Learn Continually, Generalize Rapidly, Lifelong Knowledge Accumulation for Few-shot Learning
Learn Continually, Generalize Rapidly: Lifelong Knowledge Accumulation for Few-shot Learning
随着时间的推移不断扩展知识,并利用这些知识迅速归纳到新的任务中,这是人类语言智能的一个关键特征。
现有的追求快速泛化到新任务的模型(如few-shot learning),大多是在固定的数据集上进行单次训练,无法动态地扩展其知识;而持续学习算法则不是专门为快速泛化设计的。
作者提出了一个新的学习设置,即 “ Continual Learning of Few-Shot Learners”(CLIF),以在一个统一的设置中解决这两种学习设置的挑战。
CLIF假设一个模型从一连串不同的NLP任务中依次学习,积累知识以提高对新任务的概括能力,同时也保留了之前学习的任务的性能。
本文研究了在持续学习设置中泛化能力是如何受到影响的,评估了一些持续学习算法,并提出了一种新颖的带有正则化的Adapter的双级超网络。
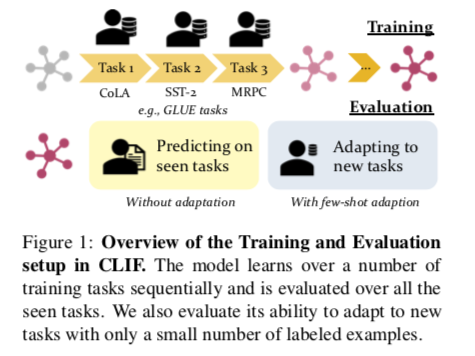
挑战:模型在一连串的NLP任务中学习(逐一到达;不重复访问),然后在以下方面进行评估:(1)对新的(few-shot learning)任务的泛化;以及(2)保留其在解决已见任务上的性能。
作者认为此类任务与LifeLong的区别:
此任务研究了NLP模型是否可以在一连串的任务中不断积累可归纳的知识,并迅速学习归纳到新的任务。
相关的工作是希望从连续到达的任务中学习,被称为持续学习(CL),主要关注的是当模型在新任务中被持续更新时,保留在所见任务中的表现。在后续的分析中,发现,现有的大多数CL方法几乎不利于模型的泛化能力,即使它们被证明可以缓解灾难性遗忘。
Problem Formulation
The CLIF Problem
我们假设有一个NLP模型 $f$ 随着时间的推移在不同的任务上不断地训练(即持续学习),然后通过少量的例子迅速概括到许多未见过的任务(即few-shot适应)
在持续学习阶段,模型遇到一个有序的 $N_u$ 上游任务列表 : $[T_u^1,…,T^{N_u}_u]$ ,其中每个任务有自己的训练集和测试集。
为了测试连续选了的模型 $f$ 的 few-shot 学习能力,在一组单独的 $Nv$ 少量任务 ${T_v^i}{i=1}^{N_v} $ 上对其进行adapt ,其中每个未见的任务只有几个训练样本。
在CLIF中,除了传统的CL目标是保持在所见任务上的性能外,在CLIF中,保持可概括的知识以在训练结束时获得更好的few-shot learning性能也是至关重要的。
Evaluation Protocol
如图所示,针对CLIF设置评估方法有三个主要方面:few-shot性能、最终性能和即时性能。
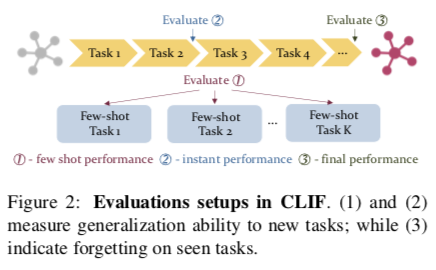
- Few-shot Performance: 首先,在一组未见过的任务上评估持续训练的模型 $f$, 在上游任务 $T^1u,…,T_u^{N_u}$ 训练结束后,用几个标注的样本对每个任务 $T_v^i$ 进行微调。因此,我们可以评估 few-shot 的泛化能力。把一个任务 $T_v^i$ 的 few-shot accuracy 记为 $s{FS}^i = F(Yv^i, \hat Y_v^i)$, 其中 $\hat Y_v^i$ 是对任务 $T{v}^i$ 的测试样本进行预测, $Yv^i$ 是真实标签。$F$ 是度量函数如accuracy。 记录所有few-shot 任务,例如:$s{FS}= \frac{1}{Nv} \sum{i=1}^{Nv} s{FS}^i$ 。 还计算了在每个 few-shot 任务上单独训练的模型的相对改进 $\Delta_{FS}$
- Instant Performance : 在模型完成对上游任务 $Tu^i$ 的学习后,立即评估其性能,在模型$f$ 将任务 $j$ 学习为 $\hat Y{u}^{i,j}$ 之后,记录在任务 $Tu^i$ 的测试集上的预测。 Instant performance 在任务 $T_u^i$ 上被定义为 $s{inst.}^i = F(Yu^i,\hat Y_u^{i,i})$ 。例如,模型 $f$ 在 $T_u^1$ 和 $T_u^2 $ 的数据上训练之后,在 $T_u^3$ 上进一步训练之前评估 $f$ 在 $T_u^2$ 上的性能。因此,$f$ 在 $T_u^2 $ 上的表现可以告诉我们,模型将其知识从学习 $T_u^1 $ 转移到学习 $T_u^2 $ 的情况 —— 使用 $f$ 仅只在 $T_u^2 $ 上训练时的表现作为参考。我们计算所有上游任务的 Instant performance,$s{inst.} = \frac {1}{Nu} \sum{i=1}^{Nu} s{inst.}^i $ ,此外还计算了相对于在每个上游任务上单独训练的改进 $\Delta_{inst.}$, 以表明上游学习的好处。
- Final Performance :评估 $f$ 在对上游任务的持续学习结束时的表现,以了解模型 $f$ 在学习解决更多任务后对任务知识的遗忘程度。一个任务 $Tu^i $ 的最终 accuracy 被定义为 $F(Y_u^i,\hat Y_u^{i,N_u})$ 。同样地,我们报告了所有任务的平均最终准确度,记为 $s{final} = \frac{1}{N} \sum{i=1}^{N_u} s{final}^i$。遗忘可以被量化为 $s{inst} - s{final}$ 。
Challenges
CLIF 的设置对现有的 few-shot learning 方法来首特别具有挑战,大多数 few-shot 学习方法假定所有任务的上游数据集总是可用的,并且没有按时序去学习。因此,上游的任务可以在多任务学习的环境下共同学习。然而,CLIF问题采用的是持续学习的设置,即任务是按顺序访问的,没有重新访问。因此,依靠从任务分布中随机抽样的方法并不适用。
Tasks and Data Streams
为了将CLIF挑战推向一个更实际的设置,考虑了一组多样化的NLP任务来进行CL和few-shot learning。我们考虑了两个数据集的组合,被称为CLIF-26和CLIF-55任务:
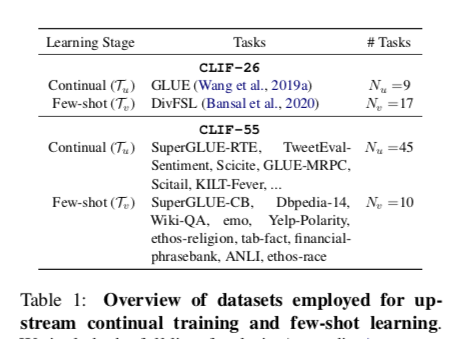
将CLIF-26中每个GLUE任务中的训练样本数量限制在10,000个,以避免数据集过度失衡。对于CLIF-55,每类使用90个样本进行连续学习。
在CLIF-26和CLIF-55的 few-shot 学习任务中,如果没有指定的话,每类使用 k=16 个样本,并在实验中包括更多的 k 的设置。由于GLUE的测试标签没有公开,仅报告了验证集的性能。
Method
首先介绍我们研究中的 baseline。然后,我们介绍一些现有的持续学习和持续元学习的方法。最后,提出了一个新颖的正则化双级适配器生成框架,以更好地解决CLIF问题。
Base NLP Models
BART and BART-Adapter
由于将CLIF问题中的NLP任务制定为统一的文本到文本格式,我们使用预先训练好的语言模型(LM)作为模型f的架构,并在训练期间对整个模型进行微调。
我们还包括Adapter训练,作为对整个BART模型进行微调的一种改变。这里,适配器是插在BART每层之后的两层MLPs。
给出 transformer的第 $l$ 层的输出 $h_l$ , adapter的输出被计算为 $h_l’ = h_l + f_l^a(h_l)$, 其中 $f_l^a$ 是在 $l$ 层的adapter。只有adapter在训练中被学习,BART模型被frozen。
Hyper-Networks for Adapter Generation
除了BART和BART适配器之外,还使用考虑HyperNetwork(HNet)架构。HyperNetwork 记为 $g$ ,将任务表示 $z$ 作为输入,并生成另一个预测模型的模型参数,记为 $f$ 来解决该任务。在 few-shot learning 中,$z$ 通常被计算为任务的训练实例的平均表示,即 任务的平均表示: $z = \frac{1}{|D{tr}^i|} \sum{(xj,y_j)\in D{tr}^i} fe(x_j, y_j) $ ,其中 $D{tr}^i$ 是任务 $T^i$ 的训练集,$f_e$ 是encoder。
我们使用一个BART编码器作为 $f_e$,并将 $x$ 和标签 $y$ 的文本格式串联起来,得到任务表示 $z$。
Baseline Learning Algorithms
Single Task Learning
为了了解基础模型在没有任何知识转移的情况下对上游任务的参考性能,应用了单一任务学习(STL)方法,该方法在每个任务的数据集上单独地训练和测试模型 $f$。
在这种情况下,我们忽略了CLIF问题的顺序性,所以我们可以用这个STL的性能来评估不同的持续方法(下面介绍)的有效性。理想情况下,一个有效的 CL 算法应该具有比 STL 结果更好的几率准确性,这意味着它积累了并有效地迁移了知识,用于学习。
同样地,为了了解 few-shot 任务的参考性能,我们在没有任何上游训练的情况下,为每个 few-shot 任务学习一个模型 $f$ ,这样我们就可以用这种性能来评估CLIF方法对泛化能力的改善程度。
Continual Learning Algorithms
作为一种简单的基线方法,我们使用 Vanilla 表示简单地在上游任务上按顺序训练模型 $f$。
具体来说,它在 $T_u^i$ 上训练模型 $f$,直到其性能收敛,然后在 $T_u^{i+1}$ 的数据上不断训练 $f$。
请注意,CL 中不允许访问先前任务的数据,还考虑在实验中考虑 CL 算法,例如 EWC、MbPA++和 meta-MbPA。
EWC 正则化了训练过程中重要模型参数的变化,MbPA++ 方法对存储在内存中的几个训练样本执行测试 test-time 调整。 meta-MbPA 方法包括快速适应元学习目标。
Hyper-Networks for CL
《Continual learning with hypernetworks》 提出了 hypernetwork-based continual learning。其中减轻灾难性遗忘的高级想法是惩罚超网络在其学习新任务时为先前任务生成的模型权重的改变。虽然原始工作生成模型的整个参数,但我们仅通过生成适配器的权重来使其适应 PTLMs。 将这种方法记为 HNet-Reg。
具体来说,当模型刚刚完成学习任务 $T{u}^{i-1}$ 并且在持续学习阶段学习任务 $T_u^i$ 之前,我们存储当前超网络为所有先前任务 $T_u^1…T_u^{i=1}$ 生成的适配器权重,记为 ${\hat\theta_1^{i-1},\hat\theta_2^{i-1},…,\hat\theta{i-1}^{i-1}}$ ,其中生成是通过超网络 $h$ 应用于先前任务 $1,..,{i-1}$ 的存储任务表示来控制的,记为 $M = {z_h^1,…,z_h^{i-1}}$ 。在这里,任务 $T_u^i$ 的任务表示 $z_i$ 在学习任务之前随机初始化,并在学习任务时联合优化。
然后,在学习 $T_u^i$ 的每一步中,我们随机抽样一个先验任务 $T_u^j \ \ (j < i)$ 来规范超网络学习。 它惩罚在当前步骤 $\theta_j$ 生成的适配器权重与预先计算的权重之间的 $l_2$ 距离,例如 $||\theta_j-\hat \theta_j^{i-1}||_2^2$
因此,避免了超网络 g 在持续学习阶段过多地改变其先前任务的输出,从而更好地保证学习模型的知识积累。
Limitations
EWC 和 HNET-Reg 不是为 CLIF 问题精心设计的,CLIF还试图在持续学习后改进对未知任务的 few-shot 泛化。 虽然 MbPA 和 meta-MbPA 中的 test-time 适应可能有利于 few-shot learning,但这些工作并未研究这种能力。 此外,由于这两种算法存储了先前训练任务的真实数据,因此不适用于无法再访问来自早期任务的数据的隐私敏感应用,这是持续学习中的典型场景。
Our Extension: Bi-level Hypernetworks for Adapters with Regularization
受用于 few-shot 和 CL的超网络方法的启发,我们将基于超网络的CL方法扩展到CLIF。我们提出了一种新的方法,即带有正则化的双级超网络Adapters(BiHNet+Reg),该方法学习使用双级任务表示来生成Adapters权重,以便在一连串的任务中学习快速适应模型,同时通过正则化来减轻遗忘效应。
方法由三个组件组成:
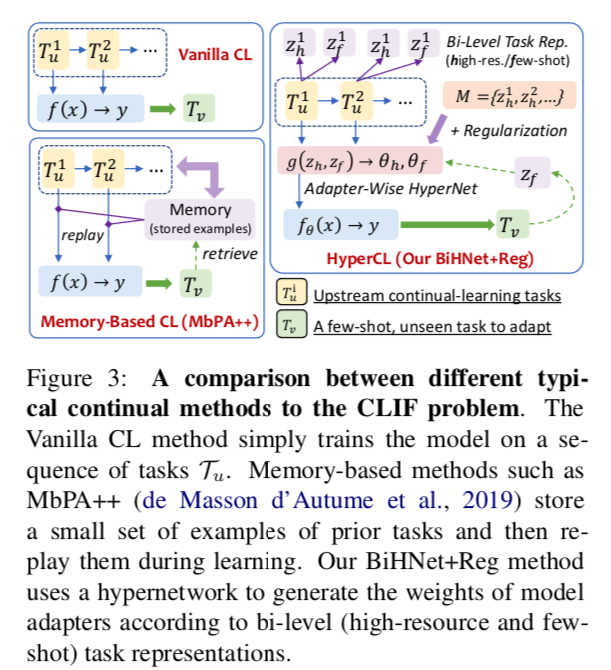
- Context Predictor 上下文预测器,从训练实例中生成双级任务表征(即高资源和few-shot表征)
- Adapter-Wise Hypernetworks 超网络,根据任务表征生成适配器的权重;
- Regularization 正则化项,阻止所见任务的权重变化以避免遗忘
Context Predictor
为每个任务 $t$ 生成两个任务表征,分别在高资源和 few-shot 的情况下为其建模,表示为 $z_h^t$ 和 $z_f^t$,用frozne BART编码器。高资源表征用于鼓励持续学习过程中的知识转移;few-shot 任务表征帮助我们在 few-shot learning 模仿 few-shot任务,以获得更好的泛化,类似于元学习。
然后,高资源任务表示被计算为任务 $t$ 中所有样本的上下文向量的平均值。 记为:$zh^t = \frac{1}{|D_t|} \sum{(x_i,y_i)\in D_t} R(x_i, y_i)$
然而,few-shot 任务表示 $zf^t$ 使用有限数量 K 个采样样本 $z_f^t = \frac{1}{k} \sum{(xi,y_i)\in \Tau(D_t, K)} R(x_i, y_i)$, 其中$\Tau(D_t,K)$ 是在 $D_t$ 中采样K 个样本。请注意,在不断的学习过程中,上游任务的高资源表征被长期储存在一个记忆模块中,$M={z_h^t| t\in {\Tau_u^i}{i=1}^{N_u}}$ 。在few-shot的学习阶段,我们设定 K为给定的样本的数量,因此对于任何任务,$z_h=z_f$。
Adapter-Wise Hypernetworks
使用超网络 $g$ 来生成frozen BART模型 $f$ 的各层之间的适配器的权重。
在训练过程中,使用高资源和采样的任务表征 $z_h^t$ 和 $z_f^t$ 来产生适配器权重 分别记为 $\theta_t^h$ 和 $\theta_t^f$。我们对这两个适配器的预测损失进行了优化。
Regularization
HyperNetwork是模型中唯一可训练的部分,对生成的适配器施加正则化以减轻遗忘。
虽然 BiHNet 被训练为从高资源和低资源任务表示生成适配器,但发现仅存储和正则化来自高资源任务表示的输出就足够了。
Summary and Highlights
总而言之,提出的方法首先生成了双级任务表征,用于训练具有正则化项的适配超网络,以避免随时间推移而遗忘。
与基于重放记忆的CL方法(例如MbPA)不同,我们的方法不存储任何真实的训练实例。相反,它使用任务表示来存储记忆,因此允许该方法应用于对隐私敏感的场景中。
Results and Analysis
在本节中,将讨论两个主要研究问题:
- 考虑到潜在的灾难性遗忘,与离线设置相比,模型如何在CL设置中长期积累可推广的知识?
- 持续学习的方法是否能减少对所见任务的表现和可归纳知识的灾难性遗忘。
作者在试验了各种模型架构的组合和学习算法。通过其模型结构和应用的CL算法来说明一种方法,例如BART-Vanilla, BiHNet-EWC。
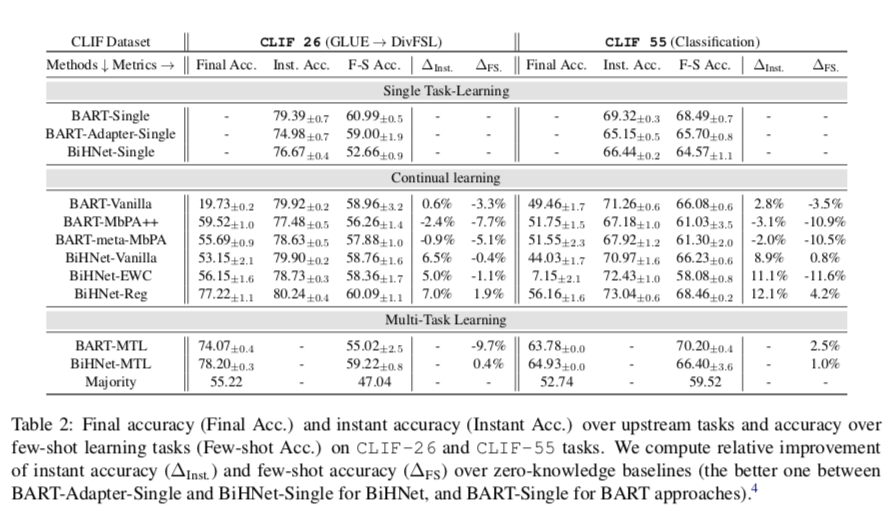
Examining Knowledge Accumulation
在这一节中,提出了对模型在离线和CL设置中获得可归纳知识的能力的分析。
我们注意到BiHNet方法,对应于学习生成适配器,应与BiHNet-Single和BART-Adapter-Single进行比较,后者是零知识基线,其学习生成或从随机初始化中学习适配器;
同样,BART方法应与BART-Single进行比较。重点是确定CLIF的挑战,并将方法论的讨论留在下一小节。
问题1:来自上游任务的知识是否有助于模型在在线学习和持续学习设置中的few-shot泛化?
看表2,在CLIF-26和CLIF-55数据集上,我们看到BiHNet-MTL在 few-shot 情况下的表现比零知识基线要好0.4%和1.0%,这意味着在标准的离线学习设置中,上游任务对few-shot 情况下的泛化有帮助。
对于BART模型,我们注意到BART-MTL在Clif-55数据集上比BART-Single提高了2.5%。然而,我们注意到CLIF-26的情况正好相反。鉴于在这些模型中整个BART参数都被优化了,我们假设BART-MTL可能受到了预训练的BART模型本身的知识遗忘的影响;而在适配器和BiHNet模型中,BART模型被冻结了。
因此,在本节的其余部分,我们更关注 侧重于BiHNet方法。
问题2:模型的泛化能力是如何随时间变化的?
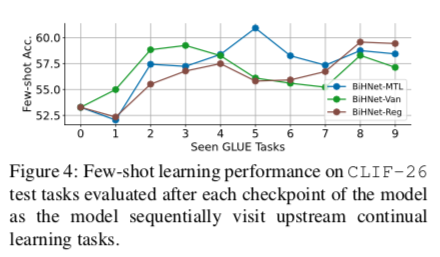
我们专注于BiHNet-Vanilla和BART-Vanilla方法,并回答三个子问题。
知识是否在上游任务中被单调地积累?与两个零知识基线相比,我们注意到BiHNet-Vanilla普遍提高了即时准确率(在CLIF-26上为6.5%,在CLIF-55上为8.9%)和少数次准确率(在CLIF-55上为0.8%),但在CLIF-26上的few-shot准确率除外(-0.4%)。这些结果在一定程度上证实了积极的知识积累。在图4中,我们绘制了模型依次访问每个上游训练任务时在CLIF-26上的few-shot精度。我们注意到BiHNet-Vanilla的几率并没有单调地增加,这意味着这些上游学习任务之间的干扰或对可概括的知识的遗忘。
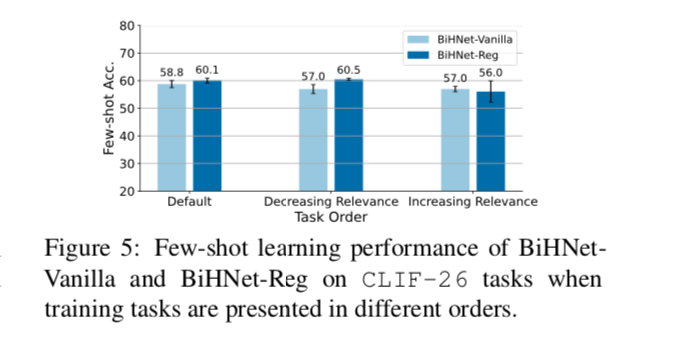
任务的顺序是否重要?图5显示了在CLIF-26上不同任务顺序下的方法性能。我们通过增加和减少与few-shot学习任务的相关性来排列任务,其中相关性被定义为模型从单一上游任务转移时的few-shot准确性。结果显示,在这两个顺序中,BiHNet-Vanilla的竞争力都不如BART- Adapter-Single。这意味着在持续学习中,如果没有CL算法,知识积累就不那么稳健。
问题3:模型的灾难性遗忘是否阻碍了其知识积累?
在表2中,我们看到Vanilla和MTL方法的最终准确率之间存在明显的差异(大约20分),这验证了当训练实例不是i.i.d.时对所见任务性能的灾难性遗忘。然而,我们发现MTL和Vanilla训练之间的差距对于 few-shot 学习性能是接近的,其中BART-Vanilla甚至比BART-MTL更好,这可能是充分遗忘缓解过拟合的一个积极结果(王等人,2020)。这表明灾难性遗忘对泛化能力的影响与它对所见任务表现的影响相比,程度较小。
Effect of Continual Learning Algorithms
有了对前面问题的认识,我们现在分析基线持续学习算法和所提出的方法是否有助于知识积累和提高模型的(few-shot)f泛化能力。
问题1:持续学习算法能缓解灾难性遗忘吗?
从表2中,我们注意到MbPA++、meta-MbPA、EWC在CLIF-26上明显比 BART-Vanilla 或 BiHNetVanilla 提高了最终准确率,这证实了对缓解灾难性遗忘的积极作用。 在CLIF-55上,其特点是训练任务更多,每个任务的样本更少,我们发现基线CL算法未能提高最终的准确性。对于基于记忆的方法,如MbPA++和meta-MbPA,这可能是因为对存储的例子有明显的过度拟合。相比之下,BiHNet-Reg在两个数据集中都很有效。
问题2:缓解灾难性遗忘能更好地保留泛化能力吗?
通过比较BiHNet-Vanilla和BiHNet-Reg的 few-shot 准确性,我们发现在两个数据集上,few-shot 准确性和即时准确性分别提高了1.9%和4.2%。从图5中,我们看到BiHNet-Reg在默认的和递减的相关性顺序中优于BiHNet-Vanilla;而我们观察到BiHNet-Reg在递增的相关性顺序中出现了异常。从图4中,我们看到随着BiHNet-Reg学习更多的上游任务,few-shot的学习精度提高得更加稳定。
问题3:BiHNet-REG比HNet-REG有改进吗?
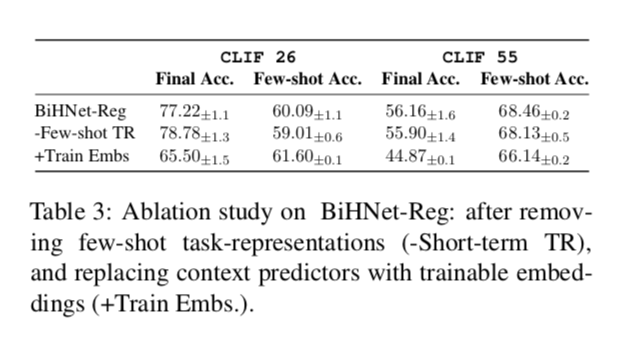
BiHNet-Reg与HNet-Reg(Oswald等人,2020)的主要区别是:(1)few-shot 任务表征;(2)用上下文预测器推断任务表征,而不是将其作为可训练的嵌入学习。作为一项消融研究,我们逐步替换掉BiHNet中的两个组件,如表3所示。我们看到,在两个数据集上,去掉 few-shot 任务表示会导致 few-shot 准确率下降1.08和0.33个点;而用可训练的任务嵌入取代上下文预测器会导致最终准确率明显下降10个点以上。我们注意到,在CLIF-26上,可训练的em-beddings的几率略高1.5分,但在CLIF-55上则低了2.3分,因为它有更多的上游训练任务。
问题4:敏感度分析:模型如何在不同数量的few-shot训练样本下执行。
图6总结了不同方法在CLIF-26上每类不同数量的训练实例下的几率表现。我们观察到BiHNet-Reg总是能达到最好的性能,而且当训练集较小时,改进更为显著。
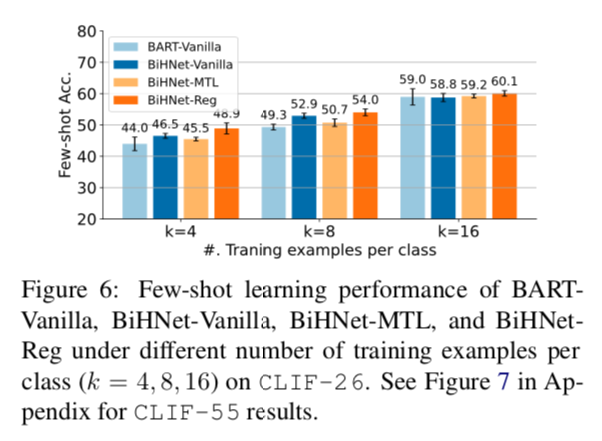
讨论。我们的研究结果表明,与类似的适配器学习框架(BiHNet-Single和BART-Adapter-Single)相比,BiHNet-Reg可以有效地提高知识积累的时间。然而,BiHNet-Reg并不能与BART-Single的几次学习准确性相媲美。我们认为这是由于适配器的模型容量有限,与整个transformer的微调相比。这为改进与PTLM微调兼容的持续学习算法开辟了未来的工作。
Related Work
Continual Learning
CL文献中涉及的主要挑战是克服解决灾难性的遗忘。一般来说,现有的持续学习方法包括基于记忆和生成重放的方法(Robins,1995;Lopez-Paz和Ranzato,2017;Shin等人,2017)、基于正则化的方法(Kirkpatrick等人,2017;Nguyen等人,2018)和基于模型扩展的方法(Shin等人,2017)。最近,持续学习在NLP领域引起了关注(Sun等人,2020;Wang等人,2019b;Huang等人,2021)。
Continual Meta Learning
有文献研究了NLP应用之外的持续元学习,对问题有各种定义。
一些前期工作目的是开发一种算法,当早期任务的少数训练实例在测试时再次可用时,可以快速恢复以前的性能。
Caccia等人(2020)提出了一种设置,即模型访问一连串可能重新出现的任务,并测量在线累积性能作为衡量标准。Antoniou等人(2020)假设模型访问了一连串的 few-shot 照片的分类任务,而测试任务由训练时看到的类组成。Jerfel等人(2019)的问题设置与我们的问题设置最为相关,我们的问题设置可以更好地在新任务上进行 few-shot 照片的学习,但只针对图像分类任务进行研究,任务数量少得多。据我们所知,我们的工作是第一个研究在不同的NLP任务中对大规模转化器模型进行少数次学习的持续知识积累。
Conclusion
我们提出了 “少数学习者的持续学习”(CLIF)挑战,以模拟学习者在一连串的NLP任务中不断积累(可归纳的)知识,同时保持其在所见任务中的表现的情景。我们提出了评估协议来研究现有的持续学习算法的性能,并介绍了我们的方法BiHNet-Reg。我们展示了建立一个NLP系统的潜力,该系统通过持续的训练,可以完成更多的任务,并且在掌握新任务方面变得更有效率。未来的工作包括将我们的工作扩展到数据分布可能不断变化的任务无关的场景,以及研究用新出现的数据不断完善大规模预训练模型的算法。
 wechat
wechat alipay
alipay





