谣言、虚假信息综述
[TOC]
谣言、虚假信息综述
A Survey on Natural Language Processing for Fake News Detection
Abstract
虚假新闻检测是自然语言处理(NLP)中的一个关键但具有挑战性的问题。社交网络平台的迅速崛起不仅带来了信息可及性的大幅提高,而且也加速了假新闻的传播。因此,假新闻的影响越来越大,有时甚至延伸到线下世界,威胁到公共安全。鉴于海量的网络内容,自动检测假新闻是一个实用的NLP问题,对所有在线内容提供商都有用,以减少人类检测和防止假新闻传播的时间和精力。在本文中,我们描述了假新闻检测所涉及的挑战,也描述了相关任务。我们系统地回顾和比较了为该任务开发的任务描述、数据集和NLP解决方案,还讨论了它们的潜力和局限性。基于我们的见解,我们概述了有希望的研究方向,包括更精细、详细、公平和实用的检测模型。我们还强调了假新闻检测和其他相关任务之间的区别,以及NLP解决方案对假新闻检测的重要性。
1 Introduction
自动假新闻检测是评估新闻中 claims(声明,主张) 的真实性的任务。这是一个新的但关键的NLP问题,因为传统的新闻媒体和社交媒体对社会中的每个人都有巨大的社会政治影响。例如,对假新闻的曝光会导致对某些政治候选人的无效、疏远和嘲讽(Balmas,2014)。假新闻甚至与威胁公共安全的真实世界的暴力事件有关(例如,比萨门(Kang和Goldman,2016))。检测假新闻是NLP可以帮助的一个重要的应用,因为它也对技术如何在教育公众的同时促进验证 claims 的真实性产生了更广泛的影响。
这项任务的传统解决方案是请专业人员,如记者,根据以前说过的或写过的事实,对照证据来检查 claims。然而,这样做既费时又费力。例如,PolitiFact 需要三位编辑来判断一条新闻的真伪。随着互联网社区和信息传播速度的快速增长,互联网内容的自动假新闻检测已经引起了人工智能研究界的兴趣。自动假新闻检测的目标是减少人类检测假新闻的时间和精力,帮助我们停止传播假新闻。随着计算机科学子领域的发展,如机器学习(ML)、数据挖掘(DM)和NLP,假新闻检测的任务已从不同角度得到研究。
在本文中,我们从NLP的角度调查了自动假新闻检测。概括地说,我们介绍了假新闻检测的技术挑战,以及研究人员如何定义不同的任务并制定ML解决方案来解决这个问题。我们讨论了每项任务的优点和缺点,以及潜在的陷阱和弊端。更具体地说,我们对假新闻检测的研究工作进行了概述,并对其任务定义、数据集、模型构建和性能进行了系统的比较。我们还讨论了这个方向上的未来研究的指导方针。本文还包括一些其他方面,如社会参与分析。我们的贡献有三个方面。
- 对用于自动检测假新闻的自然语言处理解决方案进行了首次全面调查。
- 系统地分析了假新闻检测如何与现有的NLP任务保持一致,并讨论了问题的不同公式的假设和值得注意的问题。
- 对现有的数据集、NLP方法和结果进行了分类和总结,为对这个问题感兴趣的新研究人员提供了第一手的经验和易懂的介绍。
2 Related Problems
2.1. Fact-Checking
事实核查的任务是评估政治家、专家学者等公众人物提出的主张的真实性。许多研究者并不区分假新闻检测和事实核查,因为它们都是为了评估 claims主张 的真实性。一般来说,假新闻检测通常专注于新闻事件,而事实核查则更广泛。 Thorne和Vlachos(2018)对这一主题进行了全面的回顾。
2.2. Rumor Detection
谣言检测并没有一个一致的定义。最近的一项调查(Zubiaga等人,2018)将谣言检测定义为将个人主张分为谣言和非谣言,其中谣言被定义为在发布时由未经核实的信息片段组成的声明。换句话说,谣言必须包含可以验证的信息,而不是主观的意见或感觉。
2.3. Stance Detection
立场检测是指从文本中评估作者在辩论中站在哪一边的任务。它与假新闻检测不同,因为它不是针对真实性,而是针对一致性。立场检测可以是假新闻检测的一个子任务,因为它可以应用于搜索文本的证据(Ferreira和Vlachos,2016)。PHEME,假新闻数据集之一,有与新闻相关的推文,捕捉到用户信任或不信任的行为。
2.4. Sentiment Analysis
情感分析是一项提取情感的工作,例如顾客对一家餐厅的好感或负面印象。与谣言检测和假新闻检测不同的是,情感分析不是为了对主张进行客观验证,而是为了分析个人情感。
3. Task Formulations
在第2节中,我们比较了与假新闻检测有关的问题,以确定本调查的范围。在本调查中,假新闻检测的一般目标是识别假新闻,定义为看似新闻的虚假故事,包括在谣言检测中被判断为可以验证的信息的谣言。特别是,我们专注于文本内容的假新闻检测。输入可以是文本,从简短的声明到整个文章。输入与使用的数据集有关(见第4节),而且还可以附加附加信息,如发言人的身份。
有不同类型的标签或评分策略用于假新闻检测。在大多数研究中,假新闻检测被表述为一个分类或回归问题,但分类的使用更为频繁。
3.1. Classification
最常见的方法是将假新闻的检测制定为一个二元分类问题。然而,将所有的新闻分为两类(假的或真的)是很困难的,因为存在着新闻部分是真的和部分是假的情况。为了解决这个问题,增加额外的类别是常见的做法。主要是为既不完全真实也不完全虚假的新闻设置一个类别,或者设置两个以上的真实度作为附加类别。当使用这些数据集时,预期的输出是多类标签,而这些标签是作为独立的标签学习的,具有i.i.d的假设(Rashkin等人,2017;Wang,2017)。
假新闻分类器取得良好性能的条件之一是有足够的标签数据。然而,要获得可靠的标签需要大量的时间和人力。因此,人们提出了半/弱监督和无监督的方法(Rubin和Vashchilko,2012;Bhattacharjee等人,2017)。
3.2. Regression
虚假新闻检测也可以被表述为一项回归任务,其输出是真实性的数字分数。Nakashole和Mitchell(2014)采用了这种方法。通常情况下,评估是通过计算预测分数和地面真实分数之间的差异或使用Pearson/Spearman Correlations来完成。然而,由于可用的数据集有离散的地面真实分数,这里的挑战是如何将离散的标签转换成数字分数。
4. Datasets
数据集地址集合:
https://www.sohu.com/a/377489976_787107
https://www.zhihu.com/question/264356019/answer/1327236489
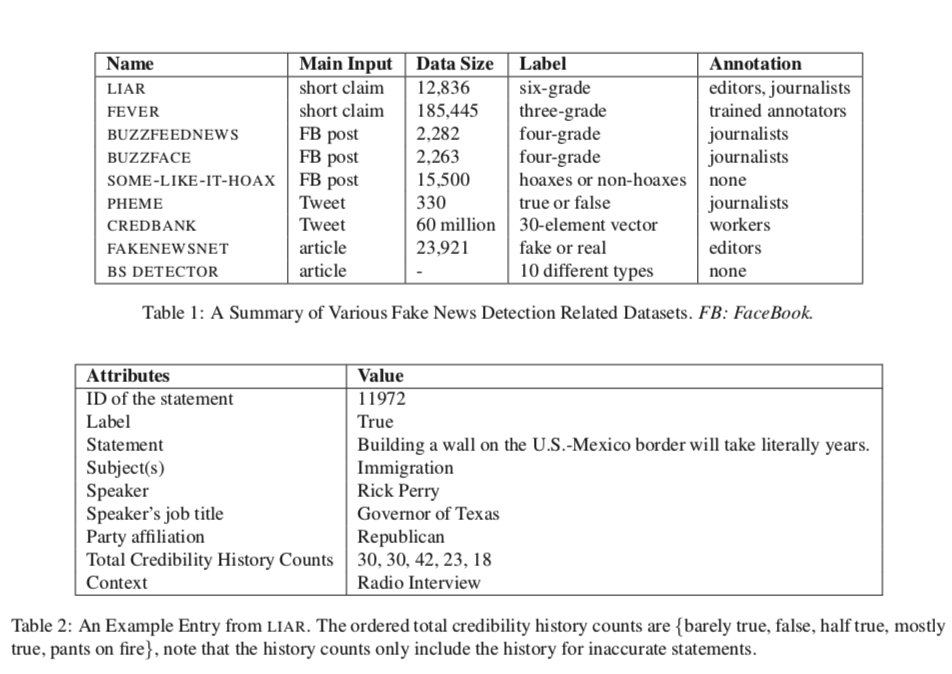
自动假新闻检测的一个重要挑战是数据集的可用性和质量。我们将公共假新闻数据集分为三类:
- claims : 是一个或几个句子,包括值得验证的信息(表2中有一个样本)
- 整篇文章 : 是由许多相互关联的句子组成,构成信息的整体。
- 社交网络服务(SNS)数据,在长度上与 claims 相似,但以账户和帖子的结构化数据为特征,包括大量的非文本数据。
4.1. Claims
POLITIFACT、CHANNEL4.COM、 SNOPES 是三个来源的新闻中的人工标注的短文,这些短文是人工收集和标注的。编辑们从各种场合,如辩论、竞选、Facebook、Twitter、采访、广告等,精心挑选了这些说法。许多数据集是基于这些网站创建的。
Vlachos和Riedel(2014)发布了第一个公开的假新闻检测数据集,收集了来自POLITIFACT和CHANNEL4.COM的数据。这个数据集有221条声明,其中有制作日期、说话人和URL,以及五分制的真实性标签。EMERGENT(Ferreira和Vlachos,2016)也是早期的声称-验证数据集的工作。它是在事实核查的背景下进行立场分类,包括带有一些支持或反对文本的主张。这个数据集可以改善事实核查,条件是提供一些与 Claims 有关的文章。
Vlachos只包括221项索赔,Emergent只包括300项索赔,因此将其用于基于机器学习的评估是不切实际的。这些天来,有许多索赔的数据集被公布,它们可以作为前两者的改进版使用。
最近一个用于假新闻检测的基准数据集是LIAR(Wang,2017)。这个数据集与Vlachos和Riedel(2014)一样从Politifact收集数据,但包括12,836个真实世界的短文,每个声明都被标记为六级真实性。该数据集中还包括关于主题、政党、背景和发言人的信息。对于来自Politifact文章的数据集,Rashkin等人(2017)也发表了大型数据集。他们也收集了来自PunditFact(Politifact的衍生网站)的文章。
Fever 是一个为事实核查提供相关证据的数据集。在这一点上,它与EMERGENT相似。Fever包含185,445个由维基百科数据生成的说法。每个声明都被标记为支持、反驳或信息不足。他们还标注了他们使用维基百科中的哪些感性内容作为证据。Fever使我们有可能开发出一个能够与证据一起预测主张的真实性的系统,尽管来自维基百科的事实和证据的类型可能仍然表现出与现实世界的政治运动的一些主要风格差异。
4.2. Entire-Article Datasets
有几个假新闻检测的数据集可以预测———整个文章是真的还是假的。例如,FAKENEWSNET(Shu等人,2017a;Shu等人,2017b;Shu等人,2018)是一个正在进行的假新闻研究的数据收集项目。它包括基于BuzzFeed和PolitiFact的假新闻文章的标题和正文。它还收集了来自Twitter的这些文章的社会参与信息。
BS DETECTOR4是从一个名为BS Detector的浏览器扩展中收集的,表明其标签是BS Detector的结果,而不是人类注释者。BS Detec- tor通过检查人工编制的不可靠域名列表,搜索有问题的网页上的所有链接,以寻找不可靠来源的参考。
4.3. Posts On Social Networking Services
BUZZFEEDNEWS收集了9家新闻机构在Facebook上的2282个帖子。每个帖子都由5名BuzzFeed记者进行事实核查。这个数据集的优势在于,文章是从左倾和右倾组织的两边收集的。BUZZFEEDNEWS有两个丰富的版本。Potthast等人(2017)通过添加链接文章等数据对其进行了丰富,而BUZZFACE(Santia和Williams,2018)则通过Facebook上与新闻文章相关的160万条评论来扩展BuzzFeed数据集。
SOME-LIKE-IT-HOAX(Tacchini等人,2017)由32个Facebook页面的15500个帖子组成,也就是组织的公开资料(14个阴谋论和18个科学组织)。这个数据集是根据发布者的身份而不是帖子级别的注释来标注的。这种数据集的一个潜在隐患是,这种标签策略可能导致模型学习每个发布者的特征,而不是假新闻的特征。
PHEME(Zubiaga等人,2016)和CREDBANK(Mitra and Gilbert, 2015)是两篇文章。PHEME包含9个有新闻价值的事件的330条twitter线程(一个人的一系列连接tweet),标记为真或假。CREDBANK包含覆盖96天的6000万条推文,被分组为1049个事件,有一个30维的真实性标签向量。每个事件都由30名人类注释者以5分的李克特量表对其真实性进行评分。他们将30个评分串联起来作为一个向量,因为他们发现很难将其简化为一个一维的分数。
如上所述,这些数据集是为验证推文的真实性而创建的。因此,它们只限于少数主题,并且可能包括与新闻没有关系的推文。因此,这两个数据集对于假新闻的检测并不理想,它们更多地被用于谣言检测。
5. Methods
我们介绍假新闻的检测方法。像往常一样,我们首先将输入文本预处理成合适的形式(5.1.)。如果数据集有整个文章的长度,可以使用修辞学方法作为手工制作的特征提取之一(5.3.)。如果数据集有EMERGENT或FEVER这样的证据,我们可以使用5.4.中的方法来收集输出的证据。
5.1. Preprocessing
预处理通常包括标记化、词干化和概括化或加权词。为了将标记化的文本转换为特征,经常使用术语频率-反向文档频率(TF-IDF)和语言学查询和单词计数(LIWC)。对于单词序列,通常使用预先学习的单词嵌入向量,如word2vec(Mikolov等人,2013)和GloVe(Pennington等人,2014)。
当使用整个文章作为输入时,一个额外的预处理步骤是从原始文本中识别中心主张。Thorne等人(2018)使用TF- IDF和DrQA系统(Chen等人,2017)对句子进行排名。这些操作与子任务密切相关,如单词嵌入、命名实体识别、消歧义或核心参考解析。
5.2. Machine Learning Models
如第3节所述,现有的研究大多使用监督方法,而半监督或无监督的方法则较少使用。在本节中,我们主要通过几个实际的例子来描述分类模型。
5.2.1. Non-Neural Network Models
Support Vector Machine (SVM) 和 Naive Bayes Clas- sifier (NBC) 是经常使用的分类模型(Conroy等人,2015;Khurana和Intelligentie,2017;Shu等人,2018)。这两种模型在结构上有很大不同,它们通常都被用作基线模型。Logistic回归(LR)(Khurana和Intelligentie,2017;Bhattacharjee等人,2017)和决策树,如Ran- dom Forest Classifier(RFC)(Hassan等人,2017)也被偶尔使用。
5.2.2. Neural Network Models
循环神经网络(RNN)在自然语言处理中非常流行,特别是长短时记忆(LSTM),它解决了梯度消失的问题,因此它可以捕获较长期的依赖关系。在第6节中,许多基于LSTM的模型在LIAR和FEVER上都有很高的准确性。此外,Rashkin等人(2017)建立了两个LSTM模型,将文本作为简单的词嵌入输入到一边,并作为LIWC特征向量输入到另一边。在这两种情况下,它们都比NBC和MaxEntropy(MaxEnt)模型更准确,尽管只是轻微的。
卷积神经网络(CNN)也被广泛使用,因为它们在许多文本分类任务中都很成功。Wang(2017)使用了一个基于Kim的CNN(Kim,2014)的模型,将最大池的文本代表与双向LSTM的元数据代表连接起来。CNN也被用于提取具有各种元数据的特征。例如,Deligiannis等人(2018)将新闻和出版商之间的关系图样数据作为CNN的输入,并用它们评估新闻。
Karimi等人(2018)提出了多源多类假新闻检测框架(MMFD),其中CNN分析索赔中每个文本的局部模式,LSTM分析整个文本的时间依赖性,然后通过全连接网络传递所有最后的隐藏输出的连接。 这个模型利用了两种模型的特点,因为LSTM对长句子的效果更好。
注意力机制经常被纳入神经网络以获得更好的性能。Long等人(2017)使用了一个注意力模型,该模型结合了说话人的名字和语句的主题,首先关注特征,然后将加权向量送入LSTM。这样做使准确率提高了约3%(表3)。Kirilin和Strube(2018)使用了一个非常类似的注意机制。Pham(2018)使用了记忆网络,它是一种基于注意力的神经网络,也分享了注意力机制的想法。
5.3. Rhetorical Approach
修辞结构理论(RST),有时与矢量空间模型(VSM)相结合,也被用于假新闻检测(Rubin等人,2015b;Della Vedova等人,2018;Shu等人,2017b)。RST是一个故事连贯性的分析框架。通过定义文本单元的语义作用(例如,一个句子代表环境、证据和目的),这个框架可以系统地识别基本思想,并分析输入文本的特点。然后根据其连贯性和结构来识别假新闻。为了用RST解释结果,VSM被用来将新闻文本转换成向量,在高维RST空间中与真新闻和假新闻的中心进行比较。向量空间的每个维度表示新闻文本中修辞关系的数量。
5.4. Collecting Evidence
基于RTE(识别文本蕴涵)(Dagan等人,2010)的方法经常被用来收集和利用证据。RTE是识别句子之间关系的任务。通过使用RTE方法从数据源(如新闻文章)收集支持或反对输入的句子,我们可以预测输入是否正确。基于RTE的模型需要文本证据进行事实核查,因此这种方法只有在数据集包括证据时才能使用,如FEVER和Emergent。
The Future of False Information Detection on Social Media: New Perspectives and Trends
社交媒体上虚假信息的大量传播已经成为一种全球性的风险,隐性地影响着公众舆论,威胁着社会/政治发展。因此,虚假信息检测(FID)已成为近年来风起云涌的研究课题。作为一个前景广阔、发展迅速的研究领域,我们发现很多人已经为FID的新研究问题和方法付出了努力。因此,有必要对FID的新研究趋势做一个全面的回顾。我们首先简要回顾了FID的文献历史,在此基础上,我们提出了几个新的研究挑战和技术,包括早期检测、多模态数据融合检测和解释式检测。我们进一步研究了FID中各种人群智能的提取和使用,这为解决FID的挑战铺平了道路。最后,我们对FID的开放性问题和未来的研究方向提出了自己的看法,如模型对新事件的适应性/通用性、对新型机器学习模型的接纳、人群智慧的聚合、检测模型中的对抗性攻击和防御等等。
INTRODUCTION
社会化媒体平台(如Twitter1、Facebook2、新浪微博3)彻底改变了信息的传播模式,大大提高了信息传播的速度、数量和种类。然而,社交媒体为事实和虚假信息的快速传播提供了便利。根据奈特基金会最近的一项调查4,美国人估计,他们在社交媒体上看到的新闻有65%是假新闻。此外,虚假信息通常在社交网络中传播得更快、更深、更广。
利用社交媒体传播误导性信息的敌对行为构成了一种政治威胁[8]。例如,在2016年美国总统大选期间,有多达529种不同的低可信度言论在推特上传播[73],约有1900万个恶意机器人账户发布或转发了支持特朗普或克林顿的帖子,这有可能影响了选举。2018年,《科学》杂志发表了关于 “假新闻 “的主题期刊,他们报道说,假 statements 声明可以引起人们的恐惧和惊讶的感觉,这有助于社会恐慌。例如,一段名为索马里人 “被推入浅坟 “埃塞俄比亚的虚假视频,引起了埃塞俄比亚两个种族之间的暴力冲突;一条网上的虚假信息,暗示希腊已经取消了转机限制,导致希腊警察与移民发生了冲突。上述例子表明,虚假信息的泛滥对社会信息传播的生态构成了严重威胁[91]。社交媒体用户每天都会接触到大量关于各种主题的信息。对用户来说,判断每条信息的可信度是不现实的,也是不可行的[140]。因此,检测社交媒体上的虚假信息是非常迫切的。
随着新媒体时代的到来,多模态的社交媒体帖子已经逐渐成为社交媒体的主流。因此,随着人工智能(AI)的快速发展,未来的网络虚假信息将超越文字,大规模地扩展到高质量和可操控的信息材料,如图像、视频和音频[8]。例如,DeepFakes[44, 56]利用深度学习模型创建了真实人物的音频和视频,说和做他们从未说过或做过的事情,这使得虚假信息越来越逼真,越来越难以辨别。虽然自动虚假信息检测不是一个新现象,但目前它已经引起了越来越多的公众关注。
为了便于理解和解释网络和社交媒体上的虚假信息,Kumar等人[89]根据其意图和知识对虚假信息进行总结和分类。
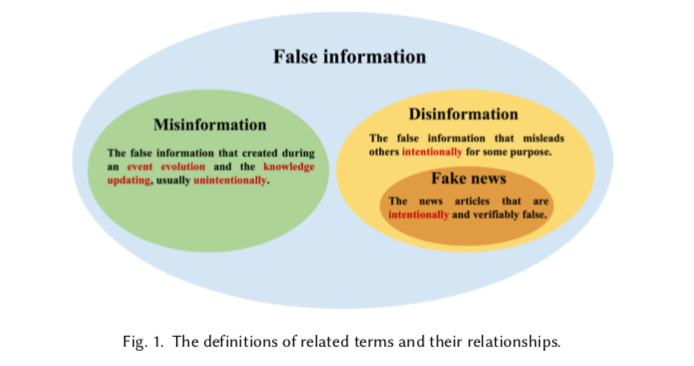
按照意图,false information 可以分为错误信息 misinformation 和虚假信息 disinformation,错误信息是指在事件演变过程中产生的虚假信息,或者是在知识更新过程中产生的虚假信息,没有误导的目的[87,150];虚假信息是指为了某种目的而故意误导他人的虚假信息[36,166]。根据知识,虚假信息可以被认为是基于意见的,它表达了用户的主观意见,描述了一些没有独特基础真相的情况,而基于事实的,是捏造或违背绝对基础真相的信息[172]。此外,相关文献中还有一些类似的术语,如谣言、假新闻。谣言一词通常指的是在发布时未经核实的信息[204]。因此,谣言可能会被证明是真的或假的。与谣言不同的是,假新闻一词被广泛用于指那些故意的、可验证的虚假新闻文章[162]。我们根据其意图对这些术语进行分类,如图1所示。尽管上述术语之间有区别,但它们都涉及到虚假信息的传播,并有能力或意图影响一些用户。因此,本调查坚持这些术语的定义,并从技术角度回顾了社交媒体上虚假信息检测(FID)的发展。
近年来,在FID方面有很多努力。根据现有FID方法中使用的特征类型,我们将其分为四类:基于内容的方法、基于社会环境的方法、基于特征融合的方法和基于深度学习的方法。基于内容的检测方法主要利用从社交帖子中提取的文本或视觉特征进行二元分类(真实或虚假)。基于社会环境的方法一般依赖于丰富的用户之间的互动特征,如评论、转贴、关注等。基于特征融合的方法综合利用了内容特征和社会环境特征。此外,基于深度学习的方法主要通过神经网络学习信息的潜在深度表示。
尽管过去几年对FID做了很多研究,但仍有许多遗留问题需要解决。首先,现有的FID方法大多利用内容或传播特征,并且通常在虚假信息的整个生命周期中工作良好,这可能导致早期检测的性能不佳。由于虚假信息可能在短短几分钟内产生严重影响,因此在早期阶段检测它们是至关重要的。第二,随着多模态帖子在社交网络上传播的增加,传统的基于文本的检测方法已不再可行,在更复杂的情况下,利用图像或视频进行FID是有益的。第三,目前的检测方法只给出了声明是否为假的最终结果,但缺乏做出决定的理由。对于揭穿不准确的信息并防止其进一步传播,给出一个令人信服的解释是非常重要的。
本文旨在深入调查与FID方法有关的最新发展。目前已经有一些关于FID的调查[39, 162, 201, 204]。Zhou等人[201]从基于知识、基于风格、基于传播和基于可信度等四个角度研究假新闻,并总结了心理学和社会科学的相关检测方法。Zubiaga等人[204]专注于谣言分类系统,研究了现有的识别疑似谣言、收集谣言相关帖子、检测帖子立场和评估目标事件可信度的方法。同样,Fernandez等人[39]将错误信息检测分为四个阶段:错误信息识别、传播、验证和驳斥。他们相应地组织了现有的在线错误信息检测系统。Shu等人[162]从数据挖掘的角度将检测模型分为基于新闻内容的模型和基于社会背景的模型,并总结了虚假新闻检测算法的评估测量方法。我们的调查与其他相关调查的区别如下:
- 上述调查对基于深度学习的虚假信息检测方法关注甚少。然而,在过去的三年里,深度学习模型已经被广泛地应用于FID。为了给检测方法提供一个最新的全面调查,我们调查并交叉比较了最近基于深度学习的方法。
- 本文回顾了近年来在FID领域出现的新问题和新技术,如早期检测、多模态数据融合检测和解释式检测等。此外,我们的论文从人群智能的角度调查了这些新问题和有前途的工作,研究了利用人群智能促进FID的潜力。
- 人工智能的发展提高了FID模型的性能,因此数据集已经变得和算法一样重要。本文为未来的研究人员梳理了自2015年以来广泛使用的开放数据集,这些数据集被现有的调查所忽视。
与现有研究大多使用帖子内容不同,基于人群智能的方法旨在检测基于聚合的用户意见、猜想和证据的虚假信息,这是人类与帖子互动过程中注入的隐性知识(如帖子的发布、评论和转贴)。最重要的是,我们工作的主要贡献包括:
- 基于对FID的简要文献回顾,我们集中讨论了它的最新研究趋势,包括对新事件的模型通用性、早期检测、基于多模态融合的检测和解释式检测。
- 我们对基于人群智能的FID方法进行了调查,包括FID中人群智能的范围,基于人群智能的检测模型,以及人机混合融合模型。
- 我们进一步讨论了FID的开放性问题和有前途的研究方向,如模型对新事件的适应性/通用性,拥抱新型机器学习模型,以及FID模型中的对抗性攻击和防御。
本文的其余部分组织如下。我们在第2节中对现有的FID工作进行了简要的文献回顾。然后,我们在第3节调查了FID的几个新的研究趋势。在第4节中,我们强调了基于人群智能的检测,然后在第5节中介绍了FID的开放问题和未来方向。最后,我们在第6节中总结了本文。
2 A BRIEF LITERATURE REVIEW
本调查主要关注检测在社交网络上传播的虚假或不准确的说法,因此我们首先给出虚假信息检测问题的一般定义。
- 对于一个具体的声明 $s$ ,它包含一组相关的 $n$ 个帖子 $P={p_1, p_2, …, p_n }$ 和一组相关的用户 $U={u_1,u_2,…,u_m}$.每个 $p_i$ 由一系列代表帖子的属性组成,包括文字、图片、评论数量等。每个 $u_i$ 由一系列描述用户的属性组成,包括姓名、注册时间、职业等。
- 让 $E = {e1,e2,…,en}$ 指的是 $m$ 个用户和 $n$ 个帖子之间的互动。每个 $e_i$ 被定义为 $e_i = {p_i,u_j,a,t}$,代表一个用户 $u_j$ 在时间 $t$ 通过行动 $a$ (发帖、转帖或评论)与帖子 $p_i$互动。
定义2.1。false information错误信息检测:给定具有帖子集 $P$、用户集 $U$ 和参与集 $E$ 的语句 $s$,错误信息检测任务是学习预测函数 $F(S)\to {0,1}$
在下文中,我们对现有的FID技术进行了简要的文献回顾,分为四大类型,即基于内容、基于社会环境、基于特征融合和基于深度学习的方法,如表1(前三种类型)和表2(最后一种类型)所总结的。此外,我们还对现有的几个在线FID工具进行了总结,这些工具对于减轻虚假信息的影响和防止其进一步传播具有重要意义。
2.1 Content-based Methods
对于一个具体的事件,其微博一般是由一段文字来描述,往往与几张图片或视频相关。基于内容的方法主要是基于特定的写作风格或虚假文章的耸人听闻的标题,如词汇特征、句法特征和主题特征[143]。例如,Castillo等人[16, 17]发现,高可信度的推文有更多的URL,而且文本内容长度通常比低可信度的推文长。
许多研究利用词法和句法特征来检测虚假信息。例如,Qazvinian等人[136]发现,语篇(POS)是FID的一个可区分的特征。Kwon等人[90]发现一些类型的情感是机器学习分类器的明显特征,包括积极的情感词(如爱、好、甜)、否定词(如不、不、永不)、认知行动词(如原因、知道)和推断行动词(如可能、也许)。然后,他们提出了一个周期性的时间序列模型来识别真实推文和虚假推文之间的关键语言差异。此外,Pérez-Rosas等人[128]总结了真实和虚假内容的语言学特征的差异,可以分为五类。”Ngrams”、”标点符号” “心理语言学特征”、”可读性 “和 “句法”。基于上述特征,使用线性SVM来识别虚假信息。Rashkin等人[141]总结了不可信的新闻内容的语言风格。具体来说,他们发现第一/第二人称代词在低可信度信息中使用的频率更高,夸张的词汇也是如此。
词汇特征有时不能完全反映虚假信息的特征,因为它的位置性。因此,许多研究为FID引入了语义特征,如话题、情感和写作风格。例如,Potthast等人[134]利用不同的写作风格来检测虚假声明。同样地,Horne等人根据假新闻文章在标题风格上与真实新闻文章有很大不同的观察,提出了一个FID模型。Hu等人[68]提出了一个利用情感信息检测低可信度社交帖子的框架。Ito等人[70]将Latent Dirichlet Allocation(LDA)主题模型引入到推文可信度的评估中,他们提出了推文主题特征和用户主题特征,用于检测虚假信息。
2.2 Social Context-based Methods
传统的基于内容的方法是孤立地分析单个微博或主张的可信度,忽略了不同微博和事件之间的高度关联性。此外,大量的人类内容互动数据(发帖、评论、转帖、评级和标签等)为FID提供了丰富的参考信息。具体来说,基于社会环境的方法可以进一步分为基于帖子和基于传播的方法。
(1) Post-based features
基于帖子的方法主要依靠用户的帖子来表达他们对特定事件的情绪或意见。许多研究通过分析用户的可信度[95, 118]或立场[63, 116]来检测虚假信息。例如,Shu等人[164]从用户档案中探索出对FID真正有用的特征,从而减少检测过程中特征提取的负担。具体来说,他们发现性格外向和随和的用户不太可能受到虚假信息的影响。此外,Guess等人[57]指出,保守派更倾向于在Facebook中分享虚假帖子。Long等人[104]发现,在基于内容的检测方法中应用用户档案(如党派、验证信息和位置)可以提高其在FID上的表现。他们提出了一个混合检测模型,分别提取新闻内容的主题特征和用户属性特征。此外,Tacchini等人[170]发现,有不准确信息的社交帖子通常比真实的事实有更多的赞。因此,他们使用逻辑回归(LR)模型和众包算法,在用户喜欢的基础上检测虚假信息。
(2) Propagation-based features
基于传播的方法将帖子和事件的可信度作为一个整体进行评估[14],这些方法通常关注信息传播网络的构建和可信度的传播。
一些研究通过分析其传播模式来检测虚假信息。例如,Ma等人[107]发现,社会环境的特征会随着时间的推移而逐渐改变。因此,他们提出了一个DSTS模型来描述FID的社会背景特征的时间模式,该模型将信息传播序列划分为固定长度的片段,然后从每段帖子中提取基于内容和社会背景的特征,最后用SVM进行分类。Liu等人[102]构建了基于异质用户特定属性的信息传播网络,用于识别虚假信息的特殊传播结构。Kim等人[79]提出了一个贝叶斯非参数模型来描述新闻文章的传播特征,该模型联合利用文章的主题和用户兴趣来进行FID。此外,Wu等人[186]观察到虚假信息通常先由普通用户发布,然后由一些意见领袖转发,最后由大量的普通用户传播。然而,真相往往是由一些意见领袖发布,然后由大量用户直接传播。基于这一观察,他们提出了一个用于FID的混合SVM分类器,该分类器对信息传播结构、主题信息、用户属性等共同建模。
此外,许多研究还通过构建特定的树状或网络结构来检测虚假信息。例如,Ma等人[108]将谣言相关的微博传播建模为传播树,他们提出了一种基于内核的方法来捕捉这些传播树之间的模式,以实现FID。此外,Gupta等人[62]构建了一个包含用户、帖子和事件的可信度传播网络来模拟虚假信息的传播过程。Jin等人[74]提出了一个连接微博、子事件和事件的三层可信度传播网络,用于信息可信度验证。
2.3 Feature Fusion-based Methods
基于内容的检测方法主要从写作风格、词汇和句法特征方面来识别真实和非真实的主张之间的差异,而基于社会背景的检测方法主要利用从信息传播过程中提取的特征。由于两类方法应用的特征可以互补[145],最近许多研究者开始研究基于特征融合的新方法。例如,Vedova等人[30]利用了用户和帖子之间的互动信息,以及帖子的文本信息。具体来说,他们对社交帖子进行词干分析,并将每个帖子表示为单词的TF-IDF向量。之后,他们利用用户的喜欢行为来描述社会背景特征,与Tacchini等人的工作类似[170],最后通过整合这两种信号来识别虚假信息。为了利用传统的内容特征(如词汇或句法特征),Volkova等人[176]将来自新闻内容的心理语言学信号和来自社会环境的作者观点作为FID中不同分类器的输入数据。此外,Shu等人[165]进一步探讨了出版商、新闻作品和用户之间的社会关系。他们提出了一个名为TriFN的通用检测框架,通过非负矩阵分解(NMF)算法对新闻内容、社会互动和新闻发布者之间的内在关系进行建模,用于识别低可信度信息。
2.4 Deep Learning-based Methods
基于深度学习的方法旨在自动抽象出虚假信息数据的高层表示。目前,大多数工作主要利用递归神经网络[106]和卷积神经网络[195]进行FID,如表2所示。在下文中,我们首先总结了广泛使用的深度学习模型,主要包括。
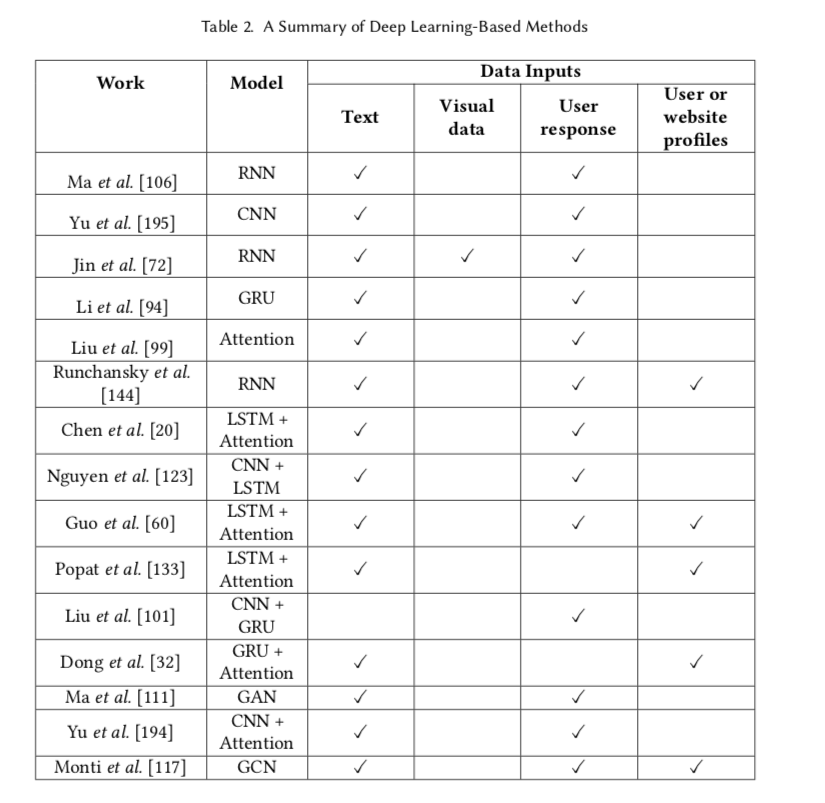
- 卷积神经网络(CNN)。CNN是典型的前馈神经网络之一,有三种层,即卷积层、池化层和全连接层[135]。在卷积层中,多个滤波器(核)与输入向量卷积,生成特征图。之后,池化层降低特征图的维度,以加速网络的训练过程。通过多次卷积和池化操作,CNN可以从输入中捕获局部和全局特征。最后,CNN通过全连接层(如Softmax)输出分类结果。可以看出,FID模型可以通过调整过滤器的大小来捕捉词与词、短语与短语之间的内容特征。
- 图卷积网络(Graph Convolutional Network,GCN)。GCN是一种处理图数据的神经网络,由卷积层和全连接层组成,可以有效捕捉图的结构特征[29, 83]。每个卷积层的隐藏状态矩阵由一个特殊矩阵的非线性变化得到,该矩阵是该图的相邻矩阵与其上一层的隐藏状态矩阵和权重矩阵的乘积。
- 递归神经网络(RNN)。RNN可以有效地捕捉连续数据的特征,通过同一隐含层的神经元之间的信息传输,节省了以前的计算。社交网络帖子显然具有时间性特征,因此FID模型可以将帖子的交互数据划分为连续的片段,并通过RNN捕获其顺序性特征。然而,Glorot等人[49]发现,RNN可能存在梯度消失的问题,这使得它不具备长期记忆。因此,长短时记忆(LSTM)[65]和门控递归单元(GRU)[25],一种具有门控机制的RNN,被广泛用于NLP中。LSTM增加了一个存储单元来存储当前网络状态,然后通过输入门、遗忘门和输出门的协调来控制信息流。虽然GRU没有引入额外的存储单元,但它可以通过一个复位门和一个更新门控制当前的存储。
- 递归神经网络(RvNN)。RvNN与RNN类似,它将数据结构展开,可用于分析数据的分层结构[135],如语法分析树。该模型由根节点、左叶节点和右叶节点组成。此外,每个节点都从直接的左、右子节点中学习它的表示方法,该方法是递归计算的,直到所有节点都被遍历。
- 自动编码器(AE)。AE是一个无监督的学习模型,包括编码和解码阶段[64]。在编码阶段,输入数据通过多个隐藏层转化为潜伏向量,在解码阶段将其重构为原始数据。通过最小化重建误差,AE尽可能地学习了输入的表示。与AE相比,变异自动编码器(VAE)约束了编码阶段,成为一个生成模型[82]。编码阶段的隐藏层通过从特定的分布(如高斯分布)中取样来学习潜变量,然后将其输入到解码阶段以生成现实的样本。
- 生成式对抗网络(GAN)。GAN是一种生成性神经网络,由生成器和鉴别器组成[51]。在反向传播的迭代过程中,鉴别器区分其输入是来自真实的数据集还是由生成器生成的虚假样本,而生成器则根据数据集的抽样分布生成真实的样本以混淆鉴别器。他们最终实现了纳什均衡,也就是说,生成器和鉴别器的性能不能再有任何提高。
- 注意机制。注意机制通常被用来描述神经网络对输入序列的注意分布[7]。它计算当前输入序列和输出向量之间的匹配度,目的是捕捉输入的关键信息。匹配度越高,注意力分数就越高。因此,检测方法可以利用注意力机制来找到这些对FID贡献较大的词或短语。
许多现有的研究利用深度神经网络,通过将相关帖子建模为时间序列数据来学习虚假信息的潜在文本表征。例如,Ma等人[106]提出了一个基于RNN的检测模型,该模型捕获了连续的用户评论流的时间-语言特征。Li等人[94]认为帖子流的前向和后向序列都传达了丰富的交互信息,因此他们提出了用于FID的双向GRU方法。Liu等人[101]认为假新闻和真新闻的传播模式存在差异,他们利用CNN和GRU对传播路径进行分类,以识别低可信度信息。Yu等人[194]认为帖子的时间序列特征有助于对事件进行准确建模,他们提出了FID的ACAMI模型。该模型使用event2vec(建议学习事件相关表征)和注意力机制来提取事件的时间和语义表征,然后使用CNN来提取高层次特征,用于对虚假微博帖子进行分类。
一些方法将文本信息和社会背景信息(如用户回应、用户或网站简介)结合起来作为深度神经网络的数据输入。例如,Guo等人[60]提出了一个分层的神经网络,将用户、帖子和传播网络的信息作为数据输入。此外,他们利用注意力机制来估计FID中特征的不同贡献。Ruchansky等人[144]的工作提出了一个基于RNN的检测模型,该模型结合了新闻内容、用户反应和源用户的特征来促进FID的性能。Ma等人[111]提出了一个基于GAN的检测模型,其目的是捕捉低频但有效的假推文迹象。生成器(基于GRU的seq2seq模型)试图生成有争议的观点,使推文的观点分布更加复杂,而判别器(基于RNN)试图从增强的样本中识别虚假信息的稳健特征。
也有一些使用图神经网络进行FID的工作,如GCNs。他们通常利用神经网络来分析社交帖子的传播结构,然后为分类器提取信息传播模式的高级表示。例如,Monti等人[117]提出了一个基于GCN的FID模型,它整合了推文内容、传播结构、用户资料和用户社会关系(关注和被关注)。考虑到原始推文和所有相关推文,即评论和转发,检测模型将每条推文作为节点,推文传播路径和用户关系作为边,建立一个特定事件图。之后,他们使用GCN来识别那些低可信度的推文,其中包含两个卷积层和两个全连接层。此外,Dong等人[33]提出了一个基于GCN的检测模型,名为GCNSI,它利用图卷积网络来检测多个虚假信息源。
3 NEW TRENDS IN FALSE INFORMATION DETECTION
在回顾了关于FID的传统研究后,本节调查了这一领域的几个新的研究趋势,包括早期检测、通过多模态数据融合检测和解释性检测。
3.1 Early Detection
虚假信息很容易被社交网络上的大量用户传播,在很短的时间内造成严重影响[14, 46]。因此,对虚假信息的早期检测成为一个重要的研究课题。然而,大多数现有的研究(基于内容和社会背景的方法)通过假设他们拥有所有的生命周期数据来检测虚假信息。他们依赖于几个聚合特征,如内容特征和传播模式,这需要一定数量的帖子来训练强大的分类器。虚假信息开始时的可用数据非常有限,以至于在早期阶段检测它很有挑战性。最近,有一些针对早期FID的努力。
传统的机器学习方法通常会分析帖子早期传播中的用户交互信息,手动提取大量的特征,最后用分类器(如SVM、随机森林)来评估其中的可信度。例如,Liu等人[100]发现,在少量的数据中,来源的可靠性、用户的多样性和证据信号,如 “我看到 “和 “我听到”,对FID有很大的影响。此外,Qazvinian等人[136]观察到,在推文传播的早期阶段,用户倾向于表达自己的信念(如支持或质疑)。因此,合理利用信息中的用户信念,对早期发现虚假信息大有裨益。为了解决数据缺乏的问题,从相关事件中借用知识进行FID将是另一种有用的方法。例如,Sampson等人[149]提出了一种通过利用隐性链接(如标签链接、网络链接)从相关事件中获取额外信息的突发性FID方法。实验结果表明,当可用的文本或互动数据较少时,这种隐性链接明显有助于正确识别突发的不真实声明。
许多检测方法利用深度学习模型对虚假信息进行早期检测。基于深度学习的检测方法通常使用神经网络来自动提取社会环境特征,并通过利用注意力机制找到FID的关键特征。例如,Liu等人[99]观察到只有少数帖子对FID有很大贡献。为了选择这些关键内容,他们提出了一个基于注意力的检测模型,该模型通过每个帖子的注意力值来评估其重要性。此外,实验结果表明,正确使用注意力机制有利于早期发现虚假信息。同样,Chen等人[20]发现,在信息传播的不同时期,用户倾向于对不同的内容进行评论(例如,从惊讶到质疑)。基于这一观察,提出了一个基于RNN的深度注意模型,有选择地学习连续帖子的时间性隐藏表征,以实现早期FID。Yu等人[195]利用一个基于CNN的模型从帖子序列中提取关键特征,并学习它们之间的高层次互动,这有利于用相对较少的互动数据识别虚假推文。Nguyen等人[123]也利用CNN来学习每条推文的潜在表征,相应地获得推文的可信度。然后,他们通过汇总事件开始时所有相关推文的预测,来评估目标事件是否是一条虚假信息。更重要的是,Liu等人[101]发现大多数用户在信息传播的早期过程中没有评论就转发源推文,这隐含着利用用户评论进行早期FID的一些延迟。因此,他们提出了一个传播路径分类模型,名为PPC,该模型联合使用CNN和GRU来提取转发路径中用户的局部和全局特征。
3.2 Detection by Multimodal Data Fusion
传统的FID方法专注于文本内容和传播结构。然而,社交媒体帖子也包含丰富的视觉数据,如图片和视频,而这种多模态数据往往被忽视。图片和视频比纯文本信息更吸引用户,因为它们可以生动地描述目标事件。
图像处理的巨大进步,如AE、VAE和GAN(如第2.4节所述),证明了图像可以很容易地被编辑和修改,使假图像的生成更加容易。因此,分析多模态数据之间的关系并开发基于融合的模型可以成为FID的一个有前途的方法[14]。社交媒体上的虚假信息中主要有三种假图像,包括图像篡改、图像不匹配和图像混合。
3.3 Explanatory False Information Detection
大多数基于深度学习的FID方法在输出决策结果时,往往不会呈现做出决策的原因,它们利用预先训练好的分类器来识别测试集中的可疑事件[14]。然而,找到支持决策的证据碎片将有利于揭穿虚假信息并防止其进一步扩散。因此,解释型FID已经成为另一个趋势性的研究课题。现有的解释性FID研究主要集中在两个方面:一是探索实用的可解释性检测模型(模型的解释),二是解释其结果(结果的解释)。
Interpretation of models
关于可解释的FID模型的研究主要集中在利用概率图模型(PGM)和知识图(KG)。
- 概率图模型(PGM)。PGM使用图来表示相关变量(节点)的联合概率分布,由贝叶斯网络和马尔科夫网络组成,前者使用有向无环图来模拟变量之间的因果关系,后者使用无向图来模拟变量之间的互动[38]。节点的关系可以通过条件独立性来解释。基于概率图的检测模型可以同时描述用户、社交帖子和人际交往内容的特征,并根据显性交互数据近似推断出隐性信息的可信度。此外,广泛使用的近似推理算法是变分推理、信念传播和蒙特卡洛抽样[84]。
- 知识图谱(KG)。KGs以图的形式描述现实世界中的实体以及它们之间的关系。具体来说,KG包含各种领域的知识,定义了实体的可能类别和关系,并允许任何实体之间有潜在的关联[127]。此外,还有一些权威的知识库,如Freebase17、Wikidata18、DBpedia19、谷歌的知识图谱20。这些知识库包含了数以百万计的实体和声明,为FID提供了参考。检测方法可以通过知识提取、融合和完成来检查社交媒体帖子的事实。
具体来说,Shi等人[157]提出了一种基于KG的事实核查方法。它首先通过从知识图中提取类似实体的元路径来分析帖子的语义信息。之后,该方法在收集到的事实状态中挖掘出异质连接模式,用于事实核查。此外,Gad-Elrab等人[47]提出了ExFaKT,为候选事实提供人类可理解的解释,它结合了来自文本内容和知识图谱的语义证据。ExFaKT使用Horn规则(一阶谓词逻辑的一个子集)将目标事实重写为多个易于解释的事实,以便进一步进行FID。Popat等人[131]的工作提出了一个概率模型,将FID的内容感知和趋势感知评估算法统一起来。具体来说,他们对事件相关文章之间的相互作用进行建模,以产生适当的用户可解释的解释,包括语言特征、立场和来源的可靠性。Yang等人[191]提出了一种无监督的FID方法,称为UFD。该方法利用贝叶斯网络来模拟真相和用户意见的完整生成过程。UFD将新闻文章的真实性和用户的声誉视为潜在变量,然后利用用户之间的社交活动来提取他们对新闻可信度的观点。
Interpretation of results
对结果的解释主要是指决策过程的可视化,或对事实的分析。虽然基于深度学习的方法极大地提高了FID的性能,但深度模型的内在机制并不能很好地解释。因此,研究人员利用其他辅助信息进行解释性的FID。
由于注意机制中的注意程度可以表征输入的每一部分的重要性[19],几个基于深度学习的检测方法通过注意程度的可视化来解释其分类。例如,Chen等人[20]将他们的模型识别的一些虚假索赔的注意力分布可视化,发现大多数与事件相关的词被赋予的程度低于表达用户怀疑、愤怒和其他情绪的词。Dong等人[32]提出了一个名为DUAL的基于注意力的FID模型,该模型分别使用GRU来提取文本特征和DNN来提取社会环境特征。他们将两个隐藏层的注意力矩阵可视化,有效地描述了识别真假帖子时每个隐藏层的注意力程度分布。同样地,Popat等人[133]使用双向LSTM分别提取源主张和外部相关帖子的特征,然后结合注意力机制来学习虚假信息的表示。他们还将其关注度可视化,显示许多信号词如 “勉强真实”、”证据 “和 “揭示 “被赋予较高的关注度。此外,他们使用主成分分析(PCA)来可视化他们的模型所学习的文本特征向量,发现真实和虚假说法的文本表示可以被适当地分开。
ClaimVerif[200]是一个在线解释信息可信度评价系统,它将给定主张的立场、观点、来源可信度等因素考虑在内,以提供有效证据。在识别网上的虚假主张时,ClaimVerif使用谷歌搜索抓取相关文章,分析原始信息和转帖信息的文本特征,最后输出源信息的可信度,以及人类可理解的证据。类似地,CredEye[132]通过分析在线相关文章来确定一个给定的说法是否是假的。解释的依据是这些文章的语言风格、立场和来源声誉。此外,Yang等人[190]提出了一个可解释的FID框架,名为XFake,它全面分析了声明的属性(如主题、说话人和背景)、语义特征和语言特征。XFake通过可视化界面显示几个支持性的例子,并以集合树的形式显示推理过程。
4 CROWD INTELLIGENCE-BASED DETECTION
现有的研究表明,帖子的内容特征仍然是FID的首要任务。由于社交帖子是由用户产生、互动和消费的,它将在帖子的编辑、评论和转发中摄入各种人类智能(如意见、立场、质疑、证据提供)。在社交媒体帖子的传播过程中,所谓的人群智慧[58, 96, 185]也会以集体的方式被聚集起来。正如Castillo等人[16]所说,一个有希望的假设是,在社交媒体环境中存在一些内在的信号,有助于评估信息的可信度。Ma等人[110]也发现,Twitter支持基于聚合的用户意见、猜想和证据碎片的虚假信息的 “自我检测”。虽然,如何在FID中利用人群智能仍然是一个开放的问题。在第4节中,我们试图通过提炼和介绍人群智能在FID系统中的几种不同使用形式来解决这个问题,如图2所示。
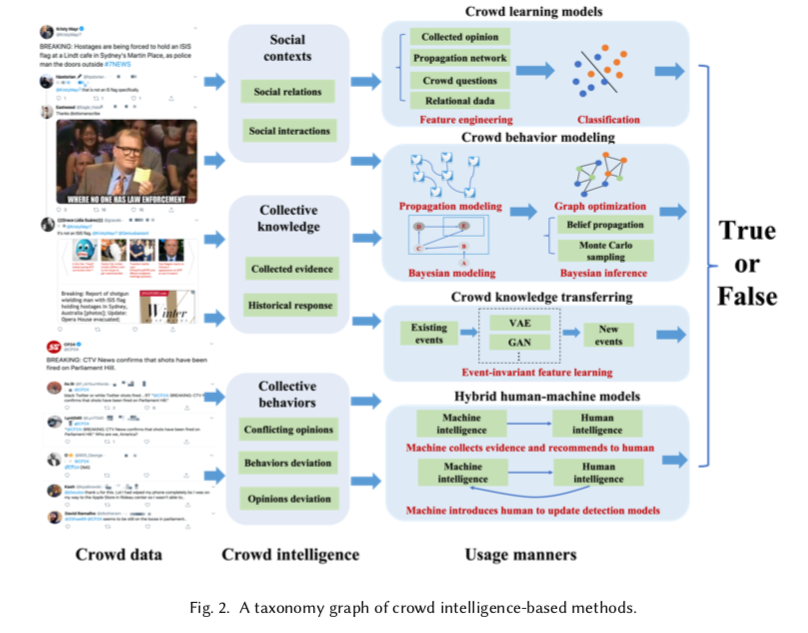
4.1 Crowd Intelligence in False Information
在FID中,人群智能是指在信息产生和传播过程中,来自社交媒体用户智慧的聚合线索或社会信号。在本小节中,我们总结了FID中人群智能的含义和使用方式。
我们从社会背景、集体知识和集体行为等三个方面来描述人群智能。
- Social contexts. 源用户和传播者之间的社会关系和互动有助于理解信息的确定性。例如,Kim等人[80]认为用户的标记可以间接反映推文的可信度,所以他们使用PGM来生成人与内容的互动过程,推断推文的真实性。Zhao等人[199]发现群众在评论中对真实性的质疑或询问是低可信度信息的指示性信号,他们使用正则表达式从用户评论中提取上述信号进行FID。此外,Wu等人[188]认为类似的话题可能会在类似的人群中传播,所以他们对传播者进行编码,以捕捉他们的社会接近性,从而识别虚假信息。
- Collective knowledge. 群众提供的收集的证据对推断信息的可信度很有用。例如,Lim等人[97]利用用户对目标事件在线证据的支持或反对来检测不准确的言论。Rayana等人[142]认为用户的评分和评论是对帖子可信度的真实评价,所以他们提出了一个名为SpEagle的检测框架,从集体线索和关系数据(信息传播网络)中提取特征。此外,Qian等人[138]提出了一种用于FID的人群知识转移方法,其中利用了历史上真/假说法中的人群反应知识(如背景特征和行为特征)。
- Collective behaviors. 在很多情况下,虽然个人行为不能很好地描述信息的可信度,但一群用户的聚合行为往往能揭示更多信息。这可能是指人群互动模式,行为或意见偏离多数[88],观点冲突,等等。例如,经常参与低可信度信息的生产和传播的用户有行为偏差,例如,在短时间内发布几个意见,或在一个固定的时间间隔后与内容互动。基于上述观察,Kumar等人[88]通过贝叶斯模型推断出回复者及其评论的可信度。此外,Jin等人[76]发现同一事件下的相关推文包含支持和反对的意见(通过LDA主题模型分析),他们利用这些冲突的观点来建立FID的可信度传播网络。
在调查了现有的FID研究后,我们提炼出四种不同的人群智能使用方式,如下所示。
- 群体学习模型。它主要使用特征工程和代表学习将人群智能融入到FID模型中。
- 人群行为建模。它使用图或概率模型对人群行为和互动进行建模,以推断信息的可信度。
- 群众的知识转移。学习到的FID模型通常在新事件上不能很好地发挥作用。这种方式解决了如何将人群知识从现有的事件转移到新的事件。
- 人机混合模型。考虑到人类智能和机器智能的互补性,这种方式集中于开发用于FID的混合人机模型。
前面三种方式的一个共同特点是,人群智能是以隐性方式使用的,没有明确的人类输入。具体来说,人群智能被表示为统计学上的人类行为模式,作为学习模型的特征或参数使用。然而,最后一种方式是基于明确的人类输入,例如使用众包进行数据标记。
4.2 Implicit Crowd Intelligence Models
在本节中,我们介绍了关于将隐式人群智能用于FID的开创性研究,特别关注4.1节中描述的前三种方式,如表4中总结的那样。
(1) 群体学习模型。在该模型中,群体智能被表示为训练分类器以检测虚假信息的特征。这已被证明对早期的 FID 很有用。例如,刘等人。 [100] 尝试使用来自 Twitter 数据的人群线索来解决实时虚假索赔揭穿的问题,包括人们的意见、证人账户的统计数据、对事件的聚合信念、网络传播等。赵等人。 [199] 观察到,在决定是否相信此消息之前,有些人愿意质疑或询问 Twitter 中声明的真实性。特别是,他们发现使用探究思维有助于及早发现虚假信息。
社会关系和交互也是 FID 特征学习中广泛使用的群体智能。例如,吴等人。 [188] 假设相似的消息通常会导致相似的信息传播轨迹。他们提出了一种社交媒体用户嵌入方法来捕捉社交接近度和社交网络结构的特征,在此基础上利用 LSTM 模型对信息传播路径进行分类并识别其真实性。拉亚娜等人。 [142] 应用集体意见线索和相关数据来检测虚假信息。
通过利用发布虚假帖子的用户行为与发布真实事实的用户行为不同的人群情报来识别虚假信息也很有帮助。陈等人。 [22] 提出了一种无监督学习模型,该模型结合了 RNN 和自动编码器,以将低可信度信息与其他真实声明区分开来。此外,谢等人。 [189] 观察到垃圾评论攻击与其评分模式密切相关,这与正常评论者的行为模式不同。因此,他们提出了一种基于其时间行为模式的垃圾评论检测方法,为群体学习模型的 FID 提供了参考。
(2) 人群行为建模。在这个模型中,集体的人群行为(人群智能的一种类型)被建模为图或概率模型来推断信息的可信度。Hooi等人[66]发现,欺诈性账户经常在短时间内呈现他们的评级(评级分数满足偏斜分布)。群众智慧的特点是贝叶斯推理模型,它可以估计一个用户的行为与相关社区的行为有多大偏差。他们通过测量行为偏差的程度来推断用户评级的可信度。同样,Kumar等人[88]提出了一个贝叶斯检测模型,该模型结合了聚合的人群智慧,如用户的行为属性、评级的可靠性和产品的优良性。通过对异常行为的惩罚,它可以推断出评级平台的信息可信度。
一些研究利用聚合的人群行为建模来促进虚假信息的早期检测。例如,Ma等人[110]假设回复者倾向于询问谁支持或否认给定的事件,并表达他们对更多证据的渴望。因此,他们提出了两个树状结构的递归神经网络(RvNN),用于有效的虚假推文表征学习和早期检测,可以对用户回复结构进行建模,并学习捕捉FID的聚合信号。
(3) 群众的知识转移。现有的FID模型在新出现的和时间紧迫的事件上仍然表现不佳。换句话说,现有的FID模型通常捕捉到许多与事件相关的特征,而这些特征在其他事件中并不常见。因此,有必要学习并将从现有众包数据中获得的共享知识转移到新的事件中。Wang等人[182]的工作提出了一个利用可转移特征识别新产生的虚假事件的检测模型,名为事件对抗神经网络(EANN ),它包括三个部分,即 “特征提取器”、”事件判别器 “和 “假新闻检测器”。EANN使用事件判别器来学习与事件无关的共享特征,并在模型训练中减少事件特定特征的影响。
群众知识转移模型也有助于早期FID。例如,Qian等人[138]提出了一个生成性条件变异自动编码器,从历史上用户对真实和虚假新闻文章的评论中捕捉用户反应模式。换句话说,当虚假信息传播的早期阶段没有社会互动数据时,人群智能被利用来产生对新文章的反应,以提高模型的检测能力。Wu等人[187]还探讨了历史众包数据中的知识是否能对新出现的虚假社交媒体帖子的检测有所帮助。他们观察到,内容相似的社交帖子往往会导致类似的行为模式(如好奇心、询问)。因此,他们建立了一个稀疏表示模型来选择共享特征并训练与事件无关的分类器。
5 OPEN ISSUES AND FUTURE DIRECTIONS
尽管研究人员已经为解决FID系统的上述挑战做出了越来越多的努力,但仍有一些开放性的问题需要在未来进行研究,如下所述。
(1) Cognitive mechanisms of false information.
人们对虚假信息的认知机制的研究对于虚假社交媒体帖子的检测和反驳具有很好的指导作用[87],尤其是基于群体智能的检测方法。几部作品对社交媒体平台上的低可信帖子进行了分析,以研究虚假信息能够快速广泛传播的原因。莱万多夫斯基等人。 [92] 认为打击虚假信息需要在技术和心理学的背景下进行科学研究,因此他们提出了一种称为“技术认知”的跨学科解决方案。此外,他们将用户面对虚假信息的认知问题分为影响效应、熟悉度逆火效应、矫枉过正逆火效应和世界观逆火效应四类,为研究用户对虚假信息的感知奠定了基础。 93]。正如 Acerbi [1] 总结的那样,不准确信息的快速传播在于它们包含满足用户认知偏好的特定内容。为了探索虚假信息的认知特征,他们通过将认知偏好编码为“威胁”、“厌恶”、“社交”、“名人”等部分,进一步分析了真假新闻文章的偏好分布。未来一个有价值的研究点是将虚假和真实的信息与具有认知吸引力的特征进行比较,或者评估与认知偏好相关的特征如何促进信息病毒式传播。
除了在数据分析层面研究认知机制外,我们还可以从人脑认知功能的角度来学习这种机制。神经科学的进步为研究虚假信息的认知机制提供了一个很好的途径。正如Poldrack等人[130]所说,利用脑电图(EEG)、脑磁图(MEG)、功能性磁共振成像(fMRI)和其他脑成像工具可以推动我们了解人脑如何形成社会行为。此外,Adolphs[3]已经确定了参与社会认知调控的神经结构,如扣带皮层、海马体和基底前脑。Arapakis等人[6]利用脑电图记录来测量用户对新闻文章的兴趣,实验结果显示,额叶α不对称性(FFA)可以客观地评价用户对媒体内容的偏好。为了解释信息病毒的机制,Scholz等人[151]提出了一个基于fMRI数据的神经认知框架来评估用户在Facebook上分享信息的意愿。如果我们能够理解虚假信息的认知机制,就可以把更多的精力放在探索揭穿信息最大化的方法上,从而找到针对虚假信息的有力对策。
(2) Lack of standard datasets and benchmarks.
尽管研究人员在FID方面做了大量的工作,但仍然缺乏像ImageNet[31]这样的视觉对象识别基准数据集。数据集作为一种资源,与FID的算法同样重要。然而,收集虚假信息是一个耗时耗力的过程,这导致了权威基准的缺乏。
我们总结了2015年以来的公开数据集,如表6所示,其数据收集自新浪微博(如RUMDECT,Meida_Weibo)、Twitter(如。MediaEval、PHEME、RUMOUREVAL)和其他社交平台,以及snopes.com、politifact.com(例如Emergent、BuzzFeedWebis、LIAR、Declare、FakeNewsNet)和其他事实核查网站。然而,这些数据集的注解方法、数据维度以及真假陈述的比例都不一样,这给研究人员公平评估其模型性能带来了一定的挑战。Shu等人[162]总结了广泛使用的FID的评价指标,现有的评价指标仍然是精度、召回率、F1得分、准确率等机器学习模型评价指标。在FID中,我们需要定义一些更实用的评价指标。例如,在政治选举中,我们会更关注虚假声明是否被更全面地识别出来(即更关注召回率而不是精度),所以用F1得分来评价检测模型的性能并不是很合适。在未来的研究中,需要标准的数据集和实用的评价指标来比较各种FID算法,促进FID方法的发展。
(3) Model adaptivity/generality to new events
FID方法应该识别未见过的、新出现的事件,因为系统的现有数据可能与新出现的事件的内容不同。然而,现有的方法倾向于提取事件的特定特征,而这些特征很难与新事件共享[204]。正如Tolosi等人[173]所说,基于特征工程的检测方法很难检测到不同领域(如政治、犯罪、自然灾害)的虚假信息,因为不同事件的特征变化很大。因此,模型的通用性或适应性对于提高FID模型的稳健性相当重要。Zubiaga等人[206]指出,依赖于领域的特征分布可能会限制模型的泛化能力。由于大多数特征的分布直接对应于事件,FID模型的性能将受到影响。尽管我们在第4.2节中讨论了一些人群知识转移模型[138, 182, 187],但还有更多的东西需要研究。在其他领域(如情感分类[50]和图像识别[103])成功使用的转移学习模型[59, 126],可以被用来设计领域适应性的FID模型。使用基于GAN的判别器[182]是另一种有前途的方法,以建立具有共享特征的通用FID模型。
(4) Embracing of novel machine learning models.
FID过程从本质上讲就是学习分类器,以识别给定主张的可信度。我们发现,许多研究建立了深度学习模型[20, 72, 101, 106, 123, 144, 195]来提高自动事实核查的性能。然而,仍有更多可以探索的地方。在下文中,我们将介绍几个有代表性的例子,它们利用先进的机器学习技术来进行FID。
- Multi-task learning. 多任务学习[109]旨在通过使用相关任务中包含的领域知识来提高模型的泛化性能。现有的方法通过对任务的相关性进行建模,如特征共享、子空间共享和参数共享等,来寻找多个任务之间的共同点,作为促进每个任务学习效果的一些补充知识。例如,Ma等人[109]认为FID任务与立场分类任务高度相关,所以他们提出了一个神经多任务学习框架,以更好地进行事实核查。在权重共享的机制下,他们提出了两个基于RNN的多任务结构来联合训练这两个任务,这可以为谣言表征提取普通以及特定任务的特征。在这项工作的启发下,我们可以研究FID和其他任务之间的联系和协作,并进一步设计基于多任务学习的算法来提高FID模型性能。
- Few-shot learning. [183]致力于解决数据稀缺的问题,利用少数监督信息来识别未见过的类的样本。现有的少量学习方法通常将其训练程序分解为多个元任务学习程序,类似于元学习[43],从不同任务的数据中提取可转移的知识。因此,这允许只用少量的标记数据对新类进行分类。据我们所知,在FID中应用的少量学习方法较少,因此我们可以从其他相关领域学习,如文本分类。为了提高分类器的归纳和泛化能力,Geng等人[48]提出了一个基于动态路由算法的分类架构,称为归纳网络,它从少数样本中学习泛化的类级表示。归纳网络主要包含一个编码器模块、一个归纳模块和一个关系模块。具体来说,编码器模块生成样本和查询表征,然后归纳模块利用一个转换矩阵将样本级表征映射到类级表征。最后,关系模块计算出查询和每个类别之间的匹配度。这项工作表明,Few-shot learning在NLP中有很大的潜力,我们可以继续研究基于Few-shot learning的FID方法。
- Semi-supervised models.大多数现有的FID工作集中在监督分类上,他们通常通过大量的标记数据(例如,假的或不假的)来训练分类器识别虚假信息。然而,在很多情况下,我们只有少量的标记数据。半监督模型经常被用来处理标签稀少的问题。例如,Guacho等人[55]提出了一种半监督的FID方法,它利用基于张量分解的文本嵌入来捕捉社交帖子的全局和局部特征。在构建所有帖子的K-近邻(K-NN)图后,他们使用信念传播算法将已知的标签传播到图中,以获得事件的最终可信度。此外,图神经网络的发展也为半监督检测模型的研究提供了机会。GNN,如DeepWalk[129]、LINE[171]和node2vec[54],利用不同的采样算法来生成节点序列,然后通过跳格模型学习每个节点或传播路径的表示。他们在损失函数中引入了一阶接近性(两个相邻节点之间相似性的表征)和二阶接近性(两个节点之间结构相似性的表征),以确保神经网络能够充分提取图的特征。特别是GCNs[83],如第2节所讨论的,在相邻的卷积层中通过图形的拉普拉斯矩阵的非线性变换来传递信息。每个卷积层只计算一阶接近度,所以GCN可以通过多个卷积层学习节点或传播路径的高级特征表示。特别是,GNN能够通过明确的图正则化方法[184]平滑标签信息,用于图的半监督学习。因此,FID模型可以建立信息传播图,并结合GNNs来检测虚假信息。
- Unsupervised models. 如果能够直接建立可靠的无监督检测模型,对于快速驳斥虚假信息具有重要意义。无监督模型可以从人与内容的互动(如发布或转发社交媒体帖子)和人与人的互动(如关注或提及某些用户)来评估帖子的可信度。一方面,GAN和VAE的进步为无监督的FID模型带来了新的可能性。另一方面,PGMs仍然可以在FID中发挥重要作用。例如,Chen等人[22]从用户的发帖行为中判断一个帖子是否是假的。这种无监督的方法利用AE来学习一个人最近的发帖和他们的评论的潜在代表。当其重建误差收敛时,该模型可用于评估新帖子的可信度。如果模型的重建误差超过一定的阈值,这个帖子可能是一个假消息。Yang等人[191]将新闻真实性和用户可信度视为潜在变量,并利用用户评论来推断他们对新闻真实性的看法。换句话说,新闻的真实性取决于用户意见的可信度,而意见的可信度则依赖于用户的声誉。他们利用贝叶斯网络对互动过程进行建模,在没有任何标记数据的情况下推断出新闻文章的真实性。实际上,用户的意见可能会受到其他用户的影响,而且他们对不同主题的虚假信息的识别能力也是不同的。在使用PGM时可以进一步考虑这些条件。
- Hybrid learning models. 混合学习模型的发展,结合了线性模型和深度学习模型,已经成为人工智能领域新的研究趋势,即显性特征和潜在特征的结合使用。它利用了两类学习模型的互补性。例如,Wide & Deep[24]是一个表现良好的推荐系统框架,其中Wide部分提取显性特征,Deep部分学习非线性的潜性特征。在FID中也有初步的混合学习模型。Yang等人[192]提出了用于检测虚假信息的TI-CNN模型,该模型在融合显性和隐性特征空间的基础上,对文本和视觉信息进行整体训练。此外,Zhang等人[197]提出了一个基于贝叶斯深度学习的FID模型,该模型使用LSTM来编码索赔和用户评论,并利用贝叶斯模型来推断分类结果。由于混合学习模型仍处于早期阶段,在这个方向上还需要进一步的研究,如概率图模型和深度学习模型的融合。
(5) Adversarial attack and defense in FID models.
基于深度学习的FID模型有助于有效提高事实核查的性能。然而,Szegedy等人[169]已经证明,训练有素的神经网络可能无法抵御对抗性攻击,这意味着在输入向量中添加一些小的扰动会使模型得到错误的结果[4]。现有的FID研究很少强调深度模型的鲁棒性,这些模型可能被对抗性攻击所欺骗。
虽然很少有关于FID模型中对抗性攻击和防御的研究,但关于其他任务(如图像分类[52,169]、语音识别[15]、文本分类[86]和强化学习[10])的相关工作已经被调查。有几项工作侧重于对抗性攻击对模型的影响。例如,Dai等人[28]提出了一种基于强化学习(RL)的图数据的对抗性攻击方法,该方法通过增加或减少图中的边的数量来学习最佳攻击策略。为了生成通用的文本对抗性扰动,Behjati等人[9]提出了一种基于梯度投影的攻击方法。Jia等人[71]通过在问题中添加不会对人类理解造成困难的句子或短语来攻击问答系统。
以上攻击研究可以指导FID模型的对抗性攻击防御研究。Zhou等人[202]进一步将FID模型的对抗性攻击分为事实失真、主客体交换和原因混淆。为了抵御对抗性攻击,他们进一步提出了一个众包知识图谱来及时收集新闻事件的事实。Qiu等人[139]将防御方法分为三类,包括修改数据(如对抗性训练、梯度隐藏)、修改模型(如正则化、防御性蒸馏)和使用辅助工具(如防御-GAN[148])。无论是对模型的攻击还是对数据的操作,都对FID系统的稳健性提出了更高的要求。因此,在FID的对抗性攻击和防御方面仍有更多的工作要做。
(6) Explanatory detection models.
提供决策结果的证据或解释可以增加用户对检测模型的信任。尽管关于解释型FID模型的工作很少,但在其他相关领域,如推荐系统,解释的应用已经被研究过。
可解释的推荐,提供关于为什么推荐一个项目的解释,在最近几年引起了越来越多的关注[198]。它可以提高用户对推荐系统的接受度、信任度和满意度,增强系统的说服力。例如,Chen等人[23]提出了一种基于atten- tive神经网络的可视觉解释的推荐方法,以模拟用户对图像的注意力。用户可以通过提供个性化和直观的视觉亮点来理解产品被推荐的原因。Catherine等人[18]研究了如何在外部知识图谱的支持下产生可解释的推荐,他们提出了一个个性化的PageRank程序,将项目和知识图谱实体一起排名。Wang等人[181]的工作提出了一个基于强化学习(RL)的模型诊断性解释推荐系统,它可以灵活地控制解释的呈现质量。最重要的是,这种可解释推荐系统所使用的方法可以启发我们设计更好的可解释FID系统。
从更高的角度来看,机器学习模型已经在不同的应用领域(超越了推荐系统和FID)提供了突破性进展。尽管取得了巨大的成功,我们仍然缺乏对其固有行为的理解,例如分类器是如何得出一个特定的决定的。这导致了可解释机器学习(IML)研究方向的激增。IML使机器学习模型有能力以人类可理解的术语进行解释或呈现[2, 34]。Du等人[35]定义了两种类型的可解释性:模型级解释和预测级解释。模型级解释,为增加模型本身的透明度,可以阐明机器学习模型的内部工作机制。预测层面的解释有助于揭示特定输入和模型输出之间的关系。对于FID来说,它更关注预测层面的解释,它可以说明一个决定是如何得出的(使用来源的可靠性、证据和立场等要素)。构建预测级可解释模型的一个代表性方案是采用注意力机制,它被广泛用于解释序列模型(如RNN)做出的决策结果。我们还应该研究植根于IML的其他方法,以提高FID系统的可解释性。
(7) Aggregation of crowd wisdom.
如何聚合人群智慧对FID系统来说非常重要,因为人群贡献的数据往往有噪音。大多数用户的意见可以有效地用于识别虚假信息,但也存在真理掌握在少数人手中的情况。因此,未来仍有必要探索FID的人群智慧的聚合和优化方法。
我们可以从真相发现系统中学习。随着利用人类智慧从相互冲突的多源数据中提取可靠信息的能力,真相发现已经成为一个越来越重要的研究课题。对于FID,我们也有关于一个事件的多个帖子,目标是识别这个事件的真相。因此,这两个研究问题有相似之处,我们可以借用真相发现系统的知识来促进FID的研究。例如,Liu等人[98]提出了一种专家验证辅助的图像标签真相发现方法,旨在尽可能地从嘈杂的众包标签中推导出正确的标签。特别是,它以人机协作的方式利用了一种半监督学习算法,可以最大限度地发挥专家标签的影响,减少专家的努力。Zhang等人[196]提出了一个名为 “TextTruth “的基于概率图的真相发现模型,它通过全面学习关键因素(一组关键词)的可信度来选择高度可信的问题答案。TextTruth以无监督的方式将答案提供者的可信度和答案因素的可信度一起推断出来。Yin等人[193]提出了一个以无监督的方式进行人群智慧聚合的模型,称为标签感知自动编码器(Label-Aware Autoencoders,LAA),它提取了多源标签的基本特征和模式,并通过一个分类器和一个重构器推断出可信的标签。为了解决同一信息源在不同主题上具有不同可信度的挑战,Ma等人[105]提出了一种名为FaitCrowd的众包数据聚合方法。FaitCrowd通过在概率贝叶斯模型上对问题内容和发布者的答案进行建模,共同学习问题的主题分布、答案提供者的基于主题的知识和真实答案。
(8) Propagation by social bots.
现有的FID研究集中在索赔的内容和发布模式上。然而,对发布和传播帖子的 “账户 “的特征并没有很好的调查。最近,人们已经做出了一些努力来研究虚假信息像病毒一样迅速传播的根本原因。例如,Shao等人[155]对2016年美国总统选举期间的1400万条推文进行了详细分析,他们观察到
“社交机器人 “显然促进了虚假信息的快速传播。社交机器人通常指的是一种计算机算法或软件程序,为了某种目的而模仿人类的互动行为(例如,生产内容、关注其他账户、转发帖子等)[40]。这些恶意的机器人账户在虚假推文传播的早期阶段异常活跃。此外,在对社交机器人的社会互动和情感互动进行建模后,Stella等人[167]发现,他们增加了负面和暴力内容在社交网络上的曝光。
以上发现表明,抑制社交机器人可以成为缓解虚假信息传播的一个有前景的方法。一些研究者分析了社交机器人的行为模式并提出了一些检测方法。例如,Ferrara等人[40]将现有的社交机器人检测方法分为四类,包括基于图的模型、众包、基于特征的模型和混合模型。Almaatoug等人[5]设计了一种社交机器人检测方法,该方法结合了内容属性、社交互动和个人资料属性。同样,Minnich等人[115]提出了BotWalk检测方法,该方法利用几个特征来区分用户和机器人账户,如元数据、内容、时间信息和网络互动。Cresci等人[27]对社交机器人的集体行为进行了穿透性分析,并介绍了一种用于垃圾邮件检测的社会指纹技术。特别是,他们利用数字DNA技术来描述所有账户的集体行为,然后他们提出了一种受DNA启发的方法来识别真实账户和垃圾邮件。Cresci等人[26]也利用集体账户的特征来检测恶意的机器人。由于社交机器人促进了低可信度声明的传播和负面内容的曝光[155, 167],未来的工作可以将FID与社交机器人检测相结合,为快速驳斥虚假信息提供新的解决方案。
(9) False Information Mitigation.
有效的FID是预防虚假信息的一部分,也需要科学研究来减少虚假信息的影响,这属于虚假信息缓解的研究范畴。一些著作对虚假信息缓解和干预的方法进行了回顾。例如,Sharma等人[156]从信息扩散的角度总结了三种缓解方法,即 “去污” “竞争级联 “和 “多阶段干扰”。Shu等人[159]将现有的缓解策略分为 “用户识别”、”网络规模估计 “和 “网络干预”。由于每个用户在虚假信息的传播中扮演着不同的角色,如意见领袖、监护人、恶意传播者和旁观者,因此有必要采取灵活的缓解措施。例如,意见领袖和监护人适合被推荐使用事实信息,以帮助传播真相[175],而恶意账户或机器人应被遏制[122]。正如Ozturk等人[125]曾经说过的,在Twitter上用事实核查信息展示虚假信息,有助于减少虚假信息的持续传播。基于这一观察,Budak等人[13]提出了多运动独立级联模型,它包含一个虚假信息的运动和一个真实信息的运动。此外,我们还可以利用多变量霍克斯过程[37]来模拟外部干预影响下的虚假信息的传播动态。
在未来的研究中,FID可以与上述缓解策略相结合,在防止社交网络上的虚假信息传播方面探索出更多有前景的工作。此外,Sundar[168]曾经证实,社交帖子中存在的来源归属改善了用户对在线信息的可信度和质量的看法。因此,来源归属和因果推理[158]也可以用来指导社交媒体上虚假信息的检测。
Detection and Resolution of Rumours in Social Media: A Survey
尽管人们越来越多地使用社交媒体平台来收集信息和新闻,但其未经审核的性质往往导致谣言的出现和传播,即在发布时未经核实的信息项目。同时,社交媒体平台的开放性提供了研究用户如何分享和讨论谣言的机会,并探索如何利用自然语言处理和数据挖掘技术自动评估其真实性。在这篇文章中,我们介绍并讨论了两种在社交媒体上流传的谣言:一种是长期流传的谣言,另一种是在突发事件等快节奏事件中催生的新出现的谣言,这些报道是零散发布的,在早期阶段往往是未经核实的状态。我们概述了对社交媒体谣言的研究,最终目标是开发一个由四个部分组成的谣言分类系统:谣言检测、谣言跟踪、谣言立场分类和谣言真实性分类。我们深入研究了科学文献中提出的开发这四个组成部分的方法。我们总结了迄今为止在开发谣言分类系统方面所做的努力和取得的成就,并在结论中对未来在社会媒体挖掘中检测和解决谣言的研究途径提出建议。
INTRODUCTION
社会媒体平台越来越多地被用作收集信息的工具,例如,社会问题(Lazer等人,2009年),以及在突发新闻事件中了解最新进展(Phuvipadawat和Murata,2010年)。之所以能做到这一点,是因为这些平台使任何拥有互联网连接设备的人都能实时分享他们的想法和/或发布他们可能目睹的正在发生的事件的最新情况。因此,社交媒体已经成为记者(Diakopoulos等人,2012;Tolmie等人,2017)以及普通公民(Hermida,2010)的有力工具。然而,虽然社交媒体提供了前所未有的信息来源,但由于平台缺乏系统性的努力来调节帖子,也导致了错误信息的传播(Procter等人,2013b;Webb等人,2016),然后需要额外的努力来确定其来源和真实性。与突发新闻故事相关的更新往往是零散发布的,这就造成了这些更新中很大一部分在发布时未经核实,其中一些可能后来被证明是错误的(Silverman 2015a)。在没有权威声明证实或驳斥一个正在进行的谣言的情况下,据观察,社交媒体用户往往会通过一个集体的、主观间的感觉制造过程来分享他们自己对谣言真实性的想法(Tolmie等人,2018),这可能会导致谣言背后的真相曝光(Procter等人,2013a;Li和Sakamoto,2015)。
然而,尽管社交媒体具有这种明显的稳健性,但其日益增长的产生谣言的趋势促使人们开发一些系统,这些系统通过收集和分析用户的集体判断(Lukasik等人,2016),能够通过加速感知过程来减少谣言的传播(Derczynski和Bontcheva 2014)。谣言检测系统可以在早期阶段识别出真实性不确定的帖子,可以有效地用来警告用户,其中的信息可能是虚假的(Zhao等人,2015)。同样,一个汇总了用户发布的不断变化的集体判断的谣言分类系统可以帮助跟踪谣言的真实性状态,因为它被暴露在这个集体感知的过程中(Metaxas等人,2015)。在这篇文章中,我们概述了开发这样一个谣言分类系统所需的组件,并讨论了到目前为止为建立该系统所做的努力的成功。
1.1 Defining and Characterising Rumours
谣言的定义。最近研究文献中的出版物使用了彼此不同的谣言的定义。例如,最近的一些工作将谣言错误地定义为被认为是虚假的信息(如Cai等人(2014)和Liang等人(2015)),而大多数文献将谣言定义为 “流通中的未经核实的、工具性的信息声明“(DiFonzo和Bordia,2007)。在我们的文章中,我们采用了谣言的定义特征,即它们在发布时是未经核实的,这与主要词典给出的定义是一致的,比如《牛津英语词典》将谣言定义为 “目前流传的不确定或可疑的故事或报告 “1,或者《梅里亚姆-韦伯斯特词典》将其定义为 “目前没有已知权威机构证明其真实性的声明或报告 “2。 这种未经核实的信息可能被证明是真的,或部分或完全错误;或者,它也可能仍未解决。因此,在这篇文章中,我们坚持这个流行的谣言定义,将其归类为 “在发布时其真实性尚未得到验证的流通信息“。这个定义的选择与近期社会媒体研究的一些文献不同;但是,它与主要的字典和社会科学的一个长期研究领域相一致(Allport和Postman 1946;Donovan 2007)。谣言可以被理解为一个尚未被验证的信息,因此它的真实价值在流传过程中仍未得到解决。当没有证据支持它,或者没有来自权威来源(如那些有信誉的人)或在特定背景下可能有可信度的来源(如目击者)的正式确认时,谣言就被定义为未经证实。
谣言类型。许多不同的因素可用于按类型对谣言进行分类,包括其最终的真实性价值(真实、虚假或未解决)(Zubiaga等人,2016c)或其可信度(例如,高或低)(Jaeger等人,1980)。另一个按类型对谣言进行分类的尝试是Knapp(1944),他提出了三种类型的谣言的分类法。(1) “白日梦 “谣言:即导致一厢情愿的谣言;(2) “无聊 “谣言:即增加焦虑或恐惧的谣言;以及(3) “楔子驱动 “谣言:即产生仇恨的谣言。当涉及到开发一个谣言分类系统时,主要决定要利用的方法的因素是它们的时间特征:
- 突发新闻中出现的新谣言。在突发新闻中出现的谣言通常是以前没有被观察到的。因此,谣言需要被自动检测出来,而且考虑到系统可用的训练数据可能与后来观察到的数据不同,谣言分类系统需要能够处理新的、未见过的谣言。在这些情况下,早期检测和解决谣言是至关重要的,需要实时处理帖子流。在突发新闻中出现的谣言的一个例子是,当一个可疑的恐怖分子的身份被报道时。谣言分类系统可能已经观察到其他类似的疑似恐怖分子的案件,但案件和涉及的名字很可能会有所不同。因此,在这些情况下,谣言分类器的设计需要考虑新案例的出现,以及它们可能带来的新词汇。
- 长时间讨论的长期谣言。有些谣言可能流传了很长时间,但其真实性却没有得到确定的证实。尽管(或可能是因为)很难确定实际的真相,这些谣言还是会引起人们巨大的、持续的兴趣。例如,关于奥巴马是穆斯林的传言就是如此。虽然这个说法没有证据,但似乎没有任何证据能让大家满意地推翻它。3 对于像这样的谣言,一个谣言分类系统可能不需要检测谣言,因为它可能是先验的。此外,该系统可以利用历史上关于该谣言的讨论来对正在进行的讨论进行分类,其中词汇的差异性要小得多,因此建立在旧数据上的分类器仍然可以用于新数据。与新出现的谣言相比,对于长期存在的谣言,处理通常是回顾性的,所以帖子不一定需要实时处理。
在整篇文章中,我们提到了这两种类型的谣言,描述了不同的访问者如何处理每一种谣言。
1.2 Studying Rumours: From Early Studies to Social Media
简史。谣言和相关现象已经被从许多不同的角度进行了研究(Donovan 2007),从心理学研究(Rosnow和Foster 2005)到计算分析(Qazvinian等人2011)。传统上,研究人们对谣言的反应是非常困难的,因为这将涉及到在谣言展开时实时收集反应,假设参与者已经被招募了。为了克服这一障碍,All-port(Allport and Postman 1946, 1947)在战时谣言的背景下进行了早期调查。他提出了研究谣言的重要性,强调 “有新闻价值的事件很可能会滋生谣言”,”流通中的谣言数量会随着主题对相关个人的重要性而变化,同时与相关主题有关的证据的模糊性。这使他提出了一个尚待回答的动机问题。”谣言可以被科学地理解和控制吗?” (Allport and Postman 1946)。他在1947年的实验(Allport and Postman 1947)揭示了一个关于谣言流通和信仰的有趣事实。他研究了美国总统富兰克林-D-罗斯福如何消除关于美国海军在1941年日本袭击珍珠港时遭受损失的谣言。研究表明,在总统发表讲话之前,69%的本科生认为损失比官方公布的要大;但五天后,在总统发表讲话的同时,只有46%的同等学生认为这一说法是真的。这项研究揭示了一个有声望的人发表的官方声明在影响社会对谣言准确性的看法方面的重要性。
早期的研究集中在不同的目标上。一些工作研究了决定谣言传播的因素,例如,包括谣言的可信度对其后续传播的影响,其中可信度是指谣言可能被视为真实的程度。Prasad(1935)和Sinha(1952)的早期研究认为,在自然灾害的背景下,可信度不是影响造谣的一个因素。然而,最近,Jaeger等人(1980)发现,当可信度较高时,谣言的传播更为频繁。此外,Jaeger等人(1980年)和Scanlon(1977年)发现,接受者认为谣言的重要性是决定它是否被传播的一个因素,最不重要的谣言被传播得更多。
互联网上的流言。互联网的广泛采用使自然环境下的谣言研究进入了一个新的阶段(Bordia 1996),并且随着社交媒体的出现而显得尤为重要,它不仅为分享信息提供了强大的新工具,而且也便于从大量的参与者那里收集数据。例如,Takayasu等人(2015)利用社交媒体研究了2011年日本地震期间流传的谣言的扩散情况,该谣言称地震后的雨水可能包括有害的化学物质,并导致人们被警告要携带雨伞。作者研究了早期报道该谣言的推文以及后来报道该谣言的推文的转发(RTs)情况。虽然他们的研究显示,后来的更正推文的出现减少了报告虚假谣言的推文的传播,但分析仅限于一个谣言,并没有为理解社交媒体中谣言的性质提供足够的洞察力。然而,他们的案例研究确实展示了一个对社会有重要影响的谣言的例子,因为市民们都在关注有关地震的最新动态,以保持安全。
社会媒体中的谣言。近年来,社交媒体作为研究谣言的一个来源已经得到了重视,这是因为它是收集与谣言相关的大型数据集的一个有趣的来源,而且,除其他因素外,其巨大的用户群和分享的便利性使其成为谣言滋生的沃土。研究普遍发现,由于用户在分享意见、猜想和证据时具有众包的自我修正特性,Twitter在驳斥不准确信息方面表现良好。例如,Castillo等人(2013)发现,在2010年智利地震的案例中,支持和驳斥虚假谣言的推文比例为1:1(每条支持的推文对应一条驳斥的推文)。Procter等人(2013b)在分析2011年英格兰骚乱期间的虚假谣言时得出了类似的结论,但他们指出,任何自我纠正的效果都很缓慢。相反,在他们对2013年波士顿马拉松爆炸案的研究中,Starbird等人(2014)发现Twitter用户在区分真相和骗局方面做得并不好。在研究三种不同的谣言时,他们发现支持虚假谣言的推文所占比例分别为44:1、18:1和5:1。Zubiaga等人(2016c)进一步深入研究了谣言传播和支持的时间方面,描述了对九个突发新闻事件中的谣言的分析。这项研究的结论是,虽然总体趋势是用户在早期阶段支持未经核实的谣言,但随着时间的推移,会转向支持真实的谣言和驳斥虚假的谣言。因此,社交媒体聚合大量用户社区的判断的能力(Li和Sakamoto 2015)促使人们进一步研究机器学习方法,以改善谣言分类系统。尽管谣言和错误信息的传播给此类系统的开发带来了挑战,但将开发过程分解成更小的组成部分并利用合适的技术,在开发有效系统方面取得了令人鼓舞的进展,这些系统可以帮助人们在评估从社交媒体收集的信息的真实性方面做出决定。
1.3 Scope and Organisation
这篇调查文章的起因是人们越来越多地使用Facebook或Twitter等社交媒体平台来发布和发现信息。虽然我们承认它们在收集独家信息方面的作用毋庸置疑,但它们的开放性、缺乏节制以及信息可以随时随地发布的便利性,无疑给信息质量保障带来了很大的问题。考虑到谣言的传播可能带来的不安和潜在的危害,近年来,开发处理谣言的数据挖掘工具的动机越来越强烈。这篇调查文章旨在深入研究谣言对开发用于收集社交媒体信息的数据挖掘应用所带来的这些挑战,并总结迄今为止在这个方向上的努力。
我们在第2节继续这一调查,研究社交媒体给众多领域带来的机会,同时也引入了必须处理谣言的新挑战。接着是对谣言分类系统的分析,我们首先描述了将谣言数据集放在一起的不同方法,以便进行进一步的实验;第3节描述了数据集的生成,首先是访问社交媒体API的方法,然后概述了收集和注释从社交媒体收集的数据的方法。我们在第4节中总结了对社交媒体中谣言的扩散和动态的特征和理解的研究结果。之后,我们在第5节中描述了构成谣言分类系统的组件。然后,在随后的章节中进一步描述这些组件并讨论现有的方法;第6节中的谣言检测系统、第7节中的谣言追踪系统、第8节中的谣言立场分类以及第9节中的真实性分类。我们在第10节中继续列举并描述了现有的处理谣言分类的应用和相关应用。最后,我们在第11节中总结了到目前为止的成就,并概述了未来的研究方向。
2 SOCIAL MEDIA AS AN INFORMATION SOURCE: CHALLENGES POSED BY RUMOURS
社会媒体越来越多地被一系列专业人士和公众所利用,成为了解最新发展和时事的信息来源(Van Dijck 2013;Fuchs 2013)。社交媒体的使用已经在许多不同的领域被发现是有用的;我们在下面描述一些最值得注意的使用。
新闻收集。社交媒体平台在新闻传播方面显示出巨大的潜力,在突发新闻报道方面有时甚至超过了专业新闻机构(Kwak等人,2010)。除其他外,这使人们能够从目击者和广泛的用户那里获得最新信息,这些用户可以获得潜在的独家信息(Diakopoulos等人,2012;Starbird等人,2012)。为了利用社交媒体平台的这一特点,研究人员研究了新闻收集工具的发展(Zubiaga等人,2013年;Diakopoulos等人,2012年;Marcus等人,2011年),分析了用户生成内容(UGC)在新闻报道中的使用(Hermida和Thurman,2008年;Tolmie等人,2017年),并探索了社交媒体催生合作和公民新闻的潜力,包括对社交媒体上发布的报道进行合作核查(Hermida,2012年;Spangenberg和Heise,2014年)。
突发事件和危机。近年来,社会媒体在紧急情况和危机中的使用也大幅增加(Imran等人,2015;Castillo,2016;Procter等人,2013a),其应用包括从目击者那里获得报告或找到寻求帮助的人。人们发现社交媒体对不同情况下的信息收集和协调非常有用,包括紧急情况(Yates和Paquette 2011;Yin等人2012;Procter等人2013a)、抗议活动(Trottier和Fuchs 2014;Agarwal等人2014)和自然灾害(Vieweg等人2010;Middleton等人2014)。
公共舆论。研究人员也在利用社交媒体来收集用户对一系列社会问题的看法,然后将其汇总以衡量公众意见(Murphy等人,2014)。研究人员试图清理社交媒体数据(Gao等人,2014),并试图摆脱人口偏见(Olteanu等人,2016),以了解社交媒体如何塑造社会对问题、产品、人物等的看法。古德曼等人(2011)。人们发现,社交媒体对于衡量选举期间的民意(Anstead和O’Loughlin 2015),以及网上意见对组织声誉(Sung和Lee 2015)或对健康项目的态度(Shi等人2014)等方面的影响都很有用。
金融/股票市场。社交媒体也已经成为了解金融界和股票市场最新发展的重要信息来源。例如,推文中表达的情绪被用来预测股市反应(Azar和Lo 2016),收集投资者在社交媒体上发布的意见(Chen等人,2014)或分析社交媒体帖子对品牌和产品的影响(李等人,2015)。
由于社交媒体作为信息来源的潜力越来越大,其传播错误信息和未经证实的主张的倾向已经引起了许多研究。研究考察了用户的可信度认知(Westerman等人,2014),也评估了用户依赖社交媒体收集新闻等信息的程度(Gottfried and Shearer,2016)。因此,社交媒体中存在的谣言和有问题的说法所带来的困难导致了人们对建立谣言分类系统的技术的兴趣,并通过促进用户收集准确的信息来缓解这一问题。谈到谣言分类系统的发展,有两个主要用例需要考虑。
- 处理长期存在的流言。在这种情况下,被追踪的谣言是预先知道的,并且社交媒体被作为收集意见的来源而加以挖掘。这个用例可能适用,例如,当想要追踪公众意见,或者当诸如潜在的收购等谣言在金融领域被长期讨论时。
- 处理新出现的传言。当某些事件或话题被追踪时,新的谣言突然出现。这种用例可能适用于新闻收集和紧急情况,在这种情况下,信息被零散地发布并需要被核实,或者其他突然出现的谣言,例如那些预计会对股票市场产生影响的政治决定。
3 DATA COLLECTION AND ANNOTATION
本节介绍了用于收集社交媒体数据的不同策略,这些数据能够研究谣言,以及收集数据注释的方法。
3.1 Access to Social Media APIs
访问、收集和存储社交媒体平台数据的最佳方式通常是通过应用编程接口(API)(Lomborg和Bechmann,2014年)。API是易于使用的界面,通常伴随着描述如何请求感兴趣的数据的文档。它们被设计成可以被其他应用程序访问,而不是为人设计的网络接口;API提供了一套定义明确的方法,应用程序可以调用这些方法来请求数据。例如,在一个社交媒体平台上,可能需要检索某个特定用户发布的所有数据或包含某个关键词的所有帖子。
在使用API之前,关键的第一步是阅读其文档,了解其方法和限制。事实上,每个社交媒体平台都有自己的局限性,当想要开发一个利用社交媒体数据的谣言分类系统时,这是关键。用于研究谣言的三个关键平台是Twitter、新浪微博和Facebook;这里我们简要讨论一下这三个平台的特点和局限。
- Twitter提供了使用其API的详细文档4,它可以访问REST API以从其数据库中获取数据,也可以访问流式API以实时获取数据。在注册了一个Twitter应用程序5后,该程序将生成一组密钥,用于通过OAuth认证访问API,然后开发人员将有机会使用一系列方法(”端点”)来收集Twitter数据。这些端点中最慷慨的是可以访问整个推文流中随机抽样的1%;要获得更大比例的数据通常需要付费。为了确保收集到全面的推文,最好是通过流媒体API实时收集推文;同样,从这个API免费收集的推文数量有1%的限制。使用Twitter的API的主要优点是它是最开放的,这可能部分解释了为什么它被最广泛地用于研究;主要的注意事项是它主要被设计用来收集实时或最近的数据,因此收集比过去几周更早的数据更具挑战性。推特在收集每条推文时都会提供一系列元数据,包括推文语言、地点(如有)等,以及发布推文的用户的详细信息。
- 新浪微博是中国最流行的微型博客平台,它提供的API与Twitter有许多相似之处。然而,对它的一些方法的访问是不公开的。例如,搜索API需要先与管理员联系以获得批准。此外,新浪微博提供的一系列方法只能通过其REST API访问,它缺乏一个官方的流媒体API来检索实时数据。要通过新浪微博的流媒体API检索实时数据,必须使用第三方供应商,如Socialgist。7,8 与Twitter一样,新浪微博为每个帖子提供一组元数据,包括帖子的信息和用户的详细信息。
- Facebook提供了一个记录在案的API,以及一套适用于多种编程语言和平台的软件开发工具包,使得利用其数据开发应用程序变得容易。与Twitter的API类似,Facebook也需要注册一个应用程序10来生成访问API所需的密钥。与Twitter相比,Facebook用户发布的大部分内容都是私密的,因此无法访问发布的具体内容,除非用户是认证账户的 “朋友”。获取Facebook上的帖子的变通方法通常是从所谓的Facebook页面收集数据,这些页面是由组织、政府、团体或协会创建的公开页面。与Twitter不同的是,从这些Facebook页面获取历史数据是可能的;但是,访问仅限于在这些页面上发布的内容。脸谱网提供的每个帖子的元数据更加有限,需要向API提出额外的请求才能获得这些数据。
4 CHARACTERISING RUMOURS: UNDERSTANDING RUMOUR DIFFUSION AND FEATURES
最近的许多研究都关注了社会媒体中谣言的出现和传播的特点。从这些研究中得到的启示反过来也可以为谣言分类系统的发展提供参考。其中一些研究集中于对某一特定谣言的广泛分析,而另一些研究则是对较大的谣言集进行更广泛的分析。
对围绕谣言的话语进行研究是为了考察围绕谣言的讨论以及谣言随时间的演变。一些研究着眼于定义一个方案,以对谣言的反应类型进行分类。Maddock等人(2015年)研究了谣言的起源和随时间的变化,从而确定了对谣言的七种行为反应:错误信息、猜测、纠正、质疑、对冲、不相关或中立/其他。同样,Procter等人(2013b)提出,对谣言的反应可以分为四种类型,即支持、否认、呼吁提供更多信息和评论。还有人研究了谣言,以了解人们对谣言的反应。通过研究在中国微博平台上传播的谣言,Liao和Shi(2013)确定了七种类型的用户(名人、认证、大众媒体、组织、网站、网络明星和普通人)的干预,他们以七种不同的方式(提供信息、发表意见、情感状态、感性陈述、询问性陈述、指导性陈述和离题陈述)做出贡献。在另一项研究中,Zubiaga等人(2016c)研究了由Twitter上的谣言报道引发的 “对话”(即由回复关系连接的一系列推文),发现社交媒体用户的普遍倾向是支持和传播谣言,而不考虑其真实性价值。这包括声誉高的用户,如新闻机构,他们倾向于在谣言的早期阶段支持谣言,稍后在需要时发布更正声明。在早期的研究中,Mendoza等人(2010)发现了谣言支持和真实性之间的强烈关联,表明大多数用户支持真实的谣言,而更多的用户否认虚假的谣言。尽管这些研究之间存在明显的矛盾,但值得注意的是,Mendoza等人(2010年)研究了谣言的整个生命周期,因此汇总导致了良好的相关性;相反,Zubiaga等人(2016c)专注于谣言的早期再行动,表明用户在谣言的早期阶段确定真实性方面存在问题。利用Reddit的谣言数据,也发现了不同用户之间的差异,表明有三个不同的用户群体:一般支持虚假谣言的用户,一般反驳虚假谣言的用户,以及一般对虚假谣言开玩笑的用户(Dang等人,2016a)。也有人认为,更正通常是由新闻机构发布的,它们有时会被广泛传播(Takayasu等人,2015;Arif等人,2016;Andrews等人,2016),特别是如果这些更正来自志同道合的账户(Hannak等人,2014),偶尔甚至会导致原始帖子的删除或取消分享(Frias-Martinez等人,2012)。然而,更正并不总是具有与原始谣言相同的效果(Lewandowsky等人,2012;Shin等人,2016;Starbird等人,2014),这加强了开发处理新出现的谣言分类系统的必要性。
其他研究也关注了促使谣言传播的因素。谣言的传播通常取决于用户之间的关系强度,谣言更有可能在网络中的强关系中传播(Cheng等人,2013)。其他对谣言时间模式的研究表明,在社交媒体(Kwon等人,2013年;Kwon和Cha,2014年;Lukasik等人,2015年b)和互联网上的其他平台(Jo,2002年),谣言的流行度往往会随着时间的推移而波动,但在谣言流行度消退后又有可能被重新讨论。
研究还考察了谣言的出现。通过使用谣言理论方法来研究导致表达对追踪谣言的兴趣的因素,Oh等人(2013)认为缺乏官方来源和个人参与是最重要的因素,而其他因素,如焦虑,则不那么重要。海报的可信度和谣言的吸引力也被认为是促成谣言传播的因素(Petty和Cacioppo 2012)。Liu等人(2014)强化了这些发现,认为个人参与是最重要的因素。Chua等人(2016)分析了Twitter上的具体谣言信息,发现拥有较大粉丝网络的成熟用户的推文传播最广。
虽然许多研究都探讨了谣言的传播,但对这些研究的详尽分析并不在本调查文章的范围内,而是侧重于有关检测和解决谣言的方法的发展研究。要阅读更多关于研究谣言扩散的研究,我们推荐Serrano等人(2015)和Walia和Bhatia(2016)的调查。
5 RUMOUR CLASSIFICATION: SYSTEM ARCHITECTURE
谣言分类系统的结构可以有轻微的变化,这取决于具体的使用情况。这里我们定义了一个典型的谣言分类系统的架构,它包括一个完整系统所需的所有组件;然而,正如我们在下面的描述中指出的,根据需求,其中一些组件可以省略。谣言分类系统通常从确定某条信息未被证实开始(即谣言检测),最后确定该条信息的估计可信度值(即可信度分类)。从谣言检测到真实性分类的整个过程是通过以下四个部分进行的(见图1)。
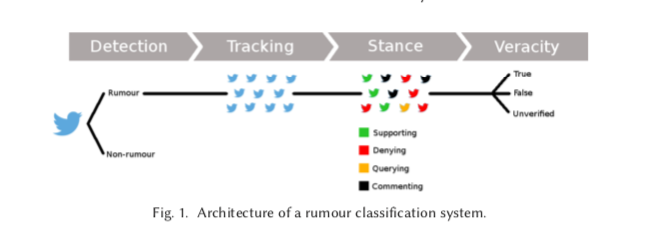
- 谣言检测。首先,一个谣言分类系统必须确定一条信息是否构成谣言。谣言检测组件的典型输入可以是社交媒体的帖子流,然后一个二元分类器必须确定每个帖子是被视为谣言还是非谣言。这个组件的输出是帖子流,其中每个帖子都被标记为谣言或非谣言。这个组件对于识别新出现的谣言很有用;但是,在处理先验已知的谣言时,它就没有必要了。
- 谣言追踪。一旦确定了一个谣言,或者因为它是先验的,或者因为它是由谣言检测组件确定的,谣言跟踪组件就会收集和过滤讨论该谣言的帖子。谣言的输入可以是一个帖子或描述它的句子,也可以是一组关键词,这个组件监测社交媒体以找到讨论该谣言的帖子,同时剔除不相关的帖子。该组件的输出是讨论该谣言的帖子的集合。
- 立场分类。当谣言追踪组件检索与谣言相关的帖子时,立场分类组件确定每个帖子对谣言的真实性的定位。将一组与同一谣言相关的帖子作为输入,它为每一个帖子输出一个标签,这些标签一般从预定义的立场类型集合中选择。这个组件对于促进后续处理真实性分类的组件的任务很有用。但是,如果公众的立场被认为是没有用的,例如,仅仅依靠专家的输入或权威来源的验证的情况下,它可以被省略。
- 真实性分类。最后的真实性分类组件试图确定谣言的实际真相价值。它可以使用在谣言跟踪组件中收集到的帖子集,以及在立场分类组件中产生的立场标签作为输入。它可以选择从其他来源,如新闻媒体,或其他网站和数据库中收集额外的数据。该组件的输出可以只是预测的真值,但它也可以包括上下文,如URL或其他数据源,以帮助最终用户通过与相关来源的双重检查来评估分类器的可靠性。
在下面的章节中,我们将更详细地探讨这四个组成部分,到目前为止用于实施这些组成部分的方法以及迄今取得的成就。
6 RUMOUR DETECTION
6.1 Definition of the Task and Evaluation
谣言检测任务是指系统必须从一组社交媒体帖子中确定哪些帖子是报告谣言的,因此是在传播有待核实的信息。请注意,一条推文构成谣言的事实并不意味着它以后会被认为是真的或假的,而是意味着它在发布的时候是未经核实的。从形式上看,该任务将社交媒体帖子的时间线TL={t1,…,t|TL|}作为输入,分类器必须确定这些帖子中的每一个,ti,是谣言还是非谣言,从Y={R,NR}中分配标签。因此,该任务通常被表述为一个二元分类问题,其性能通过计算目标类别(即谣言)的精度、召回率和F1分数来评估。
6.2 Datasets
唯一公开的数据集是PHEME的谣言和非谣言数据集,其中包括与5个突发新闻故事相关的1972个谣言和3830个非谣言的集合(Zubiaga等人,2016b)。
6.3 Approaches to Rumour Detection
尽管人们对分析社交媒体中的谣言和建立工具来处理之前已经确定的谣言越来越感兴趣(Seo等人,2012;Takahashi和Igata,2012),但在自动谣言检测方面的工作却很少。谣言检测方面的一些工作(Qazvinian等人,2011年;Hamidian和Diab,2015年,2016年)仅限于寻找先验的谣言。他们用一组预定义的谣言(例如,奥巴马是穆斯林)来喂养分类器,将新的推文分类为与已知的谣言之一有关或无关(例如,我认为奥巴马不是穆斯林将与谣言有关,而奥巴马正在与一群穆斯林交谈则不是)。像这样的方法对于长期存在的谣言是很有用的,在这种情况下,需要的是识别与追踪已经确定的谣言有关的推文;在这篇调查文章中,我们把这项任务称为谣言追踪,因为被监测的谣言是已知的,但帖子流需要被过滤。仅仅依靠谣言追踪是不够的,因为在快节奏的背景下,如突发新闻,会出现新的、未见过的谣言,而与尚未被发现的谣言相关的具体关键词并不是预先知道的。为了处理这个问题,分类器将需要学习可概括的模式,以帮助在新出现的事件中识别谣言。
第一个解决新谣言检测的工作是Zhao等人(2015)的工作。他们的方法建立在这样的假设上:谣言会引起怀疑论者的推文,他们会质疑或询问谣言的真实性;如果一条信息有一些相关的询问推文,那么就意味着该信息是谣言的。作者创建了一个由五个正则表达式(例如”(那个|这个|它)是真的吗”)组成的人工策划列表,用于识别询问性推文。然后,这些询问的推文按相似度进行聚类,每个聚类最终被视为一个候选谣言。他们用召回率来评估是不可行的,而只用精确度来评估。
相比之下,Zubiaga等人(2016b,2017)提出了另一种方法,在整个突发新闻故事中学习上下文,以确定一条推文是否构成谣言。他们的假设是,由于缺乏上下文,单单一条推文可能不足以知道其背后的故事是否是谣言。此外,他们避免了对询问性推文的依赖,他们认为并非所有的谣言都会引发,因此可能导致低召回率,因为没有引发询问性推文的谣言会被遗漏。他们的上下文学习方法依靠条件随机场(CRF)作为顺序分类器,学习事件中的报道动态,这样分类器就可以根据事件中迄今为止的情况,对每条新推文确定其是否是谣言。他们的方法导致了比Zhao等人(2015)的基线分类器更高的性能,也改善了一些作为基线的非序列分类器。在这种情况下,该分类器也被评估为召回率,取得了最先进的结果。
Tolosi等人(2016年)对不同事件中的谣言进行特征分析,发现很难区分谣言和非谣言,因为不同事件的特征变化很大。Zubiaga等人(2016b)解决了推特层面的这些发现,表明通过利用事件的背景,可以实现普遍性。
McCreadie等人(2015年)研究了使用众包平台来识别社交媒体中的谣言和非谣言的可行性,发现注释者取得了很高的注释者之间的一致性。他们还将谣言分为六个不同的类型。未经证实的信息、有争议的信息、错误的信息/虚假的信息、报道、有关联的争议和有意见的。然而,他们的工作仅限于对谣言和非谣言的众包注解,他们没有研究自动谣言检测系统的发展。这项研究的数据集没有公开提供。
然而,其他的工作被贴上了谣言检测的标签,专注于确定社交媒体上发布的信息是真的还是假的,而不是早期检测未经核实的信息,因此我们在第9节关于真实性分类中讨论。
技术现状。谣言检测的最先进方法是Zubiaga等人(2017)提出的方法,它利用与特定事件相关的早期帖子的上下文来确定一条推文是否构成谣言。
11 DISCUSSION: SUMMARY AND FUTURE RESEARCH DIRECTIONS
随着社交媒体渗透率的提高,关于开发谣言检测和验证工具的研究变得越来越受欢迎,它使普通用户和专业从业人员能够实时收集新闻和事实,但也带来了未经核实的信息传播的副作用。这篇调查文章总结了科学文献中关于发展谣言分类系统的研究,对社会媒体谣言进行了定义和定性,并描述了发展其四个主要组成部分的不同方法。(1) 谣言检测,(2) 谣言追踪,(3) 谣言立场分类,以及(4) 谣言真实性分类。在这样做的过程中,该调查为这些组件的开发提供了一个技术现状的指导。该调查特别关注在社交媒体上流传的谣言的分类。大多数一般方面,如谣言的定义和分类架构,都是可以推广到新闻文章等类型的。然而,为四个部分中的每一部分描述的具体方法通常是为社交媒体设计的,不一定直接适用于其他体裁。在下文中,我们将回顾迄今为止所取得的进展,现有系统的缺点,概述对未来研究的建议,并评论谣言分类系统对其他类型的误导性信息的适用性和通用性,这些信息也在社交媒体中传播。
自从社交媒体作为信息和新闻收集的平台激增以来,检测和解决谣言的研究有了很大进展。一系列的研究采取了非常不同的方法来理解和描述社会谣言,而这种多样性有助于阐明谣言分类系统的未来发展。在构成谣言分类系统的所有四个组成部分中,已经进行了重新搜索,尽管大多数都集中在管道的最后两个组成部分,即谣言立场分类和真实性分类。尽管如本调查所示,该研究领域取得了实质性进展,但我们也表明,这仍然是一个需要进一步研究的开放性研究问题。我们在下一节中研究主要的开放性研究挑战。
11.1 Open Challenges and Future Research Directions
近年来,谣言分类的研究主要集中在管道的后期阶段,即谣言的立场分类和真实性分类。这些都是至关重要的阶段;然而,如果不执行前面的检测谣言和跟踪与这些谣言相关的帖子的任务,它们就不能被使用。后者在以前的工作中通常被跳过,要么把这些组件的开发留给未来的工作,要么假设谣言和相关帖子是由人输入的。我们认为,未来的研究应该集中在谣言的检测和跟踪上,以避免完全依赖人在回路中的情况,从而减轻这些初始任务。在这个方向上的进一步研究将能够开发出完全自动化的谣言分类系统。
谣言检测的研究应该从在谣言的特定背景下测试最先进的事件检测技术开始。除了事件检测系统所做的,谣言检测系统还需要确定检测到的事件是否构成谣言。如果只使用其内容,确定一个单独的社交媒体帖子是否报告了一个谣言是具有挑战性的。最近的研究表明,使用上下文(Zubiaga等人,2017年)和互动(Zhao等人,2015年)可以提供帮助,这些都是值得详细探索的方向。
对谣言追踪系统的研究是有限的,而且研究人员经常假设用于收集与谣言有关的帖子的关键词是先验的。社交媒体的一个明显的问题是用户之间使用不一致的词汇,例如,用户可能不明确地使用杀戮或射击来指称同一事件。在扩大数据收集方面的研究仍处于起步阶段,通过技术(如伪相关性反馈)使用查询扩展方法,还有待详细探讨,但初步研究显示了其潜力
谣言分类系统发展的一个重要限制是缺乏公开可用的数据集。除了我们在本调查中列出的最近发表的数据集,我们鼓励研究人员发布他们自己的数据集,以便对不同的数据集进行进一步研究,从而使科学界能够相互比较他们的方法。
虽然许多人试图自动确定谣言的真实性价值,但鉴于分类器不可避免地会出现错误,仅仅输出真实性的最终决定的系统可能并不总是足够的。为了使真实性分类器的输出更加可靠,我们认为系统需要提供更丰富的输出,其中还包括决策的原因(Procter等人,2013b)。真实性分类器不仅输出自动确定的真实性分数,而且还链接到可以证实这一决定的来源,这将更加稳健,因为它将使用户能够评估分类器决定的可靠性,并且—如果发现想要忽略它。例如,可以通过使用立场分类器的输出来丰富真实性分类器的输出,选择一些支持和反对的观点,作为摘要呈现给用户。鉴于实现完全准确的真实性分类器是一个不太可能的目标,我们认为这个方向的研究应该特别关注寻找信息源,以促进终端用户对谣言的真实性做出自己的判断。
现有真实性分类系统的另一个注意事项是,它们侧重于确定真实性,而不考虑谣言是否得到解决。在谣言尚未解决的情况下,真实性分类任务就变成了预测任务,由于缺乏支持系统决策的证据,这对终端用户来说可能并不可靠。由于谣言具有未经证实的立场,确定其真实性很难,或者需要权威来源的参与,未来的研究应该研究谣言真实性确定的时间性,可能会尝试在找到证据后很快确定真实性。
谈到立场分类,最近的工作表明,利用社交媒体流和对话中的上下文来开发个人帖子立场的最先进分类器是有效的。然而,这个方向的研究仍处于起步阶段,还需要更多的研究来最好地利用这种背景来最大化立场分类器的性能。谣言分类的研究主要依赖于社交媒体帖子的内容,而从用户元数据和互动中提取的进一步信息可能有助于提高分类器的性能。
 wechat
wechat alipay
alipay





