Towards a Unified View of Parameter-Efficient Transfer Learning
Towards a Unified View of Parameter-Efficient Transfer Learning
ICLR2022高分文章
这篇工作将最近提出的多种Parameter-Efficient的迁移学习方法联系在了一起,提出了一个统一的框架,并探索了这些方法成功的关键因素是什么。
统一什么?把Adapter、prompt-tuning、LoRA都定义为预训练模型中添加可调整的特定的隐层状态,只是设计的参数维度、修改函数的计算和位置不同。定义成一个统一的框架,顺便还排列组合出几个小变体。
INTRODUCTION
使通用PLM适应下游任务的最常见方法是微调所有模型参数。然而,这导致每个任务都有一份单独的微调模型参数,当为执行大量任务的模型提供服务时,其成本过高。
为了缓解这个问题,已经提出了一些轻量级的替代方案,只更新少量的额外参数,同时保持大多数预训练参数的冻结,如:Adapters、prefix tuning 与 prompt tuning、LoRA 。(下文详细介绍他们)
这些方法都在不同的任务集上表现出与完全微调相媲美的性能,通常是通过更新不到1%的原始模型参数。除了节省参数外,参数有效的调整使其有可能快速适应新的任务,而不会出现灾难性的遗忘(Pfeiffer等人,2021),并且在 out-of-distribution 上往往表现出卓越的稳健性。
作者接下来针对上面这几种参数有效的方法提出了几个问题:
- 这些方法是如何联系的?
- 这些方法是否具有对其有效性至关重要的设计要素,这些要素是什么?
- 每种方法的有效成分是否可以转移到其他方法中,以产生更有效的变体?
PRELIMINARIES
首先看一下现有这些方法在Transformer里的结构是如何:
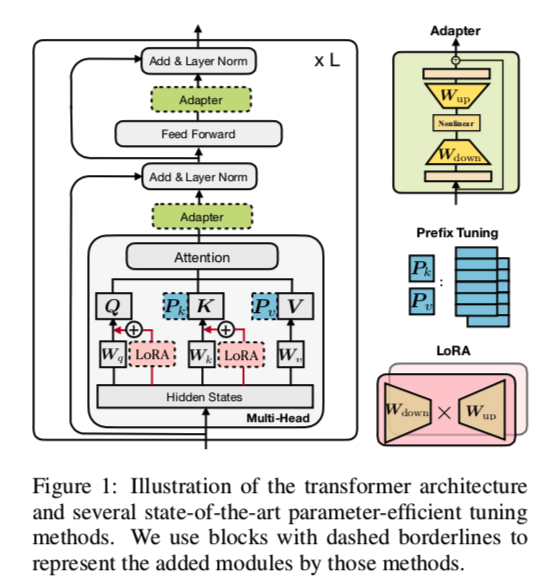
Adapters:在PLM的每一层插入称为适配器的小型神经模块,在微调时只对适配器进行训练。适配器层一般使用$W{down}\in R^{d×r}$的向下投影,将输入 $h$ 投影到瓶颈维度 $r$ 指定的低维空间,然后使用非线性激活函数 $f(\cdot)$,再使用$W{up}\in R^{r×d}$的向上投影,还有一个残差连接。
将两个适配器依次放在变压器的一个层内,一个在多头关注之后,一个在FFN子层之后。
prefix tuning 与 prompt tuning :受通prompt方法的启发,在输入层或隐藏层中预置了额外的 $l$ 个可调整的前缀tokens,在下游任务的微调时只训练这些 soft prompt。具体来说,两组prefix 向量 $P_k , P_v\in R^{l×d}$ 与原始键 $K$ 和值$V$相连接,如图中所示。然后对新的 prefixed key 和值进行多头注意力计算:
这其实也于Graphormer等Graph Transformer模型有异曲同工之妙。$P_k$ 和 $P_v$ 分别被分成 $N_h$个头部向量。Prompt-tuning 简化了前缀调整,其只对第一层的输入词嵌入进行预处理;类似工作还包括P-tuning。
LoRA :将可训练的低秩矩阵注入 transformer 层,以近似权重更新。对于一个预训练好的权重矩阵 $W\in R^{d×k}$ LoRA用低秩分解 $W +\Delta W = W +W{down}W{up}$ 表示其更新,其中$W{down}\in R^{d×r},W{up}\in R^{r×k} $ 是可调整的参数。LoRA将这种更新应用于多头注意子层中的 Query 和 Key 投影矩阵,如图1所示。对于多头注意力中的线性投影的特定输入$x$ ,LoRA将投影输出 $h$ 修改为:
其中 $s≥1$ 是可调标量超参数。
其实还有一些参数有效的调整方法像:BitFit 只对预训练模型中的 bias 向量进行微调,以及上一篇文章提到的diff-pruning,它学习一个稀疏的参数更新向量。
推导 prefix tuning
上文关于 prefix tuning 在注意力 K 和 V上添加可学习的向量来改变注意力模块,这里提出另一种观点:
其中 $λ(X)$ 是标量,归一化注意力权重之和:
THE UNIFIED FRAMEWORK
受 prefix tuning 和 Adapter 之间联系的启发,作者提出了一个总体框架,旨在统一几种最先进的参数有效的调谐方法。
具体来说,作者把它们看作是学习一个向量 $∆h$,它被应用于各种隐藏表征。形式上,作者把要直接修改的隐藏表征表示为 $h$ ,把计算 $h$ 的PLM子模块的直接输入表示为 $x$。
为了描述这个修改过程,作者定义了一组设计维度,不同的方法可以通过改变这些维度的值而被实例化。并在表1中说明了Adapters、prefix tuning 和LoRA在这些维度上的情况。
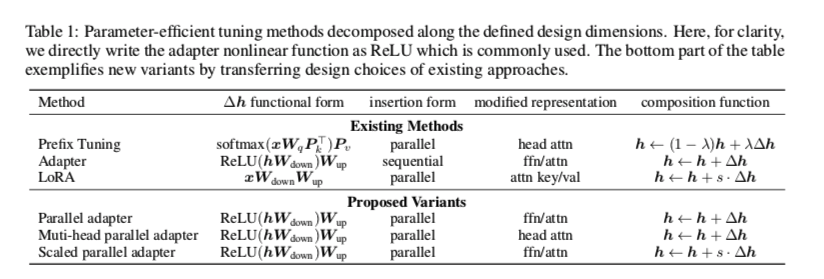
- 表中的 Functional Form :是指计算 $∆h$ 的具体函数。所有这些方法的函数形式都类似于proj down → nonlinear → proj up的架构。
- Modified Representation : 指直接修改的隐藏表示形式。
- Insertion Form : 指添加的模块如何插入到网络中。传统上适配器是以 sequential 方式插入某个位置的,其中输入和输出都是 $h$ 。prefix tuning和LoRA 相当于 parallel 插入。
- Composition Function :指修改后的向量 $∆h$ 如何与原始隐藏表征 $h$ 计算,以形成新的隐藏表征。例如,适配器执行简单的加法组合,前缀调整使用门控加法组合,而LoRA通过一个恒定的因子对 $Δh$ 进行缩放,并将其添加到原始隐藏表示中。
变体组合——通过在不同的方法之间转移设计元素而得到
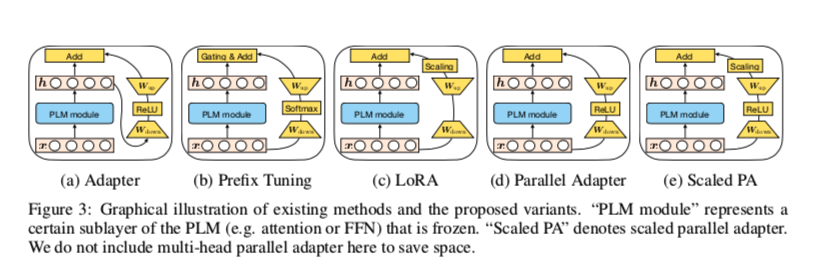
- Parallel Adapter 是通过将 prefix tuning 的 parallel 插入转移到 Adapter 的变体。
- Multi-head Parallel Adapter 是使 Adapter 与 prefix tuning 更加相似的进一步措施:应用 Parallel Adapter 来修改头部注意力输出作为 prefix tuning 。这样,变体通过利用多头投影来提高能力
- Scaled Parallel Adapter 是通过将LoRA的组成和插入形式转移到适配器的变体,如图3e所示。
EXPERIMENTS
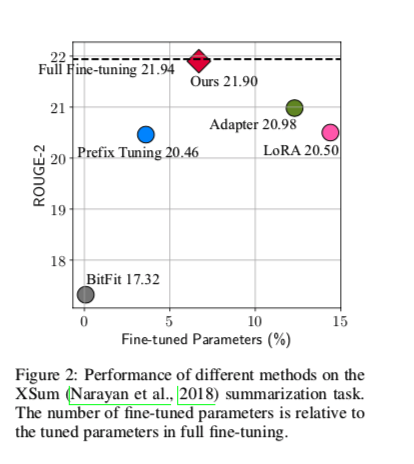
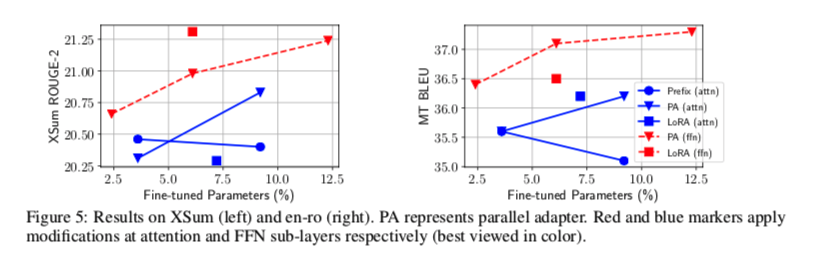
下图说明,在数据较为充沛、比较有挑战的任务中,现有的方法 距离 Full FIne-tuning 还有一定差距
SEQUENTIAL OR PARALLEL?
Parallel 和 sequential 哪个方式好些?
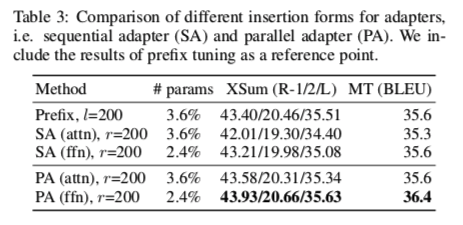
Parallel Adapter在所有情况下都能够击败 Sequential Adapter
WHICH MODIFIED REPRESENTATION – ATTENTION OR FFN?
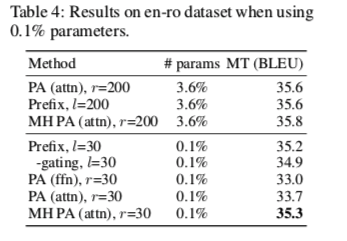
适配修改放在Transformer哪里比较好?
哪个 COMPOSITION FUNCTION 比较好
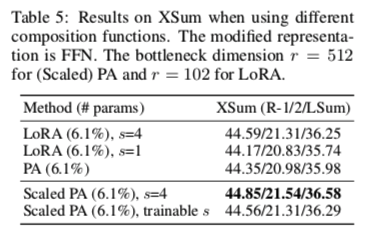
简单composition(Adapter)、门控composition( prefix tuning )和缩放composition(LoRA)。
缩放的 composition 函数,同时也很容易适用。
总结
(1) Scaled parallel adapter 是修改FFN的最佳变体
(2) FFN可以在更大的容量下更好地利用修改
(3) 像 prefix tuning 这样修改头部注意力可以在只有0.1%的参数下实现强大的性能。
 wechat
wechat alipay
alipay





