Dynamically Addressing Unseen Rumor via Continual Learning
Dynamically Addressing Unseen Rumor via Continual Learning
谣言往往与新出现的事件联系在一起,因此,处理没见过的谣言的能力对于谣言真实性分类模型至关重要。
以前的工作通过改进模型的泛化能力来解决这个问题,假设即使在新的事件爆发之后,模型也会保持不变。
在这项工作中,提出了一种解决方案,以根据谣言域创建的动态不断更新模型。
与这种新方法相关的最大技术挑战是由于新的学习而灾难性地忘记了以前的学习。
作者采用持续学习策略来控制新的学习,以避免灾难性的遗忘,并提出了一种可以联合使用的额外策略来加强遗忘的缓解。
谣言检测任务两个重要难点:
处理没见过的谣言的能力 (处理训练阶段未见的新谣言)
谣言早发现
此前的方法试图通过关注静态设置中的模型泛化通用性来解决这一挑战,如下图a。目标是提高模型$M{\theta{t=1}}$ 在不更新模型的情况下,在看不见的话题领域(“古尔利特”和“普京失踪”)上表现好。然而,增强模型的泛化能力是一个困难的问题,特别是对于总是引入新主题和词汇的任务。
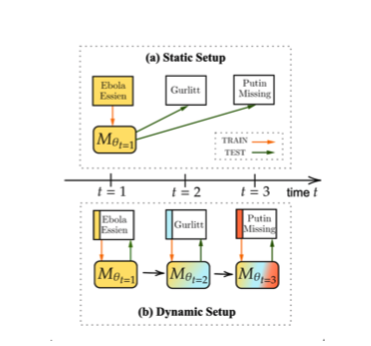
因此,作为另一种解决方案,通过训练一个能够不断适应新出现的谣言的分类器,在动态设置中对未见过谣言进行分类。如上图b。
通过这种方式,可以及时发现虚假谣言,而不必考虑可见谣言和不可见谣言之间的巨大分布差距。
持续学习想解决的主要挑战是在学习新的Domain时灾难性地忘记以前学习的Domain。
这篇文章作者采用了基于排练的(rehearsal- based)持续学习(CL)策略,利用以前遇到的领域的情景记忆来约束未来的学习,并提出了一种简单的技术TTOKENS,可以联合使用来进一步减少灾难性遗忘。
方法
Task Definition
谣言真实性分类是识别给定谣言文本 $X$ 是真、假还是无法核实的任务。
谣言数据集及其对应的标签为集合 $D = {(X_i,y_i,Rm)}_i^N$ 其中 $y\in{True, False,Unverifiabel}$
RM是谣言域标签,N是数据集的大小。
主要目标是训练一个谣言真实性分类模型M,该模型可以从传言领域流中学习,通过时间t而不会发生灾难性的遗忘。
将谣言域流定义为 $S={D_1,···,D_T}$,其中 $D_t$ 表示流中第 $t$ 个谣言域的数据集,$T$ 是流的长度。
T也等于时间戳的长度和谣言域的数量。
在每个时间戳,使用一个新的谣言域数据集 $Dt$ 来顺序训练模型 $M$,并用时间 $k$ 处的谣言域表示训练后的模型参数,$θ{t=k}$。
Base Model
BERT-BASE 编码器和一个分类层。给定输入谣言 $X=x_1,···,x_m$,该模型计算:
$H_{[cls]}$是 $[cls]$ 标记的嵌入,可训练参数为 $θ=[W,b]$
在训练期间,冻结编码层,并且仅使用交叉熵损失来训练分类器参数θ:
Rehearsal-based CL Strategies
基于排练的CL策略依赖于“episodic memory” $M$ 来存储先前遇到的样本。$M$ 被定期重播,以避免灾难性遗忘,并加强过去知识和新知识之间的联系。
REPLAY (Robins, 1995)
CL的Memory M的一个简单利用是扩展当前任务数据 $Dt$,并使用 $L{θ_t}(D_t+M)$来优化模型的参数。基本上,它可以被视为一个数据效率高的多任务框架,它只利用受Memory M大小限制的数据集的一小部分。
Gradient Episodic Memory (GEM) (Lopez- Paz and Ranzato, 2017)
另一种利用方法是使用当前域样本来约束梯度更新,使得Memory M中的样本的损失永远不会增加:
GEM通过随模型参数数量变化的二次规划求解器计算梯度约束。
Task-Specific Tokens (TTOKENS)
各种工作表明,对大型预训练语言模型的输入上下文对模型的结果有巨大影响。换句话说,可以利用LM/MLM的这种上下文相关特性来有意地控制/区分不同域的表示。为了应用该策略,对输入文本 $X$ 进行预处理以从其对应的谣言域标签 Rm开始。形式上,给定第 $t$ 传言域Rm:
该策略可以很容易地与其他CL策略一起使用,因为它是在数据处理步骤中完成的。
实验
数据集PHEME的一个显著特点是根据谣言事件进行分类。总共有9个不同的事件/域,更多详细信息如表1所示。
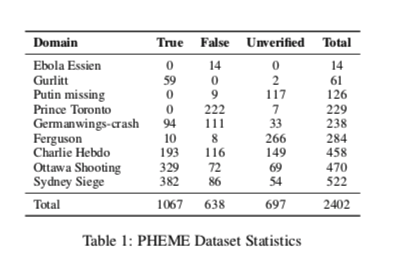
以前的工作在静态设置中利用了这个数据集,其中8个域被组合成一个训练集,剩下的1个域用作单个不可见的测试域。在这项工作中,本文的任务是在动态设置中进行的。为了与动态设置结合,将PHEME的每个域视为单独的特定于域的数据集$D_T$,并以0.4/0.1/0.5的比率将它们拆分为Train/dev/test。
Evaluation Method
在完成对第k个领域的学习后,对其在所有T领域测试集上的测试性能进行了评估。
这一步的结果是矩阵 $R \in \mathbf{R}^{T×T}$,其中 $R_{i,j}$ 是在观察到来自第 $i$ 域的最后一个样本之后,模型在第 $j$ 域上的测试分类精度。
基于此矩阵,计算了两个特定于CL的度量:
- Avg. Accuracy (ACC) 对于了解模型在学习新领域时性能如何变化很有用。此指标的计算方法如下:
请注意,在流的末尾,t=9,即Avg. Accuracy (ACC) 正好是所有任务的平均精确度。
- Backward Transfer (BWT) 是一种用于测量新学习任务对先前学习任务影响的CL方法。此指标的计算公式为:
负的BWT表明模型灾难性地忘记了以前的任务。
model
两个没有CL策略的基线模型,并在我们的动态设置中进行了评估。BERT-BL是指在PHEME数据集上微调的BERT基础模型。M2-BL是指对统一错误信息表示进行微调的另一个基线,该基线被证明能有效提高未发现领域的泛化性。
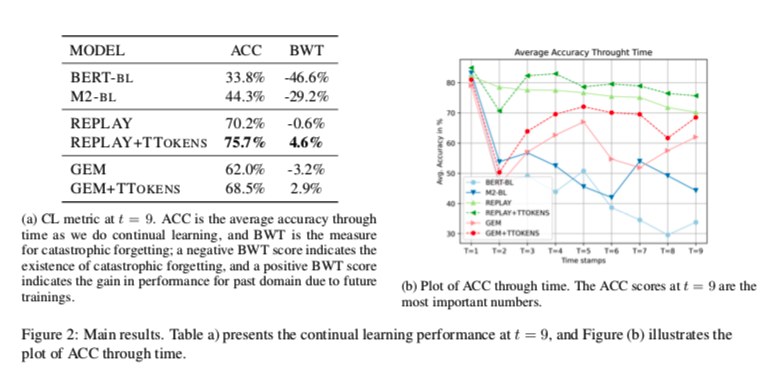
对于作者提出的模型,作者用上文提到的CL策略的各种组合来训练基于BERT的分类器,以评估所采用的策略在对不可见领域的鲁棒性方面的有效性。
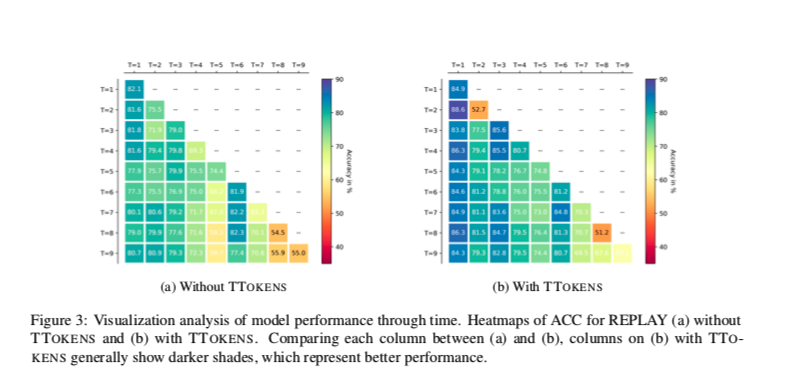
模型性能随时间变化的可视化分析。用于Replay的ACC热力图(A)没有TTOKENS和(B)有TTOKENS。比较(A)和(B)之间的每一列,使用TTO-KENS的(B)列通常显示较深的阴影,这代表更好的性能。
对于TTOKENS成功背后的推理,作者有两个假设:1)TTOKENS隐含地充当了领域差异的信号,并鼓励模型为每个领域学习单独的知识。或者,2)TTOKENS作为一个良好的开端“上下文”,帮助基于LM的编码器在必要时将输入编码为更可分离的——这意味着,来自相同域的输入在向量空间中比来自不同域的输入更接近。
 wechat
wechat alipay
alipay





