Optimizing Reusable Knowledge for Continual Learning via Metalearning
Optimizing Reusable Knowledge for Continual Learning via Metalearning
当网络的权重在新任务的训练过程中被覆盖,从而导致忘记旧信息时,就会发生灾难性遗忘。
为了解决这个问题,作者提出了MetA Reusable Knowledge: MARK, 它提高了权重的可重用性,而不是在学习新任务时被覆盖。
MARK在任务之间保留一组共享权重,将这些共享的权重设想为一个公共知识库(KB),它不仅用于学习新任务,而且在模型学习新任务时还会丰富新知识。
关键组成部分有两个方面:
- 1.元学习方法提供了用新知识逐步丰富知识库的关键机制,并促进了任务之间的权重可重用性。
- 2.一组可训练掩码提供了从知识库相关权重中有选择地选择来解决每个任务的关键机制。
以往预防灾难性遗忘(CF)的工作主要遵循两种策略:
- 1.避免修改对解决先前任务至关重要的参数。具体地说,当面对新的任务时,正则化项确保了关键参数的修改尽可能少。一般而言,该方法在任务较少的问题上表现出令人满意的性能,但是当任务数量增加时,诸如权值的累积漂移和它们之间的干扰等问题使得该方法难以扩展。
- 2.模型的体系结构更改。这包括保留部分网络容量来学习每个任务的方法,以及使用特殊记忆单元来回忆以前任务中的关键训练样本的方法。这些方法的主要问题是额外的模型复杂性并且需要一种有效的方法来回忆以前任务中的关键信息。
与这些先前的策略相反,当学习新任务时,人类会不断地将先前的经验与新情况联系起来,增强先前的记忆,这有助于缓解CF问题。
MASK 一种基于学习策略的新模型,它不是减轻权重覆盖或学习不同任务的独立权重,而是使用元学习方法来促进任务之间的权重可重用性。特别地,将这些共享的权重设想为一个公共知识库(KB),它不仅用于学习新任务,而且在模型学习新任务时还会丰富新知识。从这个意义上说,MASK背后的KB不是由以向量编码信息的外部存储器给出的,而是由以其权重编码共享信息的可训练模型给出的。作为查询该KB的补充机制,MASK还包括一组可训练掩码,其负责实施选择性寻址方案来查询KB。
因此,为了构建和查询其共享知识库,MARK 使用了两种互补的学习策略。
- 1、元学习技术提供了实现两个目标的关键机制:
- 鼓励对多个任务有用的权重更新
- 在模型学习新任务时用新知识丰富知识库。
- 2、一组可训练的掩码提供了从知识库相关权重中选择性地选择来解决每个任务的关键机制。
MARK的工作方式是,首先通过检测知识库中学习的每个模式的重要性的函数强制模型重用当前知识,然后如果过去的知识不足以成功执行任务,则扩展其知识。
Continual Learning Scenario
每个任务 $t$ 由新的数据分布 $D^t = (X^t, Y^t,T^t)$ 组成,其中 $X^t$ 是输入样例,$Y^t$ 是任务标签, $T^t$ 是任务ID。
目标是学习一个分类模型 $f : X\to Y$ 使用来自T个任务序列的数据:$D = {D^1,…,D^T}$
Method
两个主要挑战:
- 如何增量地构建此知识库?(一种称为情景训练的元学习策略)
- 如何查询此知识库以访问相关的知识片段?(为每个任务训练掩码生成函数)
Model Architecture
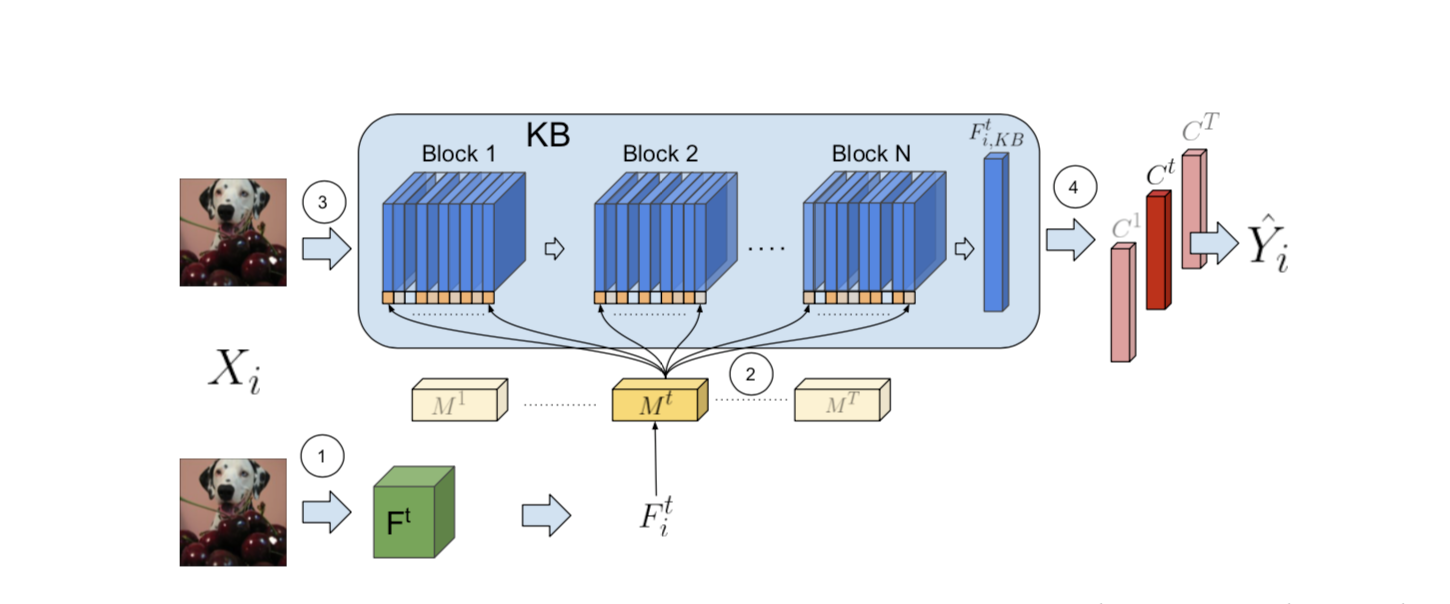
给定来自任务 $T$ 的输入 $X_i$,使用特征提取器 $F^t$ 来获得 $F_i^t$。
然后将 $F_i^t$ 传递给mask函数 $M^t$ 以生成mask $M_i^t$。
之后,相同的输入 $X_i$ 进入 KB,它具有由 $M_i^t$ 调制的中间激活
最终,调制的特征经过任务相关的分类器 $C^t$,该分类器执行对 $X_i$ 的类别预测。
模型的主要模块:
Feature Extractor ($F^t$) : 该模块负责为每个输入 $X_i$ 提供初始嵌入,即 $F^t$ 取输入$X_i$ 并输出向量表示$F_i^t$。重要的是要注意,模型 $F^t$ 可以在任务之间共享,也可以特定于每个任务。
Knowledge Base (KB) : 这是MASK背后的主要模块。当模型面临新的任务时,它负责积累相关知识。实现时使用了带B blocks的卷积架构。模型的这一部分在任务之间共享。
- Mask-Generating functions ( $M^t$): 将特征向量 $F_i^t$ 作为输入,并为 KB 的每个 block 生成一个实例和依赖于任务的掩码 $M_i^t$。 每个掩码由一组标量组成,每个标量用于KB的卷积块中的每个通道,其乘以每个通道的激活。这些掩码对于选择与每个实例和任务相关的知识至关重要。在实施中,作者使用全连接层。
- Classifier ( $C^t$) : 这些模块对应于依赖于任务的分类头。 它输入$ F^t_{i,KB}$ , 是通过对 KB 的最后一个 block 的输出进行展平操作而给出的。 给定输入 $X_i$ 的任务 ID,相应的 head 输出模型预测。 实现中使用全连接层。
MARK Training
首先是通过在第一个任务中端到端地训练知识库来初始化知识库,而不使用元学习和掩码函数。
对于分类任务,首先使用卷积神经网络的规则训练过程来执行知识库初始化。之后,我们交替三个主要步骤对Mark进行每个任务的顺序训练:
- KB Querying : 训练任务相关的掩码生成函数,这些函数用于使用向量 $F_i^t$ 来查询知识库。另外,我们同时训练当前任务的任务分类器。请注意,撇开知识库初始化不谈,在此步骤中,每个新任务仅使用以前任务积累的知识进行训练。
- KB Update: 使用元学习策略来更新知识库中的权重。该方案允许促进知识库更新,有利于获取可重用的知识以面对新任务。
- KB Querying : 在使用来自当前任务的知识更新知识库之后,我们重复查询过程,使用这些新知识来优化掩码生成函数和任务分类器。注意,在此步骤中,KB保持固定。
前面三个步骤的应用背后的直觉如下:
最初使用从先前任务中积累的知识来查询知识库。 这迫使掩码函数和分类器重用可用知识。 当该知识耗尽时,我们继续将当前任务中的知识添加到知识库中。 最后,我们利用这个新更新的知识库来获得给定任务的最终掩码函数和分类器。
KB Querying
一旦我们通过使用特征提取器 $F^t$ 获得特征向量,模型就可以了解知识库中哪些模块能够最好地解决当前任务。在这个训练阶段,模型训练函数学习如何使用知识库中可用的知识,只关注重用以前任务中的知识,而不修改KB。特别是在这一步中,我们只训练 $M^t$ 和 $C^t$。两者都经过端到端训练,同时保持KB权重冻结。
当我们为模型的每个中间激活生成掩码时,严格地说,我们总共有B个掩码生成函数。然而,为了便于表示,我们将所有此类函数都包含在 $M^t$下,并将其输出视为这些 $B$ 函数结果的拼接。
下式表明函数$M^t$,其中在给定来自任务 $t$ 的输入$X_i$的情况下获得掩码 $M_i^t$:
在此过程中生成的遮罩具有两种效果:
- 给出KB中特定模块对当前输入的重要性的信号
- 确保梯度更新在真正重要的地方进行。
如果激活映射与某个任务无关,则相应掩码的值将为零,从而使与该激活相关联的梯度更新也为零。
KB Update
这个训练步骤的目的是将当前任务中的新知识添加到KB。为了实现这一点,使用元学习作为一种方式,迫使模型捕获可以重用的知识,以面对新的任务。下图,训练Mark的元学习过程的示意图。这个过程是 Reptile的改编
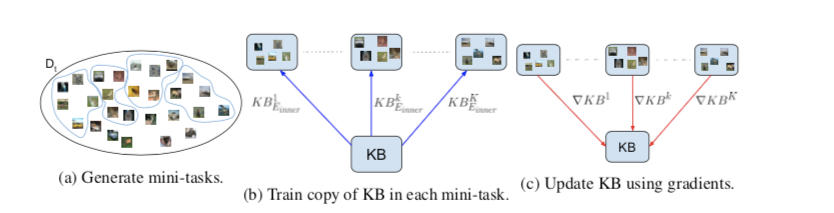
给定任务t,随机生成一组K个小任务,其中每个小任务由来自原始任务的类的子集组成。
对于每个小任务,我们为固定数量的epoch训练当前知识库的独立副本,从而生成K个模型。
然后,使用一组保持训练样本计算每个模型的损失函数的梯度。
最后,使用这些梯度的加权平均值来更新KB。
具体地说,创建了一组K个小任务,其中每个小任务包括从当前任务中随机抽样一组H个类和每个类的h个训练实例。
这允许我们创建一个与主任务不同的小任务,找到不特定于它的权重。使用 $E_{inner}$ epochs的每个小任务训练模型的一个副本。将为e个epochs 训练的副本 k 称为 $KB^{k}_e$。对于每个小任务,使用一个临时分类器 $C^k$,该分类器由 $C^t$参数初始化。在内部循环的最终迭代之后,丢弃这个分类器。
与MAML一样模型训练包括两个嵌套循环,一个内循环一个外循环。内循环负责为当前小任务训练我们的知识库副本,而外循环负责按照梯度方向更新知识库权重,从而快速适应新的小任务。
在每个内循环期间,$KB^k$ 和 $C^k$ 被端到端地训练以用于 $E_{inner}$ epochs。
下式模拟外循环并更新 KB,具体地说,对于每个k,平均 $KB^k_0$之前的 KB 参数的差异:
和Reptile 一样梯度更新为每个模型 $KB^k$ 的累积梯度之和的平均值。其中权重 $\gamma_k$ 为:
其中自同一任务 $t$ 的验证批次上的每个模型的精度作为参考。
Results
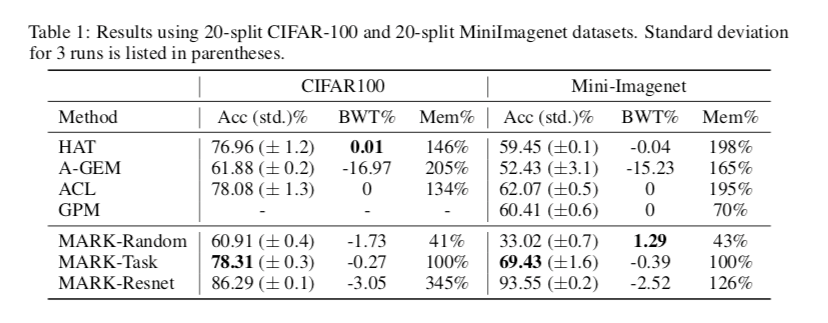
- MARK-Task : 为每个任务训练 $F^t$,在它上面添加一个使用 $D^T$训练的分类器。训练完 $ F^t $后,该分类器被丢弃。
- MARK-Random: $F^t $由一组随机权重组成。所有任务共享相同的 $F^t$。
- MARK-Resnet : 所有任务共享在Imagenet上预先训练的Resnet-18作为特征提取器。
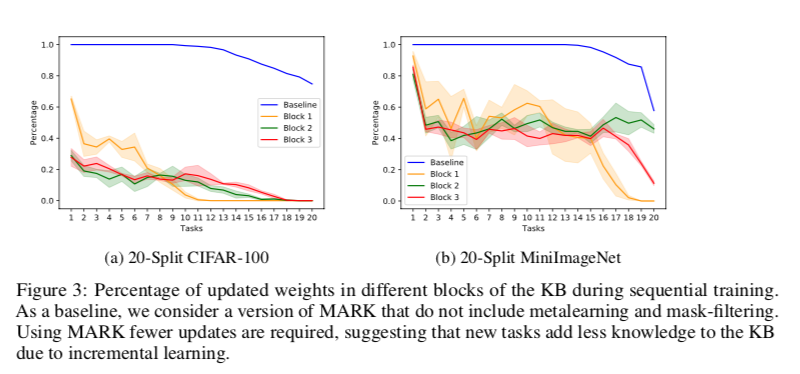
随着训练的任务越多,权重更新的数量就会迅速减少,几乎降到零。此外,在这两个基准中,相对于基线的更新次数都有显著减少。这些结果表明,当使用Mark训练模型时,干扰较少,我们将其归因于其存储可重用知识的知识库。

- Baseline :简单的顺序学习,没有元学习或掩码生成函数。我们使用与知识库相同的架构。
- Baseline + ML : 添加元学习,即知识库更新来改进基线。
- Baseline + Mask : 添加特定于任务的掩码函数来改进基线。
 wechat
wechat alipay
alipay





