Multimodal Emergent Fake News Detection via Meta Neural Process Networks
Multimodal Emergent Fake News Detection via Meta Neural Process Networks
基于深度学习的模型在对感兴趣事件的大量标注数据进行训练时表现出较好的性能,而在其他事件上由于领域漂移的影响,模型的性能往往会下降。此外,添加来自新出现的事件的知识需要从头开始构建新的模型或继续微调模型,这对于现实世界的设置来说是不切实际的。(需新注入知识)
假新闻通常出现在新到的活动上,我们很难及时获得足够的帖子。在突发事件的早期阶段,我们通常只有少数相关的验证帖子。 如何利用一小部分经过验证的帖子来使模型快速学习。(few-shot挑战)
本文作者提出 MetaFEND 将元学习(meta learning)和神经过程(np)方法集成在一起解决此类问题。 还提出了标签嵌入模块和硬注意机制,通过处理分类信息和修剪无关帖子来提高效率。
MetaFEND的目标是:调整参数以更好地利用给定的支持数据点作为条件。
Limitations of Current Techniques
few-shot learning 是一种为了克服利用一小部分数据实例进行快速学习。
元学习是一种促进few-shot learning的研究路线,其基本思想是利用以前任务中的全局知识来促进新任务的学习。然而,现有元学习方法的成功与一个重要的假设高度相关:任务来自相似的分布,共享的全局知识适用于不同的任务。这种假设在假新闻识别问题中通常不成立,因为不同事件新闻的写作风格、内容、词汇量甚至类别分布往往不尽相同。
如下图假新闻在事件中的比例明显不同。
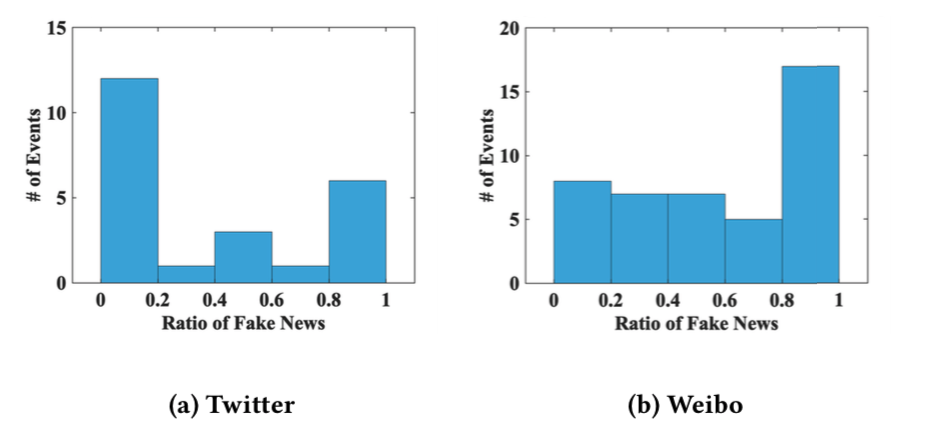
不同事件之间的显著差异对事件异构性提出了严峻的挑战,这不能简单地通过全局共享知识来解决
另一个少机会学习的研究方向是 neural processes [Attentive neural processes],它使用一小部分数据实例作为条件进行推理。尽管神经过程表现出更好的泛化能力,但它们基于一组固定的参数,并且通常受到欠拟合等限制,从而导致性能不令人满意。
这两种模型的研究思路是相辅相成的:
- 元学习中的参数自适应机制可以提供更多的参数灵活性,以缓解神经过程的不匹配问题。
- neural processes 可以使用一小部分数据实例作为条件,而不是将所有信息编码到参数集中,从而帮助应对MAML的异构性挑战。
尽管将这两种流行的小范围方法集成在一起是有希望的,但在给定的小数据实例集上的不兼容操作是基于这两种方法开发模型的主要障碍。
BACKGROUND
假新闻定义为故意编造的、可以查证为虚假的新闻。
作者的目标是利用从过去事件中学到的知识,通过几个例子对新发生的事件进行有效的假新闻检测。更正式地,我们将假新闻检测定义为紧随少镜头问题。
设 $E$ 表示一组新闻事件。在每个新闻事件$e∼E$中,有一些关于这事件$e$的带标签的贴子。
在培训阶段的每一集中,标记的帖子被划分为两个独立的集合:support set和query set 。 利用support set对模型进行训练,学习如何对query set 进行假新闻检测
supprt set : ${Xe^s, Y_e^s} = {x{e,i}^s, y^s{e,i}}{i=1}^K$
query set : ${Xe^q,Y_e^q} = {x{e,i}^q, y{e,i}^q}{i=K+1}^N$
在推理阶段,为每个事件提供带有 $K$ 个标签的帖子。该模型利用其对应的K个标签帖子作为支持集,对给定事件e进行假新闻检测。
MAML
元学习过程分为两个阶段:元训练和元测试。
在元训练阶段,基线模型 $f{\theta}$ 借助于支持集,根据具体事件 e 进行调整。例如一个事件的具体模型$f{\thetae}$ 在对应的query set上被评估,loss $L(f{\thetae}, {X_e^q,Y_e^q})$ 在 ${X_e^q,Y_e^q}$ 被用于更新基线模型 $f{\theta}$。
在元测试阶段,基线模型 $f\theta$ 根据事件$e’$进行调整,使用元训练阶段过程中获取的特定于事件的参数$\theta_e’$,用于对事件$e’$的查询集 ${X{e’}^q,Y_{e’}^q}$ 进行预测。
MAML更新参数向量 $\theta$ 使用事件 $e$ 上的一个或多个梯度下降更新。例如,使用一个梯度更新时:
通过优化模型的性能来训练模型参数关于 $\theta$ 跨从中采样的事件$p(E)$。更具体地说,元目标如下:
Limitations of MAML
MAML可以通过一个和几个梯度更新捕捉任务不确定性。然而,在虚假新闻检测中问题是,当事件是异构的时,事件不确定性很难通过一个或多个梯度步骤编码到参数中。
此外,即使给定的支持数据和感兴趣的查询数据来自同一事件,也不能保证它们都高度相关。在这种情况下,支持集上假新闻检测损失的参数自适应可能会对某些帖子产生误导。
Conditional Neural Process (CNP)
CNP包括四个主要部分:编码器、特征提取器、聚合器和解码器。这个条件神经过程的基本思想借助 ${Xe^s,Y_e^s} = {x{e,i}^s,y{e,i}^s}^K{i=1}$ 作为上下文进行预测。
Limitations of CNP
CNP的一个广泛认可的限制是欠拟合。对于不同的上下文数据点,它们在预测中的重要性通常是不同的。然而,CNP的聚合器对所有支持数据一视同仁,无法获得依赖于查询的上下文信息。此外,CNP只是将帖子的输入特征和数字标签值连接在一起作为输入,而忽略标签的分类特征。
Method
提出了一种 meta neural process框架,它可以通过模拟任务将元学习方法和神经过程方法融合在一起。
为了应对异构新闻事件带来的挑战,我们进一步提出了一个标签嵌入组件来处理分类标签,以及一个hard attention件,该组件可以从具有不平衡类分布的支持集中选择信息量最大的信息。
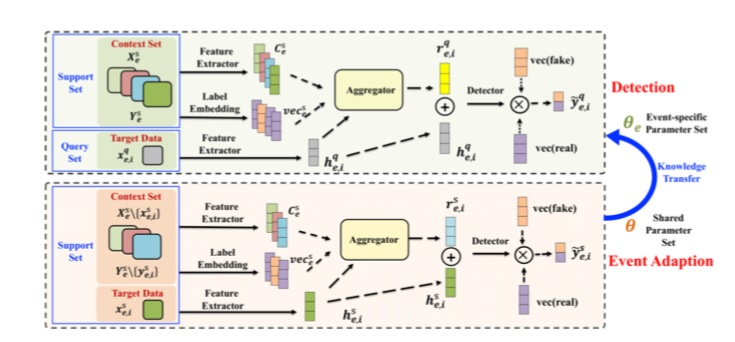
Meta-learning Neural Process Design
提出的框架包括两个阶段:
- 事件适应:事件适应阶段是在支持集的帮助下,使模型参数适应特定事件。
- 事件监测:检测阶段是在支持度和自适应参数集的帮助下,检测给定事件的假新闻。
事件适应
第i个support data ${x{e,i}^s,y{e,i}^s}$ 是一个例子,在事件适应阶段,${x{e,i}^s,y{e,i}^s}$ 被用作目标数据,剩余的support set ${Xe^s,Y_e^s} \setminus {x{e,i}^s, y_{e,i}^s}$ ,被用于上下文集,$\setminus$是差集的意思。
在support set上事件适应目标函数:
然后,我们在 $L_e^s$ 上为事件 e 更新参数 $\theta$ 。一个或多个梯度下降更新。例如,使用一个梯度更新时:
识别阶段
提出的模型具有特定事件参数集 $\theta_e$ , 获取query set $X_e^q$ 和整个support set ${X_e^s,Y_e^s}$ 作为输入和输出预测 $\hat Y_e^q $对于 query set $X_e^q$ 。 对应识别阶段的loss:
通过这个元神经过程,我们可以学习一个初始化参数集,该参数集可以快速地学习使用给定的上下文输入输出作为条件条件来检测关于新到达事件的假新闻。
 wechat
wechat alipay
alipay





