Exploring Low-dimensional Intrinsic Task Subspace via Prompt Tuning
Exploring Low-dimensional Intrinsic Task Subspace via Prompt Tuning
预训练的语言模型(PLM)如何学习通用的表征,并有效地适应广泛的NLP任务的差异很大的表面上?
在这项工作中,我们从经验上发现了一些证据,表明PLM对各种任务的适应性可以被重新参数化,即在一个共同的低维内在任务子空间中只优化几个自由参数。这可能有助于我们理解为什么PLMs 可以帮助我们理解为什么PLM可以很容易地适应各种NLP任务的 小规模的数据。
具体来说,为了找到这样一个子空间并考察其普遍性,我们借助最近在prompt tuning方面的成功经验,将多个NLP任务的软提示分解到同一个低维非线性子空间中,然后我们只通过调谐子空间中的参数来学习使PLM适应未见的任务或数据。
我们把这个管道称为 intrinsic prompt tuning(IPT)。在实验中,我们研究了不同的少量NLP任务,并令人惊讶地发现,在用100个随机任务找到的5维子空间中,只需调整5个自由参数,我们就可以对100个看过的任务(使用不同的训练数据)和20个未看过的任务分别恢复87%和65%的完整提示调谐性能,显示了所发现的内在任务子空间的巨大通用能力。
除了作为一种分析工具,IPT还可以进一步带来实际的好处,如提高提示调谐的稳定性。
Introduction
预训练的语言模型(PLMs)在各种自然语言处理(NLP)任务中表现出了优势(Han等人,2021a;Qiu等人,2020)。
在海量数据上预训练巨大的参数后,PLM可以通过全参数微调甚至参数高效的调谐方法,有效地适应不同的下游NLP任务,与模型规模相比,数据规模较小。然而,这种适应背后的机制仍然不清楚。PLM如何通过与任务无关的预训练目标来学习普遍的表征,并轻松适应差异很大的不同NLP任务?为了理解PLM如何能以较小的代价普遍地进行适应,在本文中,我们假设PLM适应各种下游任务的优化问题可以被重新参数化,即在同一个低维参数子空间中只优化几个自由参数,我们称之为内在任务子空间(图1)。
具体来说,这里的适应性是指优化可调整的适应性参数,使PLM能够适应某个下游任务,这通常是一个非常高维的优化问题。例如,在传统的微调中,自适应参数是所有的PLM参数和分类头,其数量超过了数亿。然而,Aghajanyan等人(2021)表明,对PLM单一任务的适应可以重新参数化,只需在低维子空间中优化数百个自由参数,然后将调整后的参数随机投射回全部参数空间。这激发了我们的假设,即对多个任务的适应可以被重新参数化为同一低维内在任务子空间的优化。如果这个假设成立,特定任务优化子空间的存在解释了PLMs的普遍性,而低维度解释了为什么适应性可以用相对较小的数据完成。从这个角度来看,PLMs是一个通用的压缩框架,它将各种任务的学习复杂性从非常高的维度压缩到低维度。如果这个假设成立,特定任务的优化子空间的存在解释了PLMs的普遍性,而低维度解释了为什么适应性可以用相对较小的数据完成。从这个角度来看,PLMs是一个通用的压缩框架,它将各种任务的学习复杂性从非常高的维度压缩到低维度。
为了找到该假设的证据,我们需要开发寻找PLM的内在任务子空间的方法。自然,子空间应该包含各种任务的适应性解决方案(即可调整的适应性参数),因此我们可以通过使用多个任务训练适应性参数的低维分解来近似子空间,然后考察我们是否能在找到的子空间中学习未见过的任务。然而,训练所有PLM参数的分解(微调的情况)在计算上是难以实现的,因为投影到子空间的参数将是数百个PLM。
Prompt tuning(PT)提供了一个参数高效的替代方案,其适应性参数,即软提示,只有几万个。然而,PT可以在理解(Lester等人,2021;Liu等人,2021b)和生成(Li和Liang,2021)任务上达到接近微调的性能。此外,PT没有结构上的偏差,因为调整后的软提示仅限于输入嵌入,因此与其他参数有效的调整方法如适配器(Houlsby等人,2019)相比,分解它们在直觉上更容易。
在实验中,我们通过PT在 few-shot 学习设置下探索共同的内在子空间,这保证了各种任务的数据规模是平衡的。我们将本文使用的经验方法命名为IPT,由两个阶段组成:multi-task subspace finding(MSF)和 intrinsic subspace tuning(IST)。在MSF阶段,我们首先为多个任务获得优化的软提示,然后通过首先将它们投射到低维子空间,然后用反向投射重建它们来学习一个自动编码器。优化的自动编码器定义了所需的内在子空间。在IST期间,我们只在MSF通过反投影找到的低维子空间中为未见过的数据和任务训练少数自由参数。
令人惊讶的是,我们发现内在的任务子空间可能不仅存在,而且维度极低。我们研究了不同的few-shot NLP任务,发现在一个由100个随机任务用MSF找到的5维子空间中,对于100个看过的任务(使用不同的训练数据)和20个未看过的任务,我们可以用IST分别恢复87%和65%的完整PT性能。此外,我们研究了IPT在不同任务类型以及训练任务和数据数量下的有效性。我们还表明,发现的内在任务子空间和IPT有一些实际用途,如分析任务差异和提高提示调谐稳定性。我们鼓励未来的工作探索如何更好地找到内在任务子空间,并从PLM适应性的低维重新参数化中获得灵感,开发先进的技术。
Related Work
PLM, Fine-tuning and Prompt tuning.
随着BERT以来的成功(Devlin等,2019),预训练的语言模型(Radford等,2018;Yang等,2019;Liu等,2019;Raffel等,2019)给NLP带来了新的范式,即预训练一个大规模的模型作为通用骨干,然后将PLM适应特定的下游任务。下游适应的主流方式是微调,即增加特定任务的分类头,用下游任务的监督数据调整所有PLM参数。
最近,研究人员发现,通过将下游任务铸造成预训练任务的形式,并在输入中加入一些提示标记,包括人类设计的可解释提示(Brown等人,2020;Schick和Schütze,2021a,b;Han等人,2021b;Ding等人,2021;Hu等人,2021)和自动搜索的提示(Jiang等人,2020;Shin等人,2020;Gao等人,2021),也可以取得很好的效果。按照这一研究思路,提示被从词汇表中的标记扩展到可训练的嵌入,即软提示(Li and Liang, 2021; Hambardzumyan et al., 2021; Zhong et al., 2021; Qin and Eisner, 2021; Liu et al., 2021b; Lester et al., 2021)。此外,一些工作(Li and Liang, 2021; Qin and Eisner, 2021; Lester et al., 2021)证明,只有调整软提示并保持PLM参数冻结,才能在各种任务中取得良好的表现。特别是,Lester等人(2021)表明,随着PLM规模的增长,提示调整和微调之间的差距越来越小,最后消失了。
在这项工作中,我们试图朝着解开这些现象的方向迈出一步,即PLM如何能够学习通用能力,以适应各种任务的少量数据和可调整的参数。
Intrinsic Dimensionality
本质维度(ID)是表示某些数据或近似函数所需的最小变量数。Li等人(2018)提出通过将神经网络的所有可训练参数随机投射到线性子空间来测量神经网络优化的目标函数的ID,并找到满意的解决方案(如可以达到90%的性能)出现的最小尺寸。在此之后,Aghajanyan等人(2021)表明,PLM微调在许多NLP任务上的ID可以低于数千,而且预训练隐含地优化了下游任务的ID,这也是这项工作的动机。他们的方法中使用的随机线性投影不涉及生成低维子空间的任何额外训练,因此,在子空间中成功找到解决方案为有效的低维重参数化的存在提供了充分的证据。
随机线性投影不可避免地引入了多余的任务相关信息,并使生成的子空间在重新参数化任务适应方面不紧凑。考虑到存在性已经给出,而我们要研究的假设是低维子空间是否是普遍的,我们采用更强的子空间寻找方法,并使用来自不同下游任务的监督来训练适应性参数的非线性低维分解。
Unifying Different NLP Tasks.
尽管各种NLP任务在表面上差别很大,但长期以来,人们一直试图将不同的NLP任务统一为相同的形式(Sun等人,2021),从而用类似的技术来处理它们,特别是在提示方法(Liu等人,2021a)成功地将各种任务投向PLM的预训练任务的形式之后。本文的分析可能有助于我们理解如何能做到这一点,以及如何从内在任务子空间的角度更好地统一不同的任务。
Methodology
我们首先在第3.1节中介绍了微调和软提示调谐的基本前提,然后在第3.2节中介绍了我们提出的分析管道本征提示调谐(IPT),包括两个训练阶段。(1)多任务子空间查找(MSF)和(2)内在子空间调整(IST)。在图2中,我们将微调、提示调谐和我们的IPT的范式可视化。
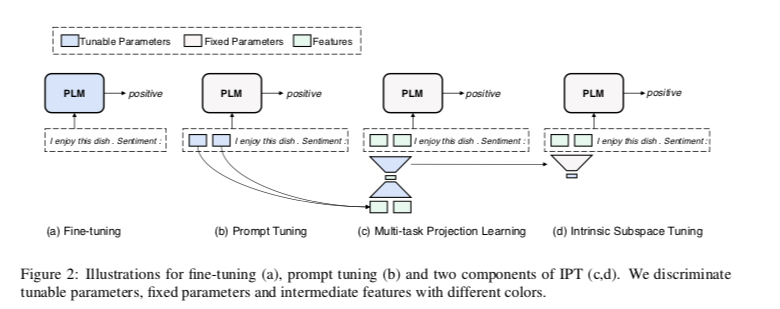
Preliminaries
假设我们得到一系列 NLP任务 ${T1, T_2, …, T{|T|}}$,在不丧失一般性的情况下,按照Raffel等人(2019)的做法,我们假设每个任务 $Ti$ 都被投射为统一格式的条件生成。$T_i = {X_i, Y_i}$ 其中输入 $X_i$ 和目标 $Y_i$都由一系列token组成,$X_i = {w_1,w_2,…,w{|X|}}$, $Yi = {y_1,y_2,…,y{|Yi|}}$ 。目标是学习一个映射函数 $F:X_i→Y_i$,事实上的方法是用PLM $M$ 对 $F$ 进行建模,它首先将输入$X_i = {w_1, w_2, …, w{|Xi|}}$转换为嵌入$E_i = {w_1, w_2, …, w{|Xi|}}∈R^{|X_i|\times d}$,其中去掉了隐藏的大小,然后将 $E_i$ 编码为隐藏的表示 $H_i = {h_1, h_2, …, h{|X_i|}}∈R^{|Xi|×d}$,最后以 $H_i$ 为条件对 $Y_i$进行解码。 目标是优化以下目标:
在传统的微调中,$M$ 的所有参数($θM$)都参与了优化。最近,及时调谐(Lester等人,2021年)作为一种有效的替代方法出现了,它的调谐参数非常少。是一种有效的替代方法,其可调谐的参数非常少。从形式上看,提示调谐通过在 $H_i$之前添加一系列由 $θ_P$ 参数化的可调谐向量 $P_i = {p_1, p_2, …, p_n}$,将额外的信息引入输入$X_i$,即修改后的输入嵌入 $E* = {p_1,p_2,…,p_n;w_1,w_2,…,w{|X_i|} }\in R^{n+|X_i|\times d} $。在提示调谐过程中,$θ_M$保持固定,只有 $θ_P$被更新,满足 $|θ_P| = n\times d << |\theta_M|$的条件。
Intrinsic Prompt Tuning
为了验证我们的假设,即PLM对各种下游任务的适应可以被重新参数化为低维内在任务子空间内的优化,我们提出了一个名为内在提示调谐(IPT)的两阶段管道。第一阶段是多任务子空间寻找(MSF),旨在寻找具有多任务 prompts 的内在任务子空间,这些 prompts 是由一个具有投影函数和反投影函数的自动编码器定义的。第二个内在子空间调整(IST)阶段是只在子空间中调整参数,然后用反投影函数将其恢复到 soft prompts 中。
Multi-task Subspace Finding
在MSF期间,我们试图通过学习矩阵 $P_i\in R^{n×d}$的分解,找到一个低维度 $d_I$ 的令人满意的内在任务子空间,这是下游任务 $T_i$ 的训练 soft-prompt。受文本自动编码器的启发(Bowman等人,2016),该分解包括一个投影函数 $Proj(-)$将$P_i$投射到 $d_I$维的子空间,以及一个反投影函数$Proj_b(-)$将 $d_I$ 维的向量投射回 soft-prompt 中以处理 $T_i$,我们重建 $P_i$如下:
其中,$Proj(-)$用单层FFN实现,$Projb(-)$用两层感知器实现,参数如下:
其中 $W1\in R^{d’_I\times d_I}, b_1\in R^{d_I’},W_2\in R^{N\times d\times d’_I}, b_2\in R^{n\times d}$ 是可训练的参数。此外,为某项任务的 prompt $P_i$ 找到分解,本质上是一个矩阵,这在某种程度上是微不足道的。由于我们想在MSF中找到的理想的内在任务子空间应该适用于广泛的任务,所以我们引入了多任务训练,同时将训练任务的重构 soft-prompt 的任务导向语言建模损失 $L{LM}$作为目标函数。通过联合优化重建损失和面向任务的损失,子空间可以获得重新参数化各种任务适应的能力。MSF的总体训练目标显示如下:
其中 $α$ 表示控制两个损失之间比例的超参数,$θ_{proj}$表示 $Proj$ 和 $Proj_b$的参数。在MSF期间,我们只对 Proj 和 Projb 进行优化,而对其他参数保持固定。通过引入下游任务监督和非线性,我们可以有效地找到比随机线性子空间更多的不冗余和更强的子空间。
Intrinsic Subspace Tuning.
在这个阶段,我们要评估MSF找到的子空间是否可以推广到未见过的训练数据或未见过的任务。如果答案是肯定的,我们可以说,我们成功地找到了内在的任务子空间,在一定程度上重新参数化了PLM对各种任务的适应性。具体来说,我们只保留在MSF期间学到的Projb,并保持 Projb 和 M 都是固定的,然后对于每个任务,我们不进行香草prompt tuning,而只tune 子空间中的 $d_I$ 自由参数($θ_d$),并将 $d_I$ 参数与 Projb 投影到 soft-prompt 中,目标函数可以表述为:
Experiment and Analysis
在本节中,我们首先在第4.1节中描述了实验设置,包括任务和相应的数据集、评价指标和本文的训练细节。然后,我们在第4.2节和第4.3节介绍实验结果和分析。
Experimental Settings
Tasks and Datasets. 为了在实验中覆盖广泛而多样的NLP任务,我们从CrossFit Gym(Ye等人,2021年)的数据库中随机选择了各种各样的 few-shot NLP任务T(共120个)。few-shot 的设置确保了各种任务的数据规模是平衡的,因此MSF发现的子空间不会轻易偏向数据丰富的任务。
简单介绍一下,CrossFit Gym由各种类型的少数NLP任务组成,包括文本分类(如情感分析和自然语言推理)、问题回答(如机器阅读理解和多选题回答)、条件生成(如总结和对话)等等。如第3.1节所述,所有任务都按照Raffel等人(2019)和Khashabi等人(2020)的做法处理成统一的序列到序列的格式,以便于用统一的文本到文本的PLM处理它们。例如,一个多选QA任务的输入被表述为: $Question:
Evaluation Metrics. 由于不同的任务有不同的评估协议(例如,通常判别性任务的F1分数和生成性任务的BLEU),我们引入平均绝对性能($E{abs}$)和平均相对性能($E{rel}$)作为主要评估指标。具体来说,让$T = {T1, …, T{|T|}}$是要评估的任务,让 $E{T_i}$ 表示 $T_i$ 对 IPT 的测试得分, $E{abs} =\frac{1}{T}\sum{T_i\in T} E{Ti} , E{rel} = \frac{1}{|T|} \sum{T_i\in T} \frac{E{Ti}}{E^*{Ti}}$ ,其中 $E^*{Ti}$ 定义为 prompt tuning$E{Ti}^{PT}$或微调 $E{Ti}^{FT}$后的性能。在本文中。我们使用 $E{rel}$作为主要评价标准,选择 $E{abs} $作为辅助标准。为了正确评估IPT实现的泛化能力,我们从T中随机抽取训练任务 $T{train}$ 和测试任务$T{test}$,满足 $T{Train} \cap T_{test} = ∅$。
在多任务子空间查找(MSF)阶段,PLMs只在 $T{train}$ 上进行训练,我们在 $T{train}$ 上评估 $E{abs}$ 和 $E{rel}$,看看重建压缩到 $dI $维子空间的提示会损失多少性能,这将为泛化到未见过的数据和任务提供一个经验上界。我们还用在MSF中学到的自动编码器重新构建 $T{test}$ 的训练过的 soft-prompt,并测试其性能,以研究学到的自动编码器对未见过的 soft-prompt 的重建能力。
对于本征子空间调谐(IST)阶段,我们 首先对 $T{train}$ 进行IST,使用与MSF中使用的 $D^i{train} /D^i_{dev}$完全相同的方法,研究只在子空间中进行优化可以在多大程度上恢复性能。
之后,我们通过两个泛化挑战来评估IPT的泛化能力,看对各种任务的适应是否在很大程度上被重新参数化为所发现的子空间。(1) 未见过的数据挑战和 (2) 未见过的任务挑战。
- 对于未见过的数据挑战,我们在 $T{train}$ 上进行IST,使用不同的K-shot $D^{i’}{train}/D^{i’}{dev}$ 训练数据进行重新采样,同时保持 $D^i{test}$ 保持不变。注意 $D^{i’}{train}/D^{i’}{dev} $ 和 $D^i{train}/D^{i}{dev}$ 形成的,符合i.i.d.假设。未见过的数据挑战是为了测试所学的子空间是否能推广到未见过的数据,这将导致不同的优化轨迹。
- 对于未见过的任务挑战,我们对通过IPT在 $T_{test}$上获得的 soft-prompt 进行评估,看看在发现的子空间中的优化能在多大程度上恢复PLM对未见过的任务的适应性,这将为我们的假设提供证据,即PLM的不同任务适应性的重新参数化子空间并不独立。
Main Results
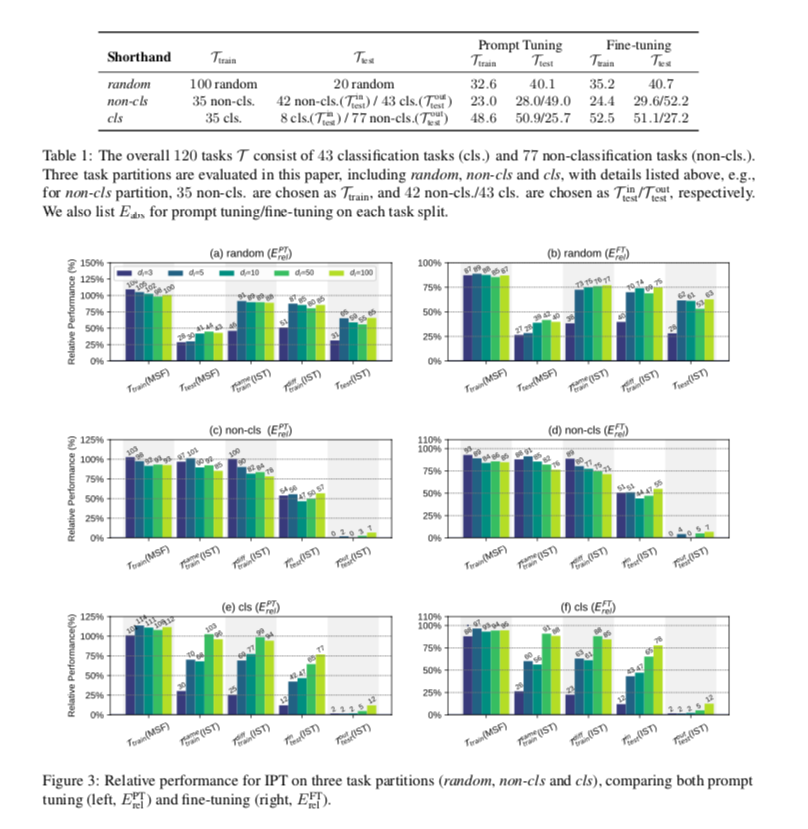
评估了三种任务拆分:随机、非cls和cls,详情列于表1。实验结果显示在图3($E{rel}$)、表2($E{abs}$)和表3($E{abs}$)。如前所述,我们选择 $E{rel}$ 作为分析的主要标准。基于这些结果,我们研究了以下研究问题。
Q1. PLM是否真的将各种任务适应性重新参数化,使之成为一个低维的任务子空间?
从图3(a)的结果,我们可以看到。(1)对于未见过的数据挑战($T{train}^{diff}(IST)$),选择 训练 dI ≥ 5可以恢复80%以上的全 对于100个训练任务,在未见过的独立数据上使用IST的 prompt tuning 性能,可以恢复80%以上。 (2)对于未见过的任务挑战($T{test}(IST)$),我们只需调整5∼100个参数,也可以达到约60%的性能。从这些结果来看,我们可以说MSF发现的子空间中的低维重新参数化成功地恢复了 $T_{train}$ 的PLM适应性,并且在一定程度上也可以推广到未见过的任务,因此只需在这些子空间中调整几个自由参数就可以实现非微不足道的性能。
这为我们的假设提供了证据,即PLM将各种任务适应性重新参数化为同一个低维子空间,或者至少各种任务适应性的低维重新参数化子空间(Aghajanyan等人,2021)应该有一个实质性的交集,否则 $T{train}$发现的子空间对 $T{test}$来说几乎不可能起作用。
此外,在随机拆分中,我们可以看到,当 dI≥5 时,$T{train}^{diff}(IST)$和 $T{test}(IST)$ 的 $E^{(PT)}_{rel}$总是在同一水平上,这表明内在任务子空间的维度应该在 5 左右,这对于有上亿个参数的PLM来说是非常低的。
Q2. What limits IPT?
虽然观察到了积极的证据,但考虑到对于未见过的任务只能恢复60%左右的表现,IPT的有效性仍然有限。从图3(a)和(b)的结果中,我们讨论了哪些因素可能会限制IPT的有效性,并为改进分析管道提供见解。
- 当我们使用MSF的自动编码器($T{train}(MSF)$)直接重建软提示时,Ttrain的性能甚至优于虚构的 soft-prompt tuning,这表明:(1)MSF的管道可以通过在极低的维度上强制执行多任务技能共享来帮助改善 soft-prompt 的调谐。极低的维度,和 (2) 在子空间中至少存在足够好的解决方案,这些解决方案是由MSF找到的。足够好的解决方案,这些解决方案已经被MSF发现。然而,即使使用完全相同的训练数据,IST也不能找到这些好的解决方案,从而导致 $T{train}(MSF)$ 和 $T_{train}^{same}(IST)$之间的差距,这表明所采用的优化算法的局限性会影响IST的性能。
- 从 $T{train}(MSF)$ 和 $T{test}(MSF)$ 的比较中,我们可以看出,直接重建未见过的任务的 soft prompt 的性能很差。这表明在MSF中训练的自动编码器的重构能力不能很好地推广到未见过的输入(soft-prompt),这可能在一定程度上限制了IPT。尽管如此,IST仍然可以在MSF找到的子空间内找到更好的解决方案。
- 从图3(a)和(b)的结果比较中,我们可以看到,fine-tuning( $E^{FT}{rel}$)的相对性能总是比 prompt tuning($E^{PT}{rel}$)要差。这是因为 soft prompt 略逊于 few-shot 设置下的微调,而IPT的性能受 soft prompt 调谐的约束,因为MSF被设计为重构 soft prompt。理想情况下,$E^{FT}_{rel}$可以通过设计更先进的 prompt tuning算法来进一步改进。
Q3. How is the influence of task types?
按照CrossFit(Ye et al. 研究的任务分为两部分:cls(分类)。属于判别性任务,而Non-cls(非 分类),它们往往是生成性任务。从图3(c)-(f)的结果中,我们发现。与常识一致,它们之间存在着巨大的 它们之间的差异。(1) 在分类任务和非分类任务之间存在着巨大的概括性差距。当在MSF中只使用一种任务(cls或non-cls)时,发现的子空间对同种任务($T^{in}{test} (IST)$)工作良好,但对其他种类的任务($T^{out}{test}(IST)$)的概括性很差。(2) 当增加d时,非cls任务(图3(c)和(d))在所有设置中的表现趋于下降,但cls表现(图3(e)和(f))趋于增加。合理地讲,对于各种NLP任务来说,理想的内在子空间维度设置至少应该达到一个阈值(内在维度),以确保子空间可以被大幅描述,但也不应该太大,因为这可能导致过度参数化。因此,我们认为这表明,尽管是反直觉的,但对于非cls任务来说,最合适的内在子空间维度要远远小于cls任务。我们假设这可能来自于 few-shot 的设置,并将在未来进行探索。
Analyses and Properties
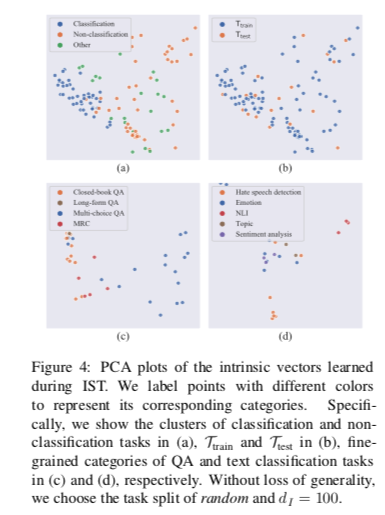
Visualization of the Found Intrinsic Subspace 我们在图4中用PCA可视化了内在向量(由IST在发现的子空间中学习的自由参数组成的向量),从中我们可以看到:(1)分类任务群和非分类任务群之间存在着明显的分界线,表明它们是高度独立的,这与常识是一致的。这也解释了为什么在任何一个簇上学到的子空间对另一个簇的概括性很差。(2)未见过的任务 $T{test}$ 的点与 $T{train}$的点混合在一起,这表明发现的子空间普遍地对各种任务进行了重新参数化,因此PLM可以泛化到未见过的任务。(3) 从(c)和(d)中还可以看出,属于同一类别的点呈现出紧凑的集群。我们认为,学到的内在向量可以被看作是低维的任务表征,有助于分析各种NLP任务的相似性和差异性。
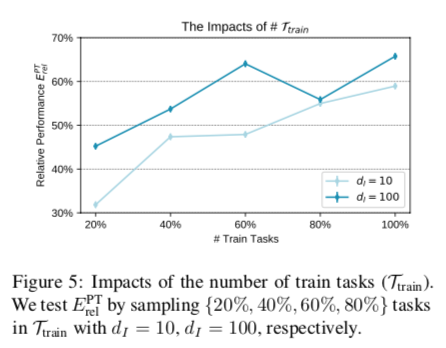
Impacts of the Number of Training Tasks.
在MSF期间,自动编码器被优化,以重建各种训练任务的适应性参数,将其重新参数化为低维任务子空间。理想情况下,$T{train}$的覆盖率会大大影响IPT在未见任务 $T{test}$ 上的泛化能力。为了证明这一点,我们随机选择任务分区,在原始 $T{train}$中只随机抽取 {20%、40%、60%、80%} 的任务来训练自动编码器,然后在相同的 $T{test}$上评估未见过的任务挑战。结果如图5所示,从图中我们可以看出,随着训练任务数量的增加,发现的任务子空间的泛化能力普遍提高。这反映出,增加所见任务的覆盖面和多样性可以帮助IPT找到更多的通用子空间。
Impacts of the Number of Shots 虽然在本文中,我们主要研究的是 few-shot 的设置,以控制数据量的影响,但研究当有更多的训练数据时,IPT的能力是否会更强,也是很有意思的。在这里,我们通过将任务分区cls的 few-shot 增加一倍来进行初始试验,并进行实验,看看MSF和IST在T上的性能($E^{PT}_{rel }$)。注意计算EPT时,K-shot和2K-shot实验的分母是不同的。
结果在图6中得到了体现。从中我们可以看到,在2K拍摄的情况下,MSF 和 IST 之间的差距在 2K-shot 设置中迅速缩小 当dI增长时,MSF和IST之间的差距迅速缩小,而在K-shot设置中则明显放缓。而在K-shot设置中则明显缓慢。这表明,涉及更多的监督可能有利于IST的优化。我们还发现,当增加dI时,2K-shot的$T^{same}_{ train}$ 增长非常接近100%,但从来没有超过它,这表明当有更多的数据可用时,联合重建多个任务的提示不会带来额外的好处,因为在K-shot设置中观察到。一般来说,我们认为探索IPT在数据丰富的情况下发现的子空间会有多强是很有意义的。
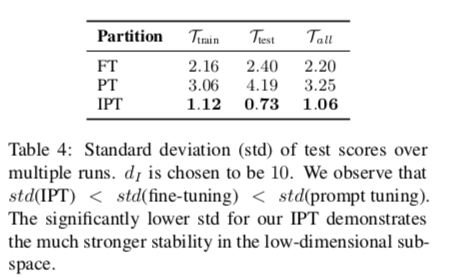
Improving Prompt Tuning Stability with IPT 在表4中,我们显示了在10次运行中120个任务的测试分数的平均标准偏差(std),比较了IPT(dI=10)、微调和及时调整。我们观察到,prompt tuning是最不稳定的策略,具有最高的标准,而精调则表现得更为稳定。soft prompt tuning的不稳定性可能会影响这一技术的实际使用。直观地说,IPT试图找到低维的内在子空间,只用几个自由参数来学习新任务,这将有助于提高稳定性,IPT肯定会成为表4中最稳定的方法。
为了使IPT带来的稳定性优势实用化,我们建议使用IPT找到的解决方案作为香草 prompt tuning的初始化。具体来说,我们在 $T_{test}$上继续进行随机分区的实验,选择 $d_I=10$,并通过在IST期间在子空间中反推来初始化软提示。在IST期间在子空间中找到的解决方案进行初始化。与 prompt tuning 基线相比,其他细节保持不变。
我们观察到,以这种方式实现的标准方差明显低于香草 prompt tuning(1.65 v.s. 4.19) 而在这种方式下,我们可以实现103.4%的EPT,也就是说,性能也可以从59%(IST)提高。这表明,IPT和 prompt tuning可以进一步以两阶段的方式结合。这个实验还表明,尽管我们的IPT管道在本文中主要作为一个分析框架,但它也能带来实际的好处。我们将在未来探索IPT的更多实际用途。
Discussion
NLP任务是否可以被重新参数化到同一个子空间?
在本文中,我们发现了强有力的证据,通过压缩各种任务的适应性参数与下游监督,我们有可能找到一个极低维的子空间,其中包含次优但非琐碎的解决方案,以适应PLM的未见任务。尽管在MSF期间 $E^{PT}_{rel}$超过了100%,但我们注意到在IST期间,对看到的和未看到的任务的概括仍然远非完美(87%对EPT的65%),而且增加 $d_I $并没有明显改善性能。
尽管这可能与目前优化算法的不足有关,但基于目前的结果,我们不能直接得出结论,PLM的各种NLP任务改编可以在完全相同的子空间内进行重新参数化优化。然而,至少我们找到了有希望的经验结果,表明各种任务的低维重新参数化子空间有很大的交集,这可以通过MSF找到。而在这个交集子空间进行IST可以恢复每个任务的大部分性能。因此,我们鼓励未来的工作探索(1)是否存在在极低维的子空间中进行IST的更高效和有效的优化算法,以及(2)各种任务的内在子空间的联合是否也是低维的。
此外,还应该注意的是,通过IPT实现的极低维度(约5∼100)不应该被完全视为Aghajanyan等人(2021)和Li等人(2018)的内在维度,因为内在维度应该确保整个训练过程可以在该低维度上完成。用IPT实现的维度有可能作为内在维度的一个粗略下限。
Relation to the scaling law. 最近,越来越多关于规模力量的案例被展示出来。人们发现,极其庞大的PLM往往更具有样本效率(Kaplan等人,2020年)、参数效率(Lester等人,2021年)和跨任务的可概括性(Wei等人,2021年)。我们认为这可以用本文的假设来解释:更大的或训练得更好的PLM的适应性可以更好地重新参数化到相同的低维子空间,这样跨任务的泛化应该更容易,更好的预训练带来更低的重新参数化尺寸(Aghajanyan等人,2021),因此更大的PLM应该需要更少的数据和可调整参数。
如果这个假设成立,我们认为应该开发类似于IPT的调整方法。较大的PLM提供了更强大的压缩框架,我们可以找到低维的内在任务子空间,并在这些子空间中训练各种下游任务,这将避免过度参数化造成的不稳定和巨大的泛化差距,而且对环境也更环保。
Conclusion and Future work
在本文中,我们研究了这样一个假设:PLM对各种任务的适应性可以被重新参数化为同一低维内在任务子空间中的几个自由参数的优化。我们开发了一个名为IPT的分析管道,它首先通过联合压缩多个任务的适应性参数找到一个子空间,然后只在子空间中对未见过的数据和任务进行参数调整。IPT在极低维度上取得的非微妙的表现为该假设提供了积极的证据。我们还讨论了影响结果的因素和IPT的潜在实际用途。未来,我们将改进IPT框架,以更好地验证普遍的低维重参数化假设,并开发更多的实用技术,在低维子空间进行更有效的优化。
 wechat
wechat alipay
alipay





