Prompt-Guided Few-Shot Event Detection
Prompt-Guided Few-Shot Event Detection
长期以来,事件提取系统对大量人工注释的需求阻碍了其实际应用。
为了扩展到新的领域和事件类型,模型必须学会应对有限的监督,就像在few-shot环境中一样。
为此,主要的挑战是让模型掌握事件类型的语义,而不需要大量的事件注释。
在本文研究中,使用完形填空提示从预先训练的语言模型中引出与事件相关的知识,并进一步使用事件定义和关键词来确定触发词。
通过将事件检测任务描述为一个【先识别后定位】的过程,我们将类型特定参数的数量最小化,使我们的模型能够快速适应新类型的事件检测任务。
在三个事件检测基准数据集(ACE、FewEvent、MAVEN)上的实验表明,当每种事件类型仅提供5个示例时,我们提出的方法在完全监督设置下表现良好,并且在FewEvent数据集和MAVEN数据集上分别比现有的few-shot方法高出16%和23%。
Introduction
理解事件是信息提取的核心,而事件检测是这一过程中不可避免的一步。事件检测的任务是定位事件触发器(即指示事件的最小词汇单位),并将触发器分类为给定的事件类型之一。尽管在充分监督下,事件检测取得了稳步进展(Wadden等人,2019年;Lin等人,2020年;Lu等人,2021年),但如果没有大规模的注释,很难在新领域和新事件类型上复制这些成功案例。在这里,为了应对新出现的用户需求和有限的注释,我们将研究重点放在few-shot学习环境上。
最近,基于提示的学习在一系列分类和生成任务的few-shot学习中取得了巨大成功。与典型的有监督学习范式相比,基于提示的模型不仅由标注的示例形成,还可以由提示引导。直观地说,在图1中,提示“句子描述[MASK]事件”使masked语言模型预测类似于上下文中提到的事件类型。受这种方法的启发,我们为事件检测定制了基于完形填空的即时学习范式。
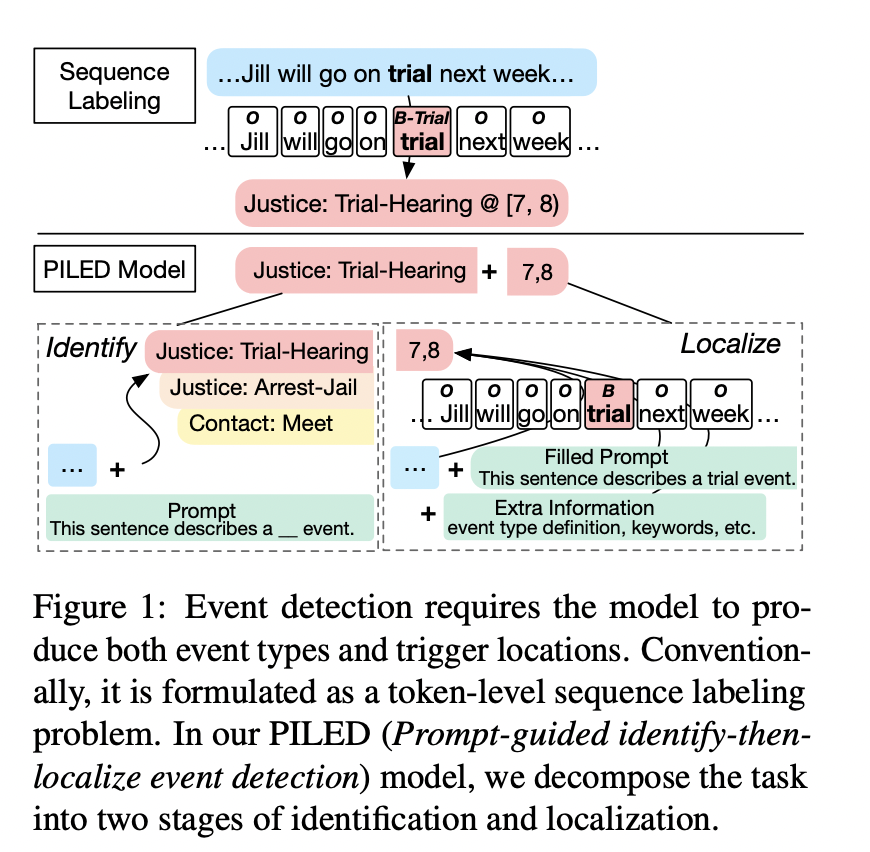
由于事件检测旨在识别事件类型和触发位置,因此基于完形填空的即时学习范式(Schick和Schuĕtze 2021a)并不直接适用。在我们的研究中,我们提出了一种先识别后定位的方法,它将类型语义从序列标记中分离出来,并为提示学习打开了大门。具体来说,我们首先通过一个基于提示的多标签模型来识别事件类型(识别阶段),并根据语义类型描述进行触发提取(定位阶段)。
我们的识别模型将基于完形填空的提示学习(Schick和Schuĕtze,2021a)扩展到事件检测。
提示学习的一个关键组成部分是verbalizer:从类标签到语言模型词汇表中的标记的映射。
由于一个句子可以包含多个事件,我们将模型扩展到多标签分类设置,方法是指定一个特殊token作为NULL类的verbalizer,并将其与所有有效事件类型的预测进行比较(如图2所示)。在这种设计中,NULL verbalizer有效地充当了多类分类的动态阈值(Zhou等人,2021)。
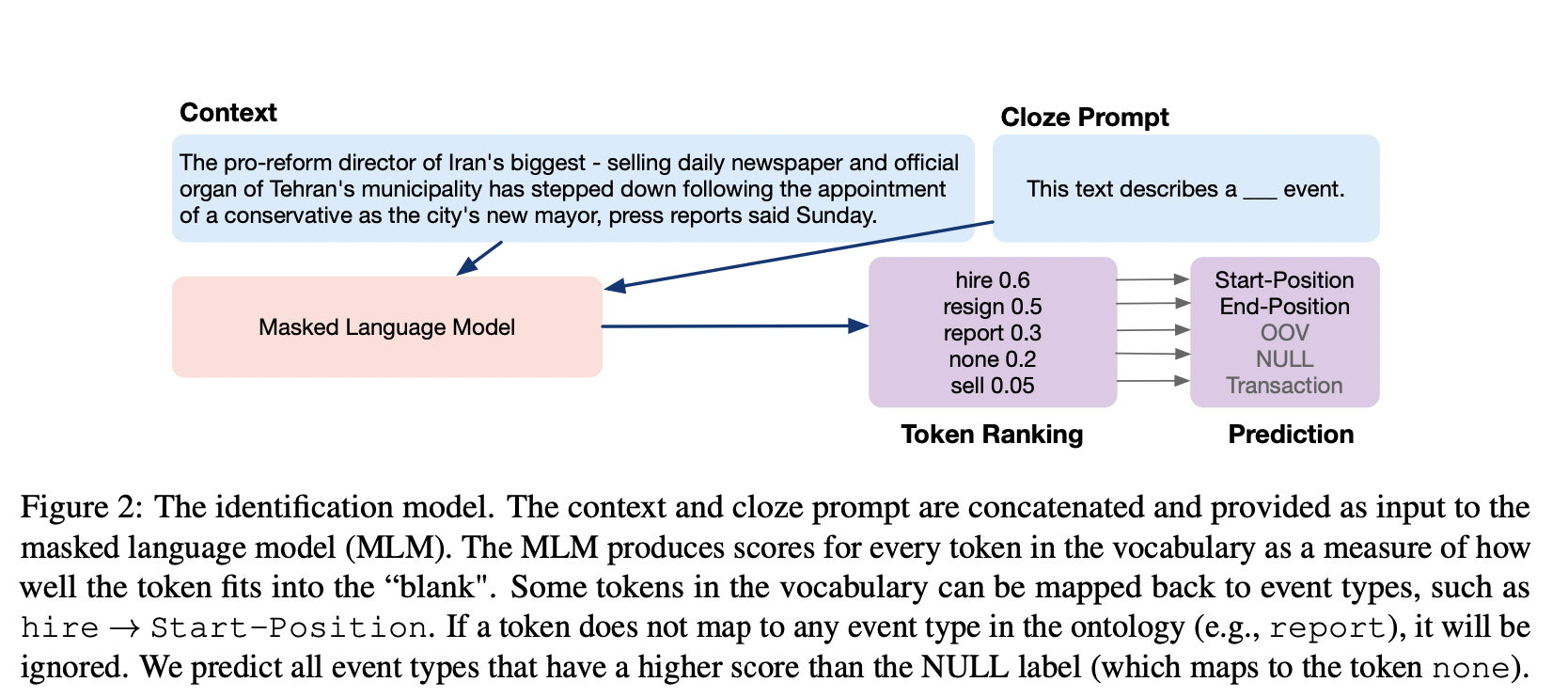
MLM为词汇表中的每个token产生分数,以衡量该标记在 “空白 “中的适合程度。词汇表中的一些token可以映射回事件类型,如雇佣→开始-位置。如果一个token没有映射到本体中的任何事件类型(例如,报告),它将被忽略。我们预测所有比NULL标签(映射到token none)得分高的事件类型。
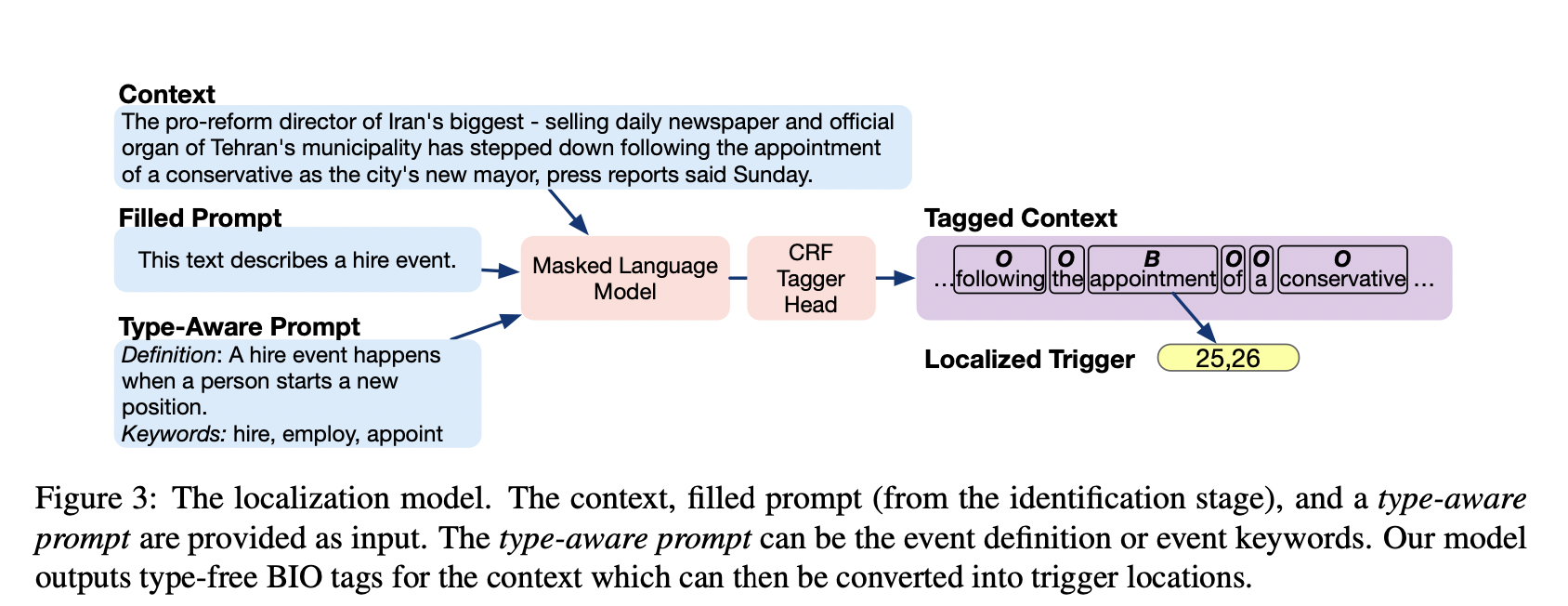
本地化模型是一个单类序列标记器,它将一个已识别的事件类型作为输入,旨在识别相应的触发器(如图3所示)。由于我们将搜索范围缩小到一种事件类型,因此我们使用填充的提示、事件描述和关键字来增加输入。通过这种方式,我们通过在输入端包含事件标签信息,将模型与事件标签分离。这使得我们的定位模型类型免费,因此受益于所有事件类型的培训示例。
我们在一系列数据集(ACE 2005、FewEvent(邓等人,2020年)、MAVEN(王等人,2020年))上,在完全监督和few-shot事件检测设置下测试了我们的模型。
我们的实验表明,我们的模型在完全监督设置下达到了最先进的性能,并且在few-shot设置下显著优于现有的基线。我们的主要贡献包括:
- 我们引入了一种新的 “识别-后-定位 “的事件检测方法。通过将类型语义与序列标签任务解耦,我们将基于cloze的提示学习的好处带到事件检测中,并允许灵活地注入事件知识。
- 我们将基于cloze的提示学习范式扩展到多标签的事件类型分类。这使我们能够利用预先训练好的LM的语言建模能力来完成事件识别任务,并迅速适应新的事件类型。这种方法可以应用于其他多标签分类任务。
- 我们设计了一个注意力增强的单类CRF标记器,用于事件触发的定位。这种关注机制允许对相邻的标记进行预测的互动。
- 我们的模型在少数事件和完全监督设置下的事件检测任务中都取得了出色的表现。特别是在FewEvent(Deng等人,2020年)上,我们对少数事件的检测超过了下一个最佳基线16%的F1。在MAVEN上,我们在识别阶段取得了8%的F1收益,并首次提出了少数事件检测的结果。
Methodology
给定一组上下文 $C$ 和一个预定义的事件本体 $T$(一组目标事件类型),事件检测的目的是找到集合中属于给定本体的所有事件提及。事件提及的特点是触发范围 $s$(开始索引、结束索引)和事件类型 $t\in T$ 在这里,我们遵循以前的工作,并考虑每个句子作为事件的背景。
我们将事件检测任务分为两个阶段:识别和定位。
- 在识别阶段,对于每个上下文 $c$,我们找到一组已经提到的事件类型 $T$。
- 在定位阶段,我们将一对上下文和事件类型 $(c,t)$ 作为输入,并找到一组与该事件类型的触发器相对应的跨度$S$。
请注意,这两个阶段都可以为每个输入生成数量可变的输出。
Event Type Identification
事件类型识别模型遵循了使用完形填空风格提示进行少数镜头学习的想法,并使用了MLM(Schick和Schủtze,2021a)。
完形填空式提示学习使用 prompt 和 verbalizer 功能将分类问题转化为掩码语言建模。
prompt P是一个带有 $[MASK]$ token 的自然语言句子。这个 prompt 可以被视为完形填空问题,而答案与所需的类标签有关。图2显示了一个可用于事件检测的完形填空提示:“本文描述了一个[MASK]事件”。
类标签 $L$ 和 $[MASK]$ 的预测 token $V$之间的关系由 verbalizer 函数 $f_v$定义 : $L\to V$。
例如,我们选择 verbalizer 函数将事件类型开始位置映射到 token hire。我们还将“hire”称为“Start-Position”的verbalizer。
在预测过程中,我们使用MLM $M$ 分配给标签 $l$ 的verbalizer $f_v(l)$ 的logit作为预测 $l$ 的代理。
在分类任务中,标签 $l$ 的概率可以按照公式1计算,
对于事件检测,由于每个句子都可能提到多个事件类型,我们将这种方法扩展到处理多标签分类。通过MLM,我们为词汇表中的所有 token 打分。
排除没有映射回任何感兴趣的事件类型(例如示例中的 report 报告)的令牌后,我们获得了所有事件类型的排名。关键在于找到将这些分数转化为输出的临界值。
我们将token $v_{NULL}$ 分配给 NULL type,并将其用作自适应阈值。在推理阶段,我们预测得分高于 NULL 类型的所有事件类型为正。
在我们的例子中,由于 hire 和 resign 都比 NULL 的描述词none得分更高,所以我们预测开始位置和结束位置作为上下文中的事件类型。
在训练期间,对于每个句子,我们分别计算与 NULL 类型相关的正事件类型和负事件类型的损失:
其中 $T$ 是句子的积极事件类型集。
等式2有效地将每种积极事件类型的得分推到了零事件类型之上,等式3降低了所有消极事件类型的得分。
对于某些事件类型,如 “Business:Lay off”,自然语言标签 “lay off “不能被映射为单一的 token。在这种情况下,我们添加一个新的标记⟨lay_off⟩,并将其嵌入初始化为构成原始事件名称的标记的平均值。
 wechat
wechat alipay
alipay





