ZeroPrompt- Scaling Prompt-Based Pretraining to 1,000 Tasks Improves Zero-Shot Generalization
ZeroPrompt: Scaling Prompt-Based Pretraining to 1,000 Tasks Improves Zero-Shot Generalization
任务数量极大的情况下,模型大小对性能的影响很小…
XLNet作者杨植麟团队发布了首个中文多任务Prompt统一模型:ZeroPrompt。研究的重点是 【任务的规模】 和 【zero-shot】 的 prompting。
以前的模型只在几十个任务上进行训练,ZeroPrompt 使用真实世界的数据将其扩展到1000个任务(中文数据)。这导致了一个重要的发现,即任务规模可以成为模型尺寸的有效替代方案; 即,模型尺寸对大量任务的性能影响很小。
此外,该文还提出了一种结合了遗传算法来自动搜索 unseen 任务的最佳 prompt。
Introduction
众所周知,prompt 可以激发语言模型的潜力,避免预训练和Fine tuning 之间的gap,并且是一个非常 Parameter-Efficient 的调整方法。不仅如此,Prompt 还可以对不同的NLP任务进行范式统一,统一为相同的数据形式。同时,受益于预训练语言模型的强大,就对多任务、多领域进行统一建模。
最初,GPT-3 证明了通过在更大规模模型上使用 prompt 来实现零样本和少样本学习的可能性。 然而,与全监督微调相比,zero-shot 和 few-shot 泛化的性能在许多任务上仍然不足。
之前 FLAN 与 T0 分别探索了模型大小与 prompt数量对多任务预训练的性能和效率,但目前还不清楚扩展训练任务的数量的影响如何。
如图 1 所示,实证研究表明,任务扩展可以成为模型尺寸的有效替代方案:
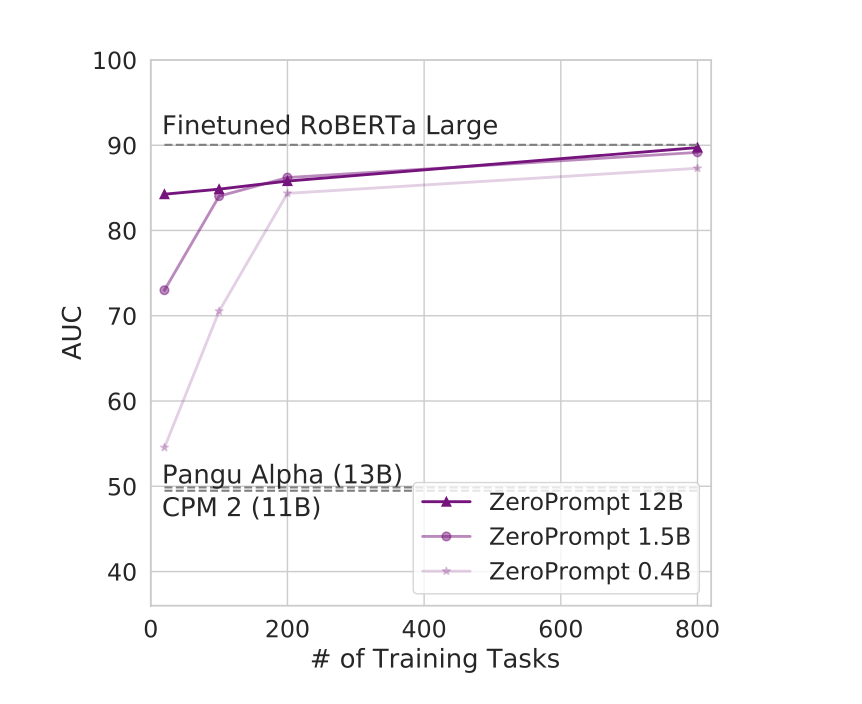
由于训练任务非常多,模型大小对性能的影响很小。 此外,任务规模可以提高各种模型规模的性能。 对于参考基线,RoBERTa-Large 以完全监督的方式进行微调,而 Pangu Alpha 和 CPM-2 是 zero-shot prompted。 所有模型都用中文训练和评估。
除此之外,ZeroPrompt 还探索了,在多任务训练时:
- 如何对不同任务类型更好地统一建模,Prompt如何设计?
- 应该选择哪些任务数据进行多任务训练呢?
- 对unseen domain的新任务如何获得高性能,如何自动构建Prompt?
ZeroPrompt
Zero-shot Adaptation with Few-shot Validation
为了验证Prompt的效果,需要标注一些样本做验证集,论文将这一设置称为,“Zero-shot Adaptation with Few-shot Validation”,设置总结在下图:

Datasets for scaling to 1,000+ tasks
数据来源主要是学术界公开的数据集和工业生产数据,包括情感分析、新闻分类、推断、NER、MRC、摘要等多个任务。其中,公开数据集共80个。下图列出了每种任务类型中的任务数量:
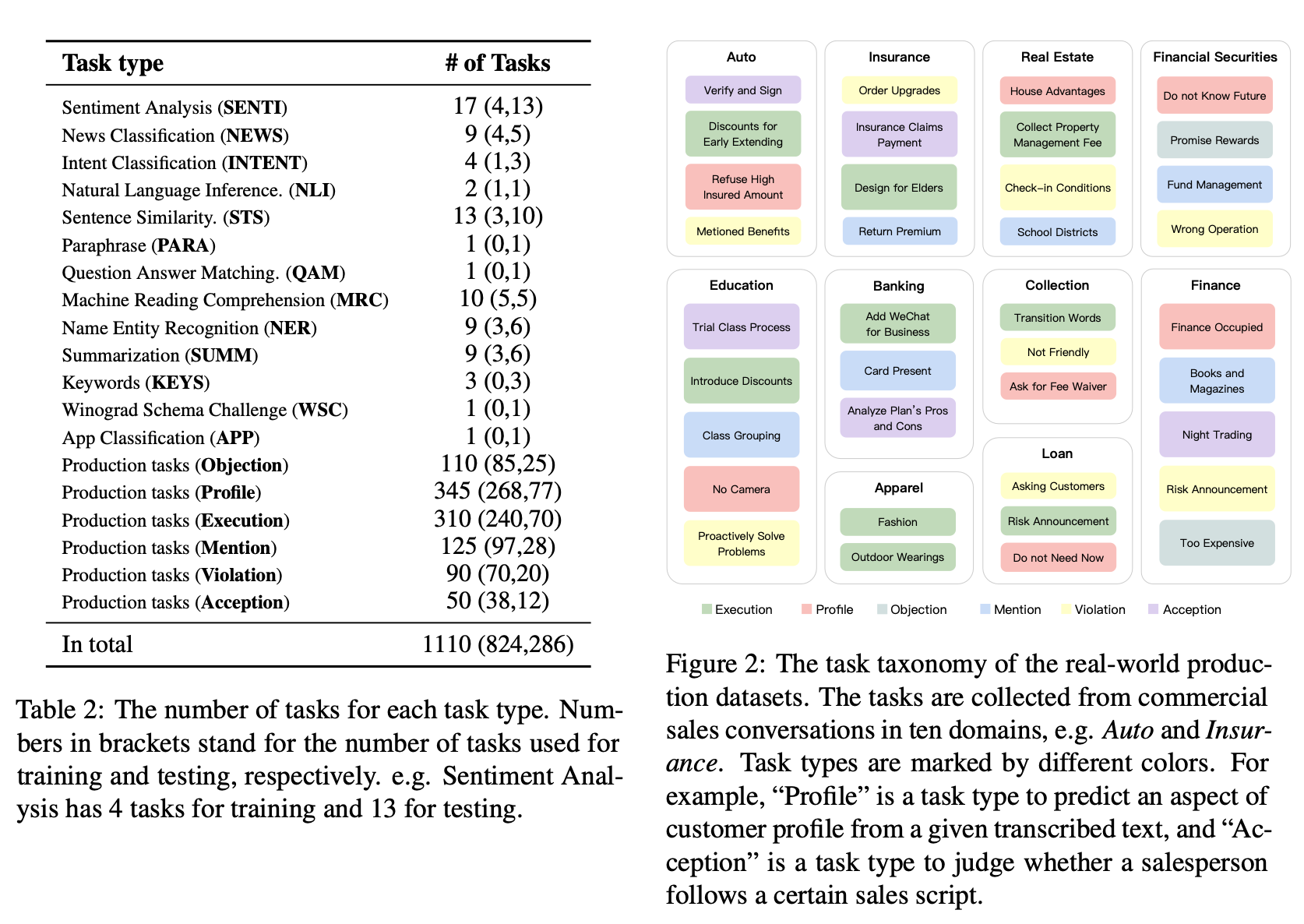
一共的1110个任务数据上,有824个用作多任务预训练,剩余的286个数据是进行zero-shot测试的unseen任务。
ZeroPrompt 的pipeline
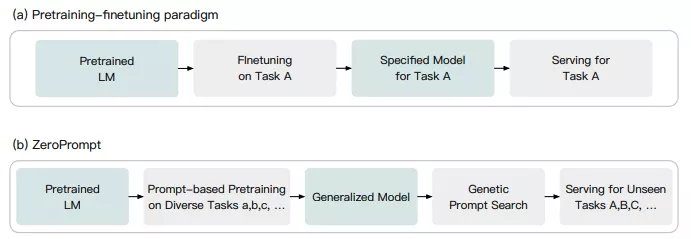
与传统的预训练-微调范式相比, ZeroPrompt 引入了两个关键差异:
- 为所有下游任务提供通用模型,而不是为每个特定下游任务提供多个不同的微调模型。
- 其次,使用 Genetic Prompt Search (GPS)在我们的“Zero-shot Adaptation with Few-shot Validation”设置中自动生成高性能prompt。 此外,我们的 ZeroPrompt 使用混合 prompt 形式,包括 soft prompt 和 hard prompt。
Genetic Prompt Search
目标在不更新模型参数的情况下自动获得高性能prompts,提出了 GPS 以进一步提高 ZeroPrompt 的 zero-shot性能。
遵循更现实的零样本学习设置,采样少量数据作为下游任务的开发集 $D_{dev}$——“Zero-shot Adaptation with Few-shot Validation”。
GPS 的过程在算法1中进-行了描述,其中 $f{GPS}$是决定保留或消除哪个 prompt 的度量函数,$g{GPS}$表示生成新 prompt 的遗传函数。 对于下游任务,算法首先使用一组手工 prompt $G_0$ 进行初始化。
在实践中,通过 3 次初始化来实现良好的性能。 对于每次迭代,使用 $f{GPS}$ 计算 $G^t$ 中 prompt 的分数,并选择前 K 个提示作为 $G^t$。 然后我们使用基于 $G^t_$ 的 $g_{GPS}$ 生成 $G^{t+1}$。最后,我们从整个生成的 prompt 集中选择前 K 个 prompts。

Prompt Design
尽管带有 prompt 的大规模预训练模型,例如 GPT-3 在没有任何标记数据的情况下对看不见的任务进行零样本泛化,显示出可喜的结果,快速设计对其性能至关重要。在本小节中,描述了我们选择的 prompt 设计和其他一些经过测试的变体。
在 prompt 模板 $T$ 的最简单形式中,提示方法通过手工提示 $P$ 和文本输入序列 $X$ 构造 $T$:
其中 $[MASK]$ 是应填写答案以完成句子的空白。 这被称为句子填充。
如图 4 所示,优化后的prompt $P$ 进一步分解为 $\Epsilon$、$V$ 和 $D$ 三个部分,其中有任务特定的 soft prompt $E$、verbalizer prompt $V$ 和任务描述prompt $D$。结果, 我们的提示模板 $T$ 可以表示为:

与 PET 类似,使用生成任务的 prompt 和用于分类任务的 prompt-verbalizer对 (PVPs)。
对于每种任务类型,我们首先设计一个基本 prompts 集合,然后通过添加特定任务的关键字或表达式来修改基本 prompts,以获得最终的任务描述 prompt。 强制每个任务类型中的任务具有相同或相似的 verbalizer 以保持一致性。
Prompts with Verbalizer Candidates
对于 unseen 的任务的零样本学习,在这种情况下微调不是一种选择,从大量候选词汇中找到表现最好的verbalizer v ∈ V 是一个难题。为了解决这个问题,我们将所有可能的 verbalizer 候选者 $V = {v_1 , v_2 , …}$ 连接起来,并将候选者放在任务描述提示之前,如图 4 所示。
Disentangled Task Representations
如上所述,我们强制执行直观相似的任务以具有相似的 prompts 或 PVPs,以便与任务无关的知识已经以这种方式正确建模。 同时,特定于任务的知识也应该有助于零样本泛化。
为了在多任务预训练中 解耦 特定于任务和与任务无关的知识,安装了一个连续 prompt 嵌入作为前缀,这被称为图 4 中所示的特定于任务的 soft prompt。
对于 unseen 的任务,需要冷启动 并在没有标记数据的情况下从头开始初始化 prompt 嵌入。 一种直觉是直接使用来自具有相似数据分布的训练任务的soft prompt。
Experiments
Experiment Setups
Baseline Models
- Pangu-α : 具有多达 2000 亿个参数的预训练解码器模型。 在计算资源有限的情况下,以 130 亿版本的 Pangu-α 作为基准。
- CPM-2 : 具有 110 亿个参数的预训练编码器-解码器模型。 以中文版的 CPM-2 为基准。
- RoBERTa : 与强基线、微调的 RoBERTa-large 模型进行比较。
Main Results
Results of Task Scaling
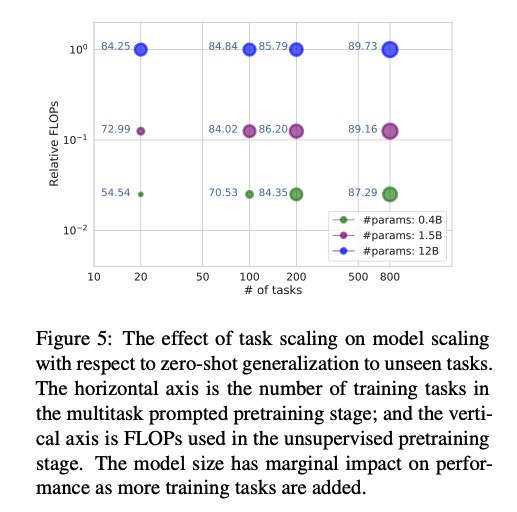
有上图可以看出:随着任务数量从20升至800个,不同参数大小模型间的差距变得很小,FLOPs提升30倍。
Results Compared with Other Approaches
在unseen的测试数据集上将 ZeroPrompt 与其他强大的零样本和完全监督的方法进行比较。 由于篇幅有限,表 3 中仅包含部分保留的测试任务( 17 个学术数据集和 10 个生产数据集以进行比较)。
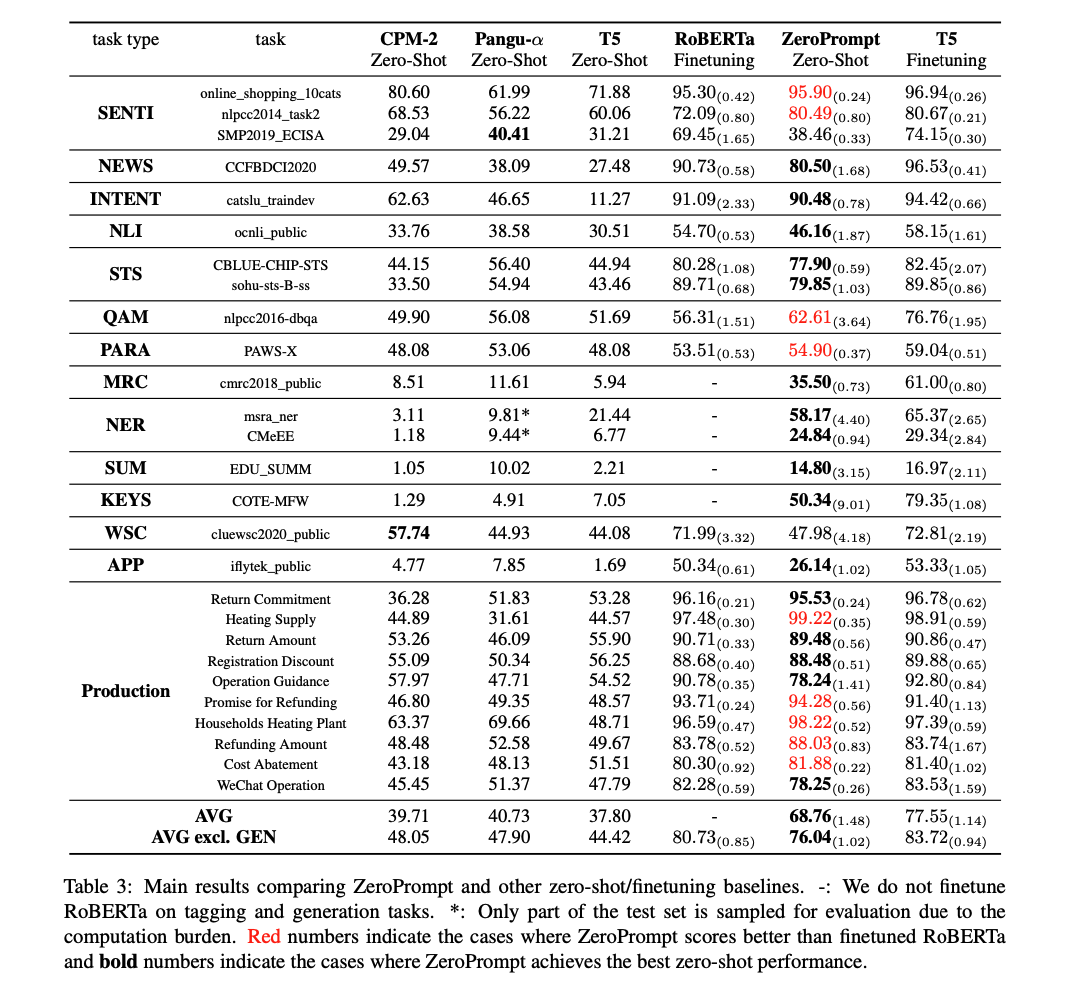
主要结论是:
- ZeroPrompt显著提升T5的zero-shot性能,从37.8提升到68.76,一共提升近31个点;
- ZeroPrompt显著提升CPM2和盘古的zero-shot性能,提升近28个点;
- ZeroPrompt的zero-shot性能与RoBERTa-large有监督finetune可比或更好(如上图红色标识);
- ZeroPrompt与finetuned的RoBERTa-large相比,整体只差4.7个点,而ZeroPrompt没有使用任何标记数据进行微调。原论文表示:这是“令人欣喜”的结果。
Ablation Studies
Effect of Prompt Design
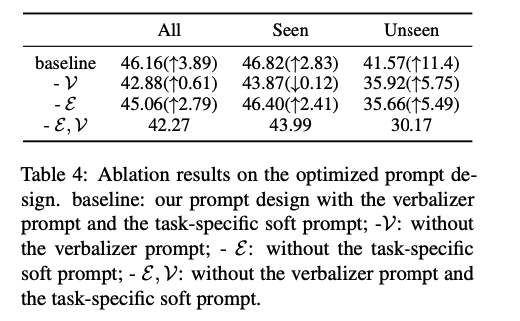
【特定任务的soft prompt】 和 【候选标签verbalizer prompt】对最终结果有正向收益。
Effect of Genetic Prompt Search
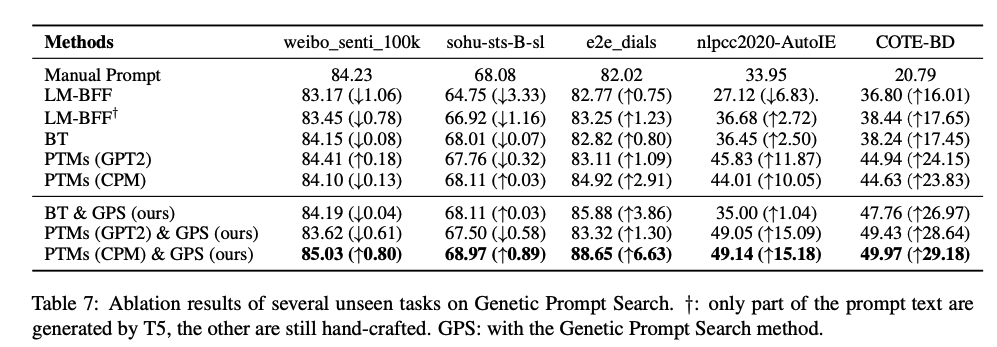
【Prompt遗传搜索算法】好于之前的LM-BFF、翻译等方式。
Effect of Cross Task Type Transfer
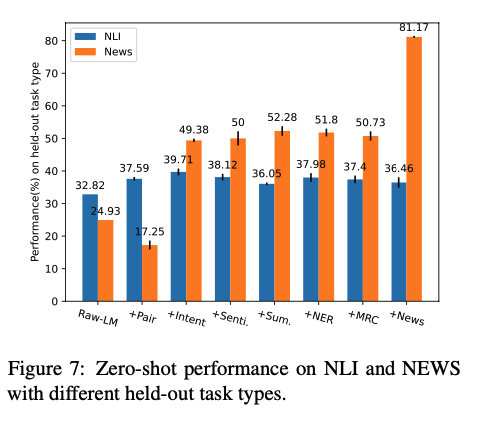
在跨任务类型的zero-shot性能测试上,只能从某些任务类型中受益,而利用其他任务的更多标记数据并没有持续提升。
Limitations and Future Work
虽然可以将任务缩放视为模型缩放的替代方案,它提高了零样本学习的效率和性能。然而,仍一些局限性,未来通过研究这些问题可能会进一步提高零样本性能。
- 跨任务迁移的zero-shot性能,并不总是随着任务规模的增加而持续提升
- 在多任务训练中,如何选择更好的训练任务分布。
- 如何收集更多多样的任务数据,而当前的任务数据规模仍然是受限的。
 wechat
wechat alipay
alipay





