Parameter-Efficient Tuning by Manipulating Hidden States of Pretrained Language Models For Classification Tasks
Parameter-Efficient Tuning by Manipulating Hidden States of Pretrained Language Models For Classification Tasks
Parameter-Efficient tuning旨在通过优化一些引入的参数的同时,冻结 PLMs 来提取下游任务的知识。
连续的 prompt tuning 在输入的嵌入中预先加入一些可训练向量。是其中的一种方法,由于其有效性和效率而受到广泛关注。这个系列的方法可以被理解为对PLM内部的隐藏状态进行了非线性转换。
然而,一个自然的问题被忽略了:隐藏状态能否直接用于分类而不改变它们?在本文中,我们旨在通过提出一种简单的 tuning 方法来回答这个问题,这种方法只引入了三个可训练的向量。
首先,我们使用引入的向量整合不同层的隐藏状态。然后,我们将整合后的隐藏状态输入到一个特定任务的线性分类器中,以预测类别。
这个方案类似于ELMo利用隐藏状态的方式,只是他们将隐藏状态反馈给基于LSTM的模型。 虽然我们提出的tuning 方案很简单,但它取得了与 P-tuning 和 P-tuning v2等 prompt tuning 方法相当的性能,验证了原始隐藏状态确实包含分类任务的有用信息。此外,我们的方法在时间和参数数量上比 prompt tuning 有优势。
Introduction
为了将 PLM 重用于不同的任务,已经提出了越来越多的 parameter-efficient tuning 方法。 他们旨在通过仅优化少量额外参数,从冻结的 PLM 中挖掘特定于任务的信息。
Adapter tuning 建议将两个可训练的 Adapter 插入到每个 transformer 中,这些适配器由一些简单的变换组成。 虽然适配器达到了近乎 state-of-the-art 的性能,但它引入的额外参数数量仍然非常多,并且原始 transformer 的架构也需要修改。
《Few- shotqa: A simple framework for few-shot learning of question answering tasks using pre-trained text- to-text models》 试图规避预训练和 tuning 过程之间的错位,因其在 few-shot 情况下的优越性而受到广泛关注。
《Pre-train, prompt, and predict: A systematic survey of prompting methods in natural language processing》包括离散prompt tuning 和连续prompt tuning,是最流行的方法。离散prompt tuning通常在输入句子中插入一些标记(出现在模型的词汇中),将任务重新表述为填空问题。然而,离散prompt tuning的调整涉及到巨大的人工努力,在高资源数据集上的表现更差,限制了其使用。连续 prompt tuning 不是插入离散的标记,而是在输入句子的嵌入中增加特定任务的可训练向量。在训练期间,只有这些特定任务的向量被优化。他们的实验表明,通过这些额外的向量,有可能从冻结的PLMs中获取知识。
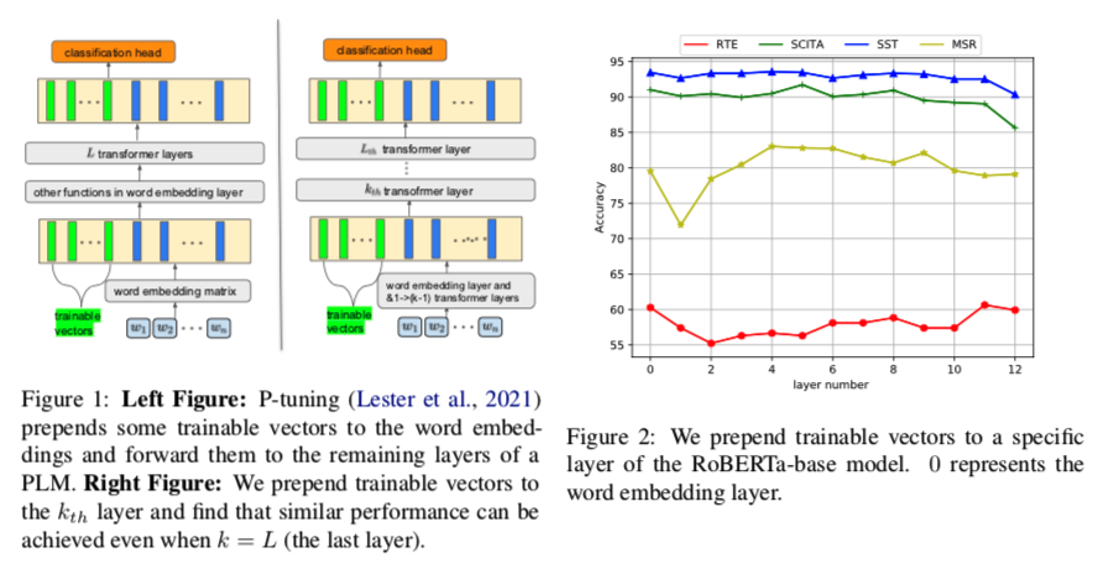
《The power of scale for parameter-efficient prompt tuning》试图利用提示向量的意义,发现它们的词邻往往是相似的词,说明连续 prompt tuning 与离散 prompt tuning 完全不同。另外,如图1所示,与P-tuning将可训练向量预置到词嵌入中不同,我们尝试将这些向量预置到特定的 transformer 中。图2描述了四个任务的准确性。我们可以看到,将向量预置到任何一层,甚至最后一层,都可以取得类似的结果。我们从这个现象中得到两个启发。(i) 当可训练的向量被插入到最后一个 transformer 时,P-tuning甚至也能发挥作用。这是否意味着这些原始的隐藏状态已经包含了大部分甚至所有用于分类的信息?(ii) 当向量被预置到第0层时,可能无法获得最好的准确性。这与ELMo类似,表现为不同层对下游任务有不同的权重
在本文中,通过提出一种只引入三个可训练向量的简单方法,表明分类信息可以很容易地提炼出来。
这个方法首先获得了输入的所有隐藏状态,并学习了一个softmax归一化的权重向量来堆叠跨层的隐藏状态。其次,一个软掩码向量被用来选择隐藏状态中对下游任务有用的维度子集。最后,进行仅由一个可训练向量组成的自我注意操作,以输出用于分类的状态。
我们发现,分类信息在表面,这意味着没有必要使用复杂的分类头,如LSTM,CNN。我们的分类头只包含一个线性转换,然后是一个softmax函数。
我们在各种任务上进行了实验,结果表明,我们的方法可以达到与P-tuning和P-tuning v2所取得的性能相当。这证实了原始的隐藏状态确实包含了分类所需的信息,而且这种信息可以通过简单的线性转换来提取。我们希望这一发现能够帮助推进对连续 prompt tuning 方案的理解。
Preliminaries
在这一节中,我们首先介绍了一些 tuning 方案的背景,介绍了ELMo和 transformer 家族语言模型如何应用于下游分类任务。
ELMo
ELMo 的骨干是 L 层双向LSTM。经过预训练,当有一个下游任务时,ELMo学习了一个特定任务的跨层隐藏状态的线性组合,并将这些隐藏状态输入到基于 LSTM 的模型,以输出一个输入的目标:
其中 $h{k,j}$ 是第 $j$ 层中第 $k$ 个token的隐藏状态。$h{k,0}$是第 $k$ 个token词嵌入层表示。$(s_0,s_1,…,s_L)$ 是任务特定的softmax归一化权重的表示,它们在训练下游任务时被优化。这些权重允许模型根据下游任务的属性,利用不同层次的表征(例如,语法、语义)。$\gamma$ 是可训练标量,其用于辅助优化过程。$e_k$ 是第 $k$个词的最终加权嵌入。最后,$[e_1, e_2, …, e_n]$被输入到量身定做的模型(通常是一个复杂的网络,如LSTM),以预测标签或生成特定任务的目标句。
The Transformer Family
在根据下游任务调整PLM时,最常用的方法叫做微调,把PLM和特定任务的分类器 $C$ 一起优化:
其中 $C、E$分别代表特定任务的分类头和编码器(一个PLM)。$β,θ$ 分别是 $C$ 和 $E$ 的参数。Fine tuning LM通常可以获得令人满意的性能。然而,在新数据按顺序出现的情况下,这种调整方案不再起作用。 因为当一个新的数据集出现时,我们要么重新训练所有的数据,要么为新的数据训练一个单独的模型。由于耗费大量时间和存储,这两种方法都是不可接受的。因此,研究人员试图通过引入一些可训练的参数,从冻结的PLM中提炼出知识。
Adapter tuning 和连续 prompt tuning 是两种普遍的方法。这里,我们只介绍第二种。有许多关于连续 prompt tuning 的工作,我们对其中的两个进行了详细介绍
P-tuning 对于一个输入句子 $x=(x_1,x_2,…,x_n)$,P-tuning在 $x$ 的词嵌入矩阵中加入K个向量,用 $P(x)=[w_0,p_1,p_2,…,p_K,w_1,…,w_n]$表示。$w_0$ 是[CLS] token 的嵌入。$P(x)$ 被输入到PLM的其余各层以预测 $x$ 的标签,优化目标是:
我们可以看到,在训练期间,只有预置的向量和分类器被优化。虽然P-tuning的想法受到离散 prompt tuning 的启发,但这两者并没有显示出任何共同的特征。例如,在将 $p_i,…, p_K$ 映射到词汇中最接近的词后,这些词往往是类似的词(如technology,technologies),这并没有显示出连续 prompt tuning 背后的机制是像离散 prompt tuning 那样利用PLM的语言建模特性。最近的一项工作(He et al., 2021)揭示了P-tuning和适配器之间的联系,他们发现P-tuning相当于原始隐藏状态和由预置向量产生的新隐藏状态的加权平均值。应该注意的一点是,这些向量是由数据集中的所有样本共享的。同样的新隐藏状态可以应用于所有不同的样本,这有点不可思议。一个可能的解释是,原始的隐藏向量已经包含了用于分类的信息,而这正是我们论文的重点。
P-tuning v2 是一种变种的P-tuning,可以扩展到困难的任务,与P-tuning相比,取得了更好的性能。与P-tuning不同的是,P-tuning将向量插入到单词嵌入矩阵中,而这些向量在后面几层的隐藏状态是根据前一层的表示来计算的,P-tuning v2利用多层提示,将一组可训练的向量插入到PLM的每层。换句话说,第 $l$ 层的原始隐藏状态会受到第 $l - 1$ 层的提示向量的影响。由于引入了更多的可训练向量,这种修改使得每个任务的容量更大。
Proposed Approach
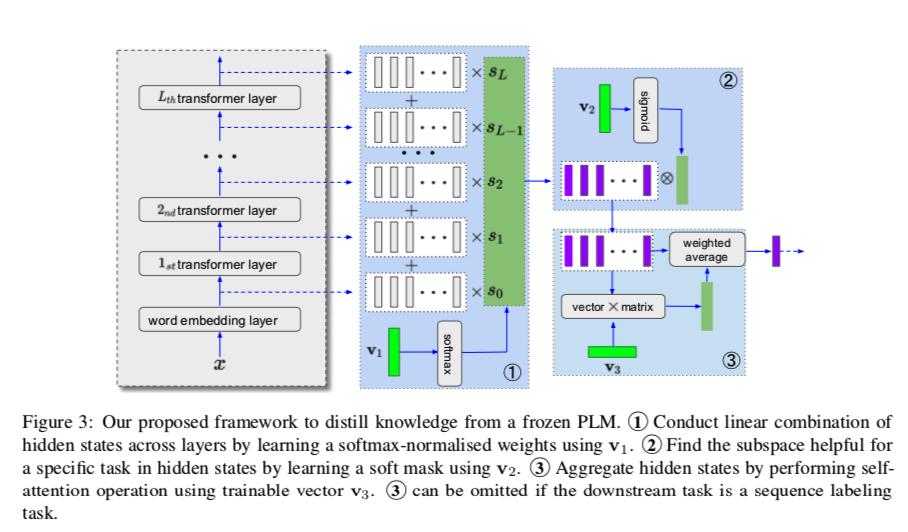
该方法直接操纵不同层的隐藏状态。与通过改变隐藏状态来提炼有用信息的 adapters 和 prompt tuning 方法不同,我们对原始隐藏状态进行操作。由于有许多方法可以整合这些隐藏状态,我们只介绍最简单的方法,由三部分组成。
Layer-Level Weighted Addition
这一步与公式1类似,只是我们不使用标量 $\gamma $。形式上,给定输入x,我们首先获得隐藏状态:
其中 $L$ 为tansformer 层数, 第 $0$ 层是词嵌入层,$N$ 是 $x$ 的长度。每个 $h_{i,j}$ 是一个 $d$ 维向量,每个 $H_i$ 是一个 $d×(N+1)$维矩阵。然后,我们给每个层分配一个权重,因为以前的工作表明,低层、中层、顶层捕捉的信息粒度不同,不同的下游任务可能对这些层有不同的关注。
我们通过引入第一个可训练向量 $v_1\in R^{L+1}$来实现这一目标:
Subspace Mining
我们认为,对于一个d 维的隐藏状态,存在一个维度为 $d_1$ 的子空间,它包含下游任务的区分信息。用二进制掩码向量选择这样的子空间是一种选择,但它在优化方面有困难《 Masking as an efficient alternative to finetuning for pretrained language models》。在此,我们通过引入第二个可训练向量 $v_2\in R^d$ 来采用软屏蔽策略:
如果下游的任务是一个序列标记 任务,如命名实体识别,H可以直接用于分类。然而,对于情感分类、自然语言推理等任务,应该进行进一步的处理步骤。
Self-Attention
使用 Self-Attention 来聚合矩阵 $H$ 。但是这种 Self-Attention 需要很多参数, 引入第三个可训练向量 $v_3\in R^d$ :
Task-Specific Classification
有了 $h$ 和 $H$ ,我们可以把它们输入到特定任务的分类头。为了说明原始隐藏状态包含了大部分(如果不是全部)分类信息,而且这些信息都在表面,我们只进行了线性变换和softmax操作来输出标签,对于序列标签任务:
对于情感分类 :
在训练过程中,只有v1、v2、v3和w是被操作的。因此,与P-tuning和P-tuning v2相比,我们的方法在内存和时间方面更加有效,因为额外的参数不参与PLM内部的计算,而且输入长度也没有增加。在第4.2节,我们将提供一个详细的分析。
Experiments
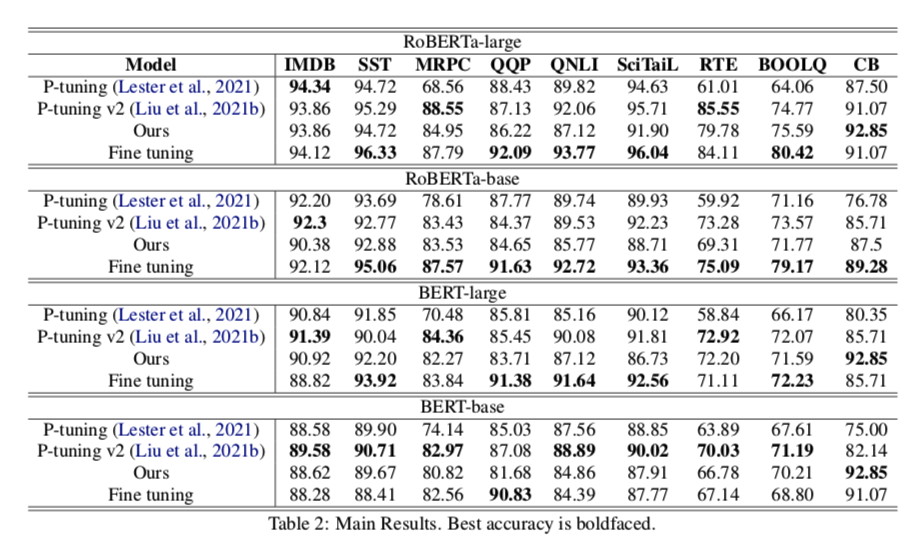
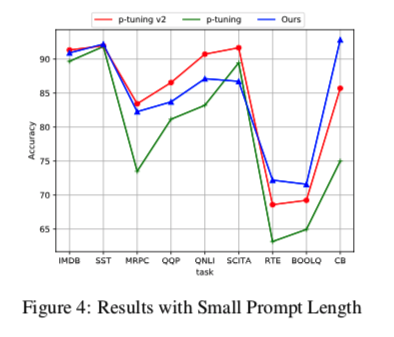
为了考察这些调谐方法在额外参数数量上的表现,我们把P-tuning中的提示向量数量减少到3个,把P-tuning v2中的提示向量数量减少到1个,结果见图4。我们可以发现Ours在整体上优于P-tuning,与P-tuning v2相当。我们还尝试增加Ours的参数数量,即引入多个V3来形成多头自关注,但发现性能没有改善。这可能是我们方法的一个缺点。
 wechat
wechat alipay
alipay





