Large-scale Extensible User Intent Classification for Dialogue Systems with Meta Lifelong Learning
MeLL: Large-scale Extensible User Intent Classification for Dialogue Systems with Meta Lifelong Learning
用户意图检测(UIC)对于理解他们在对话系统中的需求至关重要。(文本分类)
这是因为不同域中的用户输入可能具有不同的文本分布和目标意图集。随着底层应用程序的发展,新的UIC任务不断涌现。因此,为大规模可扩展UIC开发一个框架至关重要,该框架能够持续适应新任务,并以可接受的参数增长率避免灾难性遗忘。
作者引入Meta Lifelong Learning (MeLL) framework 解决此问题。
在MELL中,基于BERT的文本编码器被用来学习跨任务的健壮文本表示,其被缓慢更新以用于终身学习。
全局和局部记忆网络用来捕获不同类的跨任务原型表示,将其视为元学习者快速适应不同的任务。
此外,应用最近最少使用的替换策略来管理全局记忆,以使模型大小不会随时间爆炸。
最后,每个UIC任务都有自己的特定于任务的输出层,并仔细总结了各种特性。
INTRODUCTION
task-wise UIC models 的缺陷
一个天真的方法是训练task-wise UIC模型。这种方法不适合工业规模的应用,有三个原因:
- 模型参数总数不断增加,与任务数成线性关系。考虑到当前预先训练的语言模型具有数十亿个参数,为UIC训练这样的模型很容易涉及数万亿个参数,从而导致参数爆炸问题。
- 由于跨域的UIC任务有一些相似之处,单任务方法无法从其他任务中学习可转移的知识,这对提高UIC的性能至关重要。(前向后向迁移)
- 当需要维护越来越多的模型时,这些方法不可避免地带来了工程负担。
另一种流行的方法是跨任务的多任务训练,其中利用共享编码器来捕获共同知识,并且每个任务具有其自己的预测头。当一个新的UIC任务出现时,我们可能需要为以前的任务重新训练模型,这不仅计算量大,而且很难保持现有UIC任务的性能稳定。
Liflong learning & Meta learning
近年来,终身学习受到了研究界的广泛关注。它是一种学习范式,它不断积累过去学到的知识,并用它来帮助未来的任务学习。当终身学习应用于大规模EUIC时,当新任务不断到达时,我们只需要维护相对较少的模型参数,从而缓解了参数爆炸效应。
在终身学习中,解决灾难性的遗忘问题是具有挑战性的,即模型在学习新任务时“忘记”如何解决现有任务。这是特别不可取的,因为我们希望在学习新的UIC任务时保持现有任务的性能稳定。
元学习,旨在获得跨任务的元学习者,这样它就可以用很少的数据样本快速适应新任务。通过获取元学习者,可以获取跨不同UIC任务的可迁移知识,并将其传递给新任务。主要的缺点是元学习者(在本文的情况下是BERT模型) 应该分别适应每项任务,无法避免参数爆炸。
因此,一个自然的问题就产生了:是否有可能为大规模EUIC设计一个持续学习框架,使其既能在模型适用于新的UIC任务时保持现有UIC任务的性能,又能在新的UIC任务数量增加时具有可接受的参数增长率?
MeLL
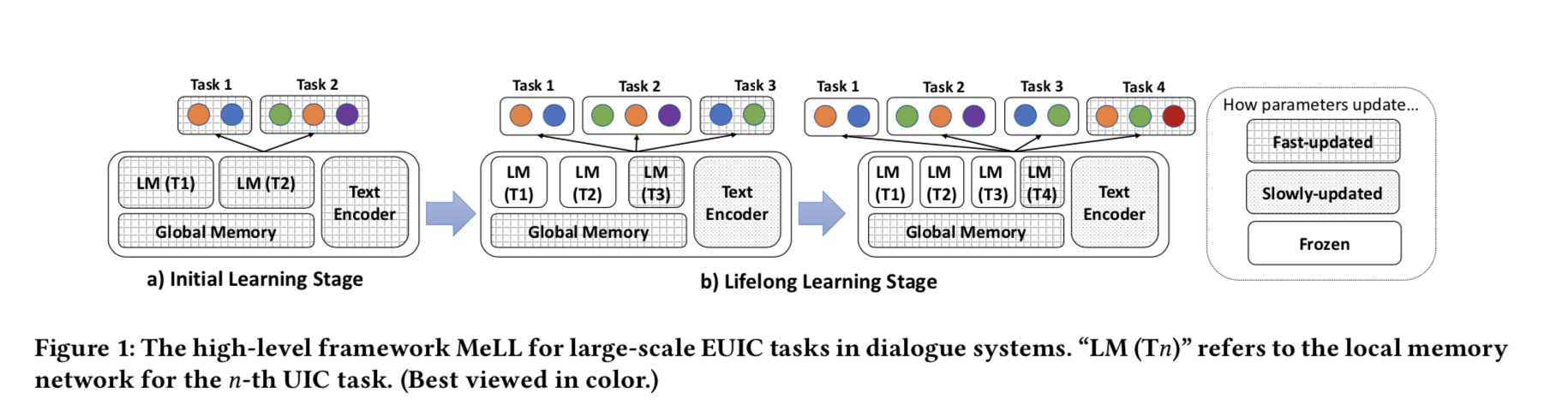
它有一个共享的网络结构,用于学习不断增长的UIC任务,由三个部分组成:文本编码器、全局记忆网络和局部记忆网络。
文本编码器是基于BERT构建的,以生成健壮的文本表示(无论是针对用户的查询还是响应)。对于终身表示学习,这些参数被缓慢更新,这确保由新任务调用的更新操作不会对现有任务产生显著的负面影响。
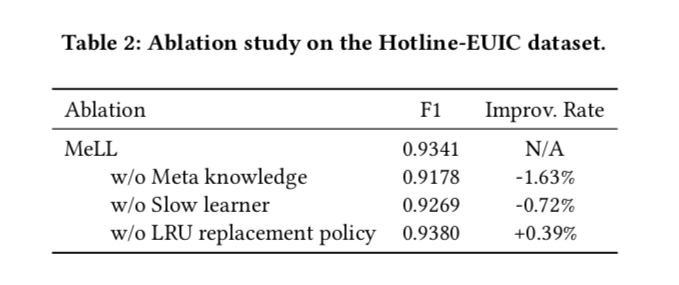
受基于原型的元学习的启发,全局网络存储不同类别的跨任务原型表示
记忆单元的更新速度很快,捕捉到了可跨任务转移的知识,使我们的模型可以很容易地适应新的任务。随着所有任务的不同类别的数量不断增加,使用LRU(最近最少使用)替换策略来管理全局内存,这样大小就不会随着时间的推移而爆炸。
通过注意力机制将文本编码器产生的特征与全局记忆网络进行融合,并利用它们来学习最终的任务特定的UIC分类器。
学习过程完成后,我们将与任务相关的原型表示复制到任务自己的本地内存网络中,并冻结参数。在推理过程中,我们使用文本编码器和任务自身的局部记忆网络进行特征生成。
编码器被认为是不断消化可传递的表示学习知识并将其传递给特定任务的慢速学习者。
全局记忆网络是快速学习器,能够快速编码给定任务的特定知识。
LRU替换策略和从全局存储网络到局部存储网络的复制机制在不增加过多参数的情况下缓解了灾难性遗忘。
RELATED WORK
User Intent Classification
UIC的技术最初应用于搜索引擎中的信息搜索,帮助搜索引擎理解用户发送的搜索查询。 由于对话系统通常通过系统和用户之间的交互提供更好的用户体验,对话系统的 UIC 越来越受欢迎。
UIC 也可以表述为一个排名问题。 Intent-Aware Ranking with Transformers (IART) 模型,基于注意力机制考虑查询意图来选择合适的答案。 MeLL 与这些方法的不同之处在于,它考虑在终身学习环境中解决大量 UIC 任务,这对于工业应用至关重要。
Lifelong Learning
终身学习或持续学习是一种机器学习范式,它侧重于借助先前学习的任务来解决无限的任务序列。开发终身学习算法的一个关键挑战是提高未来任务的性能,同时避免对现有任务的灾难性遗忘。典型的方法包括经验回放[16,20,40],知识提炼[6,26],迁移学习[5,19,39]等。在实际的工业应用中,将经验回放应用于大量的历史任务或存储这些训练好的模型进行知识提取代价很高。
在MEL中,同时使用慢速和快速学习器(即文本编码器和全局记忆网络)来将知识从现有任务转移到新任务。
Meta-learning
元学习的目标是培养能够在训练数据较少的情况下适应各种任务的元学习者。元学习在计算机视觉中得到了广泛的应用,它被认为是一种K-way N-shot few-shot learning problem。典型的应用包括 few-shot 图像分类[25]、目标检测[12]和许多其他应用。元学习在自然语言处理中的应用研究不多,有文献[31,32,34]。
与前人的工作相比,MELL框架不是一个典型的K-way N-shot算法,而是利用元学习的思想来学习文本编码器,该编码器捕获跨任务可转移的知识。全局存储器中使用的快速更新机制和原型表示类似于几个元学习神经网 络[30,43]。
Pre-trained Language Models.
尽管它们很有效,但现代语言模型的巨大规模给在工业应用程序中的部署带来了巨大的挑战,因为工业应用程序中有许多任务需要解决。在MEL中,通过使用缓慢和快速更新的元学习器来解决这个问题,这些元学习器能够处理越来越多的任务,而不会在模型中引入太多新参数。
Method
Overview
$Tn$ 代表第 $n$ 个UIC 任务, $D_n={(x{n,i}, y{n,i})}$ 是 $T_n$ 的训练集,其中 $x{n,i}$ 是第$Dn$ 中的第 $i$个输入样本( 即输入文本,根据应用程序是用户查询或响应的场景),而 $y{n,i}$ 是$x_{n,i}$ 的标签。
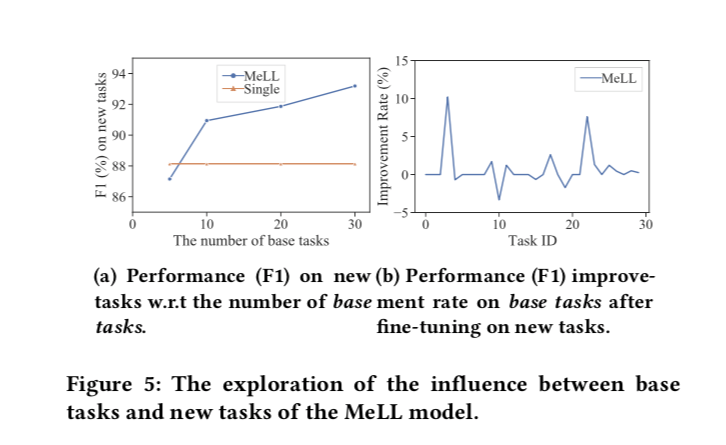
在大规模的EUIC设置中,考虑了我们面临无线序列的UIC任务 $T_1,T_2,…$ 的情况。在实际应用程序中,最开始我们通常有少量UIC任务可用。
因此让 $T1,T_2,…T_N$ 是 $N$ 现有的基本UIC任务, $T{N+1},T{N+2},..$ 是新UIC任务的无限序列。我们的目标是构建一个学习系统 $F = {f_1,f_2,…,f_N,f{N+1}, f{N+2},…}$ 不断支持为新的UIC任务获取分类器 $f{N+1},f_{N+2}$ 同时保持现有分类器 $(f_1,f_2,…,f_N)$ 的性能。
更具体的说,在初始阶段,我们给定了$N$ 训练集 $D1,D_2,…,D_N$ ,N个基础任务来训练多任务UIC模型。之后模型可以自动扩展到无线数量的新任务 $T{N+1},T_{N+2},…$ 新任务依次到达。
为了缓解灾难性遗忘和参数爆炸的问题, MeLL 的模型结构在训练和推理过程中具有不同的计算图。 总的来说,它有四个主要组成部分:
- Text Encoder
- Global Memory Network
- Local Memory Network
- Task-specific Network
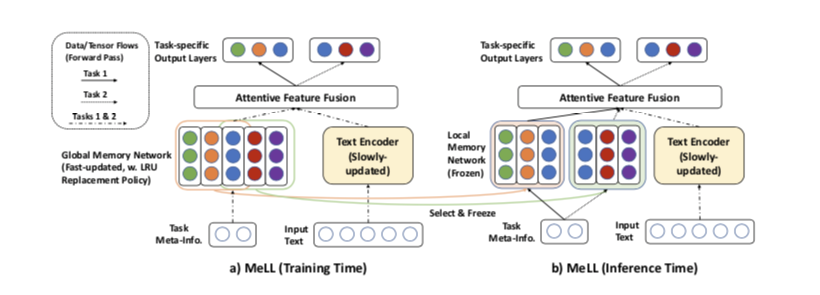
UIC的特征是由缓慢更新的 TextEncoder 和快速更新的 Global Memory Network 生成的。
在特定任务的训练过程之后,相应的类表示从全局内存复制到特定任务的 Local Memory Network。在推理过程中,用文本编码器的特定于任务的 Local Memory来生成用于预测的特征。
Text Encoder
使用 Bert作为 作为模型的主干来学习跨任务的输入文本的通用、深度表示。在这里将 $x{n,i}$ 表示为 $Q(x{n,i})$。 随着新的 UIC 任务不断到来,BERT参数会缓慢更新以消化多个任务的可迁移知识。
请注意,在终身学习阶段,应将编码器参数的学习率设置为较小的值,以避免灾难性地忘记先前学习的任务。
Global and Local Memory Networks
全局记忆网络存储 $K$ 个类别表示的 “ slots “ 槽。令 $yN$ 为跨 $N$ 任务类的集合。即 $y_N = \cup{n=1}^N y_n$ , $K \ge |y_N|$
在初始学习阶段,我们设置 global memory G 如下:
对于类别标签 $y^{(m)}\in y_{N}$, 设 $T^{(m)}$ 是涉及 $y^{(m)}$ 的任务的集合。即 $T^{m} = {T_n | n\in {1,…,N} \ ,\ y^{(m)} \in y_n }$
$Dn^{(m)}$ 是 $D_n$ 的子集,$D^{(m)}_n = {(x{n,i},y{n,i}) \in D_n |y{n,i} = y^{(m)}} $
类标签 $y^{(m)}$ 的原型表示向量 $G_N^{(m)}$ 为:
$G_N^{(m)}$ 是所有任务 $T^{(m)}$ 的原型向量的平均池化结果。通过聚合所有 $y_N$ 类表示 $G_N^{(m)}$,完成了 $G$ 的初始计算,将其视为多有$N$ 任务的高级表示。
我们进一步考虑终身学习的情况,一般而言,我们假设模型已经训练了 $j-1$ 个任务 $T1,…,T{j-1}$ 其中 $j>N$ ,并且有一个新任务 $T_j$ 到达。
对于类 $y^{(m)} \in yj$ , 如果对应的类表示 $G{j-1}^{(m)}$ 存在于 $G$ 中,更新规则如下:
其中 $\gamma \in (0,1)$ 是预定义的超参数,平衡已有的任务和新任务的相关重要性。
Global memory 的大小有 $K$ 的限制。当它满时,删除 $G$ 中最近最少访问的一项。
新插入$G$ 的类别表示计算为 :
应用LRU替换策略,因为任务的主题趋势可能会随着时间的推移而漂移。最近更新的类表示在不久的将来很有可能再次使用。示例如下图:
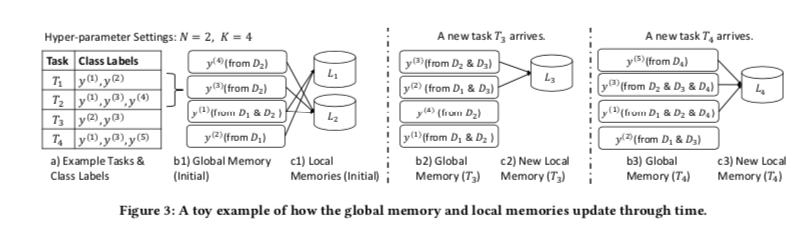
在任务感知学习过程结束时,对于当前任务 $T_n$,复制 $G$ 对应类的表示 $y_n$ 到它自己的本地内存 $L_n$ 用于推理,所有参数都被冻结。因此当全局记忆网络快速更新时,对 $G$ 的更改不会影响对现有任务的推理。
Feature Fusion and Model Output
在介绍了 $Q(x_{n,i})$ 和 $G$ 的生成后,现在讨论 MeLL中的前向传播。
假设我们正在学习任务 $Tn$, 当前训练实例为$(x{n,i}, y_{n,i})\in D_n$。我们使用类标签集 $y_n$ 查询 $G$, 为每个类 $y^{(m)}\in y_n$ 生成当前类表示 $G_n^{(m)}$ 。
注意力分数 $ \alpha ^{(m)}(x{n,i}) = softmax(Q(x{n,i})^T \cdot G_n^{(m)})$
请注意,注意力分数的计算与标准做法略有不同。 发送到task-specific output layer $Att(x_{n,i})$的最终注意力特征集计算如下:
其中$Q(x{n,i})$ 被视为残差。预测结果由 $\hat y{n,i} = fn(Att(x{n,i}))$ 给出。
由于输出层、 text encoder 和 global memory 中参数的梯度完全不同,我们通过反向传播更新这些参数。 local memory networks中的参数在反向传播期间不会更新。
Algorithmic Analysis

进一步对 MeLL 进行了更深入的分析,重点关注终身学习如何影响计算复杂性。
假设我们正在学习一个新任务 $T_j (j>N)$。设 $M$ 是BERT编码器中的参数总数, $d$ 是token嵌入的维数。
推导出全局记忆 、$T_j$ 的全局记忆、注意力融合层和 $T_j$ 的输出赠分别具有 参数 $K\cdot d$ 、 $|y_j|\cdot d$ 、0 和 $(d+1)|y_j|$ 参数
与所有第一个 𝑗 任务相关的参数总数为 $M+K\cdot d + (2d+1)\cdot |\cup{n=1}^j y_j|$ ,其中 $M+(d+1)\cdot |\cup{n=1}^j y_j|$ 个参数在反向传播期间是可训练的。
由于 BERT 编码器具有最多的参数,因此越来越多的任务对模型大小的影响很小。 因此,MeLL 成功解决了参数爆炸问题。此外,与具有重放策略的终身学习算法不同 ,我们的方法不需要任何重放操作。 相反,我们采用复制机制和文本编码器的缓慢更新来避免灾难性的遗忘。
EXPERIMENTS
Baselines
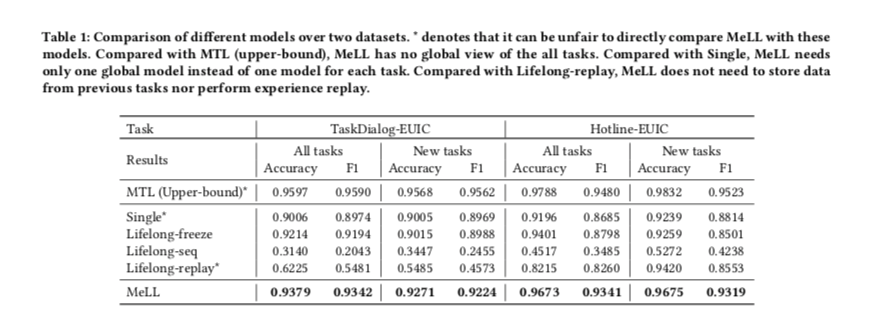
- MTL:对所有任务使用多任务微调方法。在此设置中,我们假设所有任务的数据集都可供我们使用,并且不应用终身学习设置。该模型可以产生我们工作中的上界模型性能。
- Single:为每个任务训练一个BERT分类器。当任务数较大时,不可避免地会出现参数爆炸问题。
- Lifelong-freeze:首先在𝑁基本任务上使用多任务微调方法。接下来,它冻结BERT编码器,并且只调优每个新任务的特定于任务的输出层。
- Lifelong-seq: 与“Lifelong-freeze”类似,不同之处在于当新任务到达时,BERT编码器也将以顺序方式进行调优。因此,它可能会遭受灾难性的遗忘问题。
- Lifelong-replay: 是“Lifelong-seq”的扩展,它使用从先前任务中随机抽样的数据作为经验回放来重新训练先前任务的模型。
 wechat
wechat alipay
alipay





