FREELB: ENHANCED ADVERSARIAL TRAINING FOR NATURAL LANGUAGE UNDERSTANDING
FreeLB: Enhanced Adversarial Training For Natural Language Understanding
承接上文,上文主要讲对抗训练的原理与物理意义与发展,对抗性训练是创建健壮神经网络的一种方法。在对抗性训练期间,小批次的训练样本受到对抗性扰动的污染,然后用于更新网络参数,直到得到的模型学会抵抗此类攻击,并且对模型起到了正则化的效果,提高模型泛化能力并且防止过拟合。
这篇论文结合现在流行的预训练模型或transformer模型只能结合到下游任务的embedding中。
提出FreeLB算法在GLUE上结合Roberta达到了当时的SOTA,是基于Transformer的自然语言理解和常识推理任务模型来做对抗。
摘要
对抗性训练可以最小化标签保留输入扰动的最大风险,已被证明对提高语言模型的泛化能力是有效的。
FreeLB (Free Large-Batch),通过在单词嵌入中添加对抗性扰动,并最小化输入样本周围不同区域内的对抗性风险,从而提高了嵌入空间的不变性。
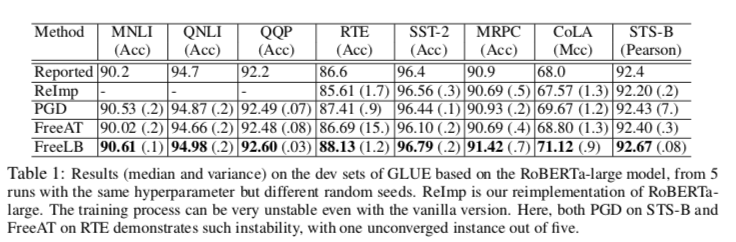
在GLUE基准上的实验表明,当仅应用于精调阶段时,它能够将BERT-BASE模型的整体测试分数从78.3提高到79.4,将Roberta-Large模型的测试分数从88.5提高到88.8。
创新点
针对PGD算法的问题:当K较小时,基于PGD的对抗性训练仍然会导致高度卷积和非线性的损失面,在更强的对手下很容易被打破,当K大时计算开销又很大。
利用最近提出的“Free”训练策略在不同范数约束下用多样化的对抗样本来丰富训练数据,
“Free”的对抗性训练算法在一次反向传递中同时更新模型参数和对抗性扰动。
还使用将大部分对抗性更新限制在第一层,有效减少的对抗过程正反向传播总量。
比PGD计算成本小,能在大规模的预训练模型上进行对抗训练。
文本的对抗样本(对手)
- 黑盒环境下对embedding进行扰动(对手不是从样本进行攻击)
- 在输入中添加分散注意力的句子(人工)
- 用GANs将输入投影到潜在空间,并搜索接近原始的文本对手

第二三算是一种辅助模型,数据增强的一种形式。
如何在没有人工评估的情况下通过单词/字符替换来构建保留标签的对抗性示例仍然不清楚,因为每个单词/字符的含义取决于上下文。
所以主要还是采用第一种进行对抗训练。
因为词的输入表达有很多种,像词embedding、句子embedding和位置embedding。作者和其他对抗训练一样只干扰词embedding和拼接词的embedding。
注意,基于Embedding的对手严格来说比更传统的基于文本的对手更强大,因为对手可以在单词嵌入上进行在文本域中不可能进行的操作。因为CV都是从样本层面进行扰动,这个扰动从embedding上扰动,相当于在更高级的层面,所以更强大。
FreeLB
此前预训练语言模型对于下游任务已被证实很有效。
作者的目标是通过在下游语言理解任务的精调过程中增强它们在嵌入空间中的鲁棒性,进一步提高这些预先训练的语言模型在下游语言理解任务上的泛化能力。
由于这篇论文只对对抗性训练的效果感兴趣,而不是产生实际的对抗性示例,因此使用基于梯度的方法在输入句子的嵌入中添加范数有界的对抗性扰动。
定义模型的输入One-hot向量为 $ Z=[z_1,z_2,…,z_n]$
嵌入矩阵为V
语言模型看成是一个 $y=f_{\theta}(X), X=VZ$ , y是模型输出 $\theta$是可学习参数。
定义对抗扰动为 $\delta$
新的预测输出变为 $y’=f_{\theta}(X+\delta)$
为了保持语义,我们将δ的范数限制为较小,并假设模型的预测在扰动后不会改变。
上面的定义和其他人的研究基本都是相同的,FreeLB区别在于不要求X归一化。
FreeLB吸取了FreeAT和YOPO加速方法, 几乎不需要任何开销就可以获得参数的梯度。实现了与标准PGD训练模型相当的健壮性和泛化能力,只使用与自然训练相同或略多的正反向传播。
FreeAT (Free Adversarial Training): NIPS2019
从FGSM到PGD,主要是优化对抗扰动的计算,虽然取得了更好的效果,但计算量也一步步增加。对于每个样本,FGSM和FGM都只用计算两次,一次是计算x的前后向,一次是计算x+r的前后向。而PGD则计算了K+1次,消耗了更多的计算资源。因此FreeAT被提了出来,在PGD的基础上进行训练速度的优化。
FreeAT的思想是在对每个样本x连续重复m次训练,计算r时复用上一步的梯度,为了保证速度,整体epoch会除以m。r的更新公式为:
伪代码:
1 | 初始化r=0 |
缺点:FreeLB指出,FreeAT的问题在于每次的r对于当前的参数都是次优的(无法最大化loss),因为当前r是由r(t-1)和theta(t-1)计算出来的,是对于theta(t-1)的最优。
代码:https://github.com/mahyarnajibi…
YOPO (You Only Propagate Once): NIPS2019
代码:https://github.com/a1600012888/YOPO-You-Only-Propagate-Once
可以参考加速对抗训练——YOPO算法浅析
极大值原理PMP(Pontryagin’s maximum principle)是optimizer的一种,它将神经网络看作动力学系统。这个方法的优点是在优化网络参数时,层之间是解藕的。通过这个思想,我们可以想到,既然扰动是加在embedding层的,为什么每次还要计算完整的前后向传播呢?
基于这个想法,作者想复用后几层的梯度,假设p为定值:
则对r的更新就可以变为
我们可以先写出YOPO的梯度下降版本:
1 | 对于每个样本x |
作者又提出了PMP版本的YOPO,并证明SGD的YOPO是PMP版的一种特殊形式。这样每次迭代r就只用到embedding的梯度就可以了。
YOPO还主张在每次反向传播后,应将第一隐层的梯度作为常数,利用该常数与网络第一层的雅可比的乘积对对手进行多次额外更新,以获得强对手。
回到FreeLB
与FreeAT不同的是,YOPO从每个上升步长开始累加参数的梯度,并且只在K个内上升步长之后更新一次参数。
对比 PGD:
FreeLB和PGD主要有两点区别:
- PGD是迭代K次r后取最后一次扰动的梯度更新参数,FreeLB是取K次迭代中的平均梯度
- PGD的扰动范围都在epsilon内,因为伪代码第3步将梯度归0了,每次投影都会回到以第1步x为圆心,半径是epsilon的圆内,而FreeLB每次的x都会迭代,所以r的范围更加灵活,更可能接近局部最优:
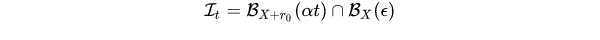
它执行多次PGD迭代来构造对抗性实例,并在每次迭代中同时累积“free”参数梯度∇θL。
伪代码:
1 | 对于每个x: |
论文中还指出了很重要的一点,就是对抗训练和dropout不能同时使用,加上dropout相当于改变了网络结构,会影响r的计算。如果要用的话需要在K步中都使用同一个mask。
参考文献
 wechat
wechat alipay
alipay





