SPoT: Better Frozen Model Adaptation through Soft Prompt Transfer
SPoT: Better Frozen Model Adaptation through Soft Prompt Transfer
在 《The Power of Scale for Parameter-Efficient Prompt Tuning》的 PROMPTTUNING 方法(学习特定任务的软 prompt,以调节冻结的语言模型来执行下游任务)的基础上,提出了一种新的基于Prompt 的迁移学习方法,称为SPOT:Soft Prompt Transfer。
SPOT首先在一个或多个源任务上学习 prompt,然后用它来初始化目标任务的 prompt。
更重要的是,SPOT 大于等于 model-tuning ,同时参数效率更高(最多可减少27,000倍的特定任务参数)。
进一步对26个NLP任务和160个源-目标任务的组合进行了大规模的任务迁移性研究,并证明了多任务往往可以通过 Prompt Transfer 而相互受益。
最后,提出了一种简单有效的检索方法,将任务 prompts 解释为任务 embeddings,以识别任务之间的相似性,并预测最可迁移的源任务用于新目标任务。
Introduction
越来越大的预先训练的语言模型是获得最佳性能的关键因素。虽然这一趋势不断推动着各种NLP基准的可能性,但这些模型的巨大规模对实际应用提出了重大挑战。对于100B以上的参数模型,为每个下游任务微调和部署一个单独的模型实例将是非常昂贵的。
为了绕过微调的不可行性,GPT-3 提出了 Prompt design,其中每一个下游任务都被铸成一个语言建模任务,冻结的预训练模型通过对推理时提供的手动文本 prompts 调节来执行不同的任务。
Brown等人(2020)用一个冻结的GPT-3模型展示了令人印象深刻的 few-shot 性能,尽管其性能高度依赖于 prompt 的选择,并且仍然远远落后于最先进的微调结果。
最近的工作探索了学习软prompt的方法(
- 《Gpt understands, too》
- 《Learning how to ask: Querying LMs with mixtures of soft prompts》
- 《Prefix-tuning: Optimizing continuous prompts for generation》
- 《The power of scale for parameter-efficient prompt tuning》
),这可以被视为注入语言模型的额外可学习参数。
PROMPTTUNING 在适应过程中为每个下游任务学习一个小的特定任务 prompt(一个可调整的标记序列,预置在每个样本中),以调节冻结的语言模型来执行该任务。
引人注目的是,随着模型容量的增加,PROMPTTUNING 与 model-tuning 比较起来,后者在每个下游任务上对整个模型进行微调。然而,在小规模和中等规模的模型(小于11B参数)中,PROMPTTUNING 和 model tuning 之间仍有很大差距。
例如,对于T5 BASE(220M参数)和T5 XXL(11B参数)模型,在SuperGLUE基准上分别获得了+10.1和+2.4点的平均精度改进。SPOT在所有模型规模上的表现都比model tuning有竞争力或明显更好
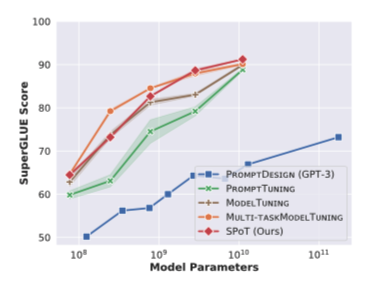
在这些结果的激励下,通过任务 prompts 的视角来研究任务之间的可迁移性。目标是回答以下问题:
(a) 对于一个给定的目标任务,何时将 prompt 初始化为源任务的 prompt 有助于提高性能?
为了解决(a),作者使用26个NLP任务和160个源-目标任务的组合对T5模型进行了系统研究。结果表明,任务往往可以通过prompt transfer 而相互受益。
(b) 能不能利用任务 prompt,对给定的新目标任务使用哪些源任务做出更有原则的选择?
为了解决(b),把学到的任务 prompt 解释为任务嵌入,以构建一个任务的语义空间,并规范任务之间的相似性。设计了一种高效的检索算法,用来测量任务嵌入的相似性,使能够识别那些有可能对给定的新目标任务产生积极迁移性的源任务。
Improving PROMPTTUNING with SPOT
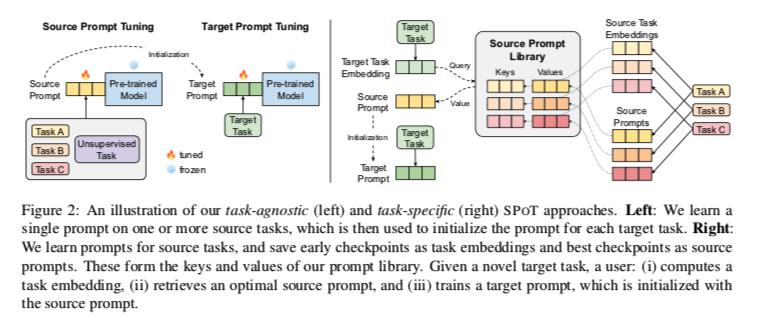
为了提高PROMPTTUNING的性能,SPOT引入了源 prompt tuning,这是语言模型预训练和目标 prompt tuning 之间的一个中间训练阶段(如图左),在一个或多个源任务上学习prompt(同时仍保持基础模型冻结),然后用来初始化目标任务的prompt。
Experimental setup
冷冻模型是建立在预先训练好的各种尺寸的T5 checkpoints 之上的。SMALL、BASE、LARGE、XL、XXL,参数分别为60M、220M、770M、3B和11B。在对SPOT的实验中,利用了T5的LM adapted(prefix LM)版本,发现它更容易为PROMPTTUNING优化。
Baselines
- PROMPTTUNING : vanilla prompt tuning approach , 其中针对每个目标任务直接训练独立提示。
- MODELTUNING & MULTI-TASKMODEL TUNING: 将 prompt tuning 方法与MODELTUNING—标准的微调方法进行比较,其中所有的预训练参数都在每个目标任务上分别进行微调。为了进行 apples-to-apples 的比较,我们还包括MULTI-TASKMODEL TUNING,这是一个更有竞争力的基线,首先在SPOT使用的相同混合源任务上微调整个模型,然后在每个目标任务上单独微调。
Evaluation datasets
在GLUE 和SuperGLUE 基准(每个基准都有8个数据集)的不同任务集上研究下游的性能。
Data for source prompt tuning
与语言模型的预训练一样,训练数据的选择对于成功的 prompt transfer至关重要。为了研究源训练数据对下游性能的影响,我们比较了一系列不同的源任务。
- A single unsupervised learning task : 首先考虑在C4数据集上使用 “prefix LM” 目标训练一个 prompt。虽然这个任务是用来预先训练冷冻T5模型的,但它仍然可以帮助学习一个通用的提示。
- A single supervised learning task : 另外,我们可以使用监督任务来训练 prompt。我们使用MNLI或SQuAD作为单源任务。MNLI被证明对许多句子级别的分类任务有帮助,而SQuAD被发现对QA任务有很好的概括性。
- A multi-task mixture : 到目前为止,我们一直在对单一来源的任务进行训练提示。另一种方法是多任务训练。在T5的统一文本到文本框架内,这只是相当于将不同的数据集混合在一起。我们探索混合来自不同NLP基准或任务系列的数据集,包括GLUE、SuperGLUE、自然语言推理(NLI)、转述/语义相似性、情感分析、MRQA的问题回答、RAINBOW的常识推理。 我们使用Raffel等人(2020)的例子—比例混合策略,从上述每个NLP基准/任务家族中创建了一个源任务的mixture,人工数据集大小限制为K = 219个训练例子。最后,我们包括C4和上述NLP基准/任务族中的所有标记数据集的混合(55个数据集)。
遵循 PROMPTTUNING 的观点。,我们使用 CLASS-LABEL 方案(其中 prompt tokens用表示输出类的合并的嵌入来初始化)来初始化提示,并退回到SAMPLEDVOCAB方案以填充任何剩余的提示位置)。
Effect of SPOT
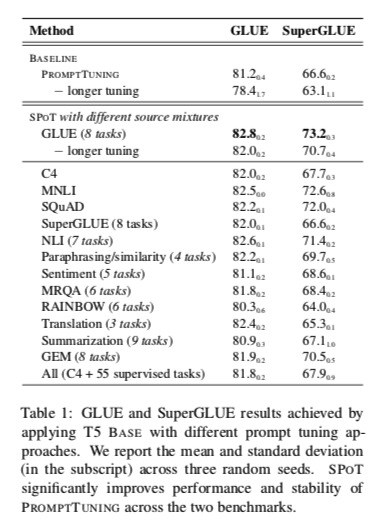
我们在图1和表1中比较了SPOT和其他方法的结果。下面,我们对每个发现进行详细的总结和分析。
- SPOT significantly improves performance and stability of PROMPTTUNING: 表1显示了我们在T5-BASE glue 和SuperGlue基准上的结果。总体而言,结果表明,prompt transfer 为 PROMPTTUNING 提供了一种提高性能的有效手段。我们的烧蚀研究表明,Longer tuning 也是实现我们最佳性能的一个重要因素,并且是对 prompt transfer 的补充。此外,当Longer tuning 被省略时,我们观察到SPOT在不同的运行中提高了稳定性。
- Different source mixtures can lead to performance gains: 在SPOT方法中,我们可以比较不同来源混合的有效性(见表1)。在GLUE和SuperGLUE上的源 prompt tuning 表现最好,分别获得82.8和73.2的平均分数。有趣的是,C4上的无监督源 prompt tuning(与预训练我们的冻结模型的任务相同)仍然产生了相当大的改进,甚至在SuperGLUE任务中超过了SuperGLUE的源 prompt tuning。此外,使用MNLI或SQuAD作为单一源数据集对GLUE和SuperGLUE都特别有帮助。最后,其他来源的混合也能带来明显的收益,一些NLP基准/任务家族(如NNLI和转述/语义相似性)比其他任务更有利。
- SPOT helps close the gap with MODELTUNING across all model sizes: 最后,SPOT产生了与强大的MULTI-TASKMODEL TUNING基线相竞争的性能,同时在多任务源 tuning 和目标 tuning 方面参数效率更高;在XXL尺寸下,SPOT获得了91.2的最佳平均得分,比MULTI-TASKMODELTUNING好+1.1分,尽管其特定任务参数少27000倍。
Investigating task transferability
在确定了 prompt transfer 对 prompt tuning 有帮助之后,我们现在将重点转移到通过任务prompts 的视角来研究任务迁移性。
为了阐明不同任务之间的可迁移性,我们对26个NLP任务(包括一个无监督的任务)和160个源-目标任务的组合进行了大规模的实证研究。我们证明,在各种情况下,任务可以通过 prompt transfer 来互相帮助,而任务的相似性在决定迁移性方面起着重要作用。
此外,我们表明,通过将任务prompts解释为任务嵌入,我们可以构建一个任务的语义空间,并制定一个更严格的任务相似性概念。最后,我们提出了一种检索算法,该算法测量任务嵌入的相似性,以选择哪些源任务用于给定的新目标任务(图2,右)。
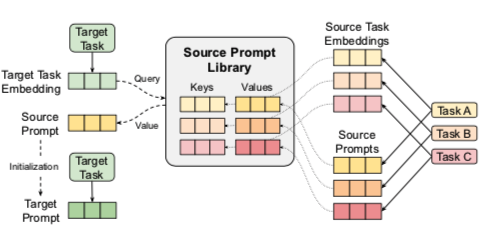
我们学习源任务的prompts,并将早期检查点作为任务嵌入,将最佳检查点保存为源prompts。这些构成了我们prompts库的键和值。给定一个新的目标任务。用户:(i) 计算一个任务嵌入,(ii) 检索一个最佳的源prompt,(iii) 训练一个目标prompt,该prompt以源prompt为初始化。
Experimental setup
我们研究了16个源数据集和10个目标数据集的不同集合(见表2)。我们考虑了所有160对可能的源和目标数据集,并从每个源任务转移到每个目标任务。
Source and target tasks
源任务包括一个无监督任务(C4)和15个监督任务,涵盖自然语言推理(NLI)、转述/语义相似性、情感分析、问题回答(QA)和常识推理。所有的源任务都是数据丰富的,或者在以前的工作中已经被证明产生了积极的转移。为了模拟一个真实的场景,我们使用低资源任务(少于1万个训练实例)作为目标任务。这些任务涵盖了上述类型的任务,此外还包括语法可接受性、词义消歧和核心推理的解决。
Training details
为了限制计算成本,我们在所有的任务迁移性实验中使用T5 BASE。我们在每个源任务上执行262,144个 prompt tuning 步骤。选择具有最高源任务验证性能的 prompt checkpoint 来初始化不同目标任务的 prompt。由于目标数据集较小,我们只对每个目标任务进行100K的 prompt tuning 步骤。
Constructing a semantic space of tasks
由于在具体任务的 prompt tuning 过程中只有 prompt 参数被更新,任务prompt很可能编码了特定的任务知识。这表明,它们可以被用来推理任务的性质及其关系。为了测试这个想法,我们将任务 prompt 解释为任务嵌入,并构建一个任务语义空间。请注意,虽然我们使用源任务的最佳 prompt checkpoint 来迁移到目标任务中,但我们使用早期的 prompt checkpoint 作为我们的任务嵌入。这使得新的目标任务的任务嵌入可以快速计算。在我们的实验中,任务嵌入来自一个固定的prompt checkpoint,即在10K步,为每个任务。我们通过测量它们对应的任务嵌入 $e^1$, $e^2$之间的相似性来估计两个任务 $t^1$, $t^2$ 之间的相似性,使用以下指标:
COSINE SIMILARITY OF AVERAGE TOKENS: 计算 prompt tokens 的平均集合表示之间的余弦相似度。
$sim(t^1,t^2) = cos(\frac{1}{L} \sum_i e^1_i, \frac{1}{L}\sum_j e_j^2)$ , 其中 $e^1_i,e^2_j$ 定义为各自的 prompt tokens
PER-TOKEN AVERAGE COSINE SIMILARITY: 计算每个 prompt token 对之间的平均余弦相似度 $(e_i^1,e^2_j)$:
$sim(t^1,t^2) = \frac{1}{L^2} \sum_i\sum_j cos(e_i^1,e_j^2)$
Predicting and exploiting transferability
利用任务嵌入来预测和利用任务迁移性。具体来说,我们探索了预测对给定目标任务最有利的源任务的方法,然后利用其prompt 来提高目标任务的表现。
为了扩大我们的源 prompts 集,我们使用了每个源任务上所有三个不同的 prompt tuning运行的 prompt,从而产生了48个源 prompts。给定一个具有任务嵌入的目标任务 $t$ ,我们将所有的源prompts $ρ^s$按其对应的任务嵌入$e^s$ 和目标嵌入$e^t$之间的相似度从高到低排序。
我们将源prompts 的排序列表表示为 $ρ^{s_r}$,其中r表示排序(r=1,2,…,48)。我们用以下方法进行实验:
- BEST OF TOP-k : 选择前 k 个源prompts,并分别使用它们来初始化目标prompt。这个过程需要对目标任务 t 进行 k 次prompt tuning,每个源prompt一次。然后,最好的单个结果被用来评估这个方法的有效性。
- TOP-k WEIGHTED AVERAGE: 用前k个源prompt 的加权平均数初始化目标prompt $\sum{r=1}^k \alpha_r ρ^{s_r}$,这样我们只对目标任务 $t$ 进行一次提示调整。 权重 $\alpha_r = \frac{sim(e^{s_r, e^t})}{\sum{l=1}^k sim(e^{s_l, e^t})}$, $e^{s_r}$表示相应的任务嵌入 $ρ^{s_r}$
- TOP-k MULTI-TASK MIXTURE: 首先确定 prompt 在前k个 prompt 中的源任务,并将其数据集和目标数据集混合在一起,使用Raffel等人(2020)的例子-比例混合策略。然后,我们在这个多任务混合物上进行源prompt tuning,并使用最后的 prompt checkpoint 来为目标 prompt tuning 进行初始化。
Evaluation
我们报告了通过使用上述每一种方法在目标任务中取得的平均分数。对于每个目标任务 $t$ ,我们衡量三个不同的 prompt tuning 运行(导致不同的任务嵌入等)的平均和标准偏差。为了进行比较,我们报告了在对每个目标任务从头开始进行prompt tuning(即没有任何 prompt Transfer)时,比基线的绝对和相对改进。此外,我们还包括通过使用暴力搜索来确定每个目标任务的48个源 prompt 中的最佳 prompt 所取得的谕示结果。
Effect of prompt-based task embeddings
在这一部分中,我们首先分析我们的任务可迁移性结果。然后,我们论证了使用基于 prompt 的任务嵌入来表示任务、预测和开发任务可迁移性的有效性。
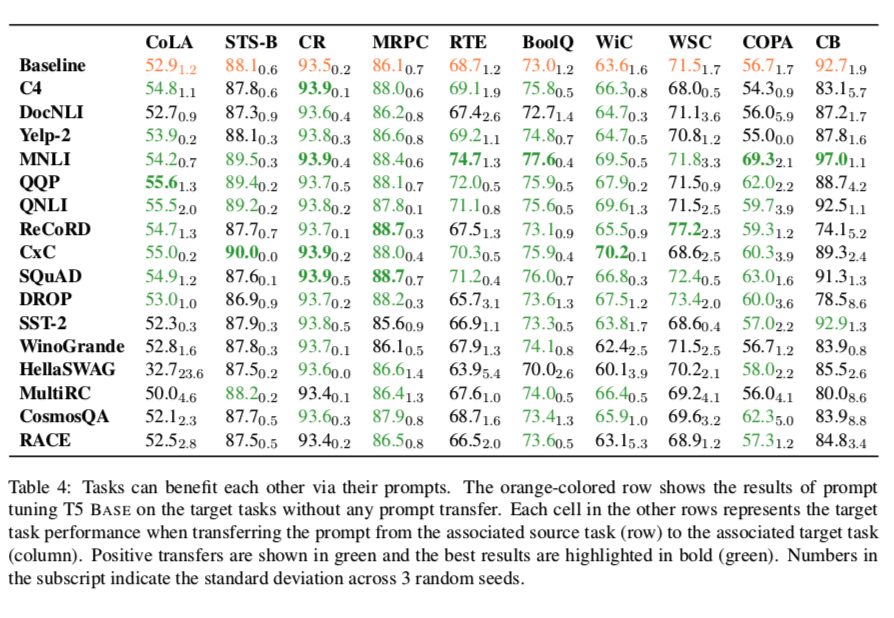
Tasks can help each other via prompt transfer in various scenarios: 实验结果表明,在许多情况下,将 prompt 从源任务转移到目标任务(SOURCE → TARGET)可以在目标任务上提供显著的增益。
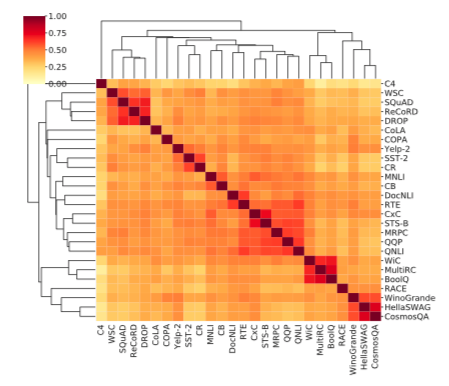
Task embeddings capture task relationships : 图3显示了研究的26个NLP任务的任务嵌入之间的余弦相似性的分层聚类热图,使用的是平均托肯斯的余弦相似性指标。具体来说,类似的任务被归为几个集群,包括问题回答(SQuAD、ReCoRD和DROP;MultiRC和BoolQ)、情感分析(Yelp-2、SST-2和CR)、NLI(MNLI和CB;DocNLI和RTE)、语义相似性(STS-B和CxC)、副词(MRPC和QQP)和常识推理(WinoGrande、HellaSWAG和CosmosQA)。我们注意到,QNLI是由SQuAD数据集建立的NLI任务,与SQuAD没有密切联系;这表明我们的任务模型对任务类型比领域相似性更敏感。有趣的是,它们也捕捉到了ReCoRD对WSC的高可转移性这一非直观的情况。此外,来自同一任务的不同提示的任务嵌入具有很高的相似性分数
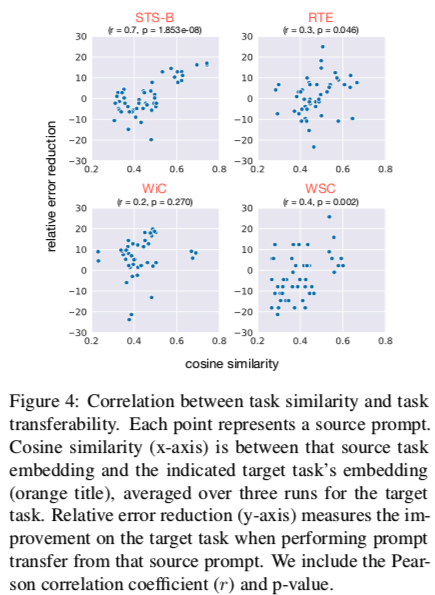
Correlation between task embedding similarity and task transferability: 图4显示了目标任务上的相对误差减少是如何作为源和目标任务嵌入之间的相似性的函数而变化的。总的来说,我们发现,在我们研究的四个(10个)目标任务上,任务嵌入的相似性和任务可转移性之间存在明显的正相关,包括STS-B(p < 0.001),CB(p < 0.001,未显示),WSC(p < 0.01),和RTE(p < 0.05),而在其他任务上则不太明显。
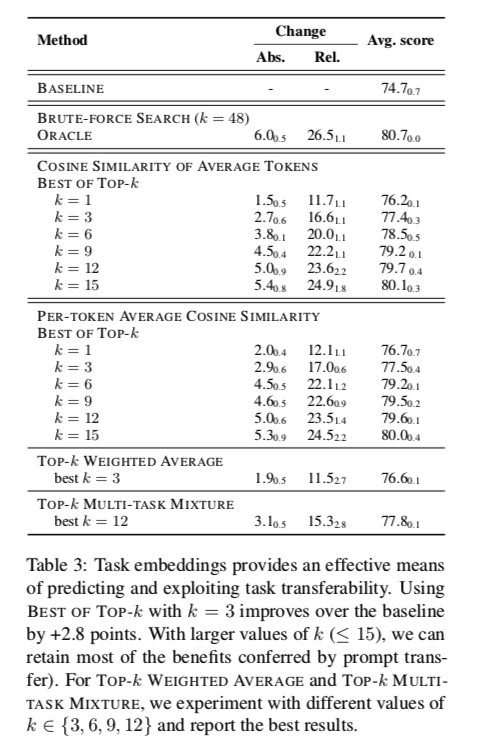
Task embeddings can be used to predict and exploit task transferability: 我们在表3中比较了不同方法的结果,以确定哪些源提示可能对给定的目标任务有益。我们发现,对于小的k值(≤9),使用每键平均COSINE SIMILARITY指标比使用AV-ERAGE TOKENS的COSINE SIMILARITY指标产生更好的结果。我们的结果还表明,BEST OF TOP-k提供了一个预测和利用任务转移性的有效手段。简单地选择源提示,其相关的任务嵌入与目标嵌入具有最高的相似性,使用每键平均COSMINE SIMILARITY度量,比基线有很大的改善(从平均得分74.7到76.7,平均相对误差减少12.1%)。为每个目标任务尝试所有前三名(共48个)的源提示,得到的平均分数为77.5分。随着k值的增大,我们可以保留神谕选择源提示的大部分好处(k=9时平均得分的80%,k=15时平均得分的90%),同时仍然可以消除2/3以上的候选源提示。尽管这种方法需要对目标任务进行K次提示调谐,但与模型调谐相比,提示调谐的成本相对低廉。在k=1的情况下,TOP-k加权平均法与BEST OF TOP-k的平均性能相似,但实现的方差较小。因此,在禁止对tar-get任务进行多次调谐的情况下,这可能是对BEST OF TOP-k的一个有吸引力的替代方案。最后,TOP-k MULTI-TASK MIXTURE也提供了一种获得强大性能的方法,其平均得分为77.8,甚至在k≤3的情况下超过了BEST OF TOP-k。
Related Work
Parameter-efficient transfer learning & lan- guage model prompting
预训练的语言模型已被证明是改善许多NLP基准的最先进结果的有效手段(Devlin等人,2019;Liu等人,2019b;Yang等人,2019;Lan等人,2020;Raffel等人,2020;Brown等人,2020;He等人,2021)。然而,MODELTUNING(又称微调)—目前将这些模型应用于下游任务的主流方法—可能变得不切实际,因为为每项任务微调所有预训练的参数可能过于昂贵,特别是随着模型规模的不断扩大。
为了解决这个问题,早期的工作使用了compression技术,如知识分散(Sanh等人,2019;Jiao等人,2020;Sun等人,2020)和模型修剪(Fan等人,2020;Sanh等人,2020;Chen等人,2020),以获得轻型预训练模型。其他工作只更新语言模型的小部分(Zaken等人,2021)或训练特定的任务模块,如适配器(Houlsby等人,2019;Karimi Mahabadi等人,2021)和/或低等级结构(Mahabadi等人,2021;Hu等人,2021),同时保持大部分或全部预训练参数固定。值得注意的是,Brown等人(2020年)使用PROMPTDESIGN的单一冻结的GPT-3模型展示了显著的几次学习性能,其中每个任务都是在推理时间向模型提供手动文本提示,要求它产生一些输出文本。
此后,一些努力集中在开发基于提示的学习方法,包括精心手工制作的提示(Schick和Schütze,2021)、提示挖掘和转述(Jiang等人,2020b)、基于梯度搜索的改进提示(Shin等人,2020)和自动提示生成(Gao等人,2021)。然而,使用硬性提示被发现是次优的和敏感的,即下游表现和提示格式之间没有明显的相关性,提示的微小变化会导致下游表现的显著差异(Liu等人,2021b)。因此,最近的工作已经转向学习软提示(Liu et al., 2021b; Qin and Eisner, 2021; Li and Liang, 2021; Lester et al., 2021),这可以被看作是注入语言模型的一些额外的可学习参数。我们请读者参考Liu等人(2021a)对基于提示的学习研究的最新调查。
同时进行的工作(Gu等人,2021)也探讨了 prompt 预训练的有效性。他们的方法使用手工制作的预训练任务,为不同类型的下游任务量身定做,这限制了其对新型下游任务的应用。相比之下,我们使用现有的任务作为源任务,并表明即使在源任务和目标任务之间存在不匹配(如任务类型、输入/输出格式)的情况下,prompt transfer也能带来好处。他们的工作也集中在 few-shot 的设置上,而我们是在较大的数据集背景下工作。此外,我们研究了任务的可迁移性,并证明任务往往可以通过 prompt transfer 来互相帮助,而任务 prompt 可以被解释为任务嵌入,以正式确定任务的相似性,从而确定哪些任务可以互相受益。
Task transferability
我们还建立在现有的关于NLP的任务迁移性的工作上(Phang等人,2019;Wang等人,2019a;Liu等人,2019a;Talmor和Berant,2019;Pruksachatkun等人,2020;Vu等人,2020;Poth等人,2021)和计算机视觉(Zamir等人,2018;Achille等人,2019;Yan等人,2020)。之前的工作表明,从数据丰富的源任务(Phang等人,2019年)、需要复杂推理和推理的任务(Pruksachatkun等人,2020年)或与目标任务相似的任务(Vu等人,2020年)中有效转移。也有人努力预测任务之间的可转移性(Bingel和Søgaard,2017;Vu等人,2020;Poth等人,2021)。Vu等人(2020)使用来自输入文本或语言模型对角线Fisher信息矩阵的任务嵌入,而Poth等人(2021)探索基于适配器的方法。在这里,我们对T5的使用使我们能够更好地对任务空间进行建模,因为每个任务都被投到一个统一的文本到文本的格式中,并且在不同的任务中使用相同的模型(没有特定的任务成分)。此外,基于提示的任务嵌入相对来说更容易获得。
Conclusion
在本文中,我们研究了在提示调谐背景下的转移学习。我们表明,规模对于PROMPTTUNING与MODEL-TUNING的性能相匹配是没有必要的。我们的SPOT方法在不同的模型规模下与MODEL-TUNING的性能相匹配,甚至超过了MODEL-TUNING的性能,同时参数效率更高(最多可减少27,000倍的特定任务参数)。我们对任务转移性的大规模研究表明,在各种情况下,任务可以通过提示转移而相互受益。最后,我们证明,任务提示可以被解释为任务嵌入,以正式确定任务之间的相似性。我们提出了一种简单而有效的检索方法,以衡量任务的相似性,从而确定哪些源任务可以给一个新的目标任务带来好处。从整体上看,我们希望我们的工作能够促进对基于提示的迁移学习的更多研究。
 wechat
wechat alipay
alipay





