Achieving Forgetting Prevention and Knowledge Transfer in Continual Learning
Achieving Forgetting Prevention and Knowledge Transfer in Continual Learning
Abstract
持续学习(CL)是指逐步学习一连串的任务,目的是实现两个主要目标:克服灾难性遗忘(CF)和鼓励跨任务的知识转移(KT)。然而,大多数现有的技术只注重克服CF,没有鼓励KT的机制,因此在KT中表现不佳。尽管有几篇论文试图同时处理CF和KT,但我们的实验表明,当任务没有太多的共享知识时,它们受到严重的CF影响。
另一个观察结果是,目前大多数CL方法没有使用预训练的模型,但事实证明,这种模型可以大大改善最终的任务表现。例如,在自然语言处理中,对类似BERT的预训练语言模型进行微调是最有效的方法之一。
然而,对于CL来说,这种方法受到了严重的CF的影响。一个有趣的问题是如何将预训练的模型最好地用于CL。本文提出了一个名为CTR的新模型来解决这些问题。我们的实验结果证明了CTR的有效性。
Introduction
本文研究了在任务持续学习(Task-CL)环境下的自然语言处理(NLP)任务序列的持续学习(CL)。它的目的是
- (i) 防止灾难性遗忘(CF)
- (ii)跨任务的知识转移
(ii)特别重要,因为NLP中的许多任务共享类似的知识,可以利用这些知识来实现更好的准确性。CF意味着在学习一个新的任务时,为以前的任务所学的现有网络参数可能会被修改,从而降低以前任务的性能[40]。
在任务-持续学习设置中,在测试中为每个测试案例提供任务ID,这样就可以应用网络中任务的特定模型来对测试案例进行分类。另一个流行的CL设置是类持续学习,它在测试中不提供任务ID,但它是为了解决不同类型的问题。
现有的CL论文大多集中在处理CF[21, 5]。也有一些论文是进行知识转移的。要实现这两个目标是非常具有挑战性的。为了克服任务-CL设置中的CF,我们不希望新任务的训练更新为以前的任务学习的模型参数,以实现模型分离。
但是,为了实现跨任务的知识转移,我们希望新任务能够利用从以前的任务中学到的知识来学习更好的模型(前向转移),也希望新任务能够提高以前类似任务的性能(后向转移)。
这意味着有必要更新以前的模型参数。这是个两难的问题。虽然有几篇论文试图处理这两方面的问题[22, 37],但它们只使用具有强大共享知识的情感分析任务进行测试。当用没有太多共享知识的任务进行测试时,它们会受到严重的CF影响(见5.4节)。那些专注于处理CF的现有论文在知识转移方面做得不好,因为它们没有明确的机制来促进转移。
关于目前CL研究的另一个观察结果是,大多数技术没有使用预训练的模型。但这种预训练的模型或特征提取器可以显著提高CL的性能[18, 24]。一个重要的问题是如何在CL中最好地利用预训练的模型。本文也使用NLP任务来研究这个问题,但我们相信所开发的思想也适用于计算机视觉任务,因为大多数预训练的模型都是基于变换器架构的[60]。我们将看到,在预训练模型上直接添加CL模块的天真或传统方式并不是最佳选择(见第5.4节)。
在NLP中,微调一个类似于BERT[8]的预训练语言模型已被视为应用中最有效的技术之一[65, 57]。然而,微调对持续学习的效果很差。这是因为一个任务的微调BERT捕获了高度特定的任务信息[41],这很难被其他任务所使用。当为一个新的任务进行微调时,它必须更新以前的任务已经微调的参数,这将导致严重的CF(见第5.4节)。
本文提出了一种新型的神经结构,以实现CF的预防和知识转移,同时也处理了具有BERT微调的CF问题。提出的系统被称为CTR(持续学习的胶囊和转移路由)。CTR在BERT的两个位置插入了一个持续学习插件(CL-plugin)模块。在BERT中加入这对CL-插件模块后,我们不再需要为每个任务对BERT进行微调,因为这将导致BERT中的CF,但我们却可以实现BERT微调的功能。CTR与Adapter-BERT[16]有一些相似之处,后者在BERT中增加了适配器,用于参数的有效转移学习,这样,不同的终端任务可以有其独立的适配器(其尺寸非常小)来为各个终端任务调整BERT,并将BERT的知识转移到终端任务中。那么,就不需要为每个任务采用单独的BERT并对其进行微调,如果需要学习许多任务,那么参数效率是非常低的。适配器是一个简单的2层全连接网络,用于将BERT适应于特定的终端任务
CL-插件与适配器有很大不同。我们不使用一对CL-插件模块来为每个任务调整BERT。相反,CTR只使用插入到BERT中的一对CL-插件模块来学习所有的任务。CL-插件是一个完整的CL网络,可以利用预训练的模型,处理CF和知识转移。具体来说,它使用一个胶囊[15]来代表每个任务,并使用一个拟议的转移路由算法来识别和转移跨任务的知识,以达到提高准确性的目的。它进一步学习和使用任务掩码来保护特定任务的知识,以避免遗忘。经验评估表明,CTR的性能优于强大的基线。还进行了消融实验,以研究在何处插入BERT中的CL-插件模块,以实现最佳性能(见第5.4节)。
Related Work
Catastrophic Forgetting
CL的现有工作主要集中在使用以下方法来克服CF。(1) 基于正则化的方法,如[27, 30, 51, 69],在损失中加入正则化,以便在学习新任务时巩固以前任务的权重。(2)基于重放的方法,如[45, 36, 4, 63]中的方法,保留一些旧任务的训练数据,并在学习新任务时使用它们。54, 20, 47, 14]中的方法学习数据生成器并生成旧任务数据用于学习新任务。(3) 基于参数隔离的方法,如[52, 21, 39, 10]中的方法,分配专用于不同任务的模型参数,并在学习新任务时将其屏蔽。(4) 基于梯度投影的方法[68]确保梯度更新只发生在旧任务输入的正交方向上,因此不会影响旧任务。最近的一些论文使用了预训练的模型[18, 23, 24]和每个任务学习一个类[18]。应对CF只处理模型恶化的问题。这些方法的表现比单独学习每个任务要差。在[44]中对CF的原因和任务相似性对CF的影响进行了实证研究。
一些NLP的应用也涉及到CF。例如,CL模型已被提出用于情感分析[23, 24, 37, 43]、对话槽填充[53]、语言建模[58, 7]、语言学习[31]、句子嵌入[33]、机器翻译[25]、跨语言建模[35],以及问题回答[12]。在[38]中也报告了一个对话CL数据集。
Knowledge Transfer
理想情况下,从任务序列中学习也应该允许多个任务通过知识转移相互支持。CAT[21](一个任务-CL系统)在相似和不相似的任务的混合序列上工作,可以在自动检测到的相似任务之间转移知识。渐进式网络[48]做了前向转移,但它是针对类持续学习(Class-CL)。
本文中的知识转移与终身学习(LL)密切相关,其目的是在不处理CF的情况下提高新的/最后的任务学习[56, 49, 5]。在NLP领域,NELL[3]进行了LL信息提取,还有几篇论文致力于终身的文档情感分类(DSC)和方面情感分类(ASC)。[6]和[61]提出了两种Naive Bayesian方法来帮助提高新任务的学习。[64]提出了一种基于投票的LL方法。[55]将LL用于方面提取。[43]和[62]分别将神经网络用于DSC和ASC。有几篇论文也研究了终身主题建模[5, 13]。然而,所有这些工作都没有涉及到CF。
SRK[37]和KAN[22]试图在持续情感分类中同时处理CF和知识转移问题。然而,它们有两个关键的弱点。(i) 它们的RNN架构不能使用插件或适配器模块来调整BERT,这大大限制了它们的能力。(ii) 由于它们主要是为知识转移而设计的,因此它们受到了严重的CF(见第5.4节)。B-CL[24]使用适配器的想法[16]来调整BERT的情感分析任务,这两者之间是相似的。然而,由于其知识转移的动态路由机制非常弱,其知识转移能力明显比CTR差(见第5.4节)。CLASSIC[23]是另一个关于知识转移的持续学习的最新工作,但其CL设置是领域持续学习。它的知识转移方法是基于对比学习。
AdapterFusion[42]使用了[16]中提出的适配器。它提出了一个两阶段的方法来学习一组任务。在第一阶段,它使用任务的训练数据为每个任务独立学习一个适配器。在第二阶段,它再次使用训练数据来学习第一阶段学到的适配器的良好组合,以产生所有任务的最终模型。AdapterFusion基本上试图改善多任务学习。它不是为了持续学习,因此没有CF。正如第1节所解释的,CTR中的CL-插件概念与为每个任务适应BERT的适配器不同。CL-插件是利用预先训练的模型的持续学习系统。
CTR Architecture
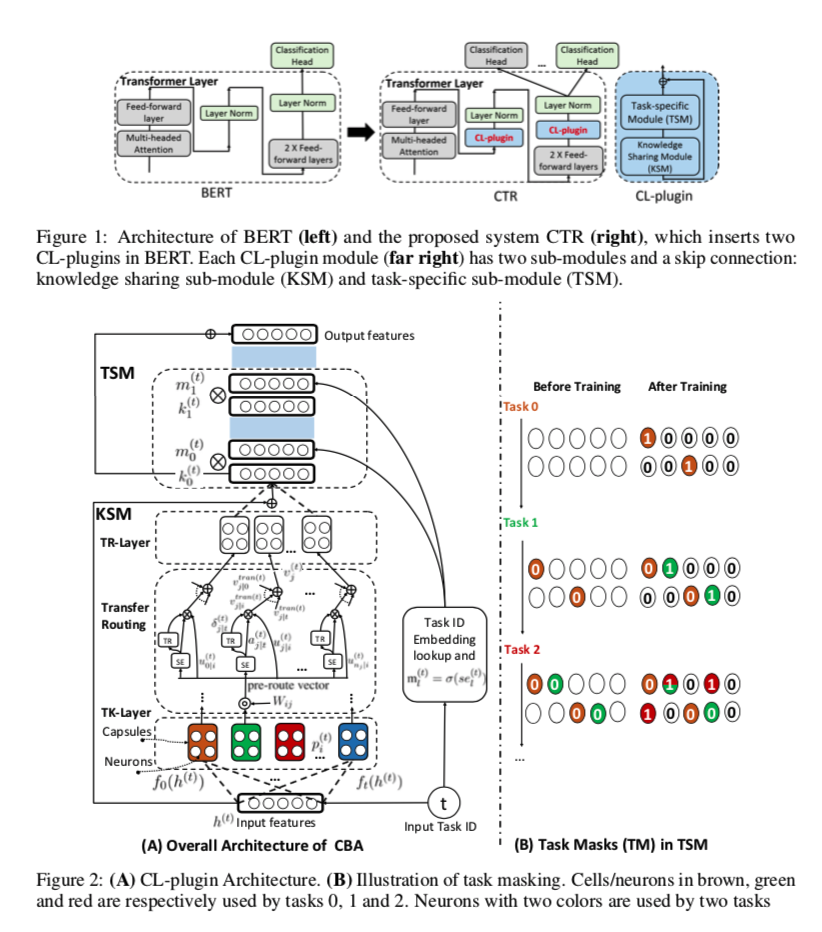
本节介绍了 CTR 的总体架构。关于其关键组件 CL-plugin 的细节将在下一节介绍。由于其良好的性能,BERT[8]及其变压器[60]结构在我们的模型CTR中被用作基础。由于BERT微调容易出现CF(第1节),我们提出了CL-plugin的想法,其灵感来自Adapter-BERT[16]。CL-插件是一个完整的持续学习模块,旨在与预先训练的模型(在我们的例子中是BERT)进行交互。
Inserting CL-plugins in BERT
一个常用的利用预训练模型的方法是在预训练模型的基础上增加终端任务模块。然而,正如第1节所解释的,对预训练模型进行微调会给CL带来严重的CF。使用这种方法的CL系统PCL[18],将预训练的模型冻结起来,以避免遗忘。但正如我们将在第5.4节中看到的,这不是最好的选择。CTR在BERT的两个位置插入了提议的CL插件,即在BERT的每个变压器层中。我们还将在第5.4节中看到,在一个位置只插入一个CL插件是次优的。图1给出了CTR架构,我们可以看到两个CL-插件被添加到BERT中。在学习中,只有这两个CL插件和分类头被训练。原始预训练的BERT的组件是固定的。
Continual learning plug-in (CL-plugin)
CL-plugin采用了类似胶囊网络(CapsNet)[15, 50]的架构。在经典的神经网络中,一个神经元输出一个标量、实值的激活作为特征检测器。CapsNets用一个矢量输出的胶囊代替,以保留额外的信息。一个简单的CapsNet由两个胶囊层组成。第一层存储低级别的特征图,第二层生成分类概率,每个胶囊对应一个类别。CapsNet使用动态路由算法,使每个低层的胶囊将其输出发送到类似的(或 “同意的”,由点积计算的)高层胶囊。这一特性已经可以用来对类似的任务及其可共享的特征进行分组,以产生一个CL系统(见5.4节中的消融研究)。CL-插件的关键思想之一(见图2(A))是一个转移胶囊层,它有一个新的转移路由算法,可以明确地识别从以前的任务转移到新任务的可转移特征/知识。
Continual Learning Plug-in (CL-plugin)
我们的持续学习插件(CL-plugin)的结构如图2(A)所示。CL-plugin需要两个输入。(1) 来自变压器层内前馈层的隐藏状态h(t)和 (2) 任务ID t,这是任务持续学习(Task-CL)的要求。输出是具有适合第t个任务分类的特征的隐藏状态。在CL-plugin内部,有两个模块。(1)知识共享模块(KSM),用于识别和转移以前类似任务的可共享知识到新任务t,以及(2)任务特定模块(TSM),用于学习任务特定的神经元及其掩码(可以保护神经元不被未来任务更新,以处理CF)。由于TSM是可分的,整个系统CTR可以进行端到端的训练。
Knowledge Sharing Module (KSM)
KSM通过任务封装层(TK-Layer)、传输胶囊层(TR-Layer)和传输路由机制实现相似任务之间的知识传输。
Task Capsule Layer (TK-Layer)
TK层中的每个胶囊代表一个任务,它准备了从每个任务中得到的低层次特征(图2(A))。因此,每个新任务都有一个胶囊被添加到TK层中。这种递增式的增长是有效和容易的,因为这些胶囊是离散的,不共享参数。另外,每个胶囊只是一个具有少量参数的2层全连接网络。让 $h(t)∈R^{d_t×d_e}$ 是CL-plugin的输入,其中dt是tokens的数量,de是维数,t是当前任务。在TK层中,我们为每个任务准备了一个胶囊。假设到目前为止我们已经学会了t个任务。第i个(i≤t)任务的胶囊是:
其中$f_i(·)=MLP_i(·)$表示2层全连通网络。
Transfer Routing and Transfer Capsule Layer
转移胶囊层(TR层)中的每个胶囊代表从TK层中提取的可转移表示。如图2(A)所示,TK层的低级胶囊和TR层的高级胶囊之间的转移路由有三个组成部分:预路由向量发生器(PVG)、相似性估计器(SE)和任务路由器(TR)。鉴于TK层中的任务胶囊,我们首先通过一个可训练的权重矩阵来转换特征。我们把这种转换的输出称为预路由向量。每个SE使用预路由向量估计以前的任务和当前的任务之间的相似性,从而为每个高层的胶囊得出相似性分数。此外,每个SE都有一个TR模块,一个作为门的可区分的任务路由器。这个路由器估计一个二进制信号,决定是否连接或断开两个连续的胶囊层(即CL-插件中的TK层和TR层)之间的当前路线。由TR估计的二进制信号可以被看作是一个可区分的二进制注意。从概念上讲,每个SE和TR对一起以随机和可区分的方式学习胶囊之间的连接性,这可以被看作是一个基于任务相似性的连接性搜索机制。这种转移路由确定了来自多个任务胶囊的共享特征/知识,并帮助知识在类似任务之间转移。接下来,我们讨论预路由向量发生器、相似性估计器和任务路由器。
CLASSIC: Continual and Contrastive Learning of Aspect Sentiment Classification Tasks
本文研究了在一个特殊的持续学习(CL)环境下的一系列方面情感分类(ASC)任务,称为领域递增学习(DIL)。每个任务都来自不同的领域或产品。DIL设置特别适用于ASC,因为在测试中,系统不需要知道测试数据所属的任务/领域。据我们所知,这种设置以前还没有为ASC研究过。本文提出了一个叫做CLASSIC的新模型。关键的创新点是一种对比性的持续学习方法,它既能实现跨任务的知识转移,又能将知识从旧任务提炼到新任务,这就消除了测试中对任务ID的需求。实验结果表明,CLASSIC的有效性很高。
Introduction
持续学习(CL)以递增的方式学习一连串的任务。在学习完一个任务后,其训练数据通常被丢弃(Chen和Liu,2018)。当数据隐私是一个问题时,CL设置是有用的,即数据所有者不希望他们的数据被其他人使用(Ke等人,2020b;秦等人,2020;Ke等人,2021)。在这种情况下,如果我们想利用过去学到的知识来改善新的任务学习,CL是合适的,因为它只分享学到的模型,而不是数据。在我们的案例中,一个任务是一个产品或领域(例如,相机或手机)的一个单独的方面情感分类(ASC)问题(刘,2012)。ASC表述如下。给出一个方面的术语(例如,手机评论中的声音质量)和一个包含该方面的句子(例如,”声音质量很差”),ASC对该句子是否表达了对该方面的积极、消极或中立的意见进行分类。
有三种CL设置(van de Ven and Tolias, 2019)。类增量学习(CIL),任务增量学习(TIL),和域增量学习(DIL)。在CIL中,任务包含不重叠的类。对于目前看到的所有类别,只建立一个模型。在测试中,不提供任务信息。这种设置不适合ASC,因为ASC任务有相同的三个类。TIL为共享网络中的每个任务建立一个模型。在测试中,系统需要每个测试实例(例如,”音质很好”)所属的任务(例如,电话领域),并且只使用任务的模型来对实例进行分类。重新要求任务信息(如电话领域)是一个限制。理想情况下,用户不应该为一个测试句子提供这些信息。这就是DIL设置,即所有任务共享相同的固定类别(例如,积极、消极和中立)。在测试中,不需要任何任务信息。
这项工作使用DIL设置来学习神经网络中的一系列ASC任务。关键的目标是在不同的任务之间转移知识,以改善分类,而不是单独学习每个任务。任何CL的一个重要目标是克服灾难性遗忘(CF)(McCloskey和Cohen,1989),这意味着在学习一个新的任务时,系统可能会改变为以前的任务学习的参数,导致其性能下降。我们也要解决CF的问题,否则我们就不能达到提高准确性的目的。然而,DIL中的所有任务共享分类头,使得跨任务干扰/更新不可避免。没有测试中提供的任务信息,使DIL更具挑战性。
以前的研究表明,ASC最有效的方法之一(Xu等人,2019;Sun等人,2019)是使用训练数据对BERT进行微调(Devlin等人,2019)。然而,我们的实验表明,这对DIL来说效果很差,因为一个任务上的微调BERT捕获了高度的任务特定特征,而这些特征很难被其他任务使用。
在本文中,我们在DIL设置中提出了一个名为CLASSIC(Continual and contrastive Learning for ASpect SentIment Classification)的新型模型。CLASSIC没有为每个任务微调BERT,这将导致严重的CF,而是使用(Houlsby等人,2019)中的Adapter-BERT的想法来避免改变BERT参数,但却能获得与BERT微调同样好的结果。提出了一种新颖的对比性持续学习方法(1)将可共享的知识转移到不同的任务中,以提高所有任务的准确性;(2)将以前的任务中的知识(包括可共享的和不可共享的)提炼到新任务的模型中,使新的/最后一个任务模型能够执行所有的任务,这样就不需要在测试中提供任务信息(如任务ID)。现有的对比学习(Chen等人,2020)无法做到这些。
任务 mask 也被学习并用于保护特定任务的知识以避免遗忘(CF)。已经进行了大量的实验来证明CLASSIC的有效性。
综上所述,本文有以下贡献。(1) 它提出了ASC的领域持续学习问题,这在以前是不可能的。(2) 它提出了一个名为CLASSIC的新模型,该模型使用适配器将预先训练好的BERT纳入ASC的持续学习中,使用一种新颖的对比性持续学习方法进行知识转移和提炼,并使用任务掩码隔离特定任务的知识以避免CF。
Proposed CLASSIC Method
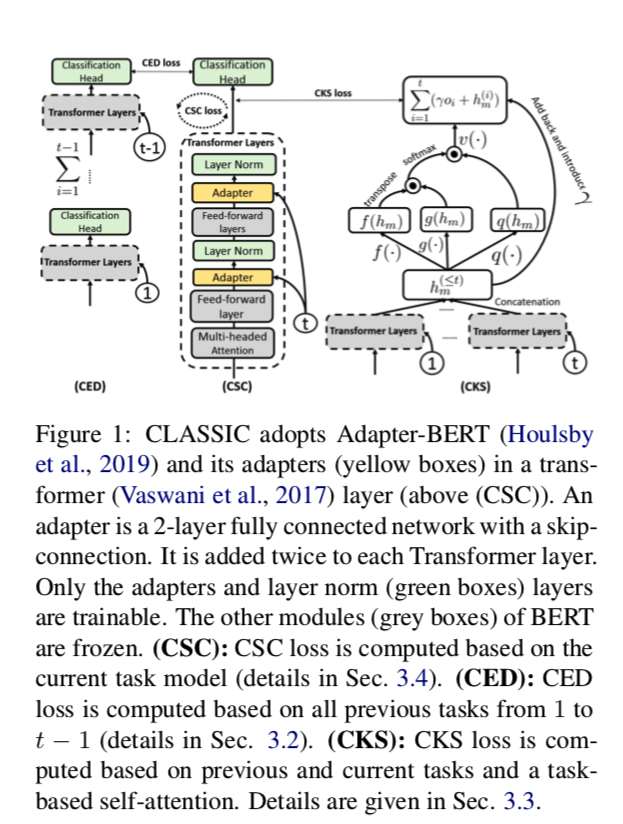
3.1 Overview of CLASSIC
图1中给出了CLASSIC的结构,它在ASC的DIL设置中工作。它使用Adapter-BERT来避免对BERT进行微调。CLASSIC在训练中需要两个输入。(1) 来自BERT变压器层的前馈层的隐藏状态 $h(t)$ 和 (2) 任务 id $t$(测试时不需要任务 id,见第3.2.3节)。输出是带有任务 $t$ 特征的隐藏状态,以建立一个分类器。
CLASSIC使用三个子系统来实现其目标(见第1节)。
- (1) 对比性集合提炼(CED),通过将以前的任务知识提炼到当前的任务模型中来减轻CF;
- (2) 对比性知识共享(CKS),鼓励知识转移;
- (3) 当前任务模型的对比性监督学习(CSC),提高当前任务模型的准确性。我们把这个框架称为对比性持续学习,其灵感来自于对比性学习。
对比学习使用现有数据的多个视图进行表征学习,将相似的数据组合在一起,并将不相似的数据推得很远,这使得学习更准确的分类器更加容易。它使用现有数据的各种转换来创建有用的视图。给定一个由 $N$ 个训练实例组成的小型批次,如果我们为每个实例创建另一个视图,该批次将有 $2N$ 个样本。
我们假设 $i$ 和 $j$ 是训练实例的两个视图。如果我们用 $i$ 作为锚点。$(i, j)$ 被称为正对。所有其他 $k\ne i$ 的对$(i,k)$都是负对。这个正数对的对比损失是(Chen等人,2020),
其中点积 $h_i \cdot h_j$ 被视为隐藏空间中的相似性函数,$τ$ 是温度。该批次的最终损失是在所有的正数对中计算的。上式是用于无监督的对比学习。它也可以用于监督对比学习,来自同一类别的任何两个实例/视图形成一个正例对,而一个类别的任何实例和其他类别的任何实例形成一个负例对。
3.2 Overcoming Forgetting via Contrastive Ensemable Distillation (CED)
CED的目标是处理CF。我们首先介绍了CED所依赖的任务掩码,以保留以前的任务知识/模型,将其提炼到新的任务模型中,以避免CF。
3.2.1 Task Masks (TMs)
给定来自转换层前馈层的输入隐藏状态 $h^{(t)} $,adapter 通过全连接网络将其映射为输入$k^{(t)}_l$,其中 $l$ 是适配器的第 $l$ 层。
在训练任务 $t$ 的分类器时,在 adapter 的每一层 $l$ 为每个任务 $t$ 训练一个 TM(一个 “软 “二进制掩码)$m^{(t)}_l$,表明该层中对任务重要的神经元。在这里,我们借鉴了(Serrà等人,2018)中的 hard attention 思想,并利用任务 id 嵌入来训练TM。
对于一个任务id t,它的嵌入$e^{(t)}_l$ 由可微调的参数组成,可以和网络的其他部分一起学习,它是为 adapter 中的每一层训练的。为了从 $e^{(t)}_l $ 中生成TM $m^{(t)}_l$,Sigmoid被用作伪门,并应用一个正的缩放超参数 $s$ 来帮助训练。$m^{(t)}_l $的计算方法如下:
请注意,$ m^{(t)}_l $ 中的神经元可能与以前任务中的其他 $m^{(iprev)}_l$ 的神经元重叠,显示出一些共享的知识。给出适配器中每一层的输出,$k^{(t)}_l $,我们将其进行元素乘法计算 $k^{(t)}_l ⊗ m^{(t)}_l$。
最后一层的屏蔽输出 $k^{(t)}_l \otimes m_l^{(t)} $ 被送入BERT的下一层,有一个跳过的连接(见图2)在学习任务 $t$ 之后,最终的 $m^{(t)}_l $ 被保存并添加到集合 ${m^{(t)}_l}$中。
3.2.2 Training Task Masks (TMs)
对于每个先前的任务 $i{prev} \in T{prev}$,其TM $m^{(iprev)}_l$表明哪些神经元被该任务使用并需要保护。在学习任务 $t$ 中,$m^{(iprev)}_l $ 用来设置 $l$ 层所有使用的神经元上的梯度 $g(t)$ 层的所有神经元的梯度为 0。在修改梯度之前,我们首先积累所有以前的任务TMs 所使用的神经元。由于 $m^{(iprev)}_l$ 是二进制的,我们用最大池化来实现累积:
term $m^{(T_{ac})}_l$用于梯度:
那些对应于 $m^{(t{ac})}_l$ 中1项的梯度被设置为0,而其他梯度则保持不变。通过这种方式,旧任务中的神经元被保护起来。请注意,我们扩展(复制)矢量 $m^{(t{ac})}_l $ 以匹配 $g^{(t)}_l$ 的尺寸。
虽然这个想法很直观,但 $e^{(t)}l $ 并不容易训练。为了使 $e^{(t)}_l $ 的学习更容易、更稳定,采用了退火策略。也就是说,s在训练期间被退火,诱发梯度 flow,在测试期间设置 $s=s{max}$。公式2将一个单位 step 函数近似为mask,当 $s→∞$ 时,$m^{(t)}_l→{0,1}$。一个训练周期开始时,所有的神经元都是同样活跃的,在周期内逐渐极化。具体来说,$s$ 的退火情况如下:
其中 $b$ 是批次索引,$B$ 是一个 epoch中的总批次数。
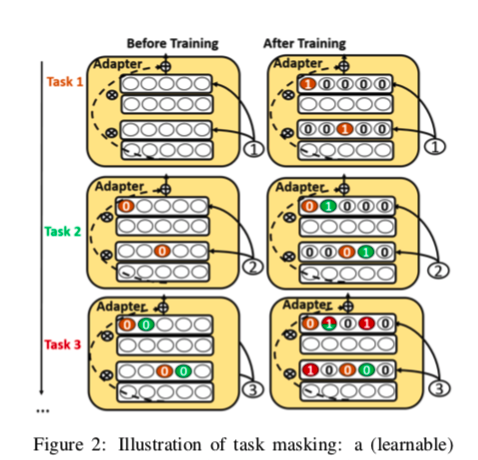
Illustration :在图2中,在学习了任务1之后,我们得到了其有用的神经元,用橙色标记,每个神经元中都有一个 “1”,在学习未来的任务时,它可以作为一个屏蔽。在学习任务2时,那些对任务1有用的神经元被掩盖了(左边那些橙色的神经元上有 “0”)。这个过程还学习了任务2的有用神经元,用绿色的 “1 “标记。当任务3到来时,任务1和任务2的所有神经元都被屏蔽了,也就是说,它的TM条目被设置为0(训练前为橙色和绿色)。训练完任务3后,我们看到任务3和任务2有一个共享神经元,对两者都很重要。该共享神经元被标记为红色和绿色。
3.2.3 Contrastive Ensemble Distillation (CED)
TMs机制为不同的任务隔离了不同的参数。这对于克服遗忘似乎是完美的,因为以前的任务参数是固定的,不能被未来的任务所更新。
然而,由于DIL设置在测试中没有任务 id,我们不能直接利用TM的优势。为了解决这个问题,我们提出了CED目标,以帮助提炼所有先前的知识到当前的任务模型,这样我们就可以简单地使用最后的模型作为最终模型,而不需要在测试中使用任务 id。
Representation of Previous Tasks。回顾一下,我们通过阅读 ${m^{(i)}_l}$ 知道哪些神经元/单元是用于哪个任务的。对于当前任务 $t$ 的每个以前的任务 $i$ 我们可以通过将 $m^{(i)}_l $ 应用于Adapter-BERT(分类头之前的那一层)来计算它的 mask 输出。
Ensemble Distillation Loss 我们将以前的任务集合的知识提炼成 单一的当前任务模型。由于我们在DIL中的所有任务都有一个共享的分类头,它被暴露在遗忘中,所以提炼应该基于分类头的输出。具体来说,给定前一个任务的Adapter-BERT输出 $h^{(i)}_m $,我们用 $h^{(i)}_m$ 计算分类头的输出,这就得到了logit(未归一化的预测)值 $z^{(i)}_m$。然后,我们利用 $z^{(i)}_m $和当前任务分类头的输出 $z^{(t)}$ 来提炼知识,其灵感来自于(Tian等人,2020a)的对比损失
其中,$N$ 是批次大小,$τ>0$ 是一个可调节的温度参数,控制类的分离。索引 $n$ 是锚点,符号 $z^{(i)}_{m:n} $ 指的是 $z^{(i)}_m $ 中的第 $n$ 个样本。
$z^{(i)}{m:2n-1}$ 和 $z{m:2n}^{(t)}$ 是先前和当前任务模型对同一输入样本的对数,是对比学习中的一对正例。所有其他可能的配对都是负例的配对。请注意,对于每个锚点 $i$ ,都有1对正数和 $2N-2$ 对负数。
分母总共有 $2N - 1$个项(包括正项和负项)。请注意,以前的任务模型是固定的,因此可以作为教师网络。由于我们有$i≥1$ 个以前的任务,因此 $i≥1$个教师网络,但只有一个当前任务的学生网络。我们采用对比性框架,在 $z^{(i)}_m $ 和 $z^{(t)}_m $ 之间定义多个配对的损失。这些损失相加,得出最终的CED损失,
3.3 Transferring Knowledge via Contrastive Knowledge Sharing (CKS)
CKS旨在捕捉任务间的共享知识,帮助新任务学习更好的表示和更好的分类器。CKS的直觉是这样的。对比学习有能力捕捉不同观点之间的共享知识(Tian等人,2020b;van den Oord等人,2018)。这是通过寻求不变的跨类似观点的表示来实现的。
如果我们能从以前的任务中产生一个与当前任务相似的视图,那么对比性损失就能捕捉到共享的知识,并为知识转移到新的任务学习中学习一个表示。下面,我们首先介绍如何构建这样的视图并在CKS目标中使用它。
3.3.1 Task-based Self-Attention
直观地说,这两项任务越是相似,它们的共享知识就越多。它们拥有的共享知识就越多。为了实现我们的目标,我们应该将所有类似的任务合并为 共享知识视图。为了专注于 类似的任务,我们建议使用Task-based Self-Attention来关注它们。
在(Zhang等人,2018年)的启发下,给定Adapter-Bert针对所有先前和当前任务的输出的级联,$h{m}^{(\le t)} = cat({h_m^{(i)}}{i=1}^t)$, 并且 task $i\le t$, 我们首先转换它到两个特征空间,通过 $f(h_m^{(i)}) = W_fh_m^{(i)}, g(h_m^{(i)})=W_gh_m^{(i)}$ (见图1 CKS)
为了比较任务 $i≤t$ 和 $j≤t$ 之间的相似度,我们通过以下方式计算相似度 $s_{ij}$ :
然后,我们计算注意力分数 $α_{j,i} $,以表明根据当前任务数据,哪些类似的任务(与当前任务 $t$ 类似)应该被关注:
注意力得分被应用于 $h_m^{(\le t)}$ 中的每个任务,以获得加权和的注意力输出 $o_j$ :
其中 $v(-)$ 和 $q(-)$ 是两个用于转换特征空间的函数:$v(h^{(i)}_m) = W_vh^{(i)}_m $和 $q(h^{(i)}_m) = W_vh^{(i)}_m$。
最后,我们将注意力层的输出乘以一个比例参数,再加回输入特征 $h^{(≤t)}{cks}$。$h^{(≤t)}{CKS}$的最终输出是所有考虑的任务之和,
其中 $\gamma$ 是可学习的标量,并且被初始化为0,这允许模型首先在当前任务上进行学习,然后逐渐学习为其他任务分配更多的权重。
3.3.2 Knowledge Sharing Loss
基于任务的自我关注的输出为我们提供了 知识共享视图 $h^{(≤t)}{CKS}$。 伴随着Adapter-BERT对当前任务 $h^{(t)}{m}$ 的输出,我们可以很容易地在这两种观点之间进行对比性学习。
请注意,$h^{(≤t)}_{CKS} $ 是计算出来的基于当前的任务数据和它们相应的类标签,所以我们给两个视图有相同的标签,因此我们可以在我们的CKS损失中整合标签信息 :
其中,$N$ 是批次大小,$N{yn} $是批次中具有标签 $y_n$的例子的数量。 $h{CKS}^{(\le t)}$ 是第一个视图, 同时 $h_m^{(t)}$ 是第二个视图。
他们之间的共享知识代表了以前和当前任务之间的共享知识。 与CED损失不同,CKS损失利用了类别信息,因此可以通过两个样本是否共享相同的类别标签来决定多个正例对。
3.4 Contrastive Supervised Learning of the Current Task (CSC)
我们通过采用监督对比损失法进一步提高了当前任务的性能。通过在当前任务 $h(t)$ 上采用有监督的对比性损失 (Khosla et al., 2020)对当前任务 $h^{(t)}_m$:
Experiments
Compared Baselines
我们采用了46个基线,其中包括非持续学习和持续学习方法。由于在DIL方面所做的工作很少,我们通过合并分类头来使最近的TIL系统适应DIL,形成DIL系统。
Non-Continual Learning Baselines 这些基线中的每一个都为每个任务独立建立一个单独的模型,我们称之为一个变体。因此,它没有知识转移或CF。有8个ONE变体。四个是使用(1)带有微调的BERT,(2)没有微调的BERT(冷冻)(3)Adapter-BERT(Houlsby等人,2019)和(4)W2V(使用FastText(Grave等人,2018)中的亚马逊评论数据训练的word2vec嵌入)。添加CSC(Contrastive Supervised learning of the Current task)会产生另外4种变体。 我们采用(Xue和Li,2018)中的ASC网络工作,将方面术语和评论句子作为BERT变体的输入。对于W2V变体,我们使用它们的连接。
Continual Learning (CL) Baselines.CL设置有5个类别的38个基线。
- 第一类是使用 自然的CL(NCL)方法。它只是用一个网络来学习所有的任务,没有处理CF或知识迁移的机制。像ONE一样,我们有8个NCL的变体。
- 第二类有11条使用最近的CL方法KAN(Ke等人,2020b)、SRK(Lv等人,2019)、HAT(Serrà等人,2018)、UCL(Ahn等人,2019)、EWC(Kirkpatrick等人,2016)、OWM(Zeng等人,2019)和DER++(Buzzega等人,2020)创建的基线。
KAN 和 SRK是用于文档情感分类。我们使用方面和句子的串联作为输入。HAT、UCL、EWC、OWM和DER++最初是为图像分类设计的。我们用CNN取代它们原来的图像分类网络,用于文本分类(Kim,2014)。HAT是最好的TIL方法之一,几乎没有遗忘。UCL是一种最新的TIL方法。EWC是一种流行的CIL方法,在(Serrà等人,2018)中被调整为TIL。它们通过合并分类头被转换为DIL版本。
OWM(Zeng等人,2019)是一种CIL方法,我们也将其改编为EWC这样的DIL方法。DER++和SRK可以在DIL环境下工作。HAT和KAN在测试中需要任务ID作为输入,不能在DIL设置中发挥作用。我们创建了HAT(和KAN)的两个变体:在测试中使用最后一个模型,就像CLASSIC所做的那样,或者使用熵法检测任务ID,在这个类别中使用BERT(冻结)作为基础。第三类有7个基线使用Adapter-BERT。KAN和SRK不能被调整为使用适配器。第四类使用W2V,这又有11条基线。最后一类有一个基线LAMOL(Sun等人,2020),它使用GPT-2模型。
Evaluation Protocol: 我们遵循(Lange等人,2019)中的标准CL评估方法。我们首先向CLASSIC提出一连串的ASC任务供其学习。一旦一个任务被学会,它的训练数据就被丢弃。在所有任务都学会后,我们使用所有任务的测试数据进行测试,而不给任务的ID。
Continual Learning of a Mixed Sequence of Similar and Dissimilar Tasks
现有的关于一连串任务的持续学习的研究集中在处理灾难性的遗忘上,在这种情况下,任务被认为是不相似的,并且几乎没有共享的知识。也有一些工作是在任务相似且有共享知识的情况下,将以前学到的知识转移到新的任务中。据我们所知,还没有人提出学习混合的相似和不相似的任务序列的技术,该技术可以处理遗忘问题,也可以向前和向后转移知识。本文提出了这样一种技术来学习同一网络中的两种类型的任务。对于不相似的任务,该算法侧重于处理遗忘问题,而对于相似的任务,该算法侧重于有选择地转移从以前一些相似的任务中学到的知识,以提高新任务的学习。此外,该算法还自动检测一个新任务是否与以前的任何任务相似。使用混合任务序列的实证评估表明了所提出的模型的有效性。
Continual Learning with Knowledge Transfer for Sentiment Classification
本文研究了情感分类(SC)的持续学习(CL)。在这种情况下,持续学习系统在一个神经网络中逐步学习一连串的情感分类任务,每个任务建立一个分类器,对特定产品类别或领域的评论进行分类。两个自然的问题是。系统能否将过去从以前的任务中学到的知识转移到新的任务中,以帮助它为新的任务学习一个更好的模型?而且,在这个过程中,以前的任务的旧模型是否也能得到改善?本文提出了一种叫做KAN的新技术来实现这些目标。KAN可以通过前向和后向的知识转移,明显地提高新任务和旧任务的SC准确性。通过大量的实验证明了KAN的有效性。
类持续学习(CCL)。在CCL中,每个任务包括一个或多个要学习的类。到目前为止,只为所有的类建立一个模型。在测试中,一个来自任何类别的测试实例可能会被提交给模型,让它进行分类,而不给它任何训练中使用的任务信息。
任务持续学习(TCL)。在TCL中,每个任务都是一个单独的分类问题(例如,一个是对不同品种的狗进行分类,另一个是对不同类型的鸟进行分类)。TCL在一个神经网络中建立了一组分类模型(每个任务一个)。在测试中,系统知道每个测试实例属于哪个任务,只使用该任务的模型对测试实例进行分类。
在本文中,我们在TCL环境中工作,不断地学习一连串的情感分析(SA)任务。通常情况下,一个情感分析公司必须为许多客户工作,每个客户都想研究公众对其产品/服务的一个或多个类别以及其竞争对手的意见。对每一类产品/服务进行情感分析是一项任务。为了保密,客户往往不允许SA公司与其他客户分享数据或将其数据用于其他客户。持续的学习是一个自然的过程。在这种情况下,我们也希望在不违反保密性的情况下,随着时间的推移提高SA的准确性。这就提出了两个关键的挑战。(1)如何将从以前的任务中学到的知识转移到新的任务中,以帮助它在不使用以前任务的数据的情况下更好地学习,(2)如何在没有CF的情况下在这个过程中改进以前任务的旧模型?在[15]中,作者表明CL可以帮助提高文档级情感分类(SC)的准确性,这是SA[13]的一个子问题。在本文中,我们提出了一个明显更好的模型,称为KAN(知识可及性网络)。请注意,这里的每个任务都是一个两类SC问题,即对一个产品的评论是正面还是负面进行分类。
在遗忘方面已经做了相当多的工作。然而,现有的技术主要集中在处理灾难性遗忘(CF)方面[4,18]。在学习一个新的任务时,他们通常试图使权重朝着对以前的任务伤害较小的方向更新,或者防止以前的任务的重要权重被显著改变。我们将在下一节详细介绍这些和其他相关的工作。只处理CF对SC来说是远远不够的。在大多数现有的关于CL的研究中,任务是相当不同的,而且几乎没有共享的知识。因此,专注于处理CF是有意义的。然而,对于SC来说,任务是相似的,因为用于表达不同产品/任务的情感的词和短语是相似的。正如我们在第4.4节中所看到的,由于任务间的共享知识,CF在SC的CL中不是一个主要问题。因此,我们的主要目标是利用任务间的共享知识,使其表现明显优于单独学习单个任务。
为了实现利用任务间的共享知识来提高SC的准确性的目标,KAN使用了两个子网络,主要的持续学习(MCL)网络和可及性(AC)网络。MCL的核心是一个知识库(KB),它存储了从所有训练过的任务中学到的知识。在学习每个新任务时,AC网络决定过去的知识中哪一部分对新任务有用,并可以共享。这就实现了向前的知识转移。同样重要的是,在新任务训练期间,共享的知识利用其数据得到加强,这导致了后向知识转移。因此,KAN不仅提高了新任务的模型精度,而且还提高了以前任务的精度,而无需任何额外的操作。大量的实验表明,KAN明显优于最先进的基线。
Proposed Model KAN
为了提高分类的准确性,同时也为了避免遗忘,我们需要确定一些过去的知识,这些知识在学习新的任务时是可以共享和更新的,这样就不会发生遗忘过去知识的情况,新的任务和过去的任务都可以得到改善。
我们通过从我们人类似乎做的事情中获取灵感来解决这个问题。例如,我们可能会 “忘记 “10年前的电话号码,但如果同样的号码或类似的号码再次出现,我们的大脑可能会迅速检索出旧的电话号码,并使新旧号码都得到更牢固的记忆。生物学研究[10]表明,我们的大脑会对知识的可及性进行追踪。如果我们以前知识的某些部分对新任务有用(即新任务和以前一些任务之间的共享知识),我们的大脑就会将这些部分设置为可访问,以实现知识的前向转移。这也使后向知识转移成为可能,因为它们现在可以被访问,我们有机会根据新的任务数据来加强它们。对于那些以前的知识中没有用的部分,它们被设置为不可访问,这样可以保护它们不被改变。受到这个想法的启发,我们设计了一个记忆和可访问性机制。
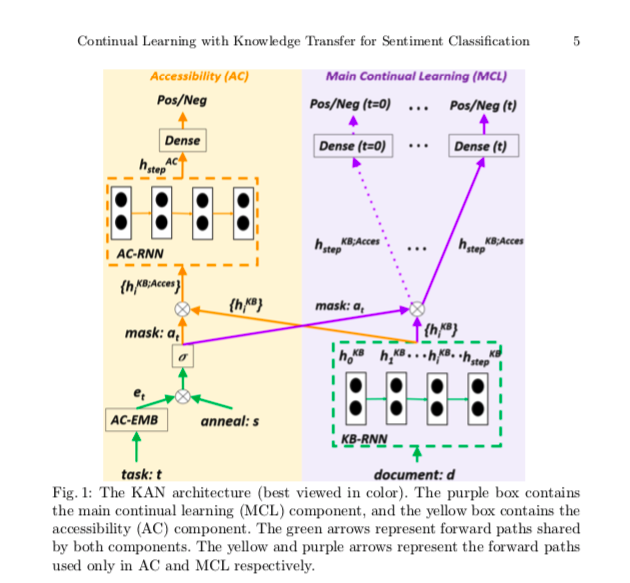
我们需要解决两个关键问题。(1)如何检测内存(我们称之为知识库(KB))中的知识的可访问性,即识别以前的知识中对新任务有用的部分;(2)如何利用识别的有用/共享的知识来帮助新任务的学习,同时也保护其他部分。为了应对这些挑战,我们提出了图1所示的知识和可及性网络(KAN)。
KAN有两个组件(见图1),紫色框中的主要持续学习(MCL)组件和黄色框中的可及性(AC)组件。MCL执行主要的持续学习和测试(AC在测试中不使用,除了从任务id t生成的掩码)。我们看到每个任务的情感分类头(正/负)在顶部。下面是密集层,再往下是绿色虚线框内的知识库(KB)(记忆)。知识库使用RNN(我们在系统中使用GRU)建模,被称为KB-RNN,包含特定任务和跨任务的共享知识。AC通过设置一个基于任务的二进制掩码来决定KB中的哪部分知识(或单元)可以被当前任务t访问。每个任务由AC-EMB从任务ID(t)中产生的任务嵌入来表示。AC-EMB是一个随机初始化的嵌入层。KAN的输入是任务id t和文档d。它们通过掩码a和{hKB}用于训练两个组件。(KB-RNN中的隐藏状态)链接来训练两个组件。
 wechat
wechat alipay
alipay





