TransPrompt Towards an Automatic Transferable Prompting Framework for Few-shot Text Classification
TransPrompt: Towards an Automatic Transferable Prompting Framework for Few-shot Text Classification
Abstract
最近的研究表明,prompts 可以提高大型预训练语言模型在 few-shot 文本分类中的表现。然而,目前还不清楚如何在类似的NLP任务中迁移 prompts 知识以达到相互强化的目的。基于连续的 prompts 嵌入,我们提出了TransPrompt,一个可迁移的 prompt 框架,用于在类似的任务中进行 few-shot 的学习。
在TransPrompt中,我们采用了一个多任务元知识获取程序来训练一个元学习者,以捕获跨任务的可迁移知识。我们进一步设计了两种去偏技术,使其对任何任务都更具有任务无关性和无偏性。
之后,元学习器可以以高精确度适应目标任务。大量的实验表明,TransPrompt在多个NLP任务和数据集上的表现优于单任务和跨任务的强基线。我们进一步表明,元学习器可以有效地提高以前未见过的任务的性能。当用完整的训练集学习时,TransPrompt也优于强大的微调基线。
Introduction
微调预训练语言模型(PLM)已经成为大多数NLP任务训练模型的标准做法(Devlin等人,2019;Liu等人,2019b;Qiu等人,2020)。为了确保高精确度,有必要为下游任务获得足够数量的训练数据,这往往是低资源场景下的瓶颈。
超大型PLM的应用,如GPT-3(Brown等人,2020),证明了这种PLM可以通过很少的训练样本来学习解决一个任务。受这些工作的启发,Gao等人(2020)提出了一种基于 prompt 的方法,以在少量的学习环境中对BERT-风格的PLM进行微调,它使PLM适应于产生对应于每个类别的特定标记,而不是学习预测头。Schick和Schütze(2020);Scao和Rush(2021);Schick和Schütze(2021)等人也表明了 prompt 的有效性。然而,设计高绩效的提示语是具有挑战性的,需要非常大的验证集。为了缓解这个问题,Liu等人(2021)提出了具有完全可分参数的连续 prompt 嵌入,避免了繁琐的手工提示工程过程。
尽管取得了显著的成功,我们注意到目前基于提示的方法可能有一些限制。对于 few-shot 的学习,下游任务的性能仍然受到训练实例数量的限制。如果模型能够在适应 few-shot 样本的特定任务之前,从类似的NLP任务中获得可迁移的知识,那将是非常理想的。然而,目前还不清楚提示编码器和具有提示技术的PLM中的知识是如何跨任务转移的。一个自然的问题出现了:我们如何为BERT风格的模型设计一个提示框架,以捕捉类似NLP任务中的可转移知识,从而提高少数样本学习的性能?
上述问题的一个直接解决方案是在这些类似的NLP任务中采用多任务微调。当训练数据稀缺时,微调后的PLM很容易对特定实例过度拟合(Nakamura and Harada, 2019)。在机器学习中,元学习范式被广泛研究,它产生的模型能够以很少的学习步骤迅速适应一组类似的任务(Wang等人,2020c;Huisman等人,2020)。对于PLM,Wang等人(2020a)发现,训练PLM的元学习者能够有效地捕捉不同领域的可转移知识。然而,这种方法并不是为提示性的少量学习而设计的,而且缺乏为所有任务学习无偏见的表征的机制。
在本文中,我们提出了TransPrompt这个提示框架,它允许PLMs为少量文本分类捕获跨任务的可转移知识,其高级架构如图1所示。TransPrompt首先采用多任务元知识获取(MMA)程序,在类似的NLP任务中共同学习提示编码器和PLM的可转移表示。为了减少过度拟合,使底层PLM更具有任务无关性,并减少对任何特定任务的偏倚,我们提出了两种去偏倚技术,即基于原型的去偏倚和基于熵的去偏倚。学习到的模型可以被看作是一组类似NLP任务的元学习器。
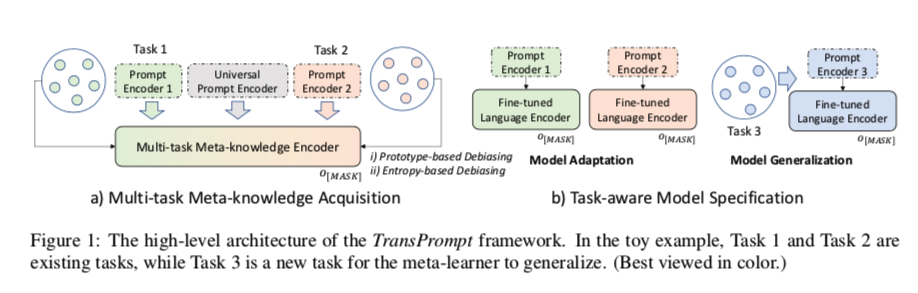
在MMA之后,TransPrompt采取了任务意识模型规范(TMS)的步骤,这可以进一步分为两种情况。 i)当模型在MMA期间适应现有任务时,可以应用P-tuning(Liu等人,2021)的变体来进行有效适应。 ii)当需要适应以前未见过的任务时,采用模型泛化策略,具体考虑模型中的通用提示知识。这通常是指由于数据隐私或计算效率问题,对所有任务的元精简器进行重新训练是不可行的情况。
为了进行评估,我们在三组少有的NLP任务(共包括七个公共数据集)上测试了TransPrompt框架:i)情感分析;ii)自然语言推理(NLI);以及iii)转述。实验结果表明,TransPrompt在单任务和跨任务的强大基线上都有稳定的表现。我们进一步证明:i)由TransPrompt训练的元学习器可以有效地推广到未见过的任务;ii)在用完整的训练集学习时,TransPrompt也优于流行的微调算法。综上所述,我们在这项工作中做出了以下主要贡献。
- 我们介绍了新的TransPrompt框架,以学习跨任务的可转移知识,用于少数文本分类。
- 我们提出了一个基于提示的元学习者训练算法和两种去偏技术,以获取可转移的知识。
- 在多种类型的NLP任务上的实验表明,TransPrompt在少量学习和标准微调方面的表现一直优于强大的基线。
The TransPrompt Framework
Overview
$T_1, …, T_M$ 是 $M$ 个类似的 few-shot 的文本分类任务。第 $m$ 项任务可以表示为:$T_m:x \to y$, 其中 $x$ 和$y\in Y$ 表示输入文本和分类标签。
$Y$ 是预先定义的标签集,$|Y| = N$, 其中 $N$ 是预定义的常数。假设在每个任务 $T_m$ 中,有 $K$ 个训练样本与每个类 $y\in Y$相关。因此,我们对每个任务 $T_m$ 有一个训练集 $D_m$,每个训练集包含 $N×K$ 个样本。$M$ 个任务的训练实例的总数是$ N×K×M$ 。
在 TransPrompt 中,根据 $M$ 个few-shot的训练集 $D1,…,D_M$ 来训练一个元学习器 $F{meta}$,其参数从任何PLM中初始化。之后,$F_{meta}$ 根据每个任务的训练集 $D_m$ 来适应每个任务 $T_m$。特定任务的模型被表示为 $F_m$。
由于 $F{meta}$ 的设计是为了消化跨任务的可转移知识,而不是简单的多任务学习,$F{meta}$ 也可以适应以前没有见过的任务。
由于数据隐私或计算效率问题,当在 $F{meta}$ 的训练过程中无法获得相似任务 $\hat T$ 的少量训练集 $\hat D$ 时,我们探索如何利用TransPrompt 来生成基于 $F{meta}$ 和 $\hat D$ 的精确模型 $\hat F$。在这种情况下,$F_{meta}$ 在MMA期间接受训练时,对新任务 $\hat T$ 没有任何了解。
在下文中,将介绍TransPrompt框架的详细技术,它由两个主要阶段组成,即多任务元知识获取(MMA)和任务意识模型规范(TMS)。最后,我们讨论了如何将 TransPrompt 应用于标准的微调场景,其中我们有相对较大的训练集,而不是解决 $N$ 路 K-shot 问题。
Multi-task Meta-knowledge Acquisition
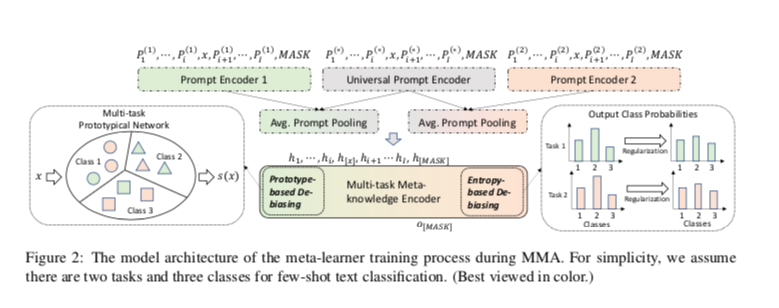
Prompt Encoding
由于 TransPrompt 框架被置于多任务设置中,对于每个任务 $T_m$,我们有一个特定任务的提示模板 $t^{(m)} (x)$,如下所示:
其中 $P_i^{(m)}$ 是 prompt 伪 token,$I$ 是伪token的总数,MASK是特殊 token 是一个特殊标记,用作模型输出的占位符。 我们还为所有任务定义了一个通用提示模板 $t^{(∗)}(x)$ :
对于一个实例$(x,y)\in D_m$,提示嵌入 $PE^{(m)}(x)$可以计算如下:
其中我们使用双向LSTM网络与多层感知器作为提示编码器(Liu等人,2021)。特定任务和通用提示编码器的平均集合结果被视为提示嵌入。提示嵌入 $PE^{(m)}(x)$ 是一个序列,作为PLM的输入:
其中 $h{[x]}$ 是输入 $x$ 的序列嵌入,$h{[MASK]}$ 是被MASK的输出 token 嵌入。由于提示参数是完全可微的,在反向传播过程中,它们有效地捕捉了特定任务和一般知识。
Training the Meta-learner
获得元学习者的一个天真的方法是在 $M+1$ 个 prompt 编码器的 $M$ 个任务中应用P-tuning过程(Staudemeyer和Morris,2019)。然而,在实践中,它不能保证满意的结果。由于大型PLMs在 few-shot 学习过程中很容易出现过度拟合(Gao等人,2020),在跨任务的情况下,元学习者会不幸地记住非目标任务中的不可转移的知识。为了缓解这个问题,我们提出了两种去偏技术,以获得一个用可转移知识编码的更无偏见的元学习者,
即i)基于原型的去偏 和 ii)基于熵的去偏。
Prototype-based De-biasing:这种技术旨在在元学习者的训练过程中对跨任务的原型实例给予更多的重视。在这里,我们扩展了Snell等人(2017)构建的轻量级多任务原型网络G。在网络G中,每个任务 $T_m$ 的类中心点嵌入$c_m(y)(y∈Y)$被计算并存储为:
其中 $D{m,y}$ 是 $D_m$ 的子集,使得 $D{m,y}$中的每个实例都有标签 $y$ ,而 $E(x)$ 是由前面描述的元学习器生成的 $x$ 的表示。对于每个实例 $(x,y)\in D_m$,我们将文本 $x$ 通过网络来生成跨任务原型得分,表示为 $s(x)$:
其中 $0<\tau <1$ 是预定义的平衡因素,$sim(\cdot, of K nowcdot)$ 是两个嵌入的相似函数,我们可以看到,如果一个实例与任务 $Tm$ 本身和其他任务的中心点都有语义上的联系,那么它就会得到更高的分数,因此更容易跨任务迁移。通过将 $s(x)$ 视为优化权重,$F{meta}$ 的整体损失函数 $L(Θ)$可以通过以下方式给出:
其中Θ是所有模型参数的集合,$l(x, y; Θ)$是样本间交叉熵损失,$λ_1$是正则化超参数。
Entropy-based De-biasing:仅仅应用基于原型的去偏移技术的一个潜在风险是获得一个非任务无关性的元学习者。考虑三个任务T1、T2和T3。如果T1和T2高度相似,而T3则更不相似。在D1和D2中,自然会得到较高的原型分数,使得元学习者偏向于T1和T2,而对T3很少关注。因此,当元学习者需要拟合T3时,它的参数初始化设置可能很差。为了使其更具任务无关性,受Jamal和Qi(2019)的启发,我们考虑了 $D_m$ 上的模型预测熵 $H(D_m)$:
其中 $\hat y(x)$是 $x$ 被分配到 $\hat y∈Y$类的预测概率。当 $H(D_m)$ 被用作模型正则器的一部分时,元学习器在任何特定任务上的过度训练将减少。
将 $H(D_m)$ 项插入损失函数 $L(Θ)$,我们就有了新的损失函数 $L’(Θ)$:
其中 $\lambda_2$ 是正则化超参数
Optimization Procedure:尽管它的公式很简单,但最小化 $L’(Θ)$是一个非简单的问题。 这是因为当我们计算 $s(x)$时,我们必须事先获得PLM的模型参数,而这在训练过程之前是无法获得的。另一方面,$L (Θ)$的优化重新要求所有训练样本的 $s(x)$ 值,这就造成了 “鸡生蛋,蛋生鸡 “问题。
我们采用双重优化过程来解决 $L’(Θ)$的问题。在初始阶段,所有的 $s(x)$s都被均匀地初始化。接下来,我们将 $s(x)$s固定为常数,使 $L′(Θ)$ 中的 $l(x, y; Θ)$ 最小化。一个关于PLM的推理过程可以被应用来获得所有的 $s(x)$s。这个过程迭代了一定数量的epoch。读者也可以参考算法1来了解算法的概况。

Task-aware Model Specification
在MMA之后,元学习者可以很容易地适应特定的任务。对于一个已经被元学习器 “看到 “的任务 $T_m$,我们通过最小化损失函数 $L^{(m)}(Θ)$来微调相应的 prompt 编码器和PLM:
这是P-tuning的一个变种(Liu等人,2021),具有更好的参数初始化。
对于一个先前未见过的任务 $\hat T$,采用模型泛化策略。这里,我们使用通用 prompt 编码器来初始化其 prompt编码器。整个模型在数据集 $\hat D $上进行训练,损失函数 $\hat L(\theta)$如下:
由于元学习器是高度泛化的,它可以为少数几次的学习任务 $\hat T$提供良好的初始化。
Learning with Full Training Sets
当我们有相对较大的训练集时,TransPrompt也可以应用于标准的微调,并进行少量修改。在MMA过程中,我们注意到,当它不是一个N-way K-shot问题时,$D_1,…,D_M$ 的大小会有很大的不同。直接在这些数据集上优化 $L’(Θ)$ 会使元学习者偏向于大数据集。为了解决这个问题,当我们从 $D_1, …, D_M$ 中抽出一批样本时,我们采用分层抽样的方式,以与数据集分布 $Pr(D_m)$ 成比例的概率选择训练实例:
其中 $γ>0$ 是一个平滑系数。这导致了对小数据集的过度采样和对大数据集的不足采样。
Method
本文旨在解决few-shot的分类问题。这个问题的定义从根本上不同于 与传统的分类法根本不同,传统的分类法的目标不是对其目的不是对未见过的样本进行分类,而是要快速地将元知识适应于新的任务。具体来说,提供一个有足够训练样本的标记数据集。提供了一个有足够训练样本的基础类 $C^{base}$,其目标是用非常有限的数据来学习概念。一组新类 $C^{novel}$,其中 $C^{base} ∩C^{novel} = ∅$。解决 few-shot 问题的一个有效方法是使用情节采样策略episodic sampling strategy.。
在这个框架中,元训练和元测试中的样本不是样本,而是情节 ${T}$,每个情节包含 $N$ 个类别(方式)和每个类别的 $K$ 个镜头。
特别地,对于N-way K-shot 任务,采样支持集 $S = {(xi, y_i)}{i=1}^{N\times K}$ 和查询集 $Q = {(xi,y_i)}{i=N\times K +1}^{N\times K +T}$
这里,$x_i$ 和 $y_i \in {C_1,…,C_N}$是第 $i$ 个输入数据,并且是来自 $C^{base}$。在元测试中,测试任务也是从未见过的类别$C^{novel}$ 中抽出同样大小的情节。其目的是将查询集中的 $T$ 个未标记的样本正确地分类到 $N$ 个类别中。
Overview of Framework
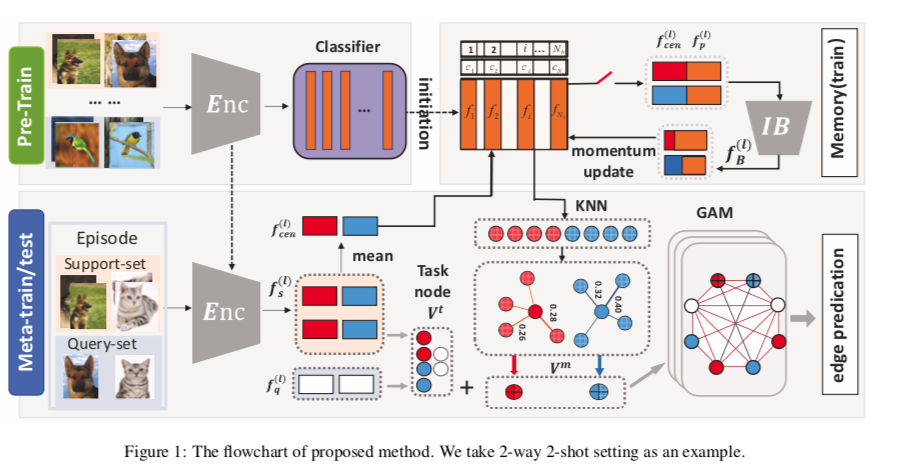
图1说明了所提方法的框架。它主要由三个部分组成,即用于鉴别性特征提取的编码器,用于表达性元知识存储的记忆模块,用于综合推理的图增强模块。一般来说,我们的方法可以概括为三个阶段(即预训练、元训练、元测试)。
- Phase-I Pre-Train. 我们遵循一个简单的基线[Chen et al., 2020]:在元训练集C的基础上学习一个有监督的表示,然后在这个表示之上学习一个线性分类器。事实证明,这个预训练阶段对下游的 few-shot 任务是有益的[Tian et al., 2020],然后将训练好的特征提取器(如ResNet-12[He et al.*, 2016])和分类器分别作为我们编码器和记忆库的初始化。
- Phase-II Meta-Train. 我们首先提取支持和查询样本的特征作为任务相关的嵌入$V^t$。然后为了促进快速适应,我们的方法拥有一个记忆库来存储支持集的表达式。这个记忆库通过一个新的更新方案进行优化,以逐步净化鉴别性信息(在第2.2节中介绍)。此外,净化后的内存与图的增强模块相结合,用于稳健预测(在第2.3节中介绍)。在这个模块中,我们挖掘相关的原型 $V^m$ ,在本文中被称为元知识,通过图神经网络传播 $V^t$ 和 $V^m$ 之间的相似性。因此,我们的模型能够以可忽略不计的内存成本方便地泛化到新的任务。
- Phase-III Meta-Test. Meta-Test的程序与Meta-Train相似,也是采用情节性抽样策略。但与第二阶段不同的是,记忆库和其他模块在整个过程中不会被更新。换句话说,开关将被关闭,如图1所示。
Refined Memory Updating
元知识在从未见过的样本中学习新概念方面起着重要作用,最近 FSL 的进展[Ramalho和Garnelo, 2019]经常利用内存机制来存储这种元知识。在其典型的设置中,存储器试图保留尽可能多的信息(例如,存储整个特征)。然而,我们认为这种策略是无效的和低效的。在FSL的背景下,偶发抽样使得特征提取器以很少的样本迅速学习新的概念,这就造成了一个问题:当特征提取器处于一个非常不同的任务背景下时,记忆中的特征会被更新。从这个角度来看,从不同的任务中学习到的表征需要一个净化的过程才能成为一个稳定的概念。
 wechat
wechat alipay
alipay





