On Transferability of Prompt Tuning for Natural Language Understanding
On Transferability of Prompt Tuning for Natural Language Understanding
Prompt tuning(PT)是一种很有前途的参数高效方法,可以利用极其庞大的预训练语言模型(PLM),只需 tuning 几个软提示,就可以达到与全参数微调相当的性能。
然而,与微调相比,经验上PT需要更多的训练步骤。为了探索是否可以通过重复使用训练好的 soft prompts 和分享学到的知识来提高 PT 的效率,我们从经验上研究了 soft prompts 在不同任务和模型中的可迁移性。
- 在跨任务迁移中,发现经过训练的 soft prompts 可以很好地迁移到类似的任务中,并为它们初始化PT,以加速训练和提高性能。此外,为了探索哪些因素会影响 prompts 的跨任务转移性,我们研究了如何测量 prompt 的相似性,发现激活的神经元的重叠率与迁移性高度相关。
- 在跨模型迁移中,我们探索了如何将一个PLM的 prompt 投射到另一个PLM上,并成功地训练了一种 projector,该projector 可以在类似的任务上实现非微不足道的迁移性能。然而,用投影的 prompt 初始化PT的效果并不好,这可能是由优化偏好和PLM的高冗余度造成的。
我们的研究结果表明,用知识转移来改善PT是可能的,也是有希望的,而提示的跨任务迁移性一般比跨模型转移性好。
Introduction
预训练的语言模型(PLM),如BERT(Devlin等人,2019)和GPT(Radford等人,2018)在各种自然语言处理任务上取得了很好的性能(Han等人,2021)。最近,在GPT-3(Brown等人,2020)取得成功后,人们发现极大型的PLM可以取得显著的自然语言理解(NLU)性能,各种大型PLM不断被开发出来(Raffel等人,2020;Zhang等人,2021;Zeng等人,2021;Wei等人,2021;Sun等人,2021),它们包含的参数多达数千亿。
考虑到这些最先进的PLMs的极大规模,传统的全参数微调方法使PLMs适应下游任务,在计算上变得难以承受。因此,各种参数高效的调谐方法(Houlsby等人,2019;Ben Zaken等人,2021;Lester等人,2021;Li和Liang,2021;Liu等人,2021)得到了探索,其中prompt-tuning(PT)引起了广泛的研究关注。
PT将一些 soft-prompt(本质上是可学习的虚拟 token)预置到输入序列中,并通过反向传播训练它们,同时保持所有PLM参数的固定。训练的目的是输出表示相应标签的 token,即标签 token。PT仅用数千个可调整的参数就可以实现卓越的NLU性能。
此外,Lester等人(2021)表明,当PLM的规模增长时,PT变得更加有效,当PLM有数十亿个参数时,最终可以达到与全参数微调相当的性能。
尽管PT是利用极其庞大的PLM的有效方法,但它需要比微调多得多的训练步骤来达到收敛(参考3.1节),因此值得探讨如何提高PT的效率。直观地说,由于 soft prompt 是PT中唯一可学习的参数,代表了以PLM为条件解决任务的特定知识,一个任务的训练提示可能对其他需要类似知识的任务有帮助。此外,由于不同的PLM都从预训练中学习了一般的语言理解能力,以不同的PLM为条件的训练过的 prompts 可能在PLM之间迁移。
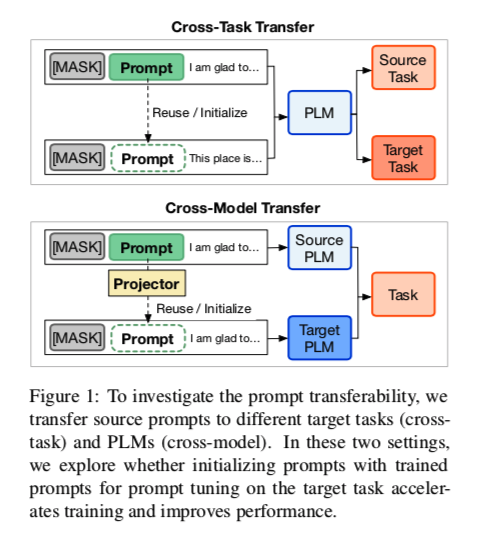
因此,通过训练有素的 soft prompts 将学到的知识迁移到其他任务和PLM上可能是一种有希望的方式,以加速新任务和PLM的PT。为了了解基本特征并帮助开发PT的迁移学习方法,我们在本文中实证分析了PT在不同任务和模型中的可迁移性,如图1所示。
在跨任务迁移中,我们研究在同一PLM上训练的 soft-prompt 是否能在不同的NLU任务中转移。
- (1) 我们研究了 soft prompt 在13个NLU任务上的 zero-shot 迁移性能,这些任务根据所需的语言理解能力被分为四种类型。我们发现,经过训练的 soft prompt 可以直接迁移到同一类型的类似任务中,并取得非同寻常的表现,但迁移到需要不同的NLU能力的不同类型的任务中却很差。
- (2) 基于这些结果,我们提出了跨任务的可转移prompt tuning($TPT{TASK}$),即用类似任务的训练好的 soft prompt作为初始化来启动PT。实验表明,与普通的PT相比,$TPT{TASK}$可以大大加快训练速度,而且还能实现一定的性能提升。
- (3) 我们进一步探讨为什么 prompts 可以跨任务转移,是什么控制了它们的迁移性。为此,我们研究了各种 prompt 相似性指标与prompt 可迁移性的相关性,发现其在PLM前馈层中激活的神经元的重叠率可以更好地反映 prompts 可转移性。
这表明提示实质上是在刺激PLM的内在能力在参数(神经元)之间分配,以完成特定的NLU任务,prompts 之间的可迁移性取决于它们在模型刺激方面的相似性,而不是嵌入的相似性,这可能启发未来PT转移方法的设计。
在跨模型转移中,我们在两种情况下研究软提示在不同PLM中的可转移性。
- (1) 在相同规模的异质PLM之间转移(例如BERTBASE到RoBERTaBASE)
- (2) 从较小的PLM迁移到较大的同质模型(例如RoBERTaBASE到RoBERTaLARGE)。
我们发现,直接在目标PLM上重复使用 prompts 是无益的,这一点在实验中得到了证明,或者是不可行的,这是因为不同尺寸的PLM的嵌入尺寸不一致。
- (1)因此,我们开发了各种 prompt projectors,将在一个PLM上训练的 soft prompt 投射到其他PLM的语义空间中,并发现通过在一些任务上用PT训练 projectors,训练后的 projectors 可以成功地投射出类似任务的软提示,并取得非同寻常的性能。
- (2) 与 $TPT{TASK}$ 类似,我们提出了跨模型的可迁移 prompt tuning($TPT{MODEL}$),即用目标PLM上同一任务的预测 prompt 开始PT。然而,实验表明,$TPT{MODEL}$的效果并不如 $TPT{TASK}$那么好。
- (3) 我们观察到,投射过的 prompts 的激活神经元与最初在目标PLM上训练的 prompt 不相似。考虑到PLM的高冗余度(Aghajanyan等人,2021),这可能表明预测的 prompt 是在目标PLM上完成任务调节的不同解决方案,而PT并不喜欢这些解决方案,并且很难用它们来持续优化。
总的来说,我们的发现和分析表明,通过知识迁移提高PT的效率是可能的,也是有希望的,在不同的PLM之间迁移提示比在同一PLM的不同任务之间转移更具挑战性。我们希望这些发现能够促进对可迁移和高效的PT的进一步研究。
Related Work
Prompt Tuning
在海量数据上预训练PLM(Radford等人,2018;Devlin等人,2018;Yang等人,2019;Liu等人,2019b;Raffel等人,2020),然后将其调整为下游任务,这已经成为NLP的典型范式。传统上,适应是通过面向任务的微调完成的,它通过特定任务的监督优化PLM的所有参数。
然而,随着PLM参数的持续增长,全参数微调对于典型的范式和模型存储都变得难以承受。为了弥补这一缺陷,人们提出了许多参数高效的调谐方法(Ben Zaken等人,2021;Houlsby等人,2019;Li和Liang,2021;Qin和Eisner,2021;Lester等人,2021),这些方法只调整几个参数,而保持大部分PLM参数的冻结。
在这些具有参数效率的微调变体中,prompt tuning 得到了广泛的关注,这是由GPT-3激发的。 它通过在输入文本之前给每个任务预留一个文本提示,并让PLM直接生成答案,从而展示了显著的 few-shot 性能。
最近,出现了许多基于 prompt 的工作,即人工设计的(Schick和Schütze,2021a,b;Mishra等人,2021)或自动搜索的(Jiang等人,2020;Shin等人,2020;Gao等人,2021)硬提示,它们是离散的 token,但不一定是人类可读的。此外,软提示(Li and Liang, 2021; Hambardzumyan et al., 2021; Zhong et al., 2021; Liu et al., 2021)出现了,它们是可调整的嵌入而不是词汇表中的 token,可以直接用特定任务的监督来训练。
而Lester等人(2021)证明,当PLM尺寸极大时,这种 PT 方法可以与全参数微调的性能相匹配。这表明 PT 在利用极大的PLM方面很有前景。然而,达到收敛所需的更多训练步骤(第3.1节)使PT效率低下。在这项工作中,我们表明 prompt迁移可以弥补这一点,也在一定程度上提高了知识转移的有效性,并实证分析了PT在不同任务和模型中的转移性。
Transferring for PLM
跨任务转移,或一般的多任务学习(Ruder,2017)一直是提高NLP系统的有效性和效率的一种长期方式。在PLM时代,一些作品提出在中间任务上调整PLM(Phang等人,2019;Pruksachatkun等人,2020;Gururangan等人,2020;Wang等人,2019a;Vu等人,2020;Poth等人,2021),然后再对具体的目标任务进行微调,并取得一定成效。特别是,Vu等人(2020)在这种情况下实证分析了跨任务的可迁移性。然而,这些探索都是针对微调的。Prompt Tuning(PT)是利用大型PLM的一种有前途的方式,我们认为PT的可转移性和转移方法值得探索。
作为先前的尝试,Lester等人(2021)证明了PT对同一任务的跨域迁移能力强于微调。与我们的工作类似,同时进行的工作(Vu等人,2021)证明了PT的跨任务转移能力,也提出了用提示初始化来进行跨任务迁移。不同的是,我们通过模型刺激的视角进一步分析了 prompt,并通过跨任务迁移提高了PT的效率。此外,我们还尝试了 prompt 的跨模型迁移,这受到了以往跨模型知识迁移工作的启发,如Net2Net(Chen等人,2016)、知识蒸馏(Hinton等人,2015)和知识继承(Qin等人,2021a)。
Preliminary
在这一节中,我们介绍了关于 prompt tuning(PT)的基本知识(§3.1)以及实验中调查的下游任务(§3.2)和模型(§3.3)。
Prompt Tuning
在这项工作中,我们研究了能够调整大型PLM的PT方法(Li and Liang, 2021; Lester et al, 2021; Liu et al, 2021),同时冻结PLM参数。考虑到我们专注于NLU的能力,我们没有探索在生成任务上工作的前缀调谐(Li and Liang, 2021)。
PT直接在PLM的输入中预置一些虚拟 token,即 soft prompt,以提供关于下游任务的知识。soft prompt本质上是可调整的嵌入向量,其训练的目的是强制 PLM 解码表示输入的相应标签的 token,而PLM的模型参数则保持冻结。对应于标签的 token 被称为标签 token。
从形式上讲,给定一个输入序列 $X={x_1,x_2,…,x_n}$,其中 $x_i$ 是 token,我们首先在它们前面预置 $l$ 个随机初始化的软提示 $P={P_1,P_2,…,P_l}$,其中 $P_i\in R_d$是一个嵌入向量,$d$ 是PLM的输入维度。在它们之前,我们先加一个[MASK] token,用来预测标签token $y$。训练目标是使解码 $y$ 的可能性最大化。
而只有P是可学习的。因此,PT中的调整参数比全参数微调要少得多,这对调谐大型PLM很友好。
当使用的PLM非常大时,PT可以达到与微调相当的性能,但当PLM不那么大时,明显的性能差距仍然存在,而且PT也比微调需要更多的内存。
此外,我们根据经验发现,PT的收敛速度明显慢于微调,如图2所示。因此,我们认为PT的效率需要进一步提高,而知识迁移的直观性可能有所帮助。
Investigated NLU Tasks
为了全面研究 soft-prompt 在各种NLU任务中的可迁移性,我们涉及了13个不同的任务,这些任务可以分为4种类型。
(1)情绪分析(SA),包括IMDB(Maas等人,2011)、SST-2(Socher等人,2013)、笔记本电脑(Pontiki等人,2014)、餐厅(Pontiki等人,2014)、电影理由(Movie)(Zaidan等人,2008)和TweetEval(Tweet)(Bar- bieri等人,2020);(2)自然语言推理(NLI),包括MNLI(Williams等人,2018 )、QNLI(Wang等人,2019b)和SNLI(Bow- man等人,2015);(3)伦理判断(EJ),包括deontology(Hendrycks等人,2021)和justice(Hendrycks等人,2021);(4)转述识别(PI),包括QQP(Sharma等人,2019)和MRPC(Dolan and Brockett,2005)。任务的细节、使用的标签令牌和实施方法分别留在附录A.1、附录A.3和附录A.2中。
Investigated Models
为了研究跨模型的可转移性,我们调查了两种PLM。BERT(Devlin等人,2019)和RoBERTa(Liu等人,2019b),它们被广泛用于NLU任务。具体来说,我们在实验中使用RoBERTaBASE、RoBERTaLARGE和BERTBASE检查点。RoBERTaBASE和BERTBASE模型由12个Transformer(Vaswani等人,2017)编码器层组成,它们的嵌入尺寸都是768,而RoBERTaLARGE是24个Transformer层和1024个嵌入尺寸。
Cross-Task Transfer
在这一节中,我们实证研究了 soft-prompt 的跨任务迁移性(第4.1节),并试图通过利用迁移性来提高 prompt tuning的有效性和效率(第4.2节),然后我们通过分析各种 prompts 的相似性指标来探索为什么 prompts可以迁移,是什么控制了prompts之间的转移性(第4.3节)。本节的所有实验都是在RoBERTaBASE上进行的。
Zero-shot Transferability
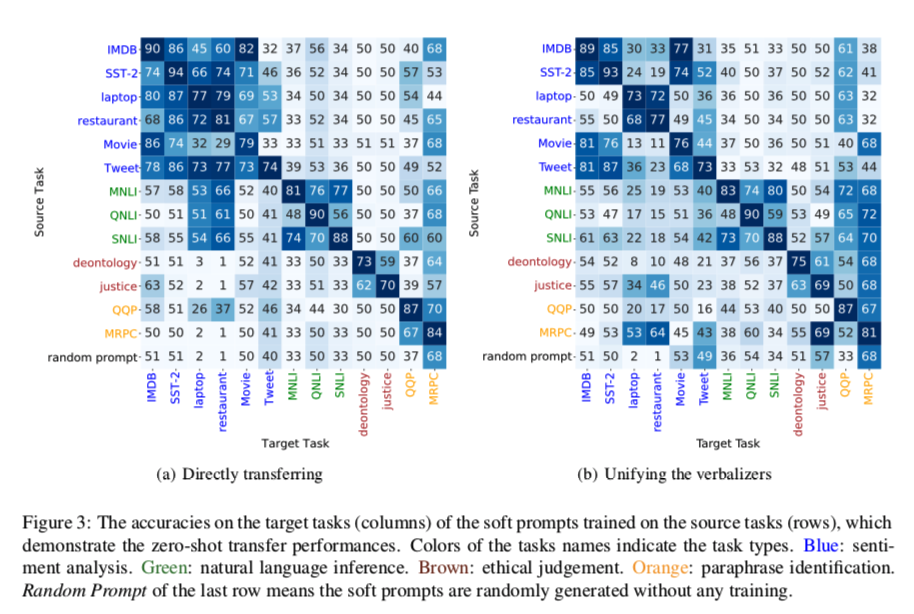
结果如图3所示,从图中我们可以看出。
- (1) 对于同一类型的任务,在它们之间迁移soft prompt一般可以表现良好,甚至可能在target数据集上超过vanilla PT,特别是当源任务的数据集比目标任务大的时候(从IMDB转到Movie的例子),这表明用类似任务的知识转移来提高PT的效果和效率是有希望的。
- (2)对于不同类型的任务,soft prompt 在它们之间的可迁移性普遍较差,迁移的 soft prompt 在很多情况下只能达到与给定的随机初始化 prompt 相似的性能。可转移性差的原因可能是不同类型的任务通常使用不同的标签,例如,entailment和convadict是用于NLI任务,而positive和negative是用于SA任务。为了排除这个因素,我们将不同任务的标签标记统一为同一组数字$(1,2,…)$,结果如图3(b)所示,从中我们可以看出,不同类型任务之间的可转移性一般不会通过这种方式得到改善。这表明,不同类型的任务肯定需要不同的能力,这就禁止在它们之间重复使用prompts。
- (3) 一些任务之间的可迁移性是直观的,例如IMDB表现最好的源任务是Movie。然而,有些则是反直觉的,比如laptop的最佳来源任务是Tweet。为了理解这一点,值得探讨是什么控制了prompts之间的迁移性,我们将在第4.3节做一些初步研究。
Transfer with Initialization
为了研究如何通过跨任务迁移来提高PT的有效性和效率,我们在本节中探讨了跨任务迁移的 prompt tuning($TPT{TASK}$)。$TPT{TASK}$在开始 prompt tuning 之前,用训练有素的类似任务的 soft prompt 来初始化 soft prompt,并观察它是否能加速训练和提高最终的表现。
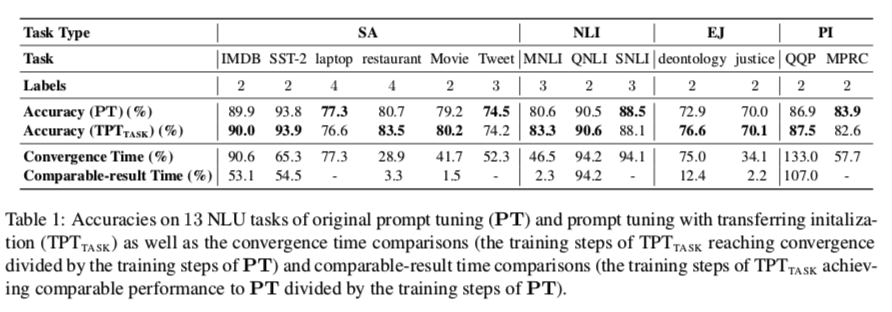
对于13个被调查的任务,我们用训练好的其他任务的 soft prompt 来启动 $TPT{TASK}$,可以达到图3(a)中的最佳性能。性能和训练时间的比较见表1。从结果中,我们可以看到 $TPT{TASK}$在大多数情况下可以达到比 vanilla PT更好或相当的性能,从随机初始化开始,它需要较少的训练步骤来达到相当的性能和收敛性。关于训练曲线的详细比较,请参考附录B。
Exploring Transferability Indicator
此外,我们还探讨了为什么 soft prompt 可以跨任务迁移,是什么控制了它们之间的可迁移性,这可能有助于揭示PT成功背后的机制,有助于设计可迁移的PT方法。为此,我们探索了各种 prompts 的相似性指标,并考察了它们与 zero-shot 迁移性能的吻合程度。
如果所设计的相似性度量标准能够很好地表明可迁移性,我们可以说在设计这个度量标准时考虑的因素大多控制了 prompts 之间的可迁移性。此外,提示的相似性指标可以用训练好的 soft prompt 作为任务嵌入来限定任务的相似性,并可能有助于设计跨任务的迁移方法。作为一个直接的例子,如果我们建立了一个包含不同任务的训练 prompt 的 prompt仓库,我们可以为一个新的任务检索具有一定相似性度量的相似任务的 prompt,并通过 $TPT_{TASK}$在新任务上更好地改进PT。在这项工作中,我们探讨了以下两种度量。
Embedding Similarity
在第一类被调查的相似性度量中,我们把训练好的 soft prompt 看作是向量空间中的嵌入,用两个常规度量来计算它们的相似性。欧氏相似度和余弦相似度。
给出两组包含 $l$ 个虚拟 token 的训练有素的 prompts: $P^{t_1} = {P_1^{t_1},…, P_l^{t_1}}$ 和 $P^{t_2} = {P_1^{t_2},.., P_l^{t_2}}$ 对应的任务为 $t_1,t_2$。 首先,我们串联 $l$ prompt token嵌入并得到 $l×d$ 维嵌入 $\hat P^{t_1}$, $ \hat P^{t_2}$,然后我们为它们计算欧氏相似度和余弦相似度:
考虑到由于我们在 PT 期间没有将Transformer(Vaswani等人,2017)中的位置嵌入添加到 prompt 中,所以提示是位置不变的,我们进一步介绍了一种简单的方法,使度量标准对 token 位置不变。
直截了当地,我们为两组中的每个 prompt 对计算欧氏距离和余弦相似度,并使用平均结果作为两个 soft prompt 的最终相似度指标。
Model Stimulation Similarity
在第二种方式中,我们不只将 soft prompt 视为嵌入向量,而是根据它们如何刺激 PLM 来描述它们的相似性,也就是说,我们研究PLM对两个训练过的 soft prompt 的反应的相似性。受Mor等人(2021)和Dai等人(2021)的启发,他们都发现Transformer模型的前馈层中间的神经元的激活与特定的模型行为相对应,我们建议使用激活的神经元的重叠率作为软提示的相似性指标。
具体来说,Transformer(Vaswani等人,2017)层中的前馈网络FFN(-)如下:
其中 $x \in R^d$ 是输入embedding, $W_1,W_2\in R^{d_m\times d }$是可训练的矩阵,并且 $b_1,b_2$ 是bias 向量。 $max(xW_1^T +b_1,0)$ 可以被视为 $d_m$ 隐含神经元的非负激活值。然后我们把 $max(xW_1^T + b_1, 0)$的所有正元素改为1,得到 one-hot 激活状态向量$s$ 。
我们输入一个输入序列 ${[MASK], p_1,…,P_l, }$ 到PLM,其中$$ 是特殊token表示句子的开头。这种格式本质上是PT输入的格式,但没有具体的输入语句。对于PLM的每个Transformer层,我们使用[MASK]位置的激活状态 $s$,因为 $[MASK]$ 是用来预测标签 token 的,因此更具有任务针对性。然后,我们将PLM中所有层的激活状态连接起来,得到整个PLM激活状态:
在相似性计算中,我们也只能检索到一部分层的激活状态。我们用余弦相似度来计算任务 $t_1$ 和 $t_2$ 的训练软提示之间的激活神经元 $ON(P^{t_1} , P^{t_2})$的重叠率:
Experimental Results
为了评估上述 soft prompt 的相似性指标的有效性,
(1)测试相似性指标是否能区分相同任务和不同任务的训练prompt
(2)检查这些指标是否与 soft prompt 的 zero-shot 迁移性能一致。
我们在表2中比较了同一任务内(用不同的随机种子训练的)和不同任务之间两个训练好的 prompt 的相似度值。从结果中,我们可以观察到。
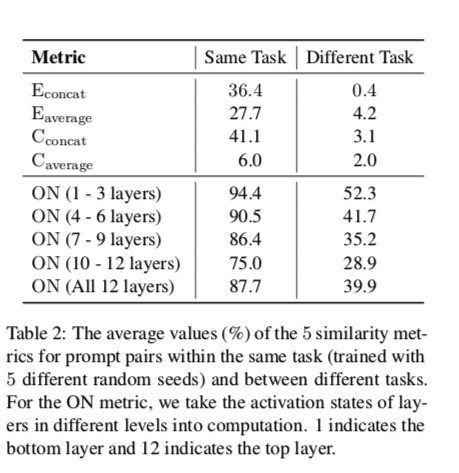
- (1) 所有的指标都能很好地区分同一任务和不同任务的 prompt 。从嵌入相似性的角度来看,这表明不同任务的训练有素的 soft prompt 形成了可以区分的集群。从模型刺激相似性的角度来看,这表明不同的任务确实需要 soft prompt 来刺激PLM中的不同能力。
- (2)对于激活的神经元的过度覆盖率,任务的差异往往在顶层更大。这与探测结果(Liu et al., 2019a)一致,显示顶层往往更具有任务特异性。激活神经元的重叠率的细节留在附录C中。
此外,我们还评估了 prompt 的相似性指标是否与图3中的 zero-shot 转移性能一致。具体来说,(a),我们计算每个目标任务的各种源任务 prompt 的相似性和 zero-shot 迁移性能之间的Spearman’s rank correlation(Spearman, 1987)。结果见表3,从中我们观察到
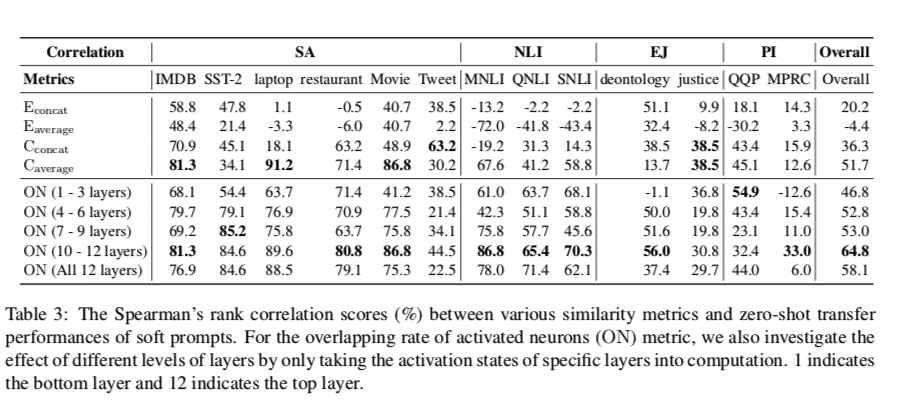
(1) 激活神经元的重叠率(ON)指标一般比所有的嵌入相似性效果好,这表明模型刺激在 prompt 迁移性方面比嵌入距离占据了更重要的位置。我们鼓励未来的工作探索如何更好地模拟提示的刺激。
(2) 在所有的嵌入相似性度量中,基于欧氏距离的两个度量效果不佳,甚至在某些任务上有负相关。基于余弦相似度的度量工作得更好,$C{average}$度量可以达到与使用底层的ON度量相当的性能。然而,$C{average}$区分不同任务的能力(表2)显然更差。这些结果表明,提示嵌入空间的属性是很棘手的,很难在此基础上设计可迁移的PT方法。
(3)使用较高模型层的ON的结果一般比使用较低层的好,这再次证实了最高层的模型更具有任务针对性。然而,也有一些反例,如 justice 和QQP,这可能来自于这些任务中需要一些特定的语言能力,需要仔细研究。
Cross-Model Transfer
在本节中,我们研究了软提示的跨模型转移能力。在实验中,我们研究了两种实际情况:从一个PLM转移到一个异质的同尺寸PLM(BERTBASE到RoBERTaBASE)和从一个较小的PLM转移到一个同质的较大的PLM(RoBERTaBASE到RoBERTaLARGE)。在不同大小的模型之间直接重用训练好的软提示是不可行的,因为嵌入维度不一致,在异质同大小的PLM之间重用的性能很差(见表4的直接重用行),这很直观,因为嵌入空间是不同的。因此,我们研究如何将在一个模型上训练的软提示投射到其他模型的空间(§5.1),并看到转移的性能(§5.2)。此外,与第4.2节类似,我们研究是否可以通过跨模型转移初始化来进一步提高效果和效率(第5.3节)。
Projecting Prompts to Different Models
在本节中,我们探讨了如何将一个模型的训练好的 soft prompt 投射到另一个模型的语义空间。为此,我们用各种监督方式训练 projectpr,并检验不同 projector 训练方法的有效性。
训练跨模型 projector 的好方法可能需要一些特定的任务监督,例如两个模型的平行 soft prompt 或某些任务的监督数据,但训练后的 projector 应能泛化到不同的任务,从而提高目标模型上PT新任务的学习效率。
从形式上讲,projector $Proj(-)$ 是将源模型中训练好的 soft prompt $P^s \in R^{l×d_s} $ 投影到目标模型语义空间中的相应 prompts $\hat P^s \in R^{l×d_t}$,其中 $d_s$ 和 $d_t$ 分别是源模型和目标模型的输入嵌入维度。在这项工作中,projector 的参数化是用两层感知器,具体如下:
其中W1、W2是可训练的矩阵,b1、b2是可训练的偏置项,tanh是非线性激活函数,LayerNorm是层归一化。
我们研究了三种类型的学习目标来训练交叉模型投影仪:
Prompt Mapping : 我们首先尝试通过学习在不同PLM上训练的同一任务的平行 soft prompt 之间的映射来学习跨模型预测。给出同一任务的两组提示 $P^s、P^t$,它们分别在源模型和目标模型上训练。投影仪将投影 $P^s$,训练目标是最小化L2准则:
Token Mapping : 由于提示是预置在输入 token 上的虚拟 token,我们探讨两个不同PLM的输入 token 嵌入之间的映射是否也能适用于提示嵌入。给定一个 token x和它相应的token 嵌入 $x^s$ , $x^t$,它们分别属于源PLM和目标PLM。我们训练投影仪以最小化L2准则:
并将词汇表中的所有输入 token 作为训练样本。
Task Tuning : 考虑到第4.3节中的发现,即 soft prompt 的可迁移性更多地与它们如何刺激PLM有关,而不是它们的嵌入距离,我们尝试用相应的任务直接调整目标PLM上的投影 prompt,并以这种方式训练投影仪,它应从任务调整中学习如何刺激目标PLM。然后,我们看看经过训练的投影仪是否可以推广到其他未见过的任务。
Prompt Mapping 和 Task Tuning 方法依靠一些任务(平行训练的 soft prompts 或训练数据)来训练投影仪。在实验中,我们分别选择了两个有代表性的SA任务(IMDB和笔记本电脑)和一个NLI任务(MNLI),供投影仪学习。Token Mapping需要源PLM和目标PLM的词汇表是一致的,因此我们只在RoBERTaBASE到RoBERTaLARGE的设置中尝试。
Transfer Performance
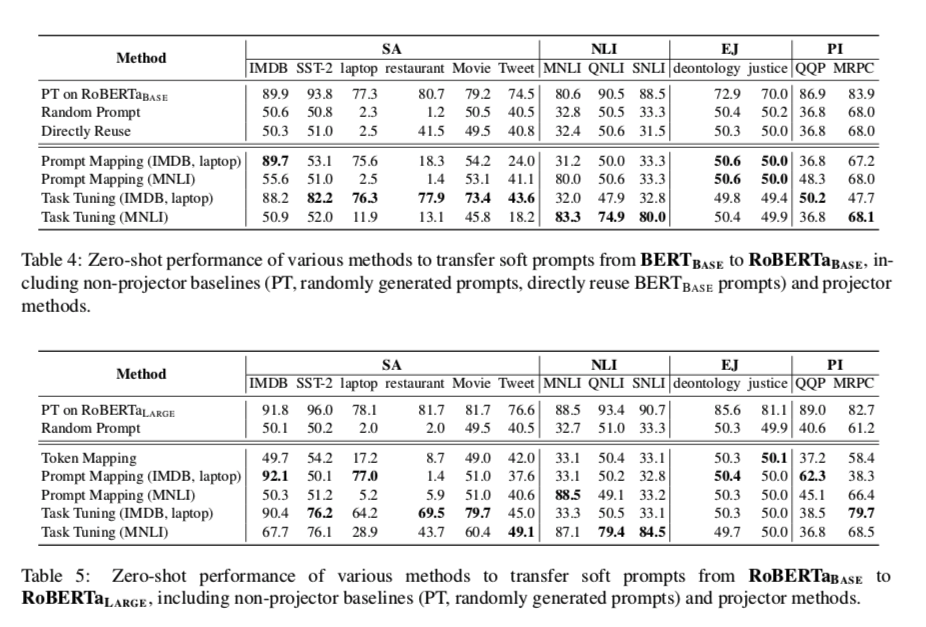
在从BERTBASE到RoBERTaBASE和从RoBERTaBASE到RoBERTaLARGE的设置上,各种投影仪-学习方法的转移性能分别见表4和表5。我们可以观察到。
- (1)虽然BERTBASE和RoBERTaBASE的输入嵌入维度一致,但它们之间直接重用训练好的 soft prompt 的性能与使用随机生成的 prompt 相似,这证实了不同模型的 prompt 语义空间差距巨大。
- (2) Token Mapping方法的性能也接近于随机基线,这表明虽然 soft prompt 与输入的 token 一起被送入PLM,但它们并不在同一个embedding空间。
- (3) Prompt Mapping在 迁移 投影仪训练中涉及的提示时效果很好,但在未见过的任务上又回到了随机性能,这是不现实的。这与我们在第4.3节中的发现一致,即嵌入的相似性/差异不能很好地反映任务之间的可迁移性。
- (4) Task Tuning 的效果最好,并且成功地将训练任务推广到同类型的未见过的任务中(例如,用MNLI训练的投影仪的NLI任务),这表明为PT设计实用的跨模型迁移方法的可行性。与Prompt Mapping的失败相比,这证实了从模型刺激的角度来分析和操作提示语是更有效的。然而,用任务调谐法训练的投影仪仍然不能用于不同类型的任务,这就要求采用更先进的转移方法。
Transfer with Initialization
与第4.2节类似,我们进一步研究投射的 soft-prompt 是否能在目标模型上初始化PT,并加速训练以及提高性能。基于第5.2节的结果,我们提出了跨模型迁移 prompt tuning,即 $TPT_{MODEL}$,它采用 Task tuning投射器,将在源PLM上训练的soft prompt 投射到目标PLM上,并用投射的 prompt 初始化PT。
在从BERTBASE转移到RoBERTaBASE的设置中,性能和训练时间的比较见表6
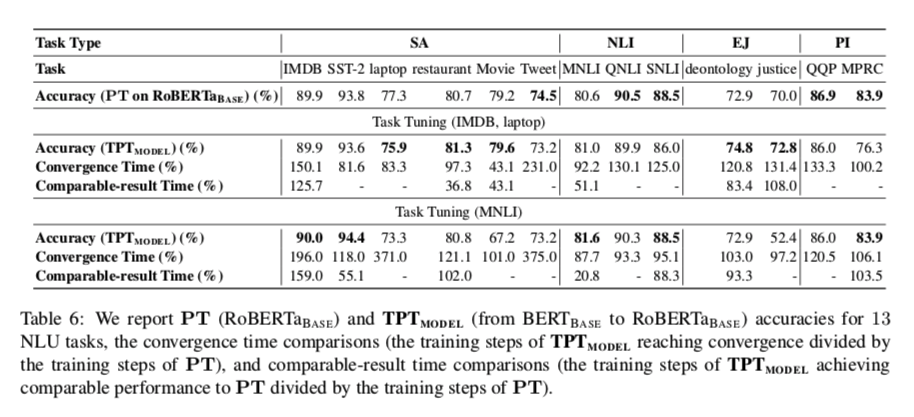
我们可以注意到。(1)对于同一类型的投影仪训练任务,TPTMODEL大多能以较少的训练步骤获得相当或稍好的性能,这表明实用的跨模型提示转移环是可能的,尽管先前的方法在这里不能取得明显的优势。(2)对于不同类型的投影仪训练任务,$TPT{MODEL}$通常不能在性能和训练时间上带来优势,这表明 $TPT{MODEL}$ 仍然严重受限于提示投影仪的质量。
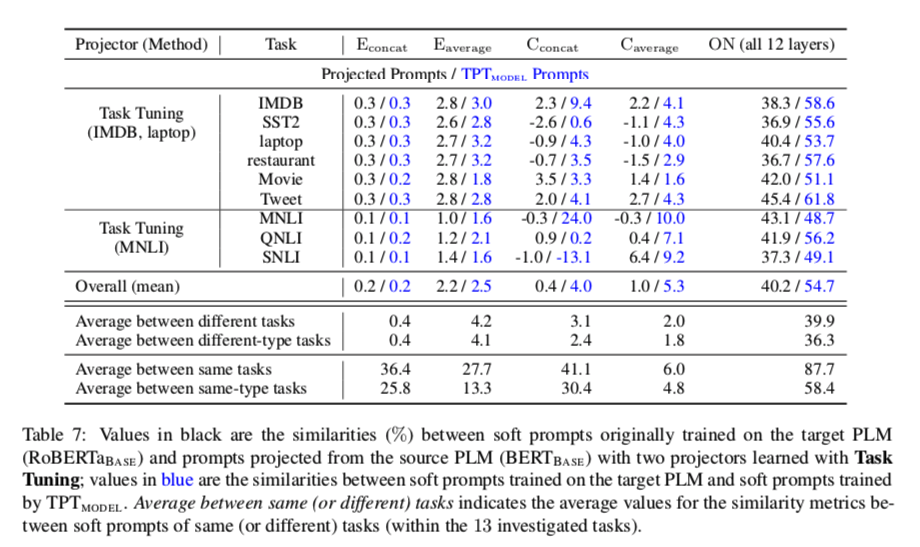
一般来说,$TPT{MODEL}$带来的优势是中等的,明显低于 $TPT{TASK}$。为了分析是什么影响了跨模型的可转移性,我们观察了在目标PLM上训练的原始提示和用4.3节中的提示相似度指标预测的提示之间的相似性。结果显示在表7中。我们可以看到,对于用所有指标衡量的所有任务,预测的提示语与最初在目标PLM上训练的提示语高度不相似,而投影仪训练任务的预测提示语可以达到与最初训练的提示语相当的性能。我们猜测这表明由于PLM的高冗余度(Aghajanyan等人,2021),不同的提示激活不同的神经元也能刺激PLM做类似的工作,但由优化器和超参数决定的优化动态更倾向于找到类似的解决方案(表2)。
Discussion
Using multiple source prompts.
在 $TPT{TASK}$ 和 $TPT{MODEL} $中,我们只使用一个源提示进行初始化,也就是事先尝试。直观地说,将多个源提示混合起来可能会实现进一步的性能和效率提升。实际上,同时进行的工作(Vu等人,2021)在跨任务转移中已经证实了这一点。未来的工作可以探索先进的混合/组合方法,以实现更好的初始化,本文探索的提示相似度指标可能有助于实现这一目的。
Finding better prompt similarity metric
在第5.3节中,我们发现,尽管从另一个PLM投射的提示可以达到与最初在目标PLM上训练的提示相当的性能,但用本文所有的提示相似度指标(包括激活神经元的重叠率)来衡量,这两种提示是高度不相似的。这表明,考虑到PLMs的高度冗余,我们仍然需要一个更好的提示相似性指标,并测量提示的基本因素,这需要对PLMs的机制有更深入的了解。以前的工作(Aghajanyan等人,2021;Qin等人,2021b)表明,各种NLP任务可以被重新参数化为类似的低维子空间,以PLMs为条件,这可能有助于实现这一目的。
Designing better cross-model prompt projection.
与 $TPT{TASK}$相比,本文中 $TPT{MODEL} $ 的结果要弱得多,这是因为源PLM和目标PLM之间的特征不同,而且投影方法有限。在第5.3节中,我们发现我们的跨模型投影倾向于投影到性能相当的解决方案,但不是那些优化过程中的首选方案;因此 $TPT{MODEL}$ 的效果不如 $TPT{TASK}$好。而且我们发现,当我们去掉任务调优中公式7的LayerNorm(-)后,这种现象更加明显,即使用 $TPT_{MODEL}$时,学习损失并没有减少。详细情况请参考附录D。这表明我们应该设计更好的跨模型投影方法来克服不同PLM的异质性和不同的优化偏好。
Conclusion
在本文中,我们实证研究了提示调谐在不同任务和模型中的可转移性。在跨任务的设置中,我们发现软提示可以在不训练的情况下转移到类似的任务中,并且使用训练过的软提示作为初始化可以加速训练并提高效果。我们还探索了各种提示的相似性指标,并表明提示如何刺激PLM比它们的嵌入距离在转移性方面更重要。在跨模型的设置中,我们探索了各种将软提示投射到其他模型空间的方法,发现使用投射提示的转移初始化只能取得适度的改善,这可能是由于PLM的冗余性。我们希望这项工作中的实证分析和尝试的转移方法能够促进PT转移的进一步研究。
 wechat
wechat alipay
alipay





