Parameter-Efficient Transfer Learning for NLP
Parameter-Efficient Transfer Learning for NLP
微调大型预训练模型是 NLP 中一种有效的传输机制。 但是,在存在很多下游任务的情况下,微调参数效率低下:每项任务都需要一个全新的模型。
作为替代方案,作者建议使用Adapter进行迁移。原始网络的参数保持不变,实现了高度的参数共享。
Adapter提供紧凑且可扩展的模型;它们只为每个任务添加几个可训练的参数,并且可以添加新任务,而无需重新访问以前的任务。
紧凑型模型:在每个任务中使用少量附加参数解决多个任务的模型。
可扩展模型:可以增量训练以解决新任务,而不会忘记以前的任务。
自然语言处理中最常见的两种迁移学习技术是 feature-based 和 fine-tuning。
- feature-based的转移涉及预训练实值嵌入向量。 这些嵌入可能在单词、句子或段落级别。 然后将嵌入提供给自定义的下游模型。
- fine-tuning 涉及从预先训练的网络复制权重并在下游任务上调整它们
feature-based 和 fine-tuning 都需要为每个任务设置一组新的权重。 如果网络的较低层在任务之间共享,则fine-tuning参数效率更高。 然而,提出的adapter tuning方法的参数效率更高。
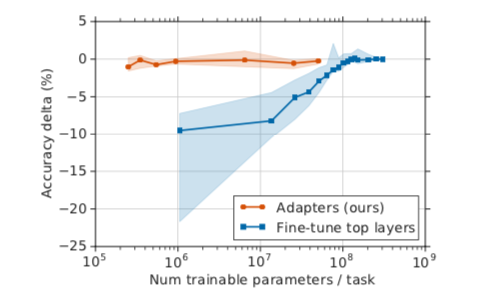
x 轴显示每个任务训练的参数数量; 这对应于解决每个额外任务所需的模型大小的边际增加。
adapter tuning 训练少两个数量级的参数来,同时获得与fine-tuning 相似的性能。
adapter 是在预训练网络层之间添加的新模块。 基于adapter tuning与 feature-based/fine-tuning在以下方面有所不同。
考虑参数为$w$ 的函数 $\phi_w(x)$ (神经网络)。
Feature-based 将 $\phi_w$ 与新函数组合 $X_v$ 在一起: $X_v(\phi_w(x))$ , 然后,仅训练新的、特定于任务的参数 $v$
Fine-tuning 为每个新任务调整原始参数 $w$ , 限制紧凑性。
对于adapter tuning,定义了新函数 $\psi{w,v}(x)$,其中参数 $w$ 从预训练中复制过来。初始参数 $v_0$ 设置为使新函数类似于原始函数:$\psi{w,v0}\approx \phi_w(x) $ 。 在训练期间,只有 $v$ 被调整。 定义 $\psi{w,v}$ 通常涉及向原始网络添加新层 $\phi_{w}$
如果选择 $|v|≪|w|$,结果模型需要 $∼|w|$ 多任务的参数。 由于 w 是固定的,模型可以扩展到新任务而不影响以前的任务。
adapter tuning 几乎与完全Fine-tuning 的BERT的性能相当,但仅使用3%的特定于任务的参数,而微调使用100%的特定于任务的参数。
Method
为了实现这些特性,提出了一个新的瓶颈适配器模块。 当执行深层网络的普通fine-tuning时,对网络的顶层进行修改。这是必需的,因为上游和下游任务的标签空间和损失不同。
Adapter模块执行更通用的架构修改,以将预先训练的网络重新用于下游任务。
特别是,Adapter调整策略涉及将新层注入原始网络。 原始网络的权重不变,而新的Adapter层是随机初始化的。 在标准Fine-tuning中,新的顶层和原始权重是共同训练的。 相比之下,在适配器调整中,原始网络的参数被冻结,因此可能被许多任务共享。
适配器模块有两个主要功能:参数数量较少 和 near-identity 的初始化。
与原始网络的层相比,适配器模块很小。 这意味着当添加更多任务时,总模型大小增长相对缓慢。
Adapter模型的稳定训练需要 near-identity 的初始化;下图实验证明初始化很重要
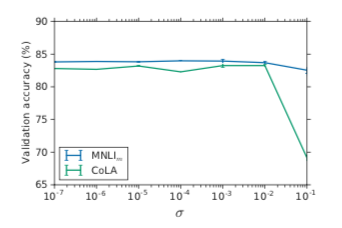
横坐标为初始化分布的标准差
Instantiation for Transformer Networks
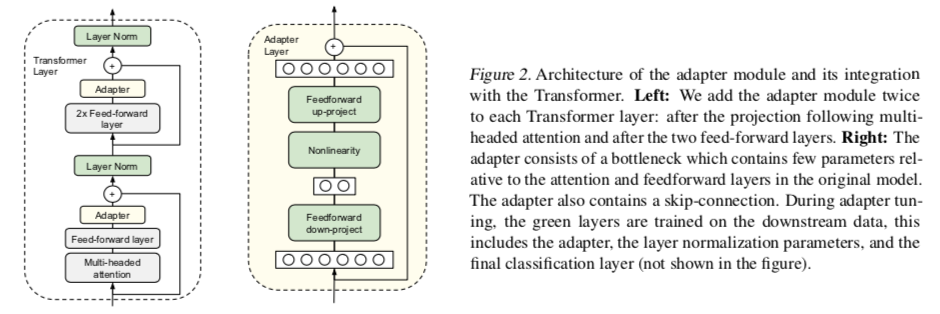
为了限制参数的数量,提出了一种瓶颈结构。
Adapter首先将原始的d维特征投影到较小的维度 m,然后应用非线性再投影回d维。
每层添加的参数总数(包括偏置)为 $2md+d+m$ 。
通过设置 $m≪d$ ,限制每个任务添加的参数数量,使用的参数大约是原始模型参数的0.5−8%。
瓶颈维度 m 提供了一种在性能和参数效率之间进行权衡的简单方法。
 wechat
wechat alipay
alipay





