PADA: A Prompt-based Autoregressive Approach for Adaptation to Unseen Domains
PADA: A Prompt-based Autoregressive Approach for Adaptation to Unseen Domains
PADA: A Prompt-based Autoregressive Domain Adaptation algorithm, based on the T5 model
作者提出解决的是这个领域适应问题,即一个算法在几个源域上进行训练,然后应用于在训练时未知的未见过的领域的样本(更准确的说这其实是领域泛化问题)。
在训练时,没有任何样本,不管是有标签的还是无标签的,或者关于目标领域的任何其他知识。
给定一个测试样本,PADA首先生成一个独特的 prompt,然后以这个 prompt 为条件,在NLP任务方面给这个样本贴上标签。
prompt 是一个长度不受限制的序列,由预先定义的领域相关特征(DRFs)组成,这些特征是每个源域的特征。直观地说,prompt 是一个独特的签名,它将测试实例映射到源域所跨越的语义空间。
Introduction
NLP算法往往依赖于一个开创性的假设,即训练集和测试集来自相同的基础分布。不幸的是,这个假设往往不成立,因为文本可能来自许多不同的来源,每个来源都有独特的分布属性。由于超出训练分布的泛化仍然是一个基本的挑战,NLP算法在应用于非分布的应用时,会出现明显的退化。
领域适应(DA)明确地解决了上述挑战,努力改善NLP算法的 out-of-distribution 。DA算法在源领域的标注数据上进行训练,以有效地应用于各种目标领域。
多年来,人们为DA挑战付出了相当大的努力,专注于目标领域在训练时是已知的(例如,通过标记或未标记的数据),但仍未得到充分体现的各种情况(Roark和Bacchiani,2003;Daumé III和Marcu,2006;Reichart和Rappoport,2007;McClosky等人,2010;Rush等人,2012;Schnabel和Schütze,2014)。然而,对训练时未知的任何可能的目标领域的适应性挑战还没有得到充分的探索。
PADA具有独特的建模优势,因为目标感知算法通常需要为每个目标域训练一个单独的模型,导致整体解决方案效率低下。
直观地说,通过整合来自几个源域的知识,可以实现对未见过的事物更好的泛化。PADA:基于 Prompt 的自回归领域适应算法,它利用自回归语言模型(T5),并包括一个适应于多个源领域的新型 Prompt 机制。给定一个来自任何未知领域的新样本,该模型首先生成属于熟悉的(源)领域并与给定样本相关的属性。然后,在模型执行下游任务时,生成的属性被用作 prompts。
为了产生有效的 prompts ,我们从以前关于 pivot features 的工作中得到启发(Blitzer等人,2006;Ziser和Reichart,2018a;Ben-David等人,2020),定义了领域相关特征(DRFs)的集合。DRFs是与源域之一密切相关的特征,编码了特定领域的语义。我们利用各个源域的DRFs,以跨越它们的共享语义空间。这些DRFs共同反映了源域之间的相似性和差异性,以及特定领域的知识。
Related Work
在DA研究中,有两种突出的设置:有监督的和无监督的。有监督的算法利用来自目标领域的稀缺标记的例子(Daumé III, 2007),而无监督的方法只假设源标记的数据和未标记的源和目标数据在手(Blitzer等人,2006)。
我们首先描述无监督DA的研究,重点是基于pivot-based的方法。然后,我们继续研究多源的DA方法,重点是专家混合模型。最后,我们描述了自回归语言模型和我们采用T5进行DA的独特方式。
Unsupervised Domain Adaptation (UDA)
随着深度神经网络(DNN)建模的突破,DA社区的注意力已经被引向了表征学习方法。其中一项工作是采用基于DNN的自编码器来学习潜在的表征。这些模型在无标签的源数据和目标数据上进行训练,并有输入重建损失(Glorot等人,2011;Chen等人,2012;Yang和Eisenstein,2014;Ganin等人,2016)。
另一个分支采用 pivot 特征来弥补源域和目标域之间的差距(Blitzer等人,2006,2007;Pan等人,2010)。支点特征对感兴趣的任务很突出,在源域和目标域都很丰富。最近,Ziser和Reichart(2017,2018b)将这两种方法结合起来。后来,Han和Eisenstein(2019)提出了一种预训练方法,随后Ben-David等人(2020)提出了一种基于 pivot-based 的变体,用于预训练语境词嵌入。
最重要的是,UDA模型假定在训练过程中可以获得来自目标领域的无标签数据。我们认为这是对超越训练分布的泛化目标的一个轻微的放松。此外,这个定义在工程上有缺点,因为每个目标域都需要一个新的模型。为此,我们追求任何领域的适应性设置,即在训练时无法获得未标记的目标数据。
我们从 pivot-based 的模型中得到启发。pivot 的定义依赖于标记的 源域数据 和 未标记的源域 和 目标域数据。特别是,好的 pivot 是与任务标签相关的。相反,我们定义了任务变量DRF,这些特征与领域的身份高度相关。由于领域与单词高度相关,我们的DRFs在本质上是词汇性的。
虽然我们的方法可以在单一的源域中运行,但我们利用多个源域来促进对未知目标域的推广。我们接下来讨论多源DA。
Multi-Source Domain Adaptation
大多数现有的多源DA方法遵循无监督DA的设置定义,同时考虑一个以上的源域。一个突出的方法是融合几个来源的模型。早期的工作是为每个领域训练一个分类器,并假设所有的源领域对测试样本都是同等重要的(Li和Zong,2008;Luo等人,2008)。最近,基于对抗的方法使用未标记的数据,将源域与目标域对齐(Zhao等人,2018;Chen和Cardie,2018)。同时,Kim等人(2017年)和Guo等人(2018年)根据目标实例和每个源域之间的关系,明确地对专家混合模型(MoE)模型进行加权。然而,Wright和Augenstein(2020)在这项工作之后,在基于Transfomers的MoE上测试了各种加权方法,发现加权方法非常有效。
我们认识到所提出的MoE解决方案的两个局限性。首先,它是不可扩展的,因为它要求每个源域都有一个专家,导致模型参数随着源域数量的增加而增加(通常是线性的)。第二,领域专家是针对特定领域的知识进行调整的。然而,测试实例可能来自未知的领域,并可能反映出来源的复杂组合。为了解决这个问题,MoE使用启发式方法将专家的预测集合起来,例如简单的平均数或基于领域分类器预测的加权平均数。我们的结果表明,这种方法是次优的。
在这项工作中,我们训练一个模型,该模型在所有领域中共享其参数。此外,我们对适应任何目标领域感兴趣,这样在训练时就不需要知道关于潜在目标领域的信息。上述一些工作(Wright和Augenstein,2020年)事实上避免了利用目标数据,因此它们适合任何领域的设置,并形成了我们的两个基线。然而,与这些作品相比,我们认为这个定义是本研究的核心部分。
Autoregressive Language Modeling
以前的工作在训练基于Transformer(Vaswani等人,2017)的语言模型时主要考虑两种方法。第一种实现了经典的马尔科夫语言建模方法,通过训练Transformer解码器模型,根据其之前的上下文自动生成下一个词(Radford和Narasimhan,2018;Radford等人,2019)。第二种是将自回归语言建模方法作为一个掩盖的标记预测任务,通过训练Transformer的编码器来得出上下文的单词嵌入(Devlin等人,2019;Liu等人,2019;Sanh等人,2019)。当为一个新的任务微调模型时,一个自定义的解码器被实现,并与模型的预训练编码器联合训练。
最近提出了第三种方法,试图将以前的方法中的优点结合起来。它提出训练一个完整的Transformer(编码器-解码器)语言模型,从输入序列中自动渐进地生成屏蔽的、缺失的或扰乱的标记跨度,作为一个序列到序列的任务(Raffel等人,2020;Lewis等人,2020b)。最近,Raffel等人(2020)提出了T5,一个基于转化器的模型,提出了文本到文本的迁移学习方法。T5基本上将所有的任务视为生成性的,同时利用一个提示短语来表示正在执行的具体任务。结合其文本到文本的方法,T5在许多鉴别性和生成性任务中显示出其优越性,同时消除了对特定任务网络结构的需求。
T5的一个特别有趣和有用的特点是其 prompting 机制。prompt 短语通常用于指示模型要执行的任务,被作为前缀添加到所有与任务相关的输入实例中。最近的工作也探索了这种 prompt 机制,以使语言模型适应不同的目的(Brown等人,2020年),激发情感或话题相关的信息(Jiang等人,2020年;Sun和Lai,2020年;Shin等人,2020年),或作为一种有效的微调方法(Li和Liang,2021年)。在这项工作中,我们利用T5的提示机制,作为激发模型编码与每个测试例子相关的特定领域特征的方式。
Any-Domain Adaptation
DA and Transfer Learning
一个预测任务被定义为 $T = {Y}$,其中 $Y$ 是任务的标签空间。定义 $X$ 为特征空间,$P(X)$ 是 $X$ 上的边缘分布,$P(Y)$ 对 $Y$ 的先验分布。domain 被定义为 $D^T={X, P(X), P(Y),P(Y|X)}$
DA是迁移学习的一个特殊案例,即过渡性转移学习,其中 $T_S$ 和 $T_T$,即源任务和目标任务,是相同的。
$DS^T, D^{T}{T}$ 是源域和目标域,至少有一个基础概率分布不同,即$P(X),P(Y) \ or \ P(Y|X)$。
DA 的目标是从一组源域 ${ D{S_i}}^K{i=1}$ 中学习一个函数 $f$ ,这个函数可以很好地泛化到一组目标域$ { D{T_i} }^M{i=1}$
The Any-Domain Setting
我们专注于为一个给定的任务建立一个能够适应任何领域的算法。为此,我们假设在训练时对目标领域 $D_T$ 的了解为零。因此,我们稍微修改了无监督多源领域适应的经典设置,假设我们不知道或无法获得目标领域的标记或未标记数据。
我们只假设可以从K个源域中获得标记的训练数据 $ {D{s_i}}$,其中 $D{S_i} = {(x_t^{S_i}, y_t^{S_i})}$。目标是学习一个仅使用源域数据的模型,该模型可以很好地概括到一个未知的目标域。
Any-Domain Adaptation and Zero-Shot Learning
我们避免将我们的设置命名为 “Zero-Shot DA”,因为我们认为Zero-Shot学习是一个过载的术语,而且它的用法在不同的作品中是不同的。一方面,GPT-3的作者(Brown等人,2020)用这个术语来表示向未知目标任务 $T^T$和未知领域 $D^T$的转变。
另一方面,Kodirov等人(2015)假设任务/标签空间漂移,而目标域在训练期间是已知的,Blitzer等人(2009)假设可以访问来自包括目标域在内的各种领域的无标签数据,而Peng等人(2018)使用来自目标域的不同任务数据。我们的问题设置与上述作品不同,但在某种程度上都可以被描述为 “Zero-shot”。在我们看来,这些差异应该被澄清,因此我们为我们的设置提出了一个指定的术语。
Prompt-based Autoregressive DA
正如前面第2节所讨论的,我们认识到基于MoE的方法所提出的解决方案有两个主要限制。(1) 它是不可扩展的。训练的参数总数,对于单个模型来说已经很大了,随着源域数量的增加而线性增长,因为需要为每个域分别训练一个专家模型。自然,这也增加了整体的训练时间;(2)在这种方法中,每个领域都要训练一个单独的模型。直观地说,针对特定领域的专家被调整为针对特定领域的知识,有时会牺牲跨领域的知识,因为跨领域的知识强调不同领域之间的关系。此外,由于领域的划分往往是任意的(例如考虑dvd和电影领域之间的差异),我们不希望将我们的模型严格限制在一个特定的分区,而是鼓励对领域边界采取更宽松的方法。
因此,我们提出一个单一的模型来编码来自多个领域的信息。我们的模型是这样设计的:来自新的未知领域的测试样本可以触发模型中最相关的参数。这样,我们允许我们的模型在各领域之间共享信息,并在测试时使用最相关的信息。我们的模型受到最近关于自回归语言模型 prompt 机制的研究启发。最近的工作显示了prompt 机制在激发这些模式方面的有效性(§2),尽管不是在DA的背景下。
我们首先(第4.1节)描述了我们模型的一般结构,然后(第4.2节)介绍了形成我们prompt的领域相关特征。
The Model
一个多任务模型,有一个为DRF生成训练的生成头和一个为谣言检测训练的鉴别头。标记的文字表示DRF,标记的文字表示域名。黑色箭头(→)表示第一个推理步骤,红色箭头(→)表示第二个推理步骤。提出的模型是在4个不同的源域上训练的。Ferguson, Germanwings-crash, Ottawa-shooting, and Sidney-siege,而测试实例来自Charlie-Hebdo域。这些模型识别出例子的来源是悉尼围城,并将其与3个DRF相关联:人质、咖啡馆和枪手。
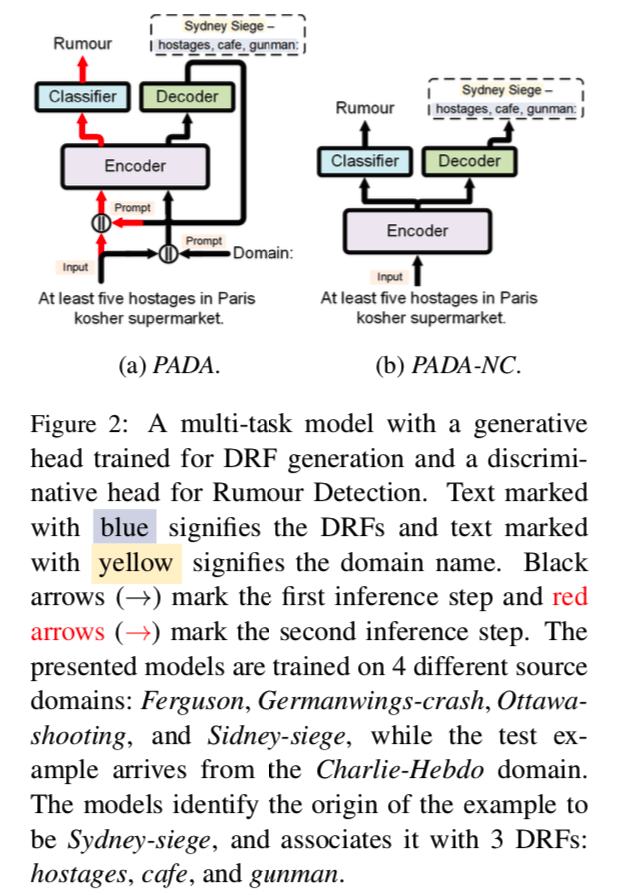
我们提出了基于提示的领域适应自回归算法(PADA,图2a)。PADA采用了一个预先训练好的T5语言模型,并学习生成特定样本的领域相关特征(DRFs),以促进准确的任务预测。这是通过一个两步多任务机制实现的,首先生成一个DRF集以形成一个prompt,然后预测任务标签。
形式上,假设一个输入样本 $ (x_i, yi) \sim S_i $ ,这样 $x_i$ 是输入文本,$y_i$ 是任务label,$S_i$是这个例子的领域。
对于输入的 $x_i$,PADA被训练成首先生成 $N_i$,即域名,然后是 $R_i$,即 $x_i$ 的DRF签名,并根据这个 prompt 来预测标签$y_i$。在测试时,当模型遇到一个来自未知领域的例子时,它会产生一个 prompt,该 prompt 可能由一个或多个域名以及一个或多个源域的DRF集的特征组成,并基于该 prompt 预测任务标签。
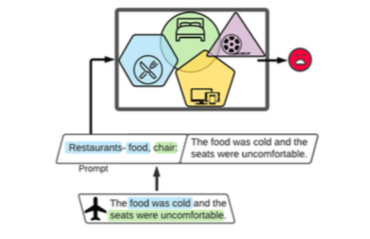
考虑到图1中的例子,它描述了一个情感分类模型,在餐馆、家庭家具、电子设备和电影等源域上进行训练。该模型观察到一个来自航空公司领域的测试例子,这是一个以前没有见过的领域,模型不知道其名称。该模型首先生成最适合这个例子的训练域的名称,在这个例子中是餐馆。然后,它继续生成 “食物 “和 “椅子”,这两个词分别与餐馆和家庭家具领域有关。最后,鉴于这一 prompt,该模型预测了该例子的(负面)情绪。
为了将 prompt 生成任务与判别分类任务分开,我们在一个多任务框架内训练我们的模型。根据样本的prompt,PADA被训练成执行两个任务。一个是生成 prompt,由例子领域的DRF集的特征组成,另一个是预测样本的标签。
对于第一个生成任务,模型接收带有特殊prompt “域:”的例子,这为模型生成 $N_i$ 和 $R_i$ 提供了条件。请注意,$R_i$是一组从 $S_i$ 的DRF集衍生出来的特征,如第4.2节所述,训练的样本被自动注释了它们的 $R_i$。对于第二个判别性任务,模型收到一个 prompt ,由 $N_i$ 和 $R_i$ 组成,其任务是预测 $y_i$。
按照T5的多任务训练协议,我们对每个任务的样本进行混合。为此,我们定义了一个任务比例混合参数 $α$。 训练集中的每个例子都以 $α$ 的概率形成生成性任务的样本,以 $1-α$ 的概率形成鉴别性任务的样本。$α$ 的值越大,模型对生成性任务的训练就越多。
PADA以生成的 prompt 为条件进行分类。为了评估这一条件的效果,我们还考虑了一个更简单的PADA变体,它联合执行分类和生成任务,但不使用生成任务的输出作为分类任务的 prompt 。我们把这个变体命名为PADA-NC,以强调判别任务不以生成部分的输出为条件。PADA和PADA-NC之间的区别在图2中得到了强调。
我们方法的核心是巧妙地选择每个领域的DRF集。我们接下来讨论这些特征和它们的选择过程。
Domain Related Features
对于每个领域,我们定义DRF集,使这些特征为该领域提供一个语义签名。重要的是,如果两个领域有共同的语义,例如餐馆和烹饪领域,我们希望它们的DRFs在语义上是重叠的。由于每个训练样本的 prompt 由其领域的DRF集的特征子集组成,我们也应该决定一个 prompt 生成规则,可以用其相关的特征来注释这些训练样本。
为了反映该领域的语义,DRF应该经常出现在该领域。此外,相对于所有其他领域,它们在该特定领域中应该是非常普遍的。尽管DRF在一个特定的领域中很突出,但它也可以与其他领域相关。例如,考虑图2中的例子。人质 “这个词与 “Charlie-Hebdo “领域高度相关,而且确实是其DRFs之一。然而,这个词也与 “Sydney-Siege “域相关,这是Rumour Detection数据集的另一个域(Zubiaga等人,2016)。此外,由于这两个领域都与类似的事件有关,前者的DRF集包含恐怖分子的特征,后者的DRF集包含枪手的特征,这并不令人惊讶。这些特征的相似性促进了我们模型中的参数共享。
我们对每个源域的DRF集定义如下。让第 $j$ 个源域($S_j$)的样本(文本)被标记为1,所有其他域( $S\setminus S_j$ )的例子被标记为 0。我们首先计算所有 tokens 和这个二元变量之间的相互信息(MI),并选择 MI 得分最高的 $l$ 个token。注意,MI标准可能会促进与( $S\setminus S_j$ )高度相关的标记,而不是与 $S_j$ 。因此,我们根据以下条件来过滤 $l$ 个token:
其中 $C{S_j}(n)$ 是 $S_j$ 中n-gram $n$ 的计数, $C{S\setminus S_j}(n)$ 是在所有源域中除了 $ S_j$ 的 n-gram 计数,$ρ$ 是 n-gram 频率比参数。
直观地说,$ρ$ 越小,我们就越确定这个n-gram与 $S_j$ 特别相关,与其他领域相比。由于 $S_j$ 中的样本数量远远小于 $S\setminus S_j$ 中的样本数量,我们选择 $ρ≥1$ ,但不允许它过大。因此,这个标准允许与 $S_j$ 相关但也与其他源域相关的特征成为 $S_j$ 的DRF集的一部分。我们用 $R_j$ 来表示第 $j$ 个域的DRF集。
给定一个来自领域 $j$ 的训练样本 $i$ ,我们从 $R_j$ 中选择与该样本最相关的 $m$ 个特征来形成其 prompt。为此,我们计算DRF特征的T5嵌入 和 每个样本的T5嵌入 之间的欧几里得距离。然后,我们根据分数对这个列表进行排序,并选择最重要的 $m$ 个特征。(在这个计算中,我们考虑了T5在其预训练期间学到的非语境嵌入。在我们的实验中,我们只考虑单字(单词)作为DRFs。)
总而言之,我们针对特定领域的 DRF 集提取和训练样本的 prompt 注释的方法,展示了三个有吸引力的特性。首先,每个样本都有它自己独特的prompt 。其次,我们的 prompt 将每个训练样本映射到其领域的语义空间。最后,特定领域的DRF集可能会在其语义上重叠,要么包括相同的token,要么包括具有类似含义的token。这样,与单独的域名相比,它们提供了一个更细微的领域签名。在推理阶段,模型可以生成一个特定的样本prompt,该提示由不同源域的DRF集的特征组成,这一点后来被使用。
Experimental Setup
我们的主要模型是PADA:这个多任务模型首先生成域名和领域相关的特征,形成一个prompt,然后用这个prompt来预测任务标签。我们将其与两种类型的模型进行比较。(a) 基于T5的基线,对应于多源DA工作中提出的想法,以及其他最近的最先进的模型;以及(b) 使用PADA特定部分的消融模型,以强调其组成部分的重要性。
Baseline Models
- Content-CRF : 一个为谣言检测而训练的CRF模型。每个预测都以相关的推文以及之前的推文为条件,同时结合了基于内容和社会特征。
- Transformer-based Mixture of Experts: 对于每个源域,在该域的训练集上训练一个单独的基于变压器的DistilBERT专家模型(Sanh等人,2019),并在所有源域的数据上训练另一个模型。在测试时,计算这些模型的类别概率的平均值,并选择最高概率的类别。这个模型被Wright和Augenstein(2020)命名为MoE-avg,并证明了在谣言检测方面取得了最先进的性能(该论文将CCRF的重新结果报告为其之前的最先进性能)。
- T5-MoE :一个基于T5的MoE集合模型。对于每个源域,一个单独的预训练的T5模型在该域的训练集上进行微调(即一个领域专家模型)。在推理过程中,模型的最终预测是用Tr-MoE中相同的平均程序决定的。
- T5-No-Domain-Adaptation (T5-NoDA) :一个预先训练好的T5模型,它向PADA(见下文)中使用的同一任务分类器提供信息,以预测任务标签。 在每个DA设置中,该模型是在所有源域的训练数据上训练的。
- T5-Domain-Adversarial-Network (T5-DAN) :一个将T5-NoDA与对抗性领域分类器整合的模型,以学习领域不变的表征(Ganin和Lempitsky,2015)。
- T5-Invariant-Risk-Minimization (T5-IRM) :一个基于T5的模型,它对每个领域有不同的最佳线性分类器的特征分布进行惩罚。IRM(Arjovsky等人,2019)是一个成熟的机器学习基线,用于超越多源分布的泛化(Koh等人,2020)。该模型是在所有源域的训练数据上训练的。
- T5-UpperBound (T5-UB) :一个与T5-NoDA结构相同的域内模型。它在所有领域的训练数据上进行训练,在每个领域的开发数据上进行测试。我们将其性能视为所有DA设置中平均目标性能的上限,对于我们设置中的任何基于T5的模型。
Ablation Models
- PADA-DN 我们的PADA模型的一个简化变体,它只给输入文本分配一个域名作为prompt。由于域名在测试时是未知的,我们为每个测试样本创建多个变体,每个变体都有一个训练域名作为prompt。对于模型的最终预测,我们遵循与Tr-MoE和T5-MoE相同的平均化过程。
- PADA-NC 一个类似于PADA的多任务模型,只是它同时生成特定于样本的域名和DRF prompt并预测任务标签。这个模型不以提示为条件进行任务预测。
Implementation Details
对于所有实现的模型,我们都使用了 “Hugging-Face “ Transformers库。基于T5的文本分类模型没有遵循Raffel等人(2020)最初描述的程序。相反,我们在T5编码器之上添加了一个简单的 1D-CNN分类器 来预测任务标签(图2)。
该分类器中的过滤器数量为32个,过滤器大小为9。基于T5的模型的生成部分与原始T5的生成部分相同。我们基于T5的特征预测模型将序列标记作为一个序列到序列的任务,采用Raffel等人(2020)的文本到文本方法,为每个输入标记生成一个’B’(开始)、’I’(进入)或’O’(退出)标记。 除了这一变化外,这些模型与基于T5的文本分类模型完全相同。
我们对所有的文本分类模型进行5个 epochs 的训练,对所有的序列标签模型进行60个 epoch的训练,并根据开发数据的表现制定早期停止的标准。我们对所有模型使用交叉熵损失函数,用ADAM优化器(Kingma和Ba,2015)优化其参数。我们对文本分类采用32个批处理规模,对序列标签采用24个批处理规模,预热比为0.1,学习率为5 e10-5。所有基于T5的模型的最大输入和输出长度被设定为128个符号。我们对较短的序列进行填充,并将较长的序列截断到最大输入长度。
对于PADA,我们调整α(例子比例—混合物,见§4.1)参数,考虑到{0.1, 0.25, 0.5, 0.75, 0.9}的数值范围。)选择的数值是 αrumour = 0.75,αmnli = 0.1和αabsa = 0.1。对于每个例子,我们选择与之最相关的前m = 5个DRF,对其进行提示。
对于基于T5的模型的生成部分,我们用Diverse Beam Search算法(Vijayaku- mar等人,2016)进行推理,考虑以下超参数。我们产生了5个候选人,使用10个波束大小,5个波束组,多样性惩罚值为1.5。DRF提取程序(§4.2)的l和ρ参数被调整为1000和1.5,适用于所有领域。
Results
Binary-F1测量的是正类的F1得分。它对正类感兴趣的不平衡数据集很有用。在谣言检测数据集中,34%的例子属于正类。
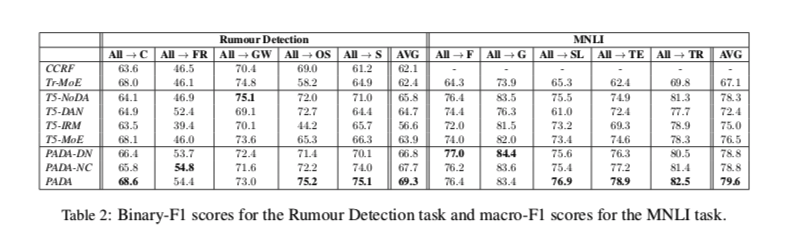
表2显示了我们的结果。 PADA在10个设置中的6个中优于所有的模型,在Rumour Detection和MNLI中分别比T5-NoDA的平均性能提高了3.5%和1.3%,T5-NoDA是不属于我们PADA框架的最佳模型。此外,在10个设置中的9个中,PADA模型是表现最好的模型之一。有趣的是,不执行任何DA的T5-NoDA的性能超过了所有不属于PADA系列的模型,包括MoE模型(平均和大多数模型之间的比较)。
虽然不同任务之间的性能提升不同,但它们部分源于每个任务中源域和目标域之间的不同性能差距。回顾一下,我们认为T5-UB在谣言检测(82.8%)和MNLI(80.8%)的开发集上的表现,是任何基于T5的模型在所有DA设置中平均目标表现的上限。当考虑到这个上限和T5-NoDA之间的差距时(Rumour Detection为65.8%,MNLI为78.3%),PADA将Rumour Detection的错误率降低了21%,MNLI为52%。事实上,PADA在这两项任务中获得的改进是巨大的。
虽然不同任务之间的性能提升不同,但它们部分源于每个任务中源域和目标域之间的不同性能差距。回顾一下,我们认为T5-UB在谣言检测(82.8%)和MNLI(80.8%)的开发集上的表现,是任何基于T5的模型在所有DA设置中平均目标表现的上限。当考虑到这个上限和T5-NoDA之间的差距时(Rumour Detection为65.8%,MNLI为78.3%),PADA将Rumour Detection的错误率降低了21%,MNLI为52%。事实上,PADA在这两项任务中获得的改进是巨大的。
与MoE相比,PADA的优势并不局限于改进预测。特别是,对于PADA,我们训练一个单一的模型,而对于MoE,我们为每个源域训练一个独特的模型,因此MoE框架中的参数数量随着源域的数量而线性增加。例如,在我们的设置中,Tr-MoE训练了五个DistilBERT模型(每个源域一个,所有源域一个),导致5 - 66M = 330M参数。相比之下, PADA模型保留了T5的220M参数, 而不考虑源域的数量。
我们的研究结果显示,在10个环境中的9个中,PADA及其变体PADA-DN和PADA-NC优于所有其他模型。特别是,PADA在10个环境中的7个环境中优于非PADA模型,PADA-NC在6个环境中优于这些模型,而PADA-DN在5个环境中优于这些模型。此外,PADA在所有的谣言检测设置中和5个MNLI设置中的3个中优于PADA-DN变体,而其PADA-NC变体在10个设置中的8个中优于PADA-DN。这些结果突出了我们设计选择的重要性。(a) 在特定例子的提示中包括DRFs,使它们能够表达源域和测试例子之间的关系(PADA vs PADA-DN);以及(b) 利用自回归组件,其中生成的DRF提示被任务分类组件使用(PADA vs PADA-NC)。
Performance Shifts between Source and Target

当DA方法提高了模型在目标域的性能时,这可能会导致源域和目标域之间的性能差距增加或减少。如果一个模型在其源训练域和未见过的目标域的表现相似,其源域的表现也可以为其未来在这些未见过的域的表现提供一个重要的指示。因此,在我们的设置中,如果未来的目标域是未知的,我们认为这种性能的稳定性是一个理想的属性。
图3显示了三个热图,描述了每个模型在源域和目标域之间的性能变化。如第6节所述,我们通过计算所有源域开发样本的F1得分和目标域测试集的表现来衡量每个模型的域内性能。然后,我们计算源域和目标域性能指标之间的差异,并对实验中表现最好的模型进行重新定位。总的趋势是明确的:PADA不仅在目标域表现更好,而且它还大大减少了源-目标性能的差距。虽然不是DA模型的T5-NoDA引发了最大的平均绝对性能转变—Rumour Detection为17%,MNLI为4.3%,Aspect Prediction为34%,但PADA的平均绝对性能转变分别为8.7%、3.5%和26%。
Discussion
我们解决了在训练时不知道目标域的情况下的多源域适应问题。这种设置的有效模型可以应用于任何目标域,对目标域没有任何数据再要求,而且模型参数的数量不会随着源或目标域的数量而增加。我们的算法PADA利用了T5自回归语言模型的提示机制,将测试例子映射到源域所跨越的语义空间。
我们对三个任务和十四个多源适应性设置的实验结果表明,与强大的替代方案相比,我们的方法是有效的,同时也表明了模型组件和我们的设计选择的重要性。此外,与MoE范式相比,PADA提供了一个统一的模型,即为每个源域训练一个模型。从直觉上讲,这种方法似乎也更符合认知规律—一个单一的模型试图使自己适应新的输入领域,而不是在每个领域采用一个独立的模型。
PADA的提示生成机制自然受到它所训练的源域集的限制。这可能会产生次优的DRF,而这些测试例子来自于与任何源域在语义上极不相关的领域。此外,我们没有直接用主要预测任务来优化提示生成过程,这也可能导致次优的DRF生成。在未来的工作中,我们希望改进我们方法的这些方面,并探索在一个单一模型中容纳多个任务和领域的自然扩展。
 wechat
wechat alipay
alipay





