EANN: Event Adversarial Neural Networks for Multi-Modal Fake News Detection
EANN: Event Adversarial Neural Networks for Multi-Modal Fake News Detection
社交媒体上的假新闻检测的独特挑战之一是如何识别新出现的事件的假新闻。
大多数现有的方法很难应对这一挑战,因为它们倾向于学习特定于事件的特征,这些特征不能迁移到看不见的事件。
事件对抗神经网络(EANN),它可以提取事件不变的特征,从而有利于对新到达的事件进行假新闻的检测。包括三个主要部分:
- 多模态特征提取器:负责从帖子中提取文本和视觉特征
- 假新闻检测器:学习用于检测假新闻的可判别表示
- 事件鉴别器:去除事件的特定特征,并保留事件间的共享特征
Introduction
最近,社交媒体的激增大大改变了人们获取信息的方式。如今,通过社交媒体消费新闻的人越来越多,社交媒体可以为世界各地发生的事件提供及时、全面的多媒体信息。与传统的文字新闻相比,带有图片和视频的新闻可以提供更好的故事性,吸引更多读者的关注。不幸的是,这也被假新闻所利用,它们通常包含错误的甚至是伪造的图片,以误导读者并获得快速传播。
假新闻的传播可能造成大规模的负面影响,有时会影响甚至操纵重要的公共事件。例如,在2016年美国总统大选的最后三个月内,为支持两位提名人中的任何一位而产生的假新闻被很多人相信,在Facebook上的分享次数超过3700万次。因此,非常需要一个自动检测器来减轻假新闻造成的严重负面影响。
到目前为止,各种假新闻检测方法,包括传统学习[6, 15, 29]和基于深度学习的模型[21, 25],都被利用来识别假新闻。在对不同事件进行充分验证的情况下,现有的深度学习模型由于其卓越的特征提取能力,已经取得了比传统模型更好的性能。然而,它们仍然无法处理假新闻检测的独特挑战,即检测新出现的和时间关键的事件上的假新闻[27]。由于缺乏相应的先验知识,关于这类事件的经过验证的帖子很难及时获得,这导致现有模型的性能不尽人意。事实上,现有的模型倾向于捕捉许多事件的特定特征,这些特征在不同的事件中并不共享。这些特定的事件特征,虽然能够帮助对已验证的事件进行分类,但会影响对新出现的事件的检测。出于这个原因,我们认为学习所有事件中的共享特征将有助于我们从未经核实的帖子中检测出假新闻,而不是捕捉事件的具体特征。因此,这项工作的目标是设计一个有效的模型,去除不可转移的特定事件特征,保留所有事件中的共享特征,以完成识别假新闻的任务。
要删除事件的具体特征,第一步是要识别它们。对于不同事件的帖子,它们有自己独特的或特定的特征,是不可共享的。这种特征可以通过测量对应于不同事件的帖子之间的差异来检测。在这里,帖子可以用学到的特征来表示。因此,识别事件的特定特征等同于测量不同事件的学习特征之间的差异。然而,这是一个在技术上具有挑战性的问题。首先,由于帖子的学习特征表示是高维的,像平方误差这样的简单指标可能无法估计这种复杂特征表示之间的差异。其次,在训练阶段,特征表示不断变化。这就要求所提出的测量机制能够捕捉到特征表征的变化并持续提供准确的测量。尽管这非常具有挑战性,但有效估计不同事件上所学特征的差异性是去除事件特定特征的前提。因此,如何在这种条件下有效地估计异同性是我们必须解决的挑战。
为了应对上述挑战,提出了一个端到端的框架,称为事件对抗神经网络(EANN),用于基于多模态特征的假新闻检测。受对抗网络的启发,我们在训练阶段加入了事件判别器来预测事件的辅助标签,而相应的损失可以用来估计不同事件之间特征表示的不相似性。损失越大,不相似性越低。由于假新闻利用多媒体内容来误导读者并得到传播,我们的模型需要处理多模态的输入。多模态特征表示仍然高度依赖于数据集中的特定事件,不能很好地泛化为识别新来事件的假新闻。
受到对抗网络的启发。现有的对抗网络通常用于生成能够与观察到的样本相匹配的图像,通过最小化博弈框架。对抗性学习框架已被用于一些任务,如半监督学习的表征[23]、鉴别性的图像特征[20]和领域适应[8, 9]。
模型还在事件判别器和多模态特征提取器之间建立了一个最小化博弈。特别是,多模态特征提取器被强制要求学习一个事件不变的表征来欺骗判别器。通过这种方式,它消除了对所收集的数据集中特定事件的严格依赖,并对未见过的事件实现了更好的概括能力。
METHODOLOGY
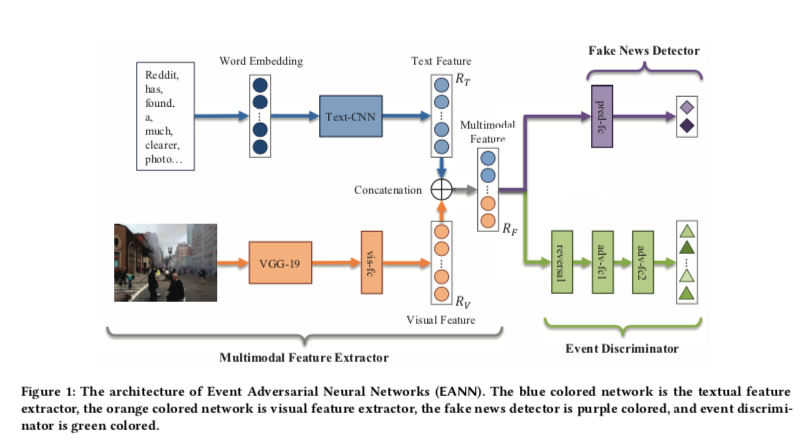
目标是为假新闻检测学习可迁移和可鉴别的特征表示。假新闻检测器和事件判别器都是建立在多模式特征提取器之上的。
- 假新闻检测器将学到的特征表示作为输入,预测帖子是假的还是真的。
- 事件判别器根据这个潜在的表征来识别每个帖子的事件标签。
Multi-Modal Feature Extractor
文本表征 $R_T$ 和 视觉表征 $R_V$, 多模态特征为:$R_F = R_T \oplus R_V \in R^{2p}$
Fake News Detector
它部署了一个带有softmax的全连接层来预测帖子是假的还是真的。假新闻检测器是建立在多模态特征提取器之上的,因此将多模态特征表 $R_F$ 作为输入。我们将假新闻检测器表示为 $G_d(\cdot;θ_d)$,其中 $θ_d$ 代表所有包含的参数。对于第 $i$ 个多媒体帖子,假新闻检测器的输出表示为 $m_i$,是这个帖子是假的概率:
假新闻检测器的目标是识别一个特定的帖子是否是假新闻。我们使用 $Y_d$ 来表示标签集,并采用交叉熵来计算检测损失。
我们通过寻求最佳参数 $\hat θ_f$和 $\hat θ_d $ 来最小化检测损失函数,这个过程可以表示为:
如前所述,假新闻检测的主要挑战之一是训练数据集没有涵盖的事件。这就要求我们能够为新出现的事件学习可迁移的特征表示。检测损失的直接最小化只有助于检测训练数据集中所包含的事件的假新闻,因为这只捕捉到了特定事件的知识(如关键词)或模式,不能很好地进行推广。
因此,我们需要使模型能够学习更多的一般特征表示,以捕捉所有事件中的共同特征。这样的表征应该是事件不变的,不包括任何事件的特定特征。为了实现这一目标,我们需要消除每个事件的独特性。特别是,我们测量不同事件中特征表征的不相似性,并将其去除,以捕获事件不变的特征表征。
Event Discriminator
事件判别器是一个神经网络,由两个具有相应激活函数的全连接层组成。它的目的是根据多模态特征表示,将帖子正确地分类为K个事件之一。我们将事件判别器表示为 $G_e (R_F; θ_e)$,其中 $θ_e$ 代表其参数。我们用交叉熵来定义事件判别器的损失,并使用 $Y_e$ 来表示事件标签的集合:
损失最小化的事件判别器的参数 $L_e (-, -)$被写成:
上述损失 $L_e (θ_f , \hat θ_e )$可以用来估计不同事件分布的不相似性。大的损失意味着不同事件的分布表征是相似的,而且学到的特征是事件不变量。因此,为了消除每个事件的唯一性,我们需要通过寻求最佳参数来最大化判别损失。
上述想法激发了多模态特征提取器和事件判别器之间的最小值博弈。
一方面,多模态特征提取器试图愚弄事件判别器,使判别损失最大化;另一方面,事件判别器旨在发现包含在特征表示中的事件特定信息,以识别事件。下一小节将介绍三个部分的整合过程和最终的目标函数。
Model Integration
在训练阶段,多模态特征提取器 $G_f(-;θ_f)$ 需要与假新闻检测器 $G_d(-;θ_d)$ 合作,使检测损失 $L_d(θ_f , θ_d)$ 最小,从而提高假新闻检测任务的性能。同时,多模态特征提取器 $G_f (-;θ_f)$试图欺骗事件判别器 $G_e (-; θˆe)$,通过最大化事件鉴别损失 $L_e (θ_f, θ_e)$ 来实现事件不变的表示。事件判别器 $G_e (R_F;θ_e)$试图通过最小化事件判别损失来识别基于多模态特征表示的每个事件。我们可以将这个三人游戏的最终损失定义为:
其中,$λ$ 控制着 【假新闻检测】 和 【事件识别】 的目标函数之间的权衡。在本文中,我们简单地将 $λ$ 设置为1,而不对权衡参数进行调整。对于最小化博弈,我们寻求的参数集是最终目标函数的鞍点:
我们使用随机梯度下降法来解决上述问题。$θ_f$ 根据
进行更新。这里我们采用[8]中介绍的梯度反转层(GRL)。梯度反转层在前向阶段作为一个识别函数,它将梯度与 $-λ$ 相乘,并在反推阶段将结果传递给前层。GRL可以很容易地加在 多模态特征提取器和事件判别器 之间。
为了稳定训练过程,我们采用了[8]中的方法来衰减学习率η。
其中 $α=10,β=0.75$,p从0到1线性变化,对应于训练进度。所提出的事件对抗性神经网络(EANN)的详细步骤在算法1中进行了总结。

EXPERIMENTS

为了进一步分析事件判别器的有效性,我们将EANN-和EANN在微博测试集上用t-SNE[22]学习的文本特征RT定性为图4所示。每个帖子的标签是真实或虚假的。
从图4中,我们可以观察到,对于EANN-的方法,它可以学习到可分辨的特征 ,但学到的特征仍然是扭曲在一起的,特别是对于图4a的左边部分。相比之下,EANN模型学习到的特征表征更具可辨识性,而且在图4b所示的不同标签的样本之间有更大的隔离区域。这是因为在训练阶段,事件判别器试图消除特征表征与特定事件之间的依赖关系。在最小化博弈的帮助下,多模态特征提取器可以针对不同的事件学习不变的特征表征,并获得更强大的转移能力来检测新事件的假新闻。EANN-和EANN的比较证明,所提出的方法在事件判别器的作用下可以学习到更好的特征表征,从而取得更好的性能。
 wechat
wechat alipay
alipay





