二分查找基本思想:减而治之
二分查找基本思想:减而治之
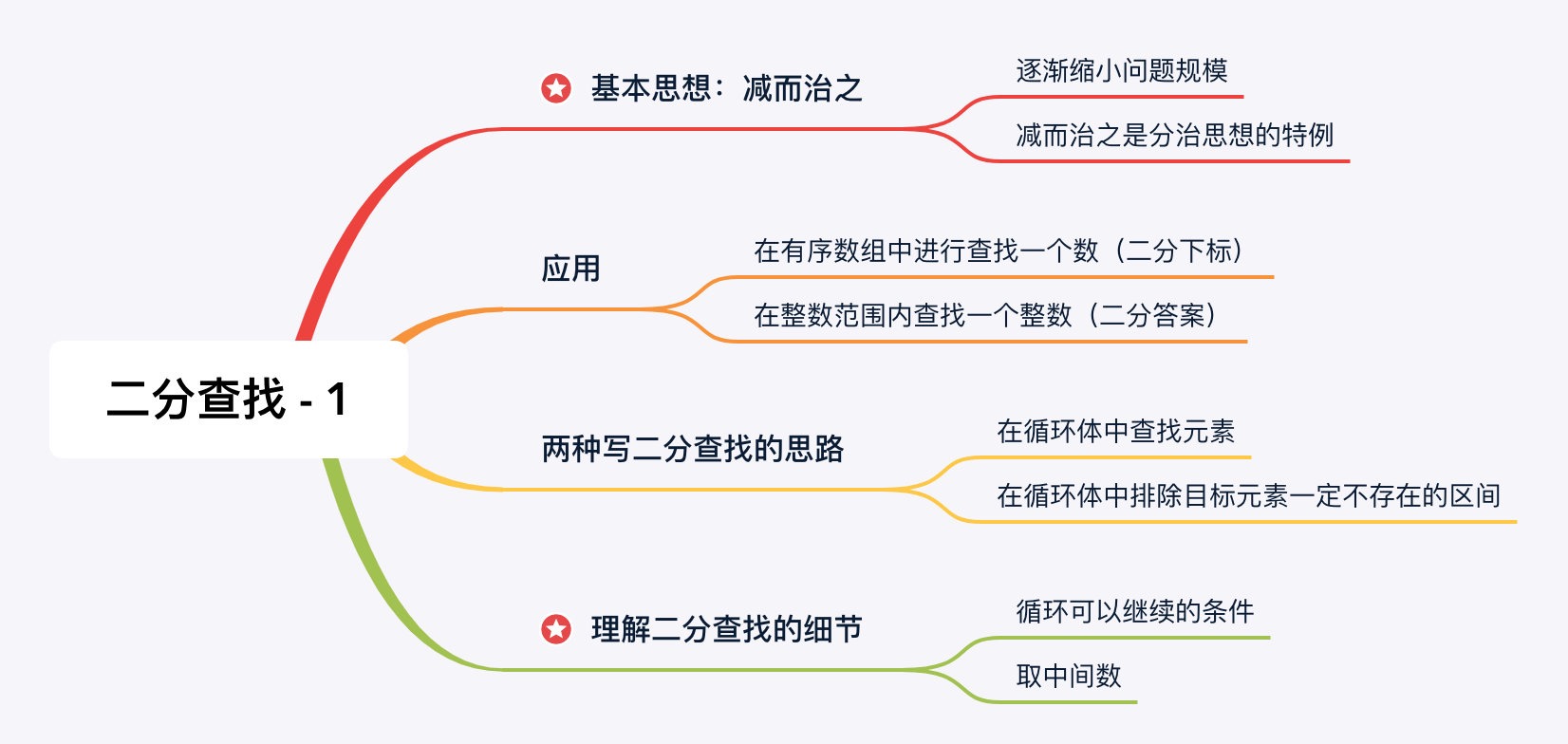
这里「减」是「减少问题」规模的意思,治是「解决」的意思。「减治思想」从另一个角度说,是「排除法」,意即:每一轮排除掉一定不存在目标元素的区间,在剩下 可能 存在目标元素的区间里继续查找。每一次我们通过一些判断和操作,使得问题的规模逐渐减少。又由于问题的规模是有限的,我们通过有限次的操作,一定可以解决这个问题。
可能有的朋友听说过「分治思想」,「分治思想」与「减治思想」的差别就在于,我们把一个问题拆分成若干个子问题以后,应用「减治思想」解决的问题就只在其中一个子问题里寻找答案。
二分查找算法的应用范围
在有序数组中进行查找一个数(二分下标)
这里「数组」和「有序」是很重要的,我们知道:数组具有 随机访问 的特性,由于数组在内存中 连续存放,因此我们可以通过数组的下标快速地访问到这个元素。如果数据存放在链表中,访问一个元素我们都得通过遍历,有遍历的功夫我们早就找到了这个元素,因此,在链表中不适合使用二分查找。
在整数范围内查找一个整数(二分答案)
如果我们要找的是一个整数,并且我们知道这个整数的范围,那么我们就可以使用二分查找算法,逐渐缩小整数的范围。这一点其实也不难理解,假设我们要找的数最小值为 0,最大值为 N,我们就可以把这个整数想象成数组 [0, 1, 2,…, N] 里的一个值,这个数组的下标和值是一样的,找数组的下标就等于找数组的值。这种二分法用于查找一个有范围的数,也被称为「二分答案」,或者「二分结果」,也就是在「答案区间」里或者是「结果区间」里逐渐缩小目标元素的范围;
在我们做完一些问题以后,我们就会发现,其实二分查找不一定要求目标元素所在的区间是有序数组,也就是说「有序」这个条件可以放宽,半有序数组或者是山脉数组里都可以应用二分查找算法。
旋转数组和山脉数组有什么样的特点呢?可以通过当前元素附近的值推测出当前元素一侧的所有元素的性质,也就是说,旋转和山脉数组的值都有规律可循,元素的值不是随机出现的,在这个特点下,「减治思想」就可以应用在旋转数组和山脉数组里的一些问题上。我们可以把这两类数组统一归纳为部分有序数组。
二分查找算法的两种思路
思路 1:在循环体中查找元素 (先介绍);
思路 2:在循环体中排除目标元素一定不存在的区间。
- 如果这个二分查找的问题比较简单,在输入数组里不同元素的个数只有 1 个,使用思路 1 ,在循环体内查找这个元素;
- 如果这个二分查找的问题比较复杂,要你找一个可能在数组里不存在,或者是找边界这样的问题,使用思路 2 ,在循环体内排除一定不存在目标元素的区间会更简单一些。
1 | public class Solution { |
二分查找的细节(重点)
细节 1:循环可以继续的条件
while (left <= right) 表示在区间里只剩下一个元素的时候,我们还需要继续查找,因此循环可以继续的条件是 left <= right,这一行代码对应了二分查找算法的思路 1:在循环体中查找元素。
细节 2:取中间数的代码
取中间数的代码 int mid = (left + right) / 2; ,严格意义上是有 bug 的,这是因为在 left 和 right 很大的时候,left + right 有可能会发生整型溢出,这个时候推荐的写法是:
1 | int mid = left + (right - left) / 2; |
这里要向大家说明的是 /2 这个写法表示 下取整。这里可能有的朋友有疑问:这里取中间位置元素的时候,为什么是取中间靠左的这个位置,能不能取中间靠右那个位置呢?答案是完全可以的。先请大家自己思考一下这个问题,我们放在细节 3 说。
有些朋友可能会看到 int mid = (left + right) >> 1; 这样的写法,这是因为整数右移 1 位和除以 2(向下取整)是等价的,这样写的原因是因为位运算比整除运算要快一点。但事实上,高级的编程语言,对于 / 2 和除以 2 的方幂的时候,在底层都会转化成为位运算,我们作为程序员在编码的时候没有必要这么做,就写我们这个逻辑本来要表达的意思即可,这种位运算的写法,在 C++ 代码里可能还需要注意优先级的问题。
在 Java 和 JavaScript 里有一种很酷的写法:
1 | int mid = (left + right) >>> 1; |
这种写法也是完全可以的,这是因为 >>> 是无符号右移,在 left + right 发生整型溢出的时候,右移一位由于高位补 0 ,依然能够保证结果正确。如果是写 Java 和 JavaScript 的朋友,可以这样写。在 Python 语言里,在 32 位整型溢出的时候,会自动转成长整形,这些很细枝末节的地方,其实不是我们学习算法要关注的重点。
我个人认为这几种种写法差别不大,因为绝大多数的算法面试和在线测评系统给出的测试数据,数组的长度都不会很长,遇到 left + right 整型溢出的概率是很低的,我们推荐大家写 int mid = left + (right - left) / 2;,让面试官知道你注意了整型溢出这个知识点即可。
细节 3:取中间数可不可以上取整
我们在「细节 2」里介绍了 int mid = (left + right) / 2; 这个表达示里 / 2 这个除号表示的含义是下取整。很显然,在区间里有偶数个元素的时候位于中间的数有 22 个,这个表达式只能取到位于左边的那个数。一个很自然的想法是,可不可以取右边呢?遇到类似的问题,首先推荐的做法是:试一试就知道了,刚刚我们说了实证的精神,就把
1 | int mid = (left + right + 1) / 2; |
因为我们的思路是根据中间那个位置的数值决定下一轮搜索在哪个区间,每一轮要看的那个数当然可以不必是位于中间的那个元素,靠左和靠右都是没有问题的。
甚至取到每个区间的三分之一、四分之一、五分之四,都是没有问题的。
1 | int mid = left + (right - left) / 3; |
一般而言,取位于区间起点二分之一处,首先是因为这样写简单,还有一个更重要的原因是:取中间位置的那个元素在平均意义下效果最好。这一点怎么理解呢?
在没有任何「先验知识」的情况下,在搜索区间里猜中间位置是最好的。
例题
35. 搜索插入位置
1 | class Solution { |
34. 在排序数组中查找元素的第一个和最后一个位置
- 不可以找到target后向两边扩散(线性查找),这样的话时间复杂度为 $O(N)$
- 应该使用两次二分查找,先找target第一次出现的位置,再找target最后一次出现的位置,注意分类讨论,并且把分类讨论的结果合并。
1 | class Solution { |
findFirstPosition()
情况 ① :当 nums[mid] < target 时
- mid 一定不是 target 第一次出现的位置;
- 由于数组有序,mid 的左边一定比 nums[mid] 还小,因此 mid 的左边一定不是 target 第一次出现的位置;
- mid 的右边比 nums[mid] 还大,因此 mid 的右边有可能存在 target 第一次出现的位置。
因此下一轮搜索区间是 [mid + 1..right],此时设置 left = mid + 1;
情况 ② :当 nums[mid] == target 时
- mid 有可能是 target 第一次出现的位置;
- mid 的左边也有可能是 target 第一次出现的位置;
- mid 的右边一定不是 target 第一次出现的位置。
因此下一轮搜索区间在 [left..mid],此时设置 right = mid。
情况 ③ :当 nums[mid] > target 时
- mid 一定不是 target 第一次出现的位置;
- mid 的右边也一定不是 target 第一次出现的位置;
- mid 的左边有可能是 target 第一次出现的位置,因此下一轮搜索区间在 [left..mid - 1],此时设置 right = mid - 1。
重点在这里:把情况 ② 和情况 ③ 合并,即当 nums[mid] >= target 的时候,下一轮搜索区间是 [left..mid],此时设置 right = mid - 1。这样做是因为:只有当区间分割是 [left..mid] 和 [mid + 1..right] 的时候,while(left < right) 退出循环以后才有 left == right 成立。
findLastPosition() 也可以类似分析,这里省略。
在本题解中,while(left < right) 只表示退出循环以后有 left == right 成立,不表示搜索区间为左闭右开区间,本题解以及我的其它题解中,对循环不变量的定义均为:在 nums[left..right] 中查找目标元素。
153. 寻找旋转排序数组中的最小值
二分法
旋转排序数组,几乎就是有序的数组,可以通过比较特定位置的元素的值判断达到减治的效果(逐渐缩小搜索区间)
很自然的,会看 中间数 (位于待搜索区间中间位置的元素),由于不是有序数组,因此不能称之为中位数。
另外,待搜索区间头和尾的元素位置特殊的元素,有两个比较自然的思路是:
- 思路1:看看当前搜索区间的 左边界 和 中间数,是不是可以缩小搜索区间的范围
- 思路2:看看当前搜索区间的 右边界 和 中间数,是不是可以缩小搜索区间的范围
要想清楚不妨举几个例子:
例1:$[1,2,3,4,5]$
例2:$[2,3,4,5,1]$
这两个例子的 中间数 都比左边界大,但 旋转排序数组 的最小值 一个在中间数的左边,一个在右边,因此思路1不合适。
针对思路2,依然写两个例子,这两个例子分别是 中间数比右边界大 和 中间数比右边界小,看看能不能推导出一般化的结论。
例3:$[7,8,9,10,11,12,1,2,3]$
中间数 11 比右边界 3 大,因此中间数左边的数(包括中间数)都不是 旋转排序数组的最小值,因此下一轮搜索的区间是 $[mid+1, right]$ ,将下一轮搜索的左边界设置成中间数位置 +1,即 $left = mid+1$
例4:$[7,8,1,2,3]$
中间数 1 比右边界3小,说明中间数到右边界是递增的,那么中间数右边的(不包括中间数)一定不是 旋转数组的最小值,可以排除,但中间数有可能是整个数组中的最小值,就如本例,因此, 在下一轮搜索区间是 $[left,mid]$,于是把右边界设置为 $right=mid$
从例 3 和例 4 可以看出,不论中间数比右边界大,还是中间数比右边界小,我们都可以排除掉将近一半的元素,把原始问题转换成一个规模更小的子问题,这正是「减而治之」思想的体现,因此思路 2 可行。
1 | class Solution { |
分治法
分治法是将原问题划分成若干与原问题同结构且规模更小的子问题,等到这些子问题解决了以后,原问题也得到了
1 | class Solution { |
154. 寻找旋转排序数组中的最小值 II
有序数组可能存在重复值
二分法
- 当中间数比右边界表示的数大的时候,中间数一定不是目标数
- 当中间数比右边界表示的数小的时候,中间数就可能是目标数
- 当中间数比有边界表示的数相等时:此时只把右边界排除掉就好
1 | class Solution { |
分治法
分治法将原问题划分成若干与原问题同结构且规模更小的子问题,等到这些子问题解决了以后,原问题也得到了解决。
1 | class Solution { |
33. 搜索旋转排序数组
题中数组不存在重复元素。
根据示例 [4, 5, 6, 7, 0, 1, 2] ,自己手写几个旋转数组。不难发现:将待搜索区间从中间一分为二,位于中间的元素 nums[mid] 一定会落在其中一个有序区间里。需要分类讨论。
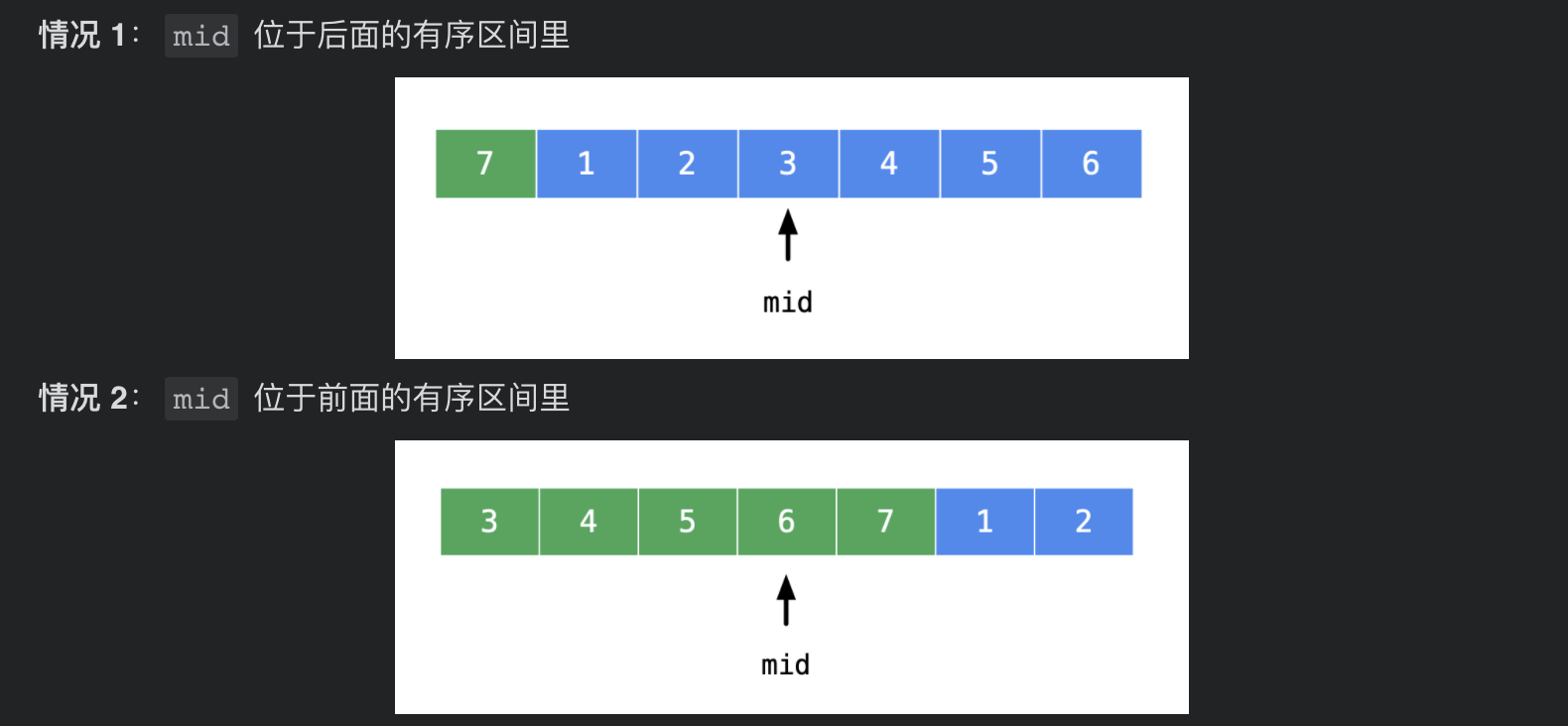
中间元素和右边界的关系 为例,其它情况类似。由于不存在重复元素,所以它们的关系不是大于就是小于。
关键:把比较好些的判断(target 落在有序的那部分)放在 if 的开头考虑,把剩下的情况放在 else 里面。
1 | class Solution { |
4. 寻找两个正序数组的中位数
解题核心思想:
- 使用二分查找确定两个有序数组的 【分割线】,中位数就由分割线左右两侧的元素决定;
- 分割线满足这样的性质:左右两边元素个数相等(这里忽略两个数组长度之和奇偶性的差异)
- 分割线左边所有元素 小于等于 分割线右边所有算是
- 由于分割线两边元素个数相等,移动分割线就会有【此消彼长】的现象,所以使用二分法去定位
这条分割线的特点是:
- 当数组的总长度为偶数的时候,分割线左右的数字个数总和相等;当是奇数时,分割线左边数字比右边仅仅多1
- 分割线左边的所有元素都小于等于分割线右边的所有元素
如果找到这条分割线,那么中位数可以确定下来,同样得分奇偶性:
- 当数组总长度为偶数时,中位数就是分割线左边最大值与分割线右边最小值的平均数
- 当是奇数时,中位数就是分割线左边的最大值,因此在数组长度为奇数时,中位数就是分割线左边的最大值。
因为两个数组本别是有序数组,因此,我们只需要判定交叉的关系中,是否满足左边依然小于等于右边即可,即
- 第1个数组分割线左边的第1个数小于等于第2个数组分割线右边的第一个数
- 第2个数组分割线左边的第1个数小于等于第1个数组右边的第1个数
通过不断缩减搜索区间确定分割线的位置
- 当数组总长度为偶数时,左边一共有 $\frac{len(nums1) + len(nums2)}{2}$ 个元素
- 当数组总长度为奇数时,左边一共有 $\frac{len(nums1) + len(nums2)}{2}+1$个元素
奇数的时候是除以2向下取整,所以计算左边元素总数的时候就得 +1。也可以向上取整
这里用到了一个小技巧,把下取整,修改为上取整的时候,只需要在被除数的部分,加上除数减 1 即可
这样问题就转化为,我们在其中一个数组找到 $i$ 个元素,则另一个数组的元素个数就一定是 $\frac{len(nums1) + len(nums2) +1}{2} - i$
于是怎么找到 $i$ 是要解决的问题。
找 i 个元素,我们通常的做法是找索引为 i的元素,因为下标是从 0 开始编号,因此编号为 i 的元素,就刚刚好前面有 i 个元素。因此,i 就是第 1 个数组分割线的右边的第 1 个元素。
下面我们来看怎么找 i,需要分类讨论。
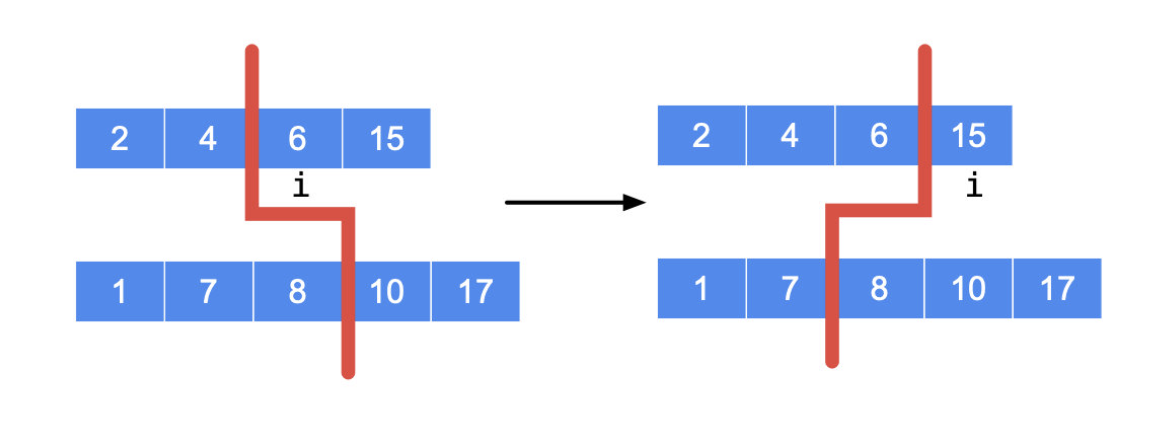
情况1:如下图,此时分割线左边元素比右边多1,但是第一个数组分割线比右边第一个数6小于第二个数组分割线左边第一个数8,说明第一个数组左边的数少了,分割线要右移。
情况 2:如下图所示,此时分割线左边的元素总数比右边多 1,但是第 一 个数组分割线左边第 1 个数 8 大于第 二 个数组分割线左边第 1 个数 7。说明,第 1 个数组左边的数多了,分割线要左移。
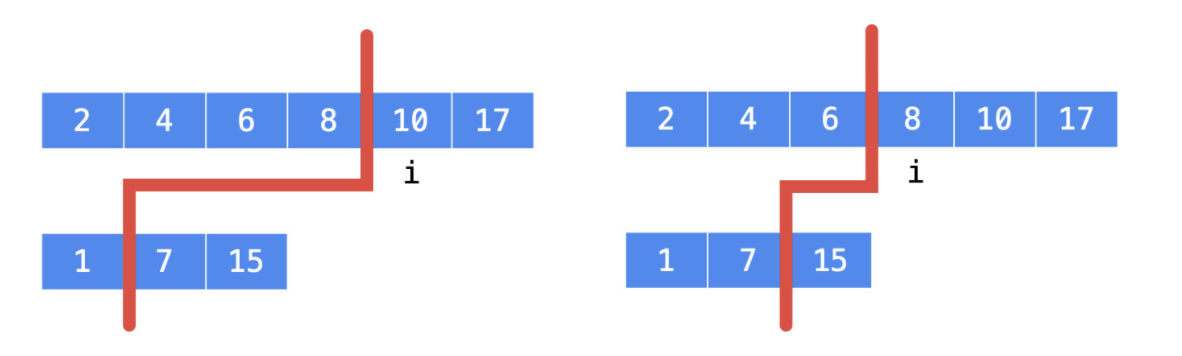
就是在这种不断缩小搜索范围的方法中,定位我们要找的 i 是多少。
极端情况
这里要注意一个问题,那就是我们要在一个短的数组上搜索 i 。在搜索的过程中,我们会比较分割线左边和右边的数,即 nums[i]、 nums[i - 1]、 nums[j]、 nums[j - 1],因此 这几个数的下标不能越界。
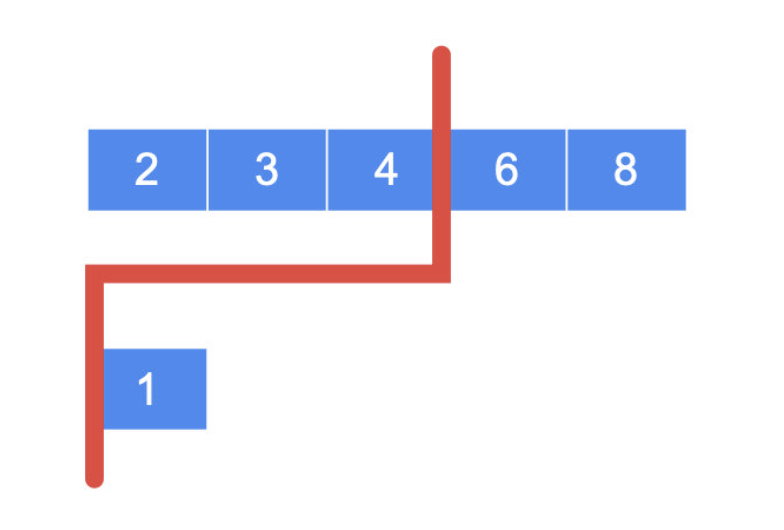
此时,分割线在第 2 个数组的左边没有值,会导致 nums2[j - 1] 的访问越界。因此我们必须在短的数组上搜索 i 。i 的定义是分割线的右边,而它的左边一定有值。这样就能保证,分割线在第 2 个数组的左右两边一定有元素,即分割线一定可以在第 2 个数组的中间切一刀。
即使我在短数组上搜索边界 i ,还真就可能遇到 i 或者 j 的左边或者右边取不到元素的情况,它们一定出现在退出循环的时候。
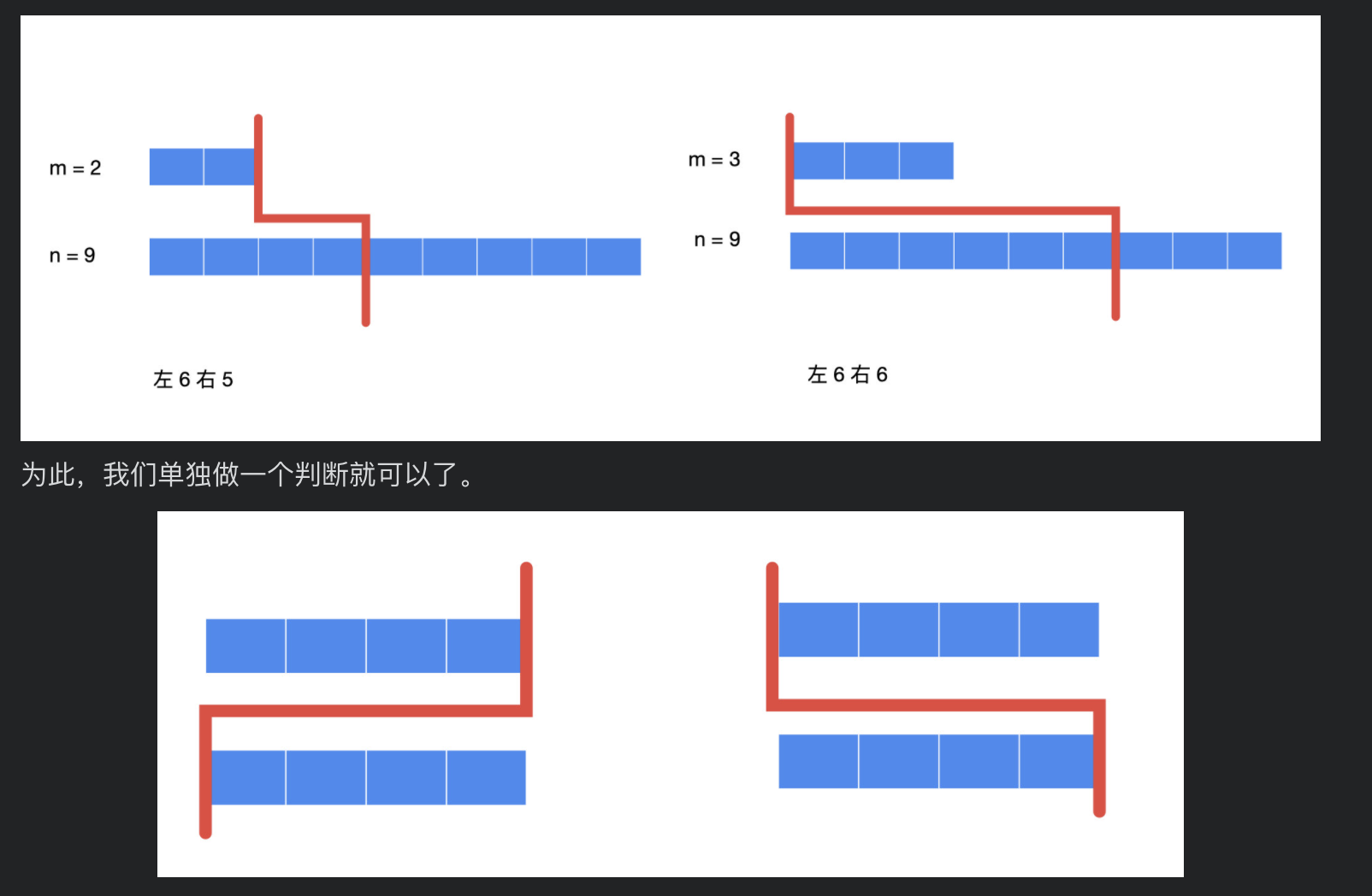
最后,我们把关心的「边界线」两旁的 44 个数的极端情况都考虑一下:
- 考虑nums1:
- 当 i=0 时,对应上图右边,此时数组 nums1 在红线左边为空,可以设置 num1_left_max = 负无穷,这样在最终比较的时候,因为左边粉红色部分要选择出最大值,它一定不会被选中
- 当 i=m 时,对应上图左边,此时数组 nums1 在红线右边为空,可设置 num1_right_min = 正无穷,这样在最终比较的时候,因为右边蓝色部分要选择出最小值,它一定不会被选中,于是能兼容其它情况。
- 数组nums2 同理
1 | class Solution { |
 wechat
wechat alipay
alipay





