The Power of Scale for Parameter-Efficient Prompt Tuning
The Power of Scale for Parameter-Efficient Prompt Tuning
https://zhuanlan.zhihu.com/p/428512183
在这项工作中,作者探索了 “prompt tuning”,这是一种简单而有效的机制,用于学习 “软提示”,以调节冻结的语言模型来执行特定的下游任务。
与GPT-3使用的离散文本提示不同,软提示是通过反向传播来学习的,并且可以进行调整以合并来自任何数量的标注样本的信号。
此端到端学习方法在很大程度上超过了GPT-3的 few-shot learning。更值得注意的是,通过使用T5对模型规模的消减,表明,随着规模的扩大,prompt tuning变得更有竞争力:当模型超过数十亿个参数时,该方法 “缩小了差距”,与model tuning (其中调整了所有模型权重)的强大性能相匹配。
这一发现尤其重要,因为共享和服务大型模型的成本很高,而将一个冻结模型重用于多个下游任务的能力可以减轻这一负担。
此方法可以看作是对最近提出的 “prefix tuning”,以软提示为条件的冻结模型对领域转移的鲁棒性有好处,并能实现有效的 “prompt ensembling”。
1 Introduction
随着预训练的大型语言模型的广泛成功,出现了一系列的技术来适应这些通用模型的下游任务。ELMo提出冻结预训练的模型,并学习其每层表征的特定任务加权。
然而,自GPT和BERT以来,主流的适应技术是模型调整(或 “微调”),即在适应期间调整所有的模型参数。
最近,GPT3 表明,prompt design (或 “priming”)在通过文本提示来调节冻结的GPT-3模型的行为方面是惊人的有效。提示通常由一个任务描述和/或几个典型的例子组成。这种回到 “冻结 “预训练模型的做法很有吸引力,尤其是在模型规模不断扩大的情况下。与其说每个下游任务都需要一个单独的模型副本,不如说一个通用模型可以同时为许多不同的任务服务。
不幸的是,基于提示的适应有几个关键的缺点。任务描述容易出错,需要人的参与,而且提示的有效性受限于模型输入中能容纳多少条件文本。
因此,下游任务的质量仍然远远落后于 model tuning。例如,GPT-3 175B 在SuperGLUE上的几率性能比微调的T5-XXL低17.5分(71.8比89.3),尽管使用了16倍的参数。
最近提出了几项自动化 prompt 设计。
《 AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts》
虽然这种技术优于人工提示设计,但相对于 model tuning 而言,仍有差距。
《Prefix-tuning: Optimizing continuous prompts for generation》 提出 “prefix tuning” 并 在生成性任务中表现出很强的效果。这种方法冻结了模型参数,并将调整过程中的误差反向传播到预置在编码器堆栈中每一层的前缀激活,包括输入层。
《WARP: Word-level Adversarial ReProgramming》 通过将可训练的参数限制在 masked 语言模型的输入和输出子网络上,简化了这个方法,并在分类任务上显示了合理的结果。
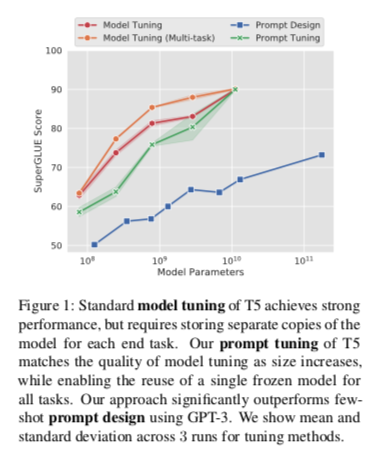
本文提出了 prompt tuning 作为适应语言模型的进一步简化方法。我们冻结了整个预训练的模型,只允许每个下游任务有额外的 $k$ 个可调整的标记被预加到输入文本中。这种 “软提示 “是端到端的训练,可以浓缩来自完整的标记数据集的信号,使我们的方法能够胜过 few-shot prompts,并缩小与模型调整的质量差距。如图1所示,随着规模的扩大,提示调谐变得更具竞争力。
同时,由于一个预训练模型被循环用于所有下游任务,因此我们保留了冻结模型的有效服务优势
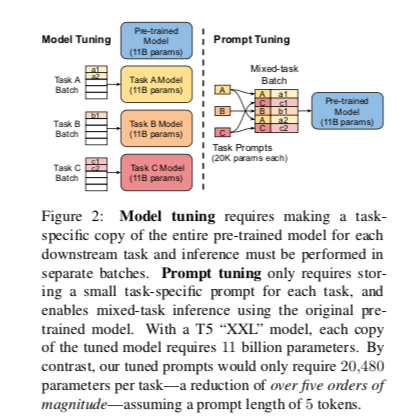
与Prefix-tuning 和 AutoPrompt 虽然都使用 “软提示”,但本文是第一个表明单独的 prompt tuning(没有中间层前缀或特定任务的输出层)就足以与 model tuning 相媲美。
主要贡献:
- 提出 prompt tuning,并证明其在大型语言模型体系中与模型调谐的竞争力。
- 消融了许多设计选择,并证明质量和稳健性随着规模的扩大而提高。
- 表明在领域转移问题上,prompt tuning 优于 model tuning。
- 提出 “prompt ensembling”并显示其有效性。
2 Prompt Tuning
按照T5的 “text-to-text”的方法,将所有的任务作为文本生成。我们现在不是将分类建模为给定某种输入的输出类别的概率$Pr(y|X)$ ,其中 $X$ 是一系列 tokens,$y$ 是一个单一的类别标签,而是将其建模为条件生成,其中 $Y$ 是代表一个类别标签的一系列 tokens。T5将分类建模为 $Pr_θ(Y|X)$,参数由构成其编码器和解码器的 transformer 的权重 $θ$ 决定。
Prompting 是指在生成 $Y$ 的过程中为模型添加额外的信息作为条件的方法。
通常情况下,提示是通过在输入的 $X$ 上预置一系列标记 $P$ 来完成的,这样模型就能最大限度地提高正确 $Y$ 的可能性,即$Pr_θ(Y |[P ; X ])$,同时保持模型参数 $θ$ 的固定。在GPT-3中,prompt tokens的表示,$P={p_1, p_2, …, p_n}$,是模型嵌入表的一部分,由冻结的 $θ$ 作为参数。
因此,寻找最佳 prompt 需要通过人工搜索或无差别搜索方法来选择提示符。
Prompt tuning 消除了提示 $P$ 被 $θ$ 参数化的限制;相反,提示有它自己的专用参数 $θ_P$,可以被更新。prompt design 涉及从固定的冻结嵌入词汇中选择提示标记,而 Prompt tuning 可以被认为是使用固定的特殊标记的提示,其中只有这些提示标记的嵌入可以被更新。
新的条件生成现在是 $Pr_{\theta;\theta_P} (Y| [P;X])$,可以通过反向传播使 $Y$ 的可能性最大化来训练,同时只对 $θ_P$ 应用梯度更新。
给定一系列的 n个 tokens,${x_1, x_2,…, x_n}$,T5做的第一件事就是嵌入这些tokens,形成一个矩阵 $X_e\in R^{n\times e}$,其中 $e$ 是嵌入空间的维度。
soft-prompts 被表达为一个参数 $P_e\in R^{p\times e}$ 其中 $p$ 是prompt长度。
然后,prompt 与嵌入的输入相连接,形成一个单一的矩阵 $[P_e; X_e]\in R^{(p+n)×e}$,然后像平常一样流经编码器-解码器。我们的模型被训练为最大化 $Y$ 的概率,但只有 prompt 参数 $P_e$被更新。
Design Decisions
有许多可能的方法来初始化 prompt 表征。最简单的是从头开始训练,使用随机初始化。一个更复杂的选择是将每个 prompt token 初始化为一个从模型词汇中提取的嵌入。
从概念上讲,soft-prompt 以与输入前的文本相同的方式调节冻结网络的行为,因此,类似于单词的表述可能作为一个好的初始化点。对于分类任务,第三个选择是用列举输出类别的嵌入来初始化 prompt,类似于 “verbalizers”。
由于我们希望模型在输出中产生这些 tokens,用有效的目标 tokens 的嵌入来初始化prompt ,应该使模型将其输出限制在合法的输出类别中。
另一个设计考虑是 prompt 的长度。我们方法的参数成本是 $EP$ ,其中E是 token 嵌入维度,P是 prompt 长度。prompt越短,必须调整的新参数就越少,所以我们的目标是找到一个表现良好的最小长度。
Unlearning Span Corruption
T5 模型的预训练任务是 Span Corruption,模型被要求去重构被打乱的句子
与GPT-3等自回归语言模型不同,我们试验的 T5 模型使用编码器-解码器架构,并对 Span Corruption 目标进行预训练。具体来说,T5的任务是 “重建 “输入文本中被屏蔽的span ,这些跨度被 tokens 为独特的哨兵符号。目标输出文本由所有被屏蔽的跨度组成,用哨兵标记分开,再加上最后一个哨兵标记。
例如。从文本 “Thank you for inviting me to your party last week”中,我们可以构建一个预训练的例子,其中输入是 “Thank you ⟨X⟩ me to your party ⟨Y⟩ week”,目标输出是”⟨X⟩ for inviting ⟨Y⟩ last ⟨Z⟩”。
虽然Raffel等人(2020年)发现这种架构和预训练目标比传统的语言建模更有效,但我们假设这种设置并不适合产生一个可以通过prompt tuning而随时控制的冻结模型。特别是,一个专门针对 Span Corruption 进行预训练的T5模型,如T5.1.1,从未见过真正自然的输入文本(不含哨兵标记),也从未被要求预测真正自然的目标。
事实上,由于T5的 Span Corruption 预处理的细节,每个预训练目标都会以哨兵开始。虽然这种输出哨兵的 “非自然 “倾向很容易通过微调来克服,但我们怀疑,由于解码器的先验因素无法调整,仅通过提示就很难推翻它。
考虑到这些问题,我们在三种情况下试验了T5模型。
- (1) “Span Corruption”。我们使用预先训练好的现成的T5作为我们的冻结模型,并测试其为下游任务输出预期文本的能力。
- (2) “Span Corruption + Sentinel”。我们使用相同的模型,但在所有的下游目标中预置一个哨兵,以便更接近于预训练中看到的目标。
- (3) “LM Adaptation”。我们继续T5的自我监督训练,进行少量的附加步骤,但使用Raffel等人(2020)所讨论的 “LM “目标;给定一个自然文本 prefix 作为输入,该模型必须产生自然文本的延续作为输出。
最重要的是,这种适应性只发生一次,产生一个单一的冻结模型,我们可以在任何数量的下游任务中重复使用,进行prompt tuning。
通过LM adaptation,我们希望将T5 “快速 “转变为一个与GPT-3更相似的模型,GPT-3总是输出真实的文本,并且作为一个 “few-shot learner”,对提示有良好的反应。与从头开始的预训练相比,这种后期转变的成功率并不明显,而且据我们所知,以前也没有人研究过这种情况。因此,我们对各种长度的适应进行了实验,最高可达10万步。
3 Results
实验设定如下:
预训练模型:T5 v1.1 from small to XXL。
默认设置:采用经过额外 100k steps 的 LM Adaption 以后的 T5 模型 + 100 tokens 的 prompt。
评测数据集:采用 SuperGLUE 基准的全量数据,将数据集重定义为 text-to-text 的形式(但是并不会加上 task name 的前缀),每一个 task 单独训练一个 prompt,训练步数为 30K,最后报告 SuperGLUE 的 dev set 的结果。
基线模型:1)Model Tuning:每个 task 分别微调一个 T5 模型;2) Model Tuning(Multi-Task):多个 task 一起训练,为了区分每个 task,会加上 task name 的前缀。
实验结果如下:
随着模型参数的增加,Prompt Tuning 的效果越来越好,当 T5 模型参数达到 XXL 时,Prompt Tuning 的效果追平了 Model Tuning 和 Model Tuning(Multi-Task)。同时,Prompt Tuning 的效果远远超过了与 T5 同参数级别的 GPT-3 in context learning 的效果。
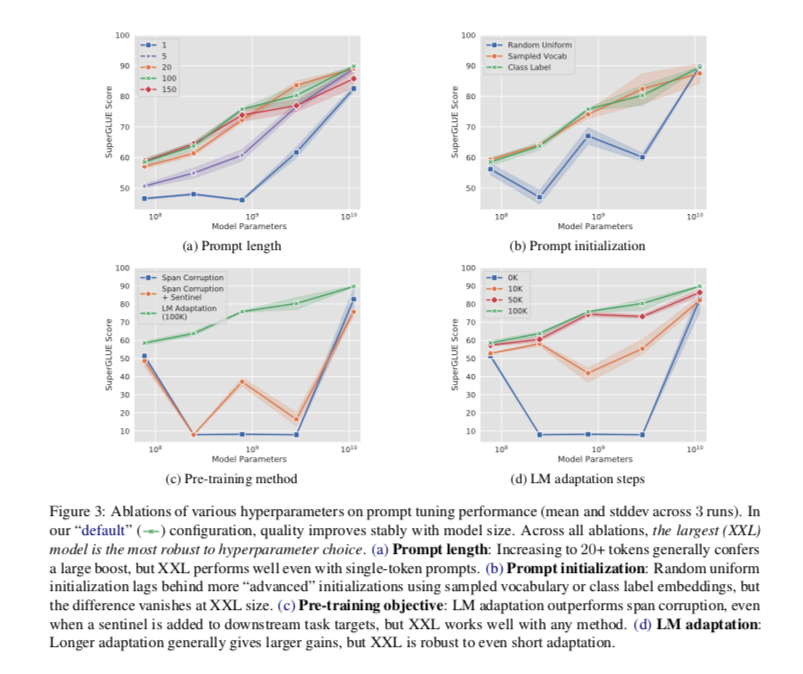
prompt tokens 对 prompt tuning 的影响:在一般模型大小情况下,prompt tokens 越多,确实效果越好,但是当 token 超过 20 以后,增益就越来越小,对于超大模型的情况,即使是单个 prompt token,也能达到和 20 个 token 以上的 prompt 相近的效果。
prompt token 的初始化:1. 随机初始化;2. 从 T5 词表中 5000 个常见单词中采样;3. 用类标签来初始化,标签是多个 token 时,则取均值,当类标签都用完后,剩下的 prompt token 用方法 2 初始化。类标签初始化在各种尺寸的模型上都表现最好,但是不同初始化策略在各种尺寸模型上表现差异很大,当尺寸变 XXL 后,这种差异就会消失。
预训练任务对 prompt tuning 的影响:Span Corruption 任务导致了 prompt tuning 表现很差,即使加了 Sentinel 也没法缓解,而 LM Adaptation 设定下随着模型尺寸增大则 prompt tuning 表现越来越好。当然,当尺寸变为 XXL 后,这种影响也会消失。
LM Adaptation steps 对 prompt tuning 的影响:LM Adaptation steps 越多,效果越好,这也说明 T5 需要进一步预训练才行。当然,当尺寸变为 XXL 后,这种影响也会消失。
4 Comparison to Similar Approaches
比较的一个重要轴是每种方法所需的特定任务参数的数量,如图4所示。在具有可学习参数的方法中,prompt tuning是参数效率最高的,对于超过10亿个参数的模型,需要不到0.01%的特定任务参数。
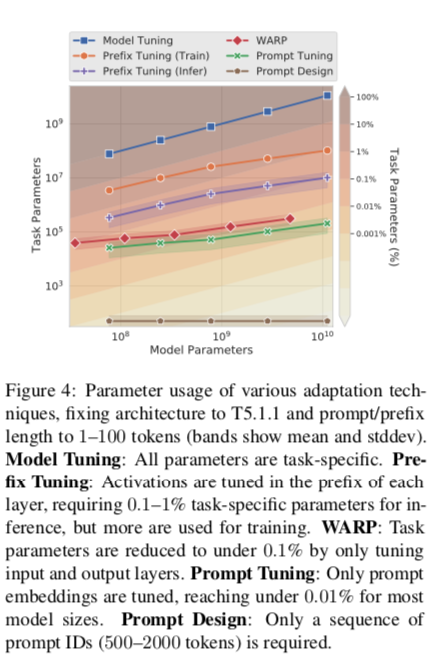
“prefix tuning”:学习在每个 transformer 层预置的前缀序列。这类似于学习 transformer 的激活,这些激活在每个网络层都是固定的。与此相反,Prompt Tuning 使用单一的提示表示,被预置到嵌入式输入。除了重新引用较少的参数外,我们的方法允许 transformer 更新中间层的任务表征,就像输入实例的背景一样。他们的工作建立在GPT-2 和 BART 的基础上,而我们的工作则以T5为基础,研究了随着模型大小的增加,设计选择的性能和稳健性的变化。当使用BART时,prefix tuning 包括编码器和解码器网络上的前缀,而 Prompt Tuning 只需要编码器上的提示。
与 P-tuning 的区别:P-tuning 的 soft tokens 需要考虑插入位置,同时采取的策略是 LM+Prompt Tuning,而 Prompt Tuning 则是直接插入在 prefix 位置,同时固定了 LM。同时 Prompt Tuning 相比 Model Tuning 的好处在于不会太过拟合在目标任务上,拥有更好的泛化性。
“adapters”,即在冻结的预训练网络层之间插入小型瓶颈层。adapters 提供了另一种减少特定任务参数的手段,Houlsby等人(2019年)在冻结BERT-Large并只增加2-4%的额外参数时,实现了接近全模型调谐的GLUE性能。Pfeiffer等人(2020年)在一个多语言文本中使用多个适配器,明确地将语言理解与任务规范分开,与我们的方法类似。
adapters 和 Prompt Tuning 之间的一个核心区别是这些方法如何改变模型行为。
adapters 通过允许重写任何给定层的激活来修改作用于输入表征的实际函数,该功能由神经网络参数化。
Prompt Tuning 通过保留固定的函数和增加新的输入表示来修改行为,这些表示会影响后续输入的处理。
5 Resilience to Domain Shift
通过冻结核心语言模型参数,prompt tuning可防止模型修改其对语言的一般理解。相反,prompt表示间接调整输入的表示。
这减少了模型通过记忆特定的词汇线索和虚假的相关关系来 overfit 数据集的能力。这一限制表明,prompt tuning可能会提高对domain shifts 的稳健性,在这种情况下,输入的分布在训练和评估之间有所不同。
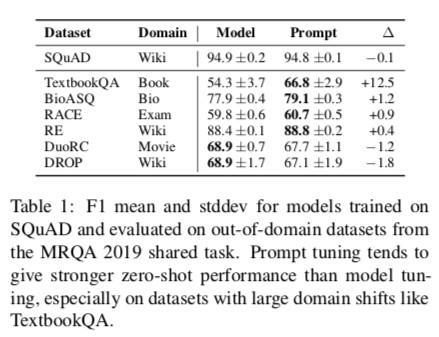
我们在两个任务上研究了 zero-shot 的领域转移:问题回答(QA)和转述检测(paraphrase detection)。对于问答,使用MRQA 2019关于泛化的共享任务。这项任务以统一的格式收集提取的QA数据集,并测试在 “域内 “数据集上训练的模型在评估 “域外 “数据集时的表现。在我们的实验中,我们在SQuAD上训练,并在每个域外数据集上进行评估。
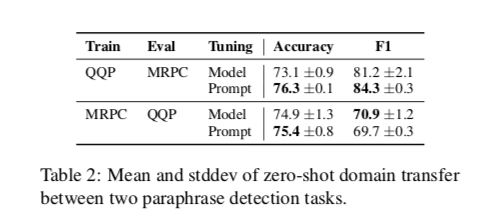
作为对结构域转移稳健性的第二个测试,我们探索了来自GLUE的两个释义检测任务之间的迁移。第一个任务是QQP(Iyer等人,2017年),它询问来自社区问答网站Quora的两个问题是否是“重复的”。
6 Prompt Ensembling
Prompt 集成:prompt tuning 的另一个好处在于可以在保存一份 LM 模型拷贝情况下,同时训练多个 prompt,并实现集成。作者在 SuperGLUE 上训练了 5 个 prompt,并用多数投票法进行集成,表现优于单一 prompt。
总结
Prompt Tuning 的做法是添加可训练的 prefix,同时固定 LM,只训练 prefix,采用 Prompt Tuning 的方式可以在 T5 超大模型和全量数据的情况下,追平 fine-tuning 的效果。
实验发现采用 prompt tuning 的方式在小模型的情况容易受到 prompt 长度,初始化策略,预训练任务等影响,并不稳定,也没法超过 fine-tuning 的效果。
作者没有探索少量数据 + 超大模型情况下和 fine-tuning 的效果比较。
 wechat
wechat alipay
alipay





