PromptBERT: Improving BERT Sentence Embeddings with Prompts
PromptBERT: Improving BERT Sentence Embeddings with Prompts
在以前的工作中,原始的BERT在句子语义相似性方面的表现不佳,已经被广泛讨论。我们发现,不尽如人意的表现主要是由于静态 token 嵌入的偏差和无效的 BERT 层,而不是因为句子嵌入的高余弦相似度。
为此,我们提出了一种 prompt based 的句子嵌入方法,它可以减少 token 嵌入的偏差,使原来的BERT层更加有效。通过将句子嵌入任务重新表述为填空问题,我们的方法显著提高了原始BERT的性能。我们讨论了 prompt based 的句子嵌入的两种 prompt 表示方法和三种 prompt 搜索方法
此外,我们通过模板去噪技术提出了一个新的无监督训练目标,这大大缩短了有监督和无监督设置之间的性能差距。
在实验中,我们对我们的方法在非微调和微调的设置上进行评估。即使是一个非微调的方法,也可以在STS任务上超过微调的方法,如无监督的ConSERT。我们的微调方法在无监督和有监督的情况下都优于最先进的方法SimCSE。与SimCSE相比,在无监督设置下,我们在BERT和RoBERTa上分别取得了2.29和2.58分的改进。
Introduction
以前的研究将各向异性与解释原始BERT的不良性能联系起来(Li等人,2020;Yan等人,2021;Gao等人,2021)。各向异性使得 token 嵌入占据一个狭窄的锥体,导致任何句子对之间的高相似度
Li 等人(2020)提出了一种归一化 flows 方法,将句子嵌入分布转化为平滑和各向同性的高斯分布,Yan等人(2021)提出了一个对比性框架来迁移句子表示。这些方法的目标是消除句子嵌入中的各向异性。然而,我们发现,各向异性并不是导致语义相似性差的主要原因。例如,在语义文本相似性任务中,对原始BERT的最后一层进行平均,甚至比对其静态token 嵌入进行平均更差,但最后一层的句子嵌入比静态 token 嵌入的各向异性要小。
根据这一结果,我们发现原始的 BERT层 实际上损害了句子嵌入的质量。然而,如果我们将静态 token 嵌入视为单词嵌入,与GloVe相比,它产生的结果仍然不能令人满意。受(Li等人,2020)的启发,他们发现 token 频率偏向其分布,我们发现分布不仅偏向频率,还偏向WordPiece(Wu等人,2016)中的大小写和子词。
我们设计了一个简单的实验来测试我们的猜想,只需去除这些有偏的token(如高频子词和标点符号),并使用剩余token嵌入的平均值作为句子表示。它可以超越Glove,甚至取得与后处理方法BERT-flow(Li等人,2020)和BERT-whitening(Su等人,2021)相当的结果。
在这些发现的激励下,避免嵌入偏差可以提高句子表述的性能。然而,手动消除嵌入偏差是很费力的,而且如果句子太短,可能会导致一些有意义的词被遗漏。
受(Brown et al., 2020)的启发,将不同的NLP任务通过不同的 prompt 重新表述为填空问题,我们提出了一种基于 prompt 的方法,使用模板来获得BERT中的句子表述。
Prompt based 的方法可以避免嵌入偏差并利用原始BERT层。我们发现原始的BERT在句子嵌入的模板帮助下可以达到合理的性能,它甚至超过了一些基于BERT的方法,这些方法在下游任务中对BERT进行了微调。
我们的方法同样适用于微调的设置。目前的方法利用对比学习来帮助BERT学习更好的句子嵌入(Gao等人,2021;Yan等人,2021)。然而,无监督的方法仍然存在泄漏适当积极对的问题。Yan等人(2021)讨论了四种数据增强方法,但其性能似乎比直接使用BERT中的 dropout 作为噪声要差(Gao等人,2021)。
我们发现 prompt 可以提供一个更好的方法,通过不同模板的不同观点来生成正数对。为此,我们提出了一种基于prompt的对比学习方法,该方法带有模板去噪功能,可以在无监督的情况下利用BERT的力量,这大大缩短了有监督和无监督性能之间的差距。我们的方法在无监督和有监督的情况下都取得了最先进的结果。
Related Work
学习句子嵌入作为一个基本的NLP问题已经被大量研究。目前,如何在句子嵌入中利用BERT的力量已经成为一个新的趋势。许多工作(Li等人,2020年;Gao等人,2021年)在有监督和无监督的情况下都用BERT取得了强大的性能。在这些工作中,基于对比学习的方法取得了最先进的成果。这些工作(Gao等人,2021;Yan等人,2021)注意构建积极的句子对。Gao等人(2021)提出了一个新颖的对比性训练目标,直接使用内部 dropout 作为噪声来构建正向句对。Yan等人(2021)讨论了四种构建积极句对的方法。
虽然BERT在句子嵌入方面取得了巨大的成功,但原始BERT的表现并不令人满意。原始BERT的上下文令牌嵌入甚至比GloVe等词嵌入的表现还差。一种解释是原始BERT中的各向异性,这导致句子对具有高相似性。根据这一解释,BERT-flow(Li等人,2020)和 BERT-whitening(Su等人,2021)已被提出,通过对原始BERT的句子嵌入进行后处理来减少各向异性。
Rethinking the Sentence Embeddings of Original BERT
以前的工作(Yan等人,2021年;Gao等人,2021年)解释了原始BERT的不良性能是由学习的各向异性的 token 嵌入空间限制的,其中 token 嵌入占据一个狭窄的锥体。然而,我们通过研究各向异性和性能之间的关系发现,各向异性并不是诱发不良语义相似性的关键因素。我们认为主要原因是无效的BERT层和静态 token 嵌入偏差。
Observation 1: Original BERT layers fail to improve the performance
在本节中,我们通过比较两种句子嵌入方法来分析 BERT 层的影响:平均静态 token 嵌入(BERT层的输入)和平均最后层(BERT层的输出)。我们报告了句子嵌入的性能和它的句子水平各向异性。
为了测量各向异性,我们遵循(Ethayarajh,2019)的工作,测量句子嵌入中的句子水平各向异性。让 $s_i$ 是出现在语料库${s_1, …, s_n }$ 中的一个句子。该各向异性可按以下方式测量:
其中 M 定义为表示语句嵌入方法,它将原始句子映射到其嵌入,cos是余弦相似度。换句话说,M的各向异性是通过一组句子的平均余弦相似度来衡量的。
如果句子嵌入是各向同性的(即方向均匀),那么均匀随机抽样的句子之间的平均余弦相似度将是0(Arora等人,2016)。它越接近于1,句子的各向异性就越大。我们从维基百科语料库中随机抽取100,000个句子来计算各向异性。
我们比较了不同的预训练模型(Bert-base-uncased、Bert-base-cased和Roberta-base)和不同的句子嵌入方法(最后一层平均法、最后一个隐藏层token作为句子嵌入和静态token嵌入的平均法、直接对静态token嵌入的平均法)。我们在表1中显示了这些方法的spearman相关性和句子水平各向异性。
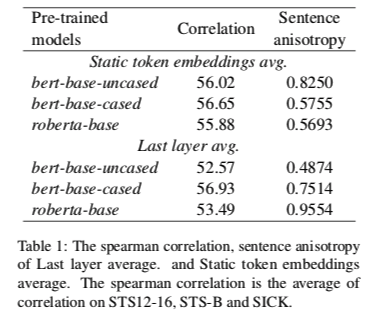
如表1所示,我们发现bert-base-uncased和roberta-base中的BERT层明显损害了句子嵌入性能。即使在bert-base-cased中,BERT层的增益也是微不足道的,只有0.28的改善。我们还展示了每种方法的句子层面的各向异性。BERT层的性能下降似乎与句子水平各向异性无关。例如,最后一层的平均值比bert-base-uncased中的静态标记嵌入平均值更加各向同性。然而,静态标记嵌入平均数实现了更好的句子嵌入性能。
Observation 2: Embedding biases harms the sentence embeddings performance.
Li等人(2020)发现,token嵌入会对 token 频率产生偏差。Yan等人(2021)也研究了类似的问题。BERT静态令牌嵌入的各向异性对令牌频率很敏感。因此,我们研究了嵌入偏差是否会产生不理想的句子嵌入性能。我们观察到,token嵌入不仅对token频率有偏见,而且对WordPiece(Wu等人,2016)中的子词和大小写敏感。
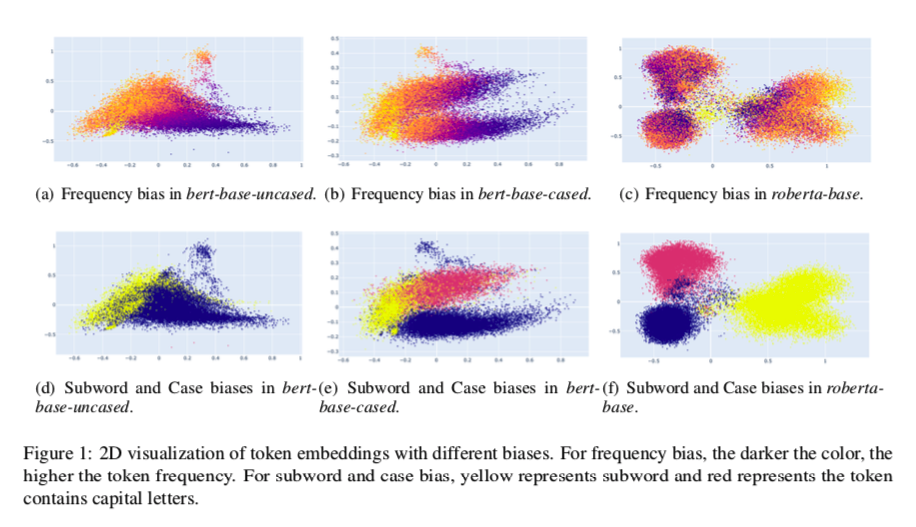
如图1所示,我们在bert-base-uncased、bert-base-cased 和 roberta-base 的token embeddings 中直观地看到这些偏差。三种预训练模型的 token 嵌入受到 token 频率、子词和大小写的高度偏向。根据子词和大小写的偏差,token 嵌入可以大致分为三个区域:1)小写的词首token,2)大写的词首token和3)子词token。对于无大小写的预训练模型bert-base-uncased,token嵌入也可以大致分为两个区域。1)词首token,2)子词token。
对于频率偏差,我们可以观察到,在所有的模型中,高频率的token是聚集的,而低频率的 token 是稀疏地分散的(Yan等人,2021)。在BERT中,词首 token 比子词token 更容易受到频率的影响。然而,在RoBERTa中,子词 token 更容易受到影响。
以前的工作(Yan等人,2021;Li等人,2020)经常将 “token嵌入偏见 “的概念与token嵌入各向异性作为偏见的原因。然而,我们认为各向异性与偏见无关。偏差意味着嵌入的分布被一些不相关的信息,如token频率所干扰,这可以根据PCA直接可视化。对于各向异性,它意味着整个嵌入在高维向量空间中占据了一个狭窄的锥体,这不能被直接可视化。
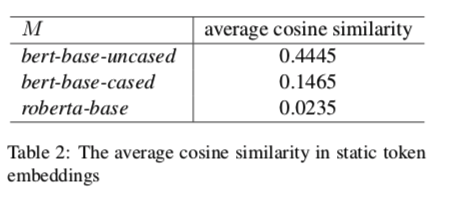
表2显示了图1中三个预训练模型的静态token embeddings各向异性,根据任意两个token embeddings之间的平均余弦相似度计算。与之前的结论相反(Yan等人,2021;Li等人,2020),我们发现只有Bert-base-uncased的静态令牌嵌入是高度各向异性的。像roberta-base的静态 token 嵌入是各向同性的,平均余弦相似度为0.0235。对于偏差,这些模型受到静态标记嵌入中的偏差的影响,这与各向异性无关。
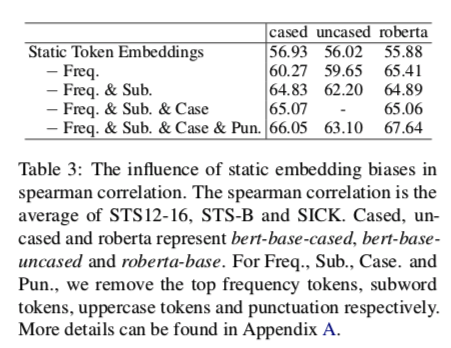
为了证明偏见的负面影响,我们用平均的静态 token 嵌入作为句子嵌入(没有BERT层)来展示偏见对句子嵌入的影响。在表3中的三个预训练模型上,消除嵌入偏差的结果相当可观。仅仅去除一组token,结果就可以分别提高9.22、7.08和11.76。roberta-base的最终结果可以超过后处理方法,如BERT-flow(Li等人,2020)和BERT-whitening(Su等人,2021),只使用静态 token 嵌入。
手动消除嵌入偏差是提高句子嵌入性能的一个简单方法。但是,如果句子太短,这不是一个适当的解决方案,可能会导致一些有意义的词被遗漏。
Prompt Based Sentence Embeddings
受(Brown等人,2020)的启发,我们提出了一种 基于提示的句子方法来获得句子嵌入。通过将句子嵌入任务重新表述为掩码语言任务,我们可以通过利用大规模的知识有效地使用原始BERT层。我们还通过从[MASK] token 表示句子来避免嵌入偏差。
然而,与文本分类或问题回答任务不同,句子嵌入中的输出不是MLM分类头预测的标签 token,而是表示句子的向量。我们按照这两个问题来讨论基于提示的句子嵌入的实现。1)如何用提示表示句子,以及2)如何为句子嵌入找到一个合适的提示。基于这些,我们提出了一种基于提示的对比学习方法来微调句子嵌入的BERT。
Represent Sentence with the Prompt
在本节中,我们将讨论两种用提示语表示一个句子的方法。例如,我们有一个模板”[X]意味着[MASK]”,其中[X]是一个放置句子的占位符,[MASK]代表[MASK]token。给定一个句子 $x{in}$,我们用模板将 $x{in}$ 映射到 $x{prompt}$。然后,我们将$x{prompt}$送入一个预先训练好的模型,以生成句子表示 $h$。
一种方法是使用 $[MASK]$ token 的隐藏向量作为句子表示:
对于第二种方法,就像其他基于提示的任务一样,我们根据 $h_{[MASK]}$ 和MLM分类头得到top-k tokens,然后根据概率分布找到这些tokens的加权平均值。$h$ 可以被表述为:
其中,v 是 top-k token 集 $V{top-k}$ 中的BERT标记,$W_v$ 是 $v$ 的静态 token 嵌入,$P([MASK] = v|h{[MASK]})$表示token $v$被MLM头预测为 $h_{[MASK]}$ 的概率。
第二种方法是将句子映射到 token 上,比第一种方法更常规。但它的缺点也很明显:1)如前所述,由于句子嵌入来自静态 token 嵌入的平均化,它仍然存在偏差。2)权重平均化使BERT在下游任务中很难进行微调。由于这些原因,我们用第一种方法来表示带有提示的句子。
Prompt Search
第二种方法是将句子映射到 token 上,比第一种方法更常规。但它的缺点也很明显:1)如前所述,由于句子嵌入来自静态 token 嵌入的平均化,它仍然存在偏差。2)权重平均化使BERT在下游任务中很难进行微调。由于这些原因,我们用第一种方法来表示带有提示的句子。
对于人工搜索,我们需要手工制作模板,鼓励将整个句子用 $h_{[MASK]} $ 表示。为了搜索模板,我们将模板分为两部分:关系token,表示 $[X]$ 和 $[MASK]$ 之间的关系;前缀token,包裹 $[X]$ 。然后,我们贪婪地搜索遵循关系 token 和前缀 token的模板。
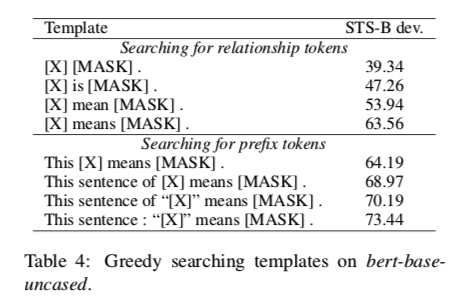
表4中显示了一些贪婪搜索的结果。当涉及到句子嵌入时,不同的模板产生了极其不同的结果。与简单地连接 $[X]$ 和$[MASK]$ 相比,复杂的模板如这句话:” $[X]$ “意味着 $[MASK]$,可以提高34.10的spearman相关度。
对于基于T5的模板生成,Gao等人(2020)提出了一种新颖的方法,通过使用T5根据句子和相应的标签来自动生成模板。在GLUE基准测试中,生成的模板可以胜过人工搜索的模板(Wang等人,2018)。
然而,实现它的主要问题是缺乏 token 标签。Tsukagoshi等人(2021年)通过根据字典将定义句子分类到其单词,成功地将句子嵌入任务转化为文本分类任务。受此启发,我们使用单词和相应的定义来生成500个模板(例如,橙子:一种大而圆的多汁柑橘类水果,有坚韧的鲜红黄色的外皮)。然后,我们在STS-B开发集中对这些模板进行评估,与模板 “也叫[MASK]”的最佳spearman相关度为64.75。[X]”. 也许这就是句子嵌入和单词定义之间的差距。与人工搜索相比,这种方法不能产生更好的模板。
OptiPrompt(Zhong等人,2021)用连续模板取代了离散模板。为了优化连续模板,我们按照(Gao et al., 2021)的设置,使用无监督的对比学习作为训练目标,冻结整个BERT参数,连续模板由手工模板的静态 token 嵌入初始化。与输入的人工模板相比,连续模板可以将STS-B开发集的spearman相关度从73.44提高到80.90。
Prompt Based Contrastive Learning with Template Denoising
最近,对比性学习成功地利用了句子嵌入中的BERT的力量。句子嵌入对比学习中的一个挑战是如何构建适当的正向实例。Gao等人(2021)直接将BERT中的dropout作为正例。Yan等人(2021)讨论了四种数据增强策略,如对抗性攻击、token shuffling、cutoff 和输入 token 嵌入中的dropout来构建正面实例。在基于提示的句子嵌入的激励下,我们提出了一种新的方法来合理地生成基于提示的正面实例。
这个想法是用不同的模板来表示同一个句子的不同观点,这有助于模型产生更合理的正向对。为了减少模板本身对句子表述的影响,我们提出了一种新的方法来去掉模板信息。给定句子 $x_i$,我们首先用模板计算出相应的句子嵌入$h_i$。然后,我们通过直接给BERT输入模板和相同的模板位置 id 来计算模板偏差 $\hat h_i$。例如,如果 $x_i$ 有5个 token,那么 [X] 后面的模板标记的位置id将被加上 5,以确保模板的位置id是相同的。最后,我们可以直接使用 $h_i - \hat h_i$ 作为去噪后的句子表示。关于模板去噪,更多细节可以在讨论中找到。
形式上,让 $h_i’$ 和 $h_i$ 表示不同模板的 $x_i$ 的句子嵌入,$\hat h_i’$和 $\hat h_i$ 分别表示 $x_i$ 的两个模板偏差,最终训练目标如下:
其中,$τ$ 是对比学习中的一个温度超参数,N 是小批量的大小。
 wechat
wechat alipay
alipay





