HotpotQA Submission Guide
HotpotQA Submission Guide
记录如何提交模型在HotpotQA test
codalab安装与注册
先去注册 https://worksheets.codalab.org/
首先安装codalab
1 | pip install codalab -U |
如果ERROR: Cannot uninstall ‘PyYAML’. It is a distutils installed project and thus we cannot accurately determine which files belong to it which would lead to only a partial uninstall.
使用 pip install codalab -U —ignore-installed PyYAML
Codalab wiki : https://github.com/codalab/codalab-worksheets/wiki
注册安装完成后可以再命令行登录:
1 | $ cl work |
cl work命令的意思就是切换工作表(worksheet),默认的工作表指向主页工作表 (home-<username>)。
先一个例子提交Hotpot QA的baseline
distractor setting 是需要提交代码的,full wiki不需要。先主要攻克 distractor setting吧
尝试完baseline再上传我自己的模型。
你的分数想要在排行榜上出现,需要预留最多一个月的时间。
在干扰项设置中,要求您将代码提交给Codalab,并根据隐藏的测试集对其进行评估。您应该首先确保您的代码能够正确生成dev的输出和评估结果,以便可以更容易地将您的设置转移到测试集。下面,提供一个提交baseline模型的示例。
Step 1: Preparing code and data
首先将基线模型的GitHub存储库克隆到Codalab包中(在codalab上代码是公开的,想要不公开。。)
在命令行中运行
1 | cl run --request-network 'git clone https://github.com/hotpotqa/hotpot.git' -n repo |
—request-network:需要网络环境, -n是添加别名为repo,以后可以更容易地引用它(而不是每次都使用长UUID)。
注意这里git克隆的要是https的ssh的路径会失败。
成功后刷新网页控制台:

然后,我们上传对训练集进行预处理后生成的词汇映射文件。
创建包含所有必要预处理文件的mappings.zip文件,即idx2char.json、idx2word.json、char2idx.json、word2idx.json、char_emb.json和word_emb.json。这个是baseline运行所需要的。
作者提供了下载mappings.zip的下载地址:http://curtis.ml.cmu.edu/datasets/hotpot/mappings.zip
要上传数据到Codalab CLI,只需运行
1 | cl upload mappings.zip -n mappings |
完全上传后,Codalab会为您解压zip文件。
当然,还需要上传预先训练好的模型文件。我们已经准备好了预先训练好的文件model.pt。
下载地址:http://curtis.ml.cmu.edu/datasets/hotpot/model.pt
1 | cl upload model.pt -n model |
如果超时就重新执行

Step 2: Preparing the environment
现在基本已经准备好对新的输入进行预测。我们只需要设置代码需要在其中运行的适当环境。
要做到这一点,最简单的方法是使用Docker镜像,我们在qipeng/hotpotqa-base上提供了一个镜像,其中预装了nvidia GPU相关库和Anaconda 3。我们还安装了运行此docker映像中的基线模型所需的所有软件包,这样我们就不必在Codalab包中安装所有东西。
如果确实忘记了环境中的某些内容,也可以在Codalab中轻松设置:
1 | cl run -n download_spacy_model --request-docker-image qipeng/hotpotqa-base:gpu --request-network :repo 'cp -r repo/hotpot .; python -m spacy download en' |
注意:由于评估期间禁止使用网络,此捆绑包仅用于演示目的。对于需要下载的软件依赖项,强烈建议下载到您准备的Docker镜像中。

Step 3: Running evaluation
现在,继续根据刚刚上传的模型进行预测,并评估输出。
要在dev集上运行上传的基线模型的预测,我们运行以下命令:
1 | cl run -n predict --request-docker-image qipeng/hotpotqa-base:gpu --request-gpus 1 --request-cpus 4 --request-memory 32g repo:download_spacy_model :mappings input.json:0xbdd8f3 :model 'cp -r repo/hotpot .; cp mappings/* hotpot; mkdir hotpot/model; cp model hotpot/model/model.pt; cp input.json hotpot; cd hotpot; python main.py --mode prepro --data_file input.json --para_limit 2250 --data_split dev; python main.py --mode test --data_split dev --para_limit 2250 --batch_size 24 --init_lr 0.1 --keep_prob 1.0 --sp_lambda 1.0 --save model --prediction_file pred.json; cp pred.json ../;' |
让我们看看上面的命令中发生了什么。在第一部分中,我们使用-n predic命名包,并使用指定所需的资源
—request-docker-image qipeng/hotpotqa-base:gpu
—request-gpus 1
—request-cpus 4
—request-memory 32g
请注意,您不能在此捆绑包中使用—request-network
然后指定对其他包的依赖关系。repo:download_spacy_model表示将包download_spacy_model别名为repo
:mappings指定对捆绑包mapping的依赖关系,而不使用别名。
input.json:hotpotqa-data//dev_distractor_input_v1.0将输入json文件重命名为input.json,其中包id指向dev json文件。0xbdd8f3
请不要上传您自己版本的开发集文件并使用它,因为我们依赖官方的开发文件UUID来确定在评估期间用测试集替换什么(如果您使用自己的开发集文件,评估将失败)。
然后,使用一系列cp命令从不同的包复制文件,并以我们的预测脚本可以处理的方式组织它们。
请注意,可以将每个引用的捆绑包视为当前捆绑包中的一个目录。例如,通过cp -r repo/hotpot。我们将repo捆绑包中的hotot子目录复制到当前捆绑包的“根”目录(开始运行捆绑包中的代码时所在的目录,而不是/root!)。
然后,我们调用main.py两次,第一次使用—mode prepro预处理dev集,第二次使用—mode test进行预测。如果您使用代码,则可以相应地更改此设置。
请注意,如果您的代码涉及预训练的特征提取(例如,Elmo或BERT),则应该将其合并为此处命令的一部分,而不是作为包上传,因为您事先没有访问测试集的权限。(也就是说要预处理测试集的话要在一个捆绑包里进行多次运行python文件吧)
还要注意,您的模型不应该依赖于键类型和级别来进行预测,因为这些键没有出现在测试集中。
之后,我们将文件pred.json复制到当前包的“根”目录。请注意,文件名必须命名为pred.json,并且该文件必须放在包的“根”目录下,评估命令才能正常工作。

使用以下命令(将predict替换为您自己的prediction bundle的名称),确保您能够在dev set上评估您的模型而不会遇到任何问题:
1 | cl macro hotpotqa-utils//dev-eval-distractor-v1.0 predict -n evaluate |


Step 4: Describe and tag your submission 描述并标记您的提交
准备好后,编辑预测捆绑包的说明,以反映在排行榜上显示所需的信息:
1 | Model name (Affiliation) (single model / ensemble) [paper name](paper link) (code link) |
如果您在使用深渊翻滚时愿意,可以使用匿名Anonymous作为您的从属关系,之后可以通过编辑您的深渊翻滚捆绑包的描述来修改它。
[paper名称] 和(代码链接)部分是可选的
请注意,虽然[paper名称]和(paper链接)之间没有空格,因为这会造成代码链接的歧义。以下是一些示例
1 | Baseline Model (Carnegie Mellon University, Stanford University, & Universite de Montreal) (single model) [(Yang, Qi, Zhang, et al. 2018)](https://arxiv.org/pdf/1809.09600.pdf) (https://github.com/hotpotqa/hotpot) |
第一个示例正是我们用来描述基线模型的。第二个没有代码链接,第三个没有指定论文名称。
请注意,Codalab在捆绑描述中使用非ASCII字符有问题,因此请避免使用它们。
要提交您的捆绑包,请使用hotpotqa-diditor-test-submit标记您的预测捆绑包(这可以在Web UI上通过选择捆绑包并修改右侧面板上的标签来完成),然后向彭琪(pengqi@cs.stanford.edu)发送一封简短的电子邮件,其中包含您的捆绑包UUID(0x后跟32个字符)或指向您的捆绑包的链接(不是您的工作表或工作表UUID!)。
请确保您的预测所依赖的所有捆绑包都是公开可读的(这是Codalab中的默认可见性)。
重要信息:
1.请仅在dev集合上执行改善模型性能所需的任何模型选择或消融。不能在测试集上支持同一模型的多个提交。
2.请避免删除您的Submission捆绑包,即使在填写排行榜条目之后也是如此。这是您更新与您的Submission相关的信息的最佳方式,包括但不限于其名称、隶属关系、纸质链接、代码链接等。
3.如果你提交了多份报告(单一模型和集成模型),请确保你的预测捆绑包有不同的名称。例如,predict-single和
predict-ensemble。这是唯一一种我们在30天内容纳的多次提交。
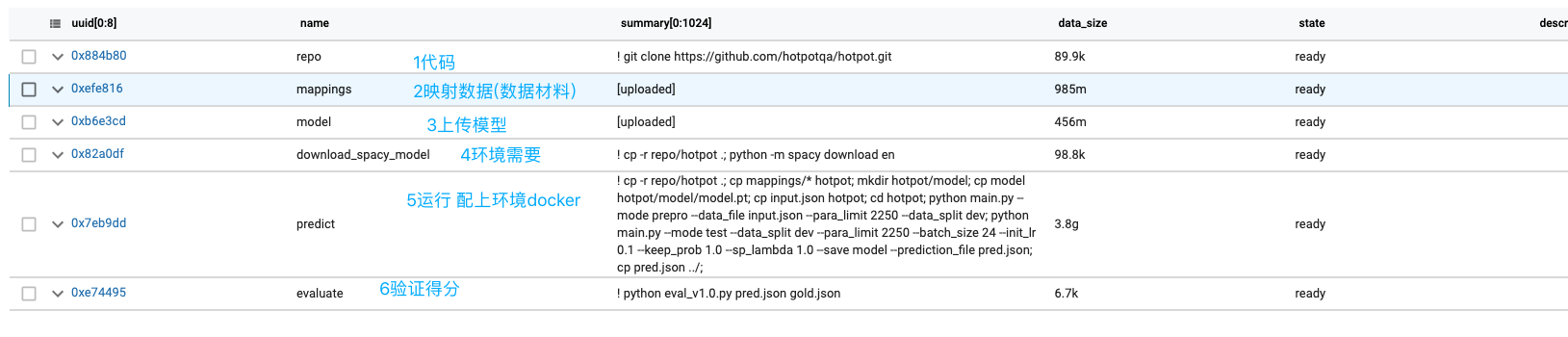
1总结
- 从github下载代码
- 上传模型和需要的数据
- 设置环境用docker
- run
 wechat
wechat alipay
alipay





