28实现strStr()——KMP
28实现strStr()——KMP
28. 实现 strStr()
朴素解法
枚举原串 ss 中的每个字符作为【发起点】,每次从原串中的【发起点】和匹配串的首位,开始尝试匹配:
- 匹配成功:返回本次匹配的原串【发起点】
- 匹配失败:枚举原串的下一个【发起点】,重新尝试匹配
1 | public int Strstr(String haystack, String needle){ |
时间复杂度: 枚举复杂度为 $O(n-m)$ , 构造比较时间复杂度为 $O(m)$, 整体复杂度 $O((n-m)*m)$
KMP
KMP 算法是一个快速查找匹配串的算法,他的作用是:如何快速在【原字符串】中找到【匹配字符串】。
上述的朴素解法,不考虑剪枝的话是 $O(m*n)$ 的,而KMP算法的复杂度为 $O(m+n)$
KMP 之所以能够在 $O(m+n)$ 复杂度内完成查找,是因为其能在【非完全匹配】的过程中提取到有效信息进行复用,以减少【重复匹配】的消耗。
1. 匹配过程
在模拟KMP匹配过程之前,先建立两个概念:
- 前缀:对于字符串 【abcxxxxefg】,我们称abc属于abcxxxefg的某个前缀
- 后缀:对于字符串【abcxxxxefg】,我们称efg属于abcxxxefg的某个后缀
然后我们假设原串为 【abeababeabf】,匹配串为【abeabf】:
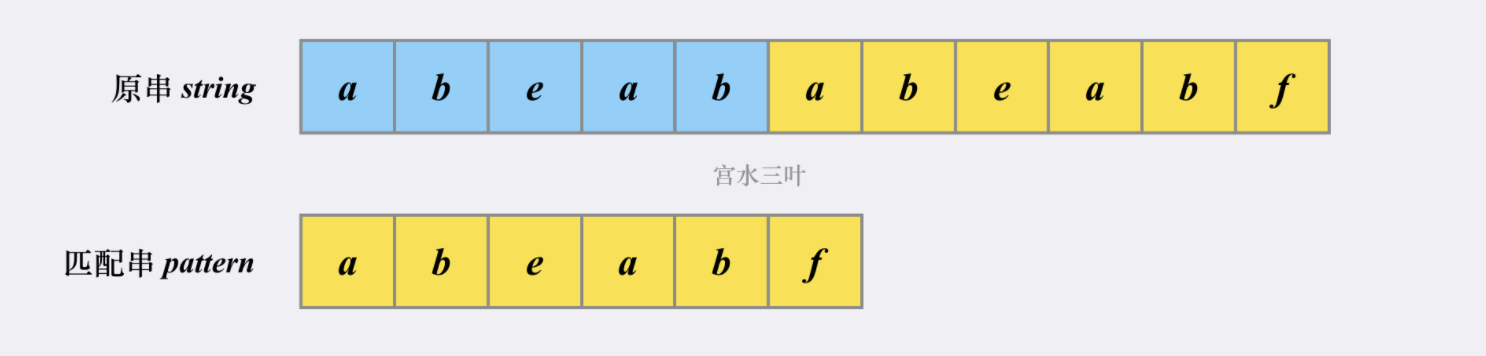
我们可以先看看如果不使用KMP,会如何进行匹配(不使用substring函数的情况下)
首先在【原串】和【匹配串】分别各有一个指针指向当前匹配的位置。
首次匹配的【发起点】是一个字符 a。显然,后面的【abeab】都是匹配的,两个指针会同时往右移动(黑标)
在都能匹配上【abeab】的部分,【朴素匹配】和【KMP】并无不同。
知道出现第一个不同位置(红标):
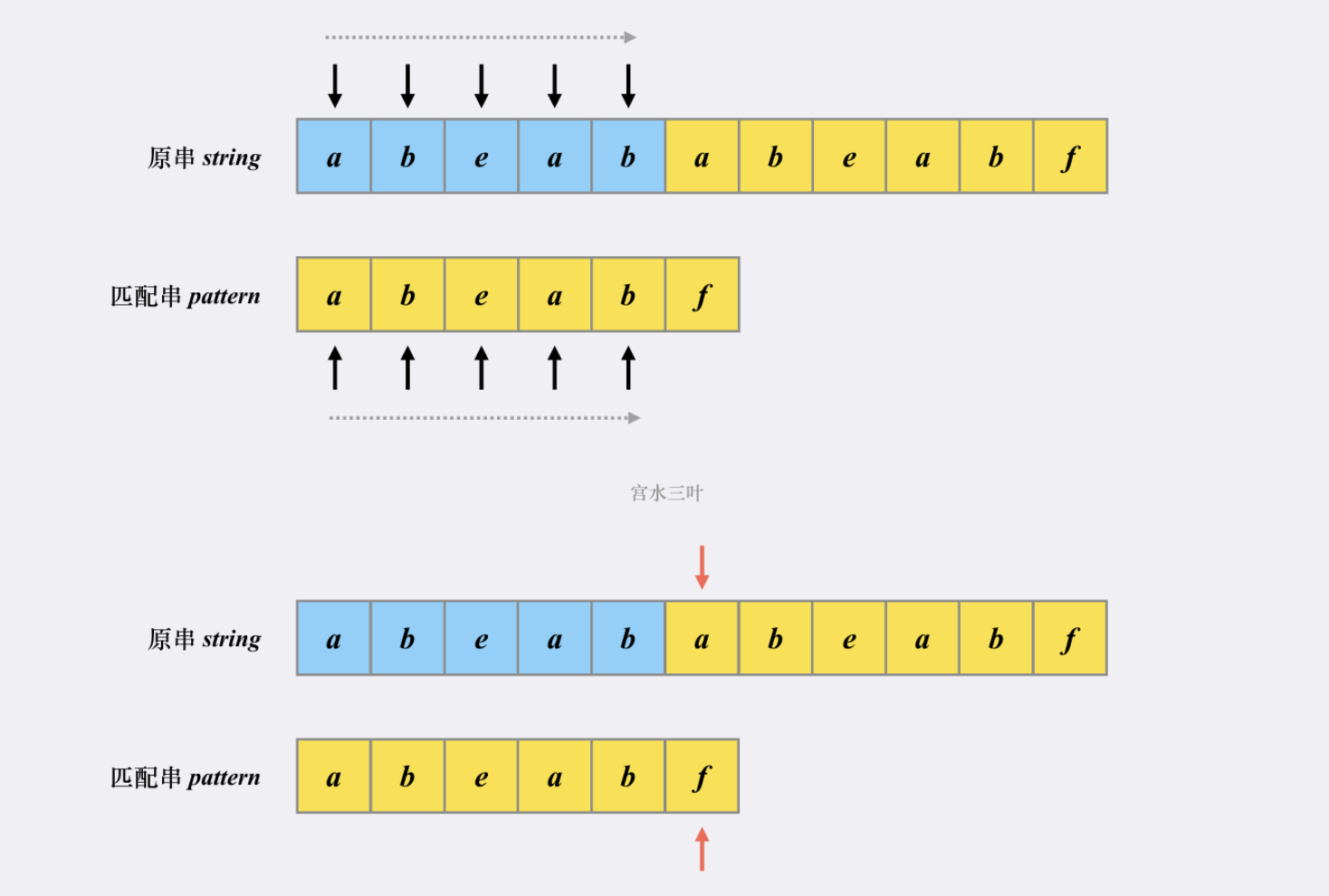
接下来,是【朴素匹配】和【KMP】出现不同的地方:
朴素匹配的逻辑:
- 将原串的指针移动至本次【发起点】的下一个位置(b字符处);匹配串的指针移动至起始位置。
- 尝试匹配,发现对不上,原串的指针会一直往后移动,直到能够匹配串对上位置
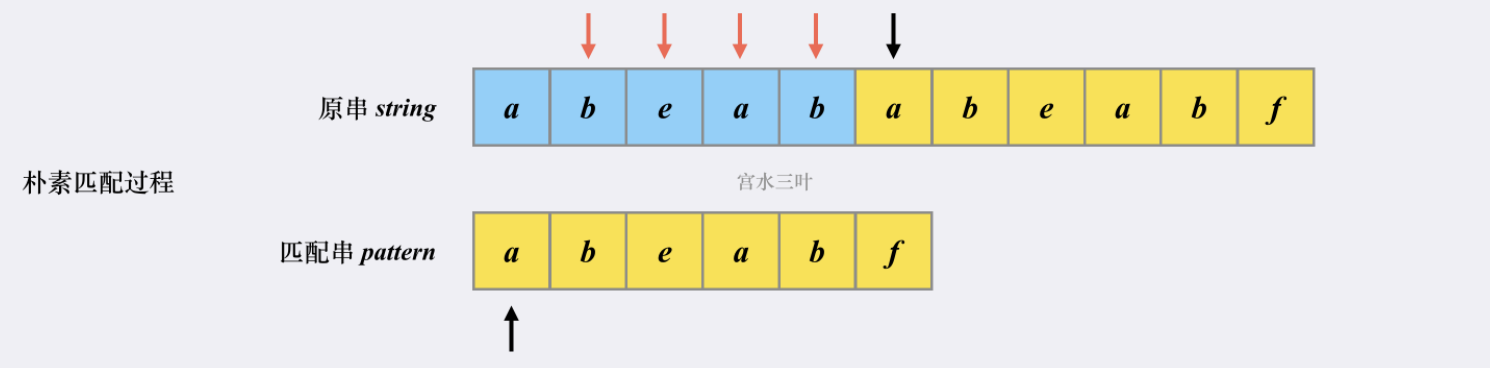
也就是说,对于【朴素匹配】而言,一旦匹配失败,将会将原串指针调整至下一个【发起点】,匹配串的指针调整至起始位置,然后重新尝试匹配。
这也就不难理解为什么【朴素匹配】的复杂度是 $O(m*n)$ 了
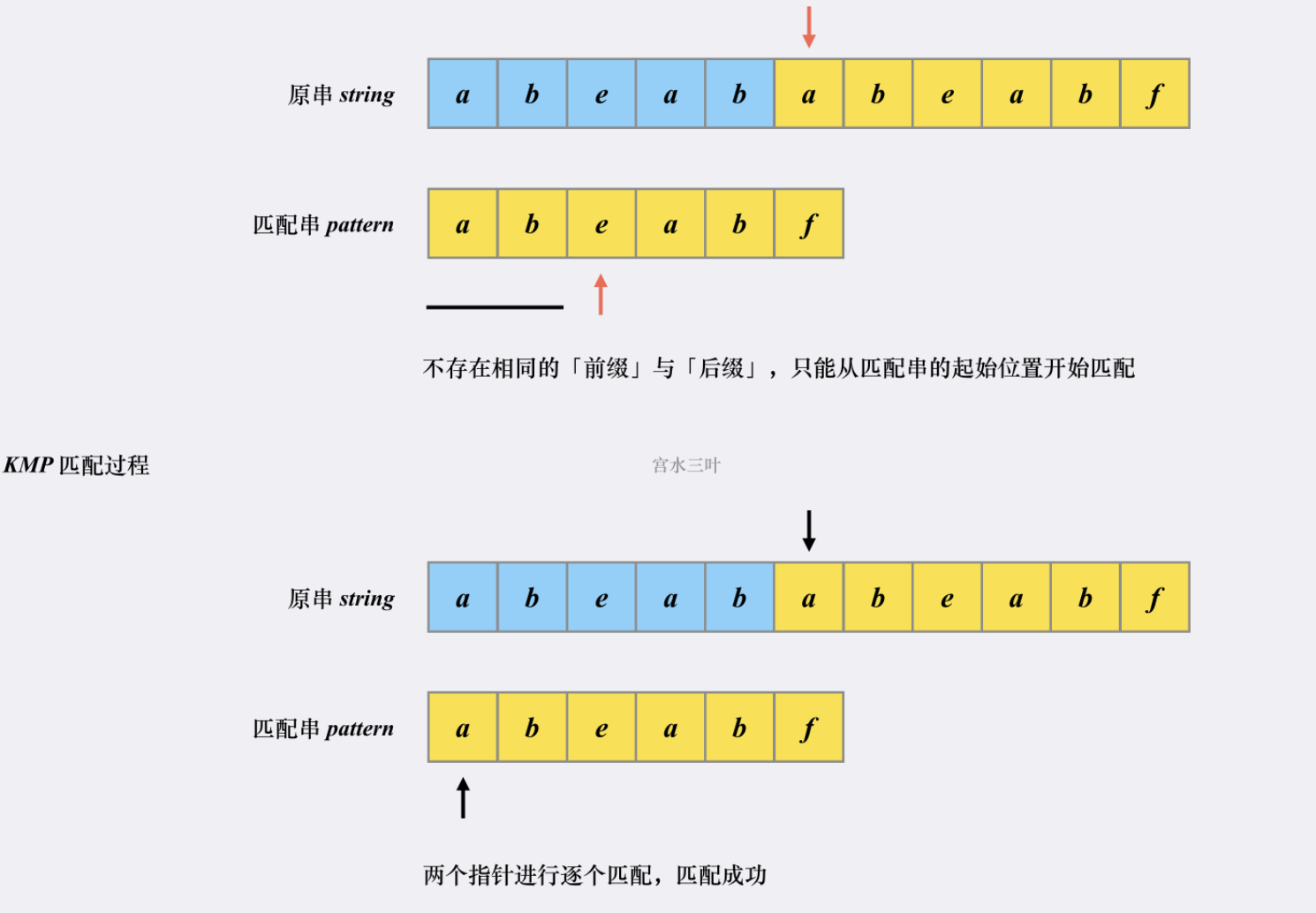
然后看看KMP匹配过程:
首先匹配串会坚持已经匹配成功的部分中是否存相同的【前缀】和【后缀】。如果存在,则跳转到【前缀】的下一个位置继续往下匹配:
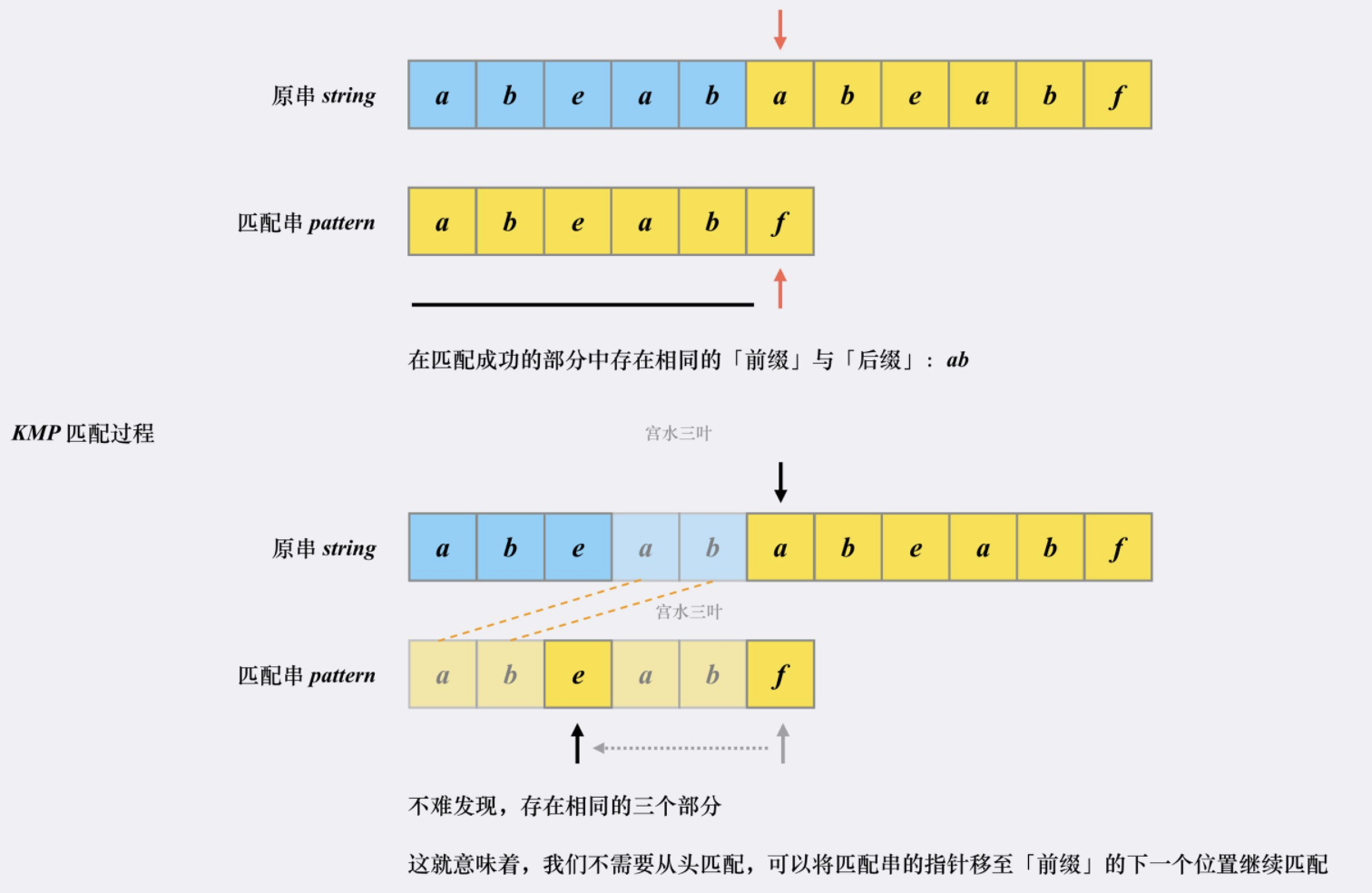
跳转到下一匹配位置后,尝试匹配,发现两个指针的字符对不上,并且此时匹配串指针前面不存在相同的【前缀】和【后缀】,这个时候只能回到匹配串的起始位置重新开始:
到这里,你应该清楚 KMP 为什么相比于朴素解法更快:
- 因为KMP利益已匹配的部分中相同的【前缀】和【后缀】来加速下一次匹配
- 因为KMP的原串指针不会进行回溯(没有朴素匹配中回到下一个【起发点】的过程)
第一点很直观,也很好理解。
我们可以把重点放在第二点上,原串不回溯至「发起点」意味着什么?
其实是意味着:随着匹配过程的进行,原串指针不断的右移,我们本质上是不断地在否决一些【不可能】的方案。
当我们的原串指针从 $i$ 位置后移到 $j$ 位置,不仅仅代表这【原串】下标范围 $[i,j)$ 的字符与【匹配串】匹配或者不匹配,更是在否决那些以【原串】下标范围为 $[i,j)$ 为【匹配发起点】的子集。
2. 分析实现
先分析一下复杂度,如果严格按照上述解法的话,最坏情况下我们需要扫描整个原串,
复杂度为$O(n)$,同时在每一次匹配失败时,去检查已匹配部分的相同【前缀】和【后缀】,跳转到对应的位置,如果不匹配则再检查前面部分是否有相同【前缀】和【后缀】,再跳转到相应的位置。。。这部分的复杂度是$O(m^2)$,因此整体的复杂度是 $O(nm^2)$,而我们的朴素解法是 $O(mn)$ 的
说明还有些性质我们没有用到。
显然,扫描完整原串操作是不可避免的,我们可以优化的只能是【检测已匹配部分的相同前缀和后缀】这一过程。
再进一步,我们检测【前缀】和【后缀】的目的其实是【为了确定匹配串中的下一段开始匹配的位置】。
同时,我们发现对于匹配串的任意一个位置而言,由该位置发起的下一个匹配点位置其实与原串无关。
举个例子,对于匹配串【abcabd】的字符 d 而言,由它发起的下一个匹配点跳转必然是字符 c 的位置。因为字符d位置的相同【前缀】和【后缀】字符ab的下一位置就是字符 c
可见从匹配串某个位置跳转到下一个匹配位置这一过程是与原串无关的,我们将这一过程称为找 next 点。
显然我们可以预处理出 next 数组,数组中每个位置的值就是该下标应该跳转的目标位置(next 点)
当我们进行了这一步优化后,复杂度是多少?
预处理next数组的复杂度未知,匹配过程最多扫描完整个原串,复杂度为 $O(n)$
因此如果我们希望整个KMP过程是 $O(m+n)$ 的话,那么我们需要再 $O(m)$ 的复杂度内预处理出 next数组
所以我们的重点在于如何在 $O(m)$ 复杂度内处理next数组
3.next数组的构建
如何用 $O(m)$ 的复杂度内被预处理处理的
假设有匹配串 【aaabbab】,我们来看看对应的next 是如何被构建出来的。
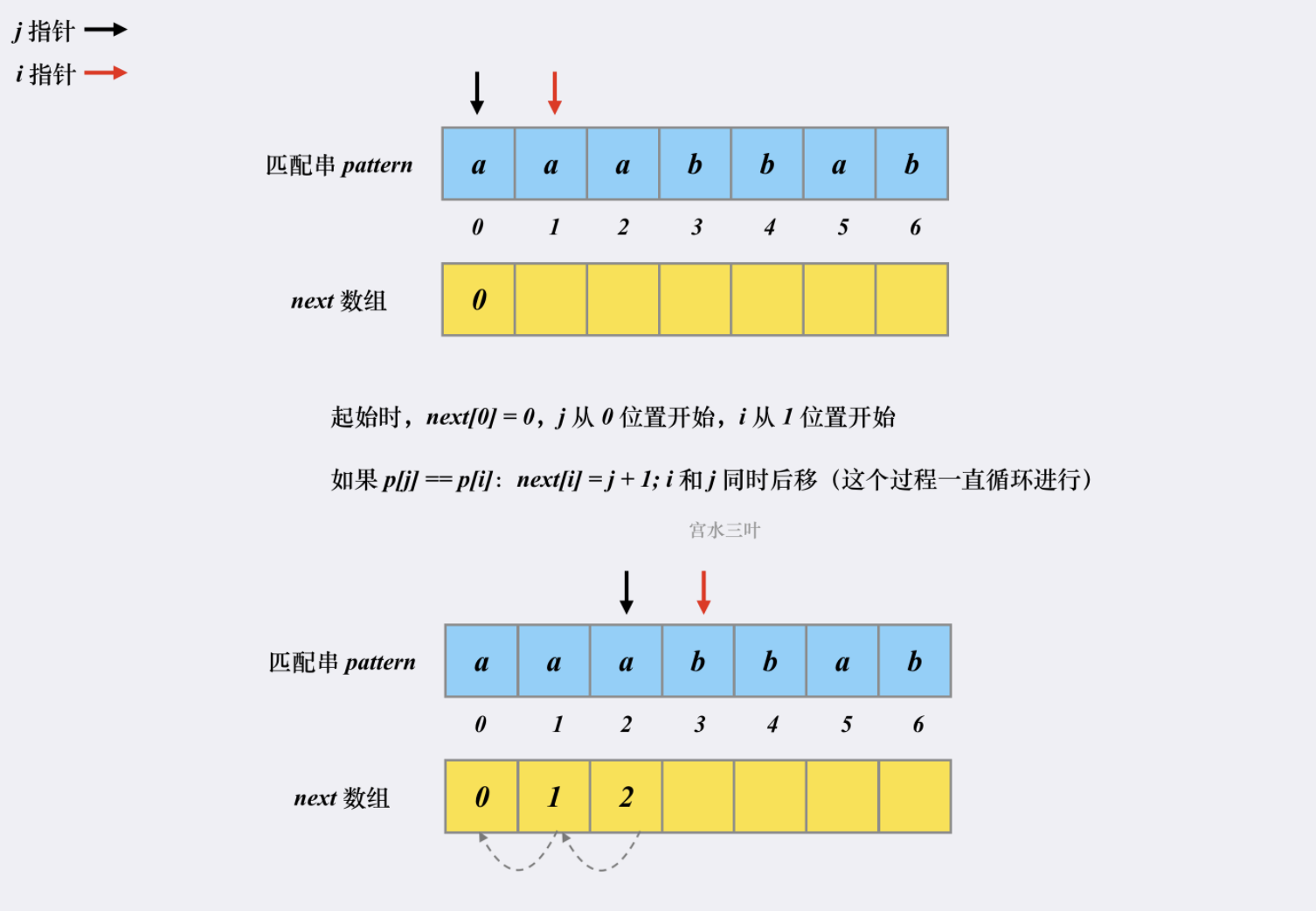
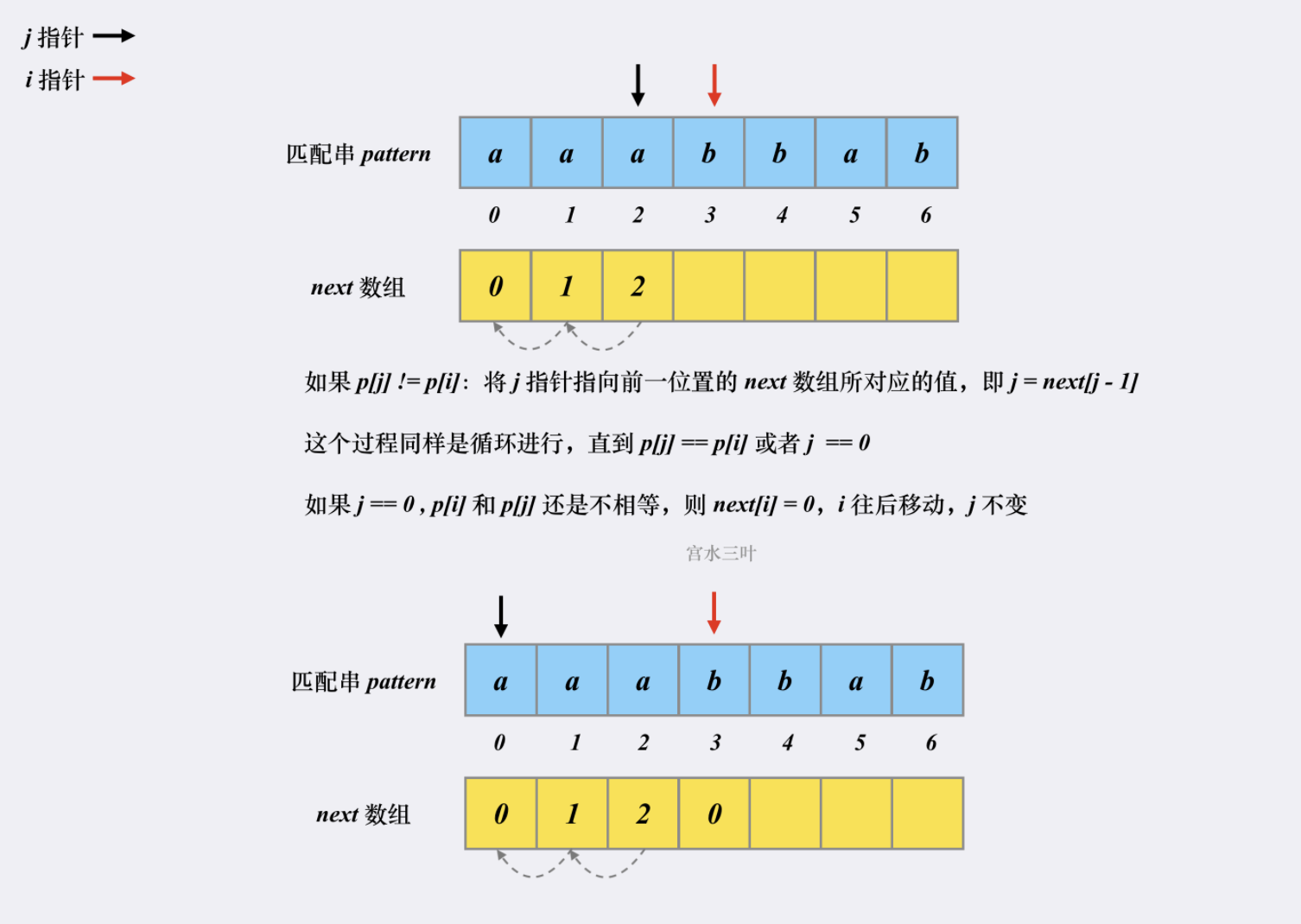
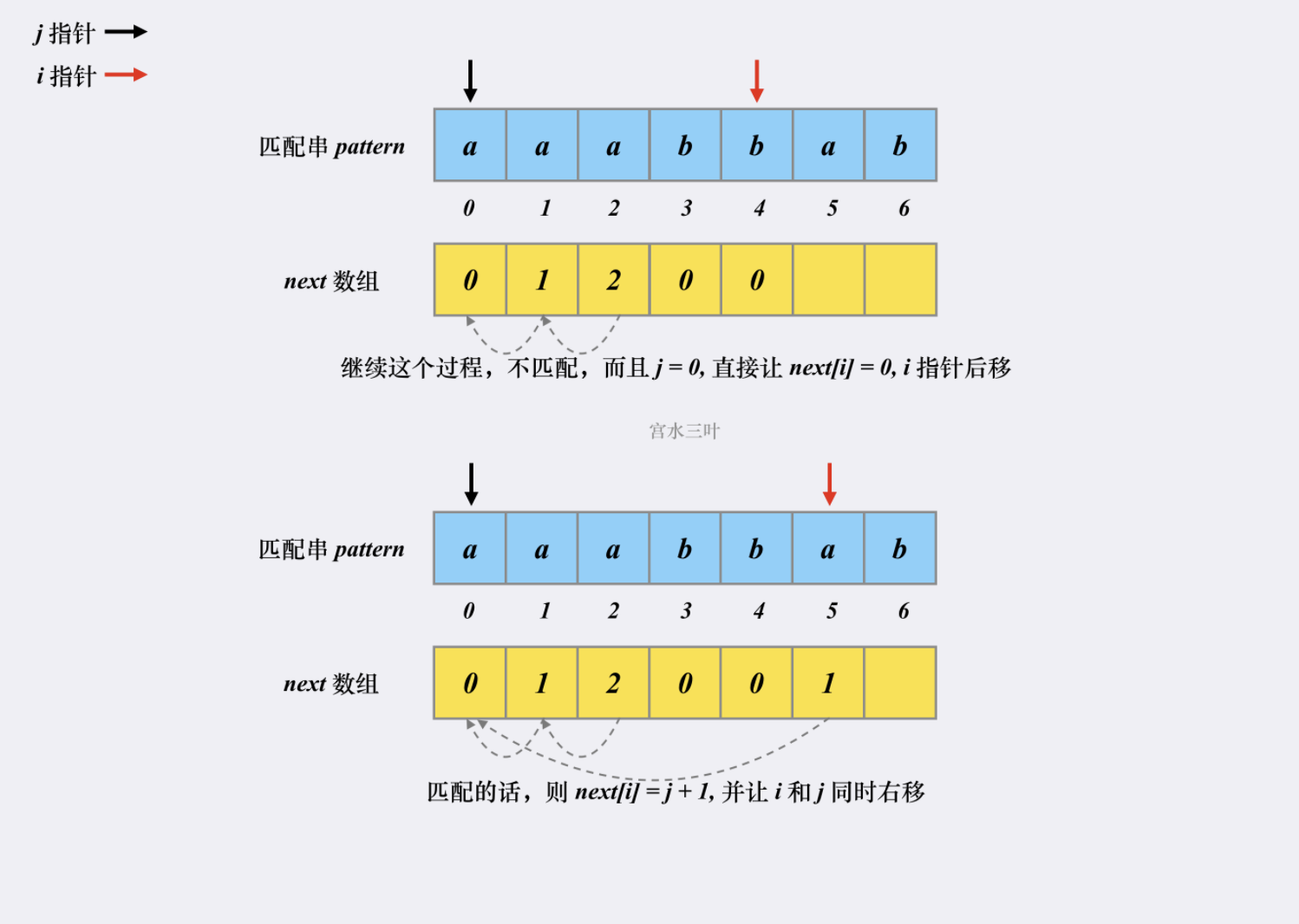
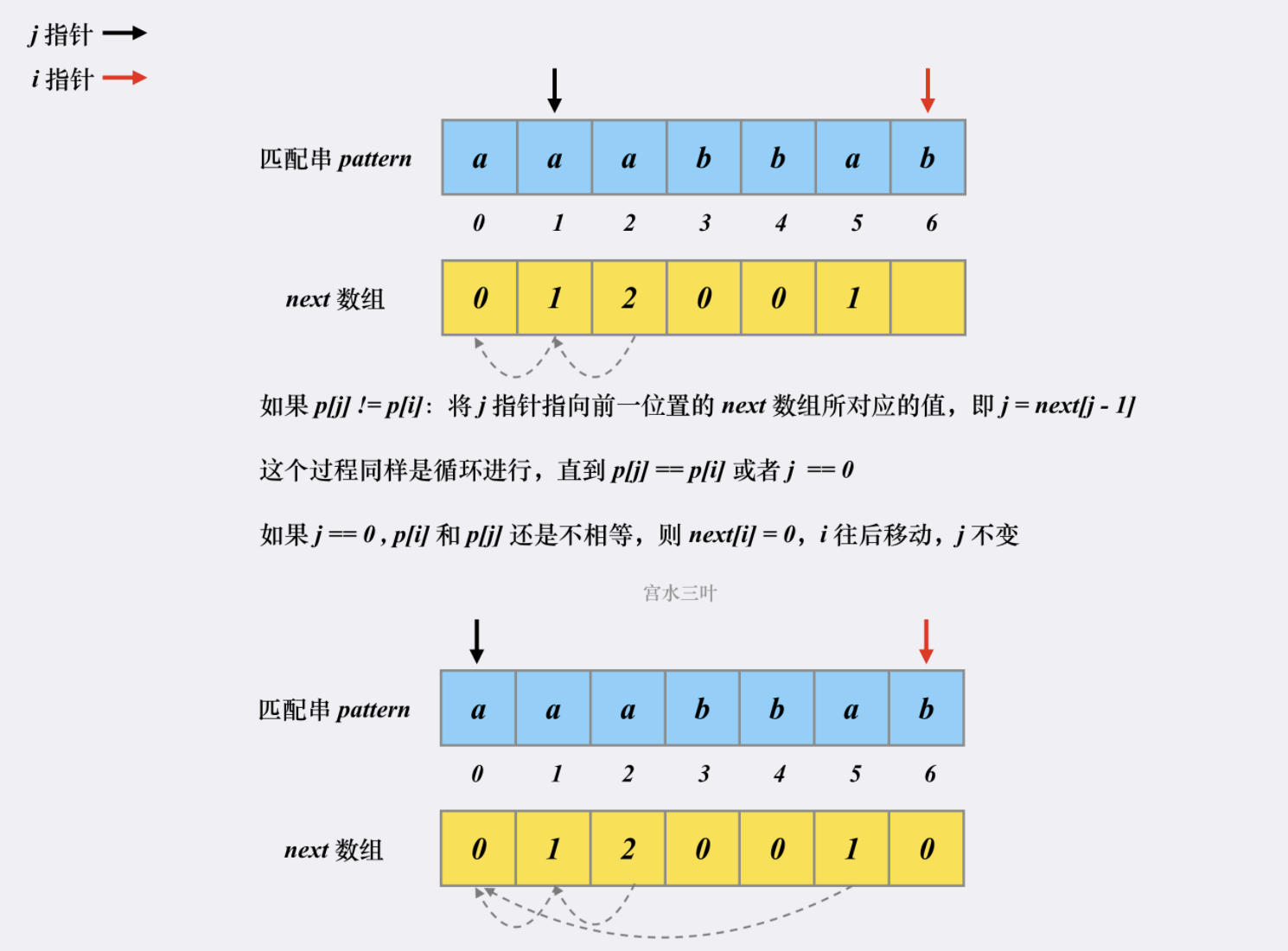
这就是整个 next 数组的构建过程,时空复杂度均为 O(m)。
至此整个 KMP 匹配过程复杂度是 O(m + n) 的。
4.代码实现
在实际编码时,通常我会往原串和匹配串头部追加一个空格(哨兵)。
目的是让 j 下标从 0 开始,省去 j 从 -1 开始的麻烦。
整个过程与上述分析完全一致,一些相关的注释我已经写到代码里。
1 | public int strStr(String ss, String pp){ |
 wechat
wechat alipay
alipay





