Unsupervised Domain Adaptation of a Pretrained Cross-Lingual Language Model
Unsupervised Domain Adaptation of a Pretrained Cross-Lingual Language Model
最近的研究表明,在大规模的无标签文本上预训练跨语言语言模型,可以在各种跨语言和低资源任务中产生明显的性能改进。通过对一百种语言和TB级文本的训练,跨语言模型已被证明能有效地利用高资源语言来提高低资源语言的处理能力,并超过了单语言模型。在本文中,我们进一步研究了当预训练的跨语言模型需要适应新领域时的跨语言和跨领域(CLCD)设置。具体来说,我们提出了一种新的无监督的特征分解方法,该方法可以从纠缠在一起的预训练的跨语言表征中自动提取特定领域的特征和领域不变的特征,给定源语言中未标记的原始文本。我们提出的模型利用相互信息估计,将跨语言模型计算的表征分解为领域变量和领域特定部分。实验结果表明,我们提出的方法比最先进的预训练的跨语言模型在CLCD环境中取得了明显的性能改进。本文的源代码可在https://github.com/lijuntaopku/UFD。
Introduction
深度学习的最新进展使各种NLP任务受益,并在大规模注释数据集可用时导致性能的显著改善。对于高资源语言,例如英语,许多任务收集足够的标记数据来建立深度神经模型是可行的。然而,对于许多语言来说,在大多数情况下可能不存在足够的数据来充分利用深度神经模型的进步。因此,人们提出了各种跨语言迁移学习方法,以利用高资源语言的标记数据来构建低资源语言的深度模型[Kim等人,2019;Lin等人,2019;He等人,2019;Vulic ́等人,2019]。尽管如此,大多数跨语言迁移学习研究的重点是减轻语言的歧视,而对领域差距的探索较少。在这项研究中,我们专注于一个更具挑战性的环境,即跨语言和跨领域(CLCD)转移,其中源语言的领域内标签数据不可用。
传统上,跨语言方法主要依靠从数据中提取语言不变的特征,将从源语言学到的知识转移到目标语言中。一种直接的方法是权重共享,它通过事先将输入文本映射到一个共享的嵌入空间,直接将在源语言上训练的模型参数重用到目标语言。然而,之前的重新搜索[Chen等人,2018]显示,权重共享不足以提取语言不变的特征,而这些特征可以在不同的语言中很好地通用。因此,我们提出了一种语言对抗训练策略,利用每种语言的非平行无标签文本,提取跨语言的不变特征。这样的策略在双语转换环境中表现良好,但不适合从多种语言中提取语言不变量特征,因为所有源语言共享的特征可能过于稀疏,无法保留有用的信息。
最近,规模化的预训练跨语言模型,例如多语言的BERT[Devlin等人,2019]和XLM[Conneau和Lample,2019;Conneau等人,2019],在各种跨语言任务中表现出非常有竞争力的性能,甚至在低资源语言上超过了预训练的单语言模型。通过采用平行文本(未为任何特定任务标记)和所有语言共享的子词词汇,这些预训练的跨语言模型可以有效地将来自多种语言的输入文本编码到一个单一的表示空间,这是一个由多种语言(超过一百种)共享的特征空间。虽然在提取语言不变的特征方面有很好的通用性,但跨语言的预训练方法在提取领域不变的特征方面没有具体的策略。在我们的CLCD设置中,语言不变量和领域不变量的特征都需要被提取。
为了解决上述跨语言预训练模型[Conneau等,2019]在CLCD场景中的局限性,我们提出了一种无监督的特征分解(UFD)方法,它只利用源语言中的未标记数据。具体来说,我们提出的方法受到最近提出的无监督表示学习方法[Hjelm等人,2019]的启发,通过结合互信息最大化和最小化,可以同时提取领域不变的特征和领域特定的特征。与以往的跨语言迁移学习方法相比,我们提出的模型保持了跨语言预训练模型的优点,即对百余种语言具有良好的泛化能力,并且只需要源语言中的未标记数据进行领域适应,适用于更多的跨语言迁移场景。
我们在一个基准的跨语言感官分类数据集上评估了我们的模型,即亚马逊评论[Pretten- hofer and Stein, 2010],它涉及多种语言和领域。实验结果表明,随着预训练的XLM跨语言模型的增强,我们提出的UFD模型(在源语言的一些未标记的原始文本上训练)和一个简单的Lin-ear分类器(在源语言和源领域的小型标记数据集上训练)胜过那些能够获得强大的跨语言监督(如商业MT系统)或多尖端源语言的标记数据集的最先进模型。此外,将我们提出的UFD策略与源语言中未标记的15万个实例集结合起来,可以持续获得超过强大的预训练XLM模型的收益,该模型是在100种语言和TB级文本上训练的。广泛的实验进一步证明,在预训练的跨语言语言模型上的无监督特征分解优于在超过1亿句话上训练的特定领域语言模型。
Model
Problem Definition & Model Overview
在本文中,我们考虑的是这样一种情况:我们只有一个特定语言和特定领域的标记集 $D{s,s}$,我们称之为源语言和源领域,而我们想训练一个分类器,在一个不同语言和不同领域的集合 $D{t,t}$上进行测试,我们称之为目标语言和目标领域。我们还假设在训练阶段可以获得一些未标记的原始数据 $D_{s,u}$,包括源语言的目标域,这在实际应用中通常是可行的。我们称这种设置为无监督的跨语言和跨领域(CLCD)适应。
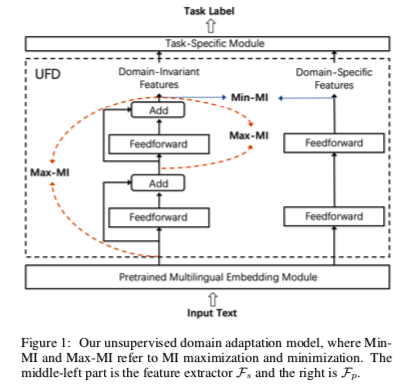
如图1所示,建议的方法由三个部分组成:一个预训练的多语言嵌入模块,将输入文档嵌入到语言不变的表示中;一个无监督特征分解(UFD)模块,从纠缠的语言不变的表示中提取领域不变的特征和特定领域的特征;以及一个根据提取的领域不变的特征和特定领域特征训练的特定任务模块。我们采用XLM1[Conneau and Lample, 2019]作为我们方法中的多语言嵌入模块,它已经被来自各种语言的大规模平行和单语数据预训练过,是目前最先进的跨语言语言模型。我们在下面的小节中描述其他两个模块和训练过程。
在我们的方法中,我们采用了最近提出的神经估计方法[Belghazi等人,2018],该方法通过训练一个网络工作来估计两个连续随机变量 $X$ 和 $Y$ 的MI,以区分来自它们的联合分布 $J$ 的样本和它们的边际分布的乘积 $M$ ,这种估计利用了基于KL-divergence的Donsker-Varadhan表示(DV)[Donsker和Varadhan,1983]的MI下限。
其中,$Tω$是一个辨别函数,由一个具有可学习参数 $ ω$ 的神经网络作为参数。通过最大化 $\hat I^{DV}$, $Tω$ 被鼓励区分从 $J$ 和 $M$ 中抽取的样本,给前者分配大值,给后者分配小值。
Proposed Method
让 $X∈R^d$ 表示由预训练的多语言嵌入模块生成的语言不变量表示。然后将其作为输入输入到拟议的 UFD模块。
如图1所示,我们引入了两个特征提取器:领域不变的提取器 $F_s$(即左边的ReLU激活的两层前馈网络),以及领域特定的提取器 $F_p$(即右边的两层网络)。我们把提取的特征分别表示为 $F_s(X)$ 和 $F_p(X)$。请注意,对于 $F_s$,我们增加了剩余连接,以更好地保持 $X$ 的领域不变属性。
具体来说,$F_s$ 旨在以无监督的方式从语言不变量的表述中提取领域不变量的特征。由于多语言嵌入模块是在超过一百种语言的开放领域数据集上进行预训练的,因此可以推测,生成的语言不变量表示应该包含某些可以跨领域泛化的属性。
当 $F_s$ 在多个领域接受训练,每个领域的输入和输出之间的 $MI$ 共同最大化时,鼓励它从语言不变的表征中保留这些领域之间的共享特征。通过这种方式,$F_s$ 被迫将领域不变的信息从 $X$ 传递给 $F_s(X)$。
我们利用方程(1)中提出的基于神经网络的估计器来计算MI。在我们的案例中,由于 $F_s(X)$依赖于 $X$ ,我们可以将基于DV-based 的MI估计器简化为Jensen-Shannon MI估计器,正如[Hjelm等人,2019]中建议的那样:
其中 x 是一个具有经验概率分布 P 的输入嵌入。由于 $F_s(x)$ 是直接从 $x$ 计算出来的,$(x, F_s(x))$ 可以被视为从 $x$ 和 $F_s(x)$ 的联合分布中抽取的样本。$x’$ 对应于来自 $\hat P=P$的输入嵌入,即 $x$ 是从同一输入分布中抽取的随机样本计算出来的,这样 $(x’,F_s(x))$ 就是从边际分布的乘积中抽取的。$sp(z) = log(1+e^z)$ 是 softplus 激活函数。$F_s$ 的训练目标是使 $X$ 和 $F_s (X )$上的MI最大化,损失表述如下:
其中 $ω_s$ 表示估计器中的辨别网络工作的参数,$ψ_s$表示 $F_s$ 的参数。为了便于学习领域不变的特征,我们还提出对 $F_s(X)$和相应的中间表示(第一层输出) $F’_s(X )$ 的MI最大化,训练损失如下:
其中 $ω_r$ 表示估计器中判别器网络的参数。回顾一下,$F_p$ 的目标是提取特定领域的特征,这应该是排他性的,并且独立于领域的不变量特征。我们建议最小化由 $F_s$ 和 $F_p$ 提取的特征之间的 $MI$,训练损失表述如下:
其中 $ψ_p$ 表示 $F_p$ 的参数。 $ω_p$ 表示MI估计器中歧视网络的参数。
因此,拟议的UFD组件的训练目标是使整体损失最小化,具体如下:
其中,α、β和γ是用于平衡次损失影响的超参数。
Task-Specific Module
在特定任务模块中,我们首先采用一个线性层,将 $R^{2d}$ 中的领域不变特征和领域特定特征的串联映射为 $R^d$中的矢量表示。然后,在这个映射的向量表示上采用一个简单的前馈层,用softmax激活来输出任务标签。我们在 $D_{s,s}$上训练这个模块,交叉熵损失表示为 $L_t$,作为训练目标。
Training
请注意,多语言嵌入模块的参数是经过预训练的,并且在整个训练过程中被设定为冻结。我们首先优化UFD的参数,即{ωs,ωr,ωp,ψs,ψp},通过最小化无标签集Ds,u上的LUFD。一旦UFD模块训练完成,我们就固定其参数,并通过在有标签的集合Ds,s上最小化Lt来训练特定任务的模块。
 wechat
wechat alipay
alipay





