。
其一是设计了节点和边类型相关的参数来表征对每条边的异构attention,使得HGT能够维护不同类型的节点和边的专用表示。
其二为了处理Web规模的图形数据,我们设计了异构小批量图形采样算法HG Samples,以实现高效和可扩展的训练
作者使用的是OAG学术图,其存在的异构关系如下图:
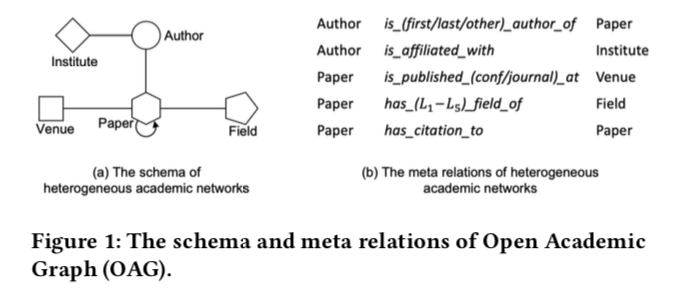
要解决的问题
GNN以前可以处理异质图是基于元路径的方法有PathSim, methpath2vec等。GNN火起来以后也出现了好多处理异质图的工作。
作者认为面临着几个问题:首先,它们大多涉及为每种类型的异构图设计元路径,需要特定的领域知识;其次,它们要么简单地假设不同类型的节点/边共享相同的特征和表示空间,要么只针对节点类型或边类型保持不同的非共享权重,使得它们不足以捕捉异构图的属性;最后,其固有的设计和实现使得它们无法对Web规模的异构图进行建模。
作者的目标是:保持节点和边类型的依赖表示,避免定制的元路径,并且能够扩展到Web规模的异构图。
做法:
异质处理
为了处理图的异构性,引入了节点和边型依赖的注意机制。HGT中的异构相互关注度不是参数化的,而是通过基于其元关系三元组分解每条边e=(s,t)来定义的,即
同时,不同类型的连接节点仍然可以交互、传递和汇聚消息,而不受其分布差距的限制。由于其体系结构的本质,HGT可以通过跨层的消息传递来融合来自不同类型的高阶邻居的信息,这可以被认为是“软”元路径。也就是说,即使HGT只将其一跳边作为输入,而不需要人工设计元路径,所提出的注意机制也可以自动和隐式地学习和提取对不同下游任务重要的“元路径”。
异质子图采样法
为了对Web规模的异构图进行建模,设计了第一个用于小批量GNN训练的异构子图采样算法HG Samples。它的主要思想是对不同类型节点比例相近的异构子图进行采样。此外,它还被设计成保持采样子图的稠密性,以最大限度地减少信息损失。有了HG-sample,所有的GNN模型都可以在任意大小的异构图上进行训练和推断。
方法
思想:利用异构图的元关系来参数化异构相互关注、消息传递和传播步骤的权重矩阵。
有向图 $G = (V,E,A,R)$ , 节点 $v \in V$,每个边$e \in E$ 。他们的类型映射函数为 $\tau(v):V \to A$ 、$\phi(e):E\to R$
元关系
对于一个边 $e = (s,t)$ ,元关系定义为 $<\tau(s),\phi(e),\tau(t)>$ 。$\phi(e)^{-1}$ 是关系的反向表达。
HGT架构
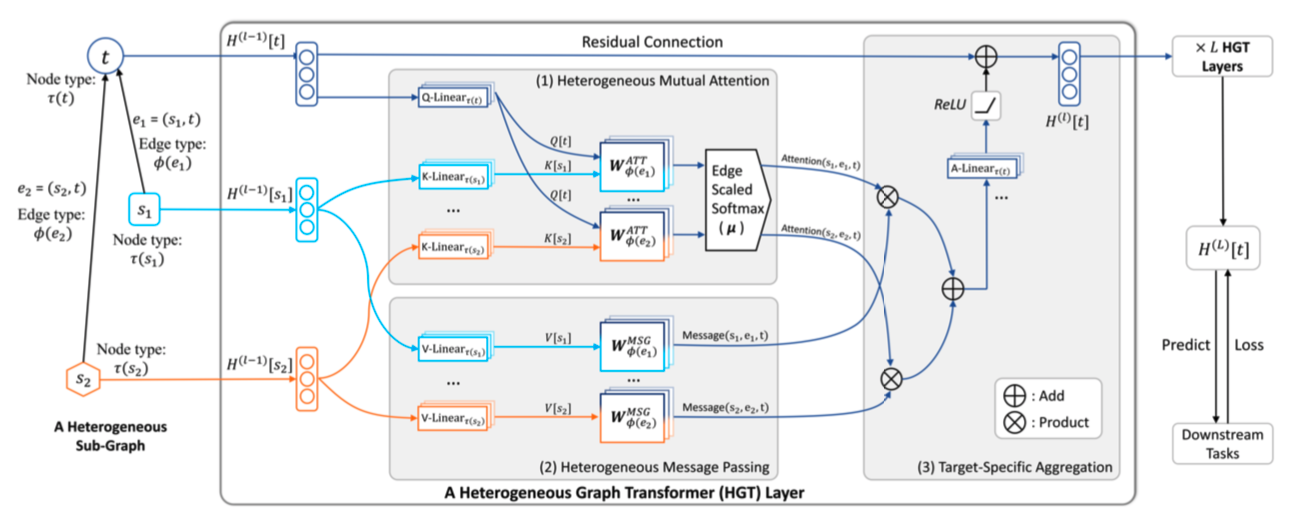
主要的三个组件:Heterogeneous Mutual Attention、Heterogeneous Message Passin和特定于Target-Specific Aggregation。
定义第$l$ 层的输出为 $H^l$, 也是第$l+1$层的输入。
Heterogeneous Mutual Attention
首先计算源节点 s 到目标节点 t 之间的 Mutual Attention。
针对问题是:通过使用一个权重矩阵W来假设s和t具有相同的特征分布。这种假设对于异构图通常是不正确的,因为在异构图中,每种类型的节点都可以有自己的特征分布。
给出目标节点 t ,以及它的邻居节点 $s \in N(t)$ 它们可能属于不同的分布。通过元关系三元组 $<\tau(s),\phi(e),\tau(t)>$, 计算mutual attention。
将目标节点t映射为query向量,将源节点s映射为key向量,并计算它们的点积作为关注度。
与Vanilla Transformer相比关键区别在于,Vanilla Transformer对所有单词使用一组投影映射,HGT的每个元关系都应该有一组不同的投影权重。
为了在保持不同关系特性的同时最大限度地实现参数共享,提出将交互算子的权重矩阵参数化为源节点投影、边投影和目标节点投影。
对每个边$e=(s,t)$进行h heads attention :
$\text{ATT-head^i(s,e,t)}$ 是第 $i$ 个注意力头。$\text{K-Linear}^i_{\tau{(s)}}:R^d \to R^{\frac{d}{h}}$ 编码了源接地那s类型$\tau(s)$ 意味着每每个类型节点有独一无二的线性映射最大限度地对分布差异进行建模。
然后计算Query和Key的相似度, 异构图的一个独特特征是在节点类型对之间可能存在不同的边类型(关系),例如 $τ(S)$和$τ(T)$ 。因此,与直接计算查询和键向量之间的点积的Vanilla Transformer不同,我们为每个边类型$\phi(e)$保留了一个不同的基于边的矩阵 $W^{ATT}_{\phi(e)}\in R^{\frac{d}{h}\times \frac{d}{h}}$ 。这样,即使在相同的节点类型对之间,该模型也可以捕获不同的语义关系。
此外,由于不是所有的关系对目标节点的贡献相等,我们增加了一个先验张量 $\mu\in R^{|A|\times |R|\times |A|}$ 表示每个元关系三元组的一般意义,作为对注意力的自适应缩放。
最后,我们将注意力集中在一起,以获得每个节点对的attention向量。
Heterogeneous Message Passing
在计算Mutual Attention的同时,将信息从源节点传递到目标节点。
与attention过程类似,希望在消息传递过程中加入边的元关系,以缓解不同类型节点和边的分布差异。
对于一对节点 $e=(s,t)$,我们通过以下公式计算其多头 Message:
Target-Specific Aggregation
这将来自不同特征分布的所有近邻(源节点)的信息聚集到目标节点 t。
最后一步是将目标节点t的向量映射回按其节点类型τ(T)索引的特定于类型的分布。为此,我们将线性投影A-线性τ(T)应用于更新后的向量H(L)[t],随后是非线性激活和剩余连接[5],如下所示:
HGSampling

 wechat
wechat alipay
alipay





