Interpretable Rumor Detection in Microblogs by Attending to User Interactions
Interpretable Rumor Detection in Microblogs by Attending to User Interactions
https://github.com/serenaklm/rumor_detection
通过学习区分社区对微博中真假claim的响应来解决谣言检测问题。
现有最先进的模型是基于对会话树建模的树模型。然而,在社交媒体中,发布回复的用户可能是对整个thread的回复,而不是对特定用户的回复。
提出Multi-head post-level attention模型(PLAN)来构建推文之间的远距离交互。并提出几个变体:
- 结构感知自注意模型(StA-PLAN),将树形结构信息合并到Transformer中
- 分层token和post-leve attention(StA-HiTPLAN), 通过token-level 自注意力学习句子表征
这篇工作重点是利用社区对虚假claim的响应来检测虚假索赔。这一研究领域通过将自然语言处理应用于针对claim的评论来利用社区的集体智慧。这些工作背后的关键原则是,社交媒体上的用户会分享对不准确信息的看法、猜测和证据。
样本
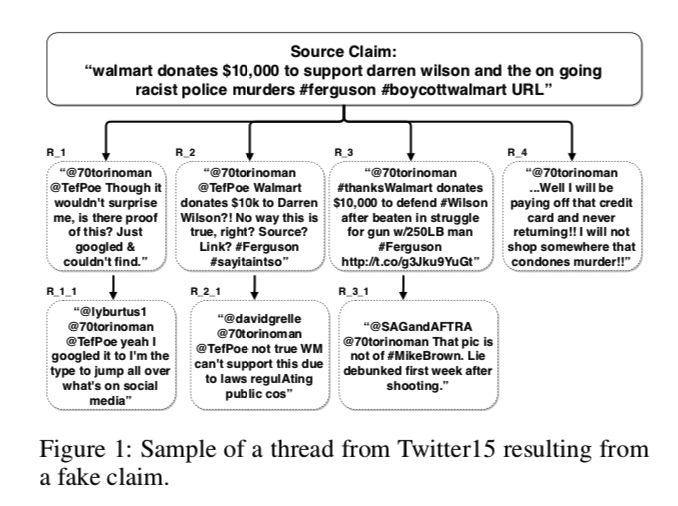
源贴:“沃尔玛捐赠1万美元支持达伦·威尔逊和正在进行的种族主义警察谋杀案#弗格森#抵制沃尔玛URL”。
推特R_1及其回复推文R_1_1对消息来源的真实性表示怀疑。
推特R_2_1和R_3_1提供了确凿的证据,揭穿了消息来源的说法是假的。
虽然R_2_1和R_3_1分别是R_2和R_3的子节点,但它们可以为树上的所有其他节点(如R_1_1和R_1)提供重要信息。
因此,应该考虑所有tweet之间的互动,而不仅仅是父节点和他们的孩子节点之间的互动。
相关工作
两篇使用树形结构进行建模的sota对社交媒体中谣言检测有限制。
Rumor detection on twitter with tree-structured recursive neural networks(2018) ,将来源claim及其回复推文组织成树形结构,使用递归神经网络对传播树中的信息传播进行建模。来自不同节点的信号以自下而上或自上而下的方式进行粗略地重新聚合。在自下而上的模型中,信息从子节点传播到父节点,在自上而下的模型中,信息从父节点传播到子节点,反之亦然。
Tree lstms with convolution units to predict stance and rumor veracity in social media conver- sations.(2019) ,组织了树状结构的对话线程,并探索了用于谣言检测的branch和tree LSTM的几种变体。
这两篇论文都使用了树模型,目的是对会话线索中存在的结构信息进行建模。在树模型中,信息从父级传播到子级,反之亦然。然而,社交媒体对话中的线索结构有所不同,每个用户通常能够观察到对话的不同分支中的所有回复。揭穿假新闻的用户不能只针对他回复的人创建的内容也可能适用于该帖子中的其他推文。树模型不会对来自其他分支的节点之间的交互进行显式建模,这是对社交媒体会话建模时的一个关键限制。
自动区分真假Claims的现有方法利用了各种特征:
- Claims的内容
- Claims来源的重点考虑和社交网络
- 使用可信来源(例如,维基百科)进行事实核查
- 社区对Claims的反应。
这篇重点在社区响应,接下来展开介绍介绍。
Content Information
早期关于欺骗性内容检测的工作研究了语言线索的使用,例如代词的百分比、词长、动词数量和词类。也有工作对关于虚假的评论,目击者的陈述,和讽刺。利用语言特征对假新闻的检测也进行了研究。这种对概念内容的分析依赖于可能是领域或主题所独有的语言特征。
Source and Social Network
研究假新闻的来源及其社交网络,在内容中加入来源信息提高了假新闻分类准确率。为传播假新闻而创建的账户往往具有不同的社交网络特征。
Fact Checking
事实核查网站,如PolitiFact。com和snopes.com依靠人工验证来揭穿假新闻,但无法匹配假新闻的生成速度(Funke 2019)。自动事实核查旨在对照诸如维基百科(Ciampaglia et al.2015年)。
最近,索恩等人(2018)提出了FEVER共享任务,针对包含500万维基百科文档的数据库验证输入Claim,并将每个Claim分为三类:支持、驳斥或信息不足。
事实核查是一种更有原则的假新闻检测方法。然而,它也需要建立一个经过核实的事实语料库,而且可能不适用于证据很少的新Claim。
Community Response
研究人员致力于通过构建分类器来自动预测claim的有效性,分类器利用对社交媒体帖子的评论和回复,以及传播模式。
Ma(2018a)采用多任务学习方法构建了一个学习立场感知特征的分类器用于谣言检测。
Li (2019)对他的模型采用了多任务学习方法,并在他的模型中包括了用户信息。
Chen(2017)提出汇集截然不同的特征,以捕捉帖子随时间的上下文变化。
除了语言特征,其他研究人员也关注了用户的人口统计或交互预测来确定用户的可信度。
Yang(2012)收集了从事传播假新闻的用户特征,通过对传播路径进行分类,仅利用用户特征构建了假新闻检测器
Li(2019)使用用户信息和内容特征相结合的方式训练具有多任务学习目标的LSTM。
在本文中,仅从帖子和评论两个方面来检测谣言和假新闻。提出了一种用于谣言检测的Transformer,而不是递归树模型。
任务定义
问题陈述,将每个线程thread定义为:
其中$x_1$是源tweet,$x_i$是按时间顺序排列的第 $i$ 条tweet,$n$是线程中的tweet数量。
会话树中除了文本信息外,还有可以利用的结构信息。在树形结构模型中,如果$x_i$对$x_j$进行应答,反之亦然,则只对Twitter $x_i$和$x_j$进行关联。
本文模型允许任何帖子关注同一主题中的任何其他帖子。
在提出的结构感知模型中,用关系标签来标记任何一对推文 $x_i$ 和 $x_j$之间的关系 $R(i,j)\in {\text{parent, child, before, after, self}}$ 。$R(i,j)$ 的值是通过依次应用以下规则集来获得的:
- parent:如果 $x_i$ 直接回复 $x_j$
- child:如果 $x_j$ 直接回复 $x_i$
- before:如果 $x_i$ 在 $x_j$之前到来
- after:如果 $x_i$ 在 $x_j$之后
- self:如果i=j
谣言检测任务简化为学习预测每个$(X,R)$到其谣言类别 $y$。
在两个谣言检测数据集上进行了实验,即Twitter15和Twitter16数据,以及PHEME 5数据。
对于我们正在处理的数据集,分类标签是不同的:
- Twitter15 and Twitter16:$y\in {\text{non-rumor, false-rumor, true-rumor, unverified}}$
- PHEME: $y\in {\text{false-rumor, true-rumor, unverified}}$
方法
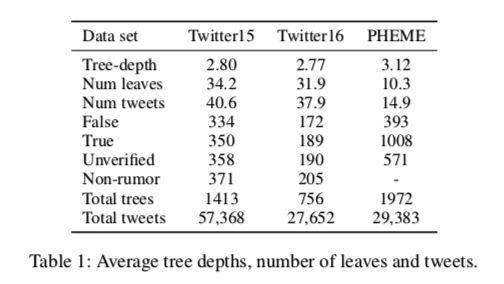
然而,正如我们将在下表中的数据统计中看到的那样,数据集中的树非常浅,大部分评论直接回复源tweet,而不是回复其他tweet。
我们发现,在社交媒体中,由于整个帖子通常都是可见的,回复根帖子的用户可能会继续与更活跃的用户进行对话,而不是专门为根帖子撰写回复。因此,在对社交媒体对话进行建模时,没有对推文之间的每一种可能的成对交互进行显式建模的树模型是次优的,所以用Transformer-based模型。
Post-Level Attention Network (PLAN)
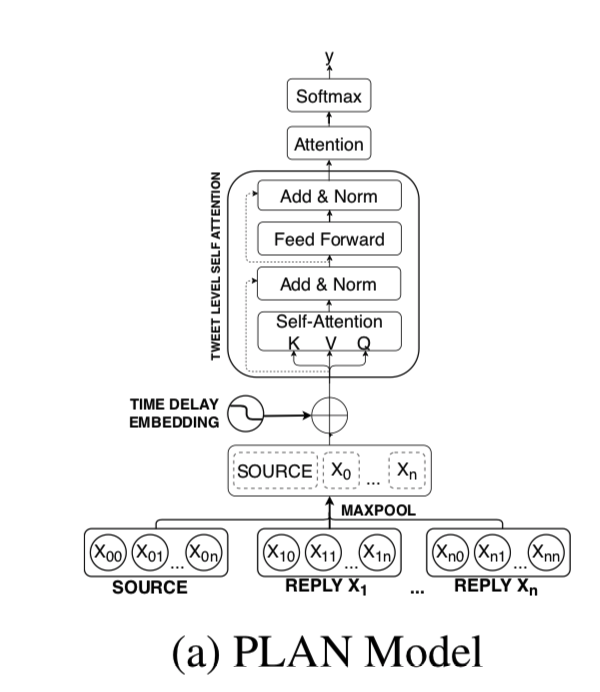
首先将对话树的结构展平,并将推文按时间顺序排列成直线结构,源推文作为第一条推文。对于我们的计划模型,我们在线性结构中对每个推文 $x_i$ 应用最大池化来获得它的句子表示 $x_i$。
然后传递一个句子嵌入序列 $X’ = (x_1’,x_2’,…,x_n’)$ 通过s个数的多头注意力(MHA)层来模拟推文之间的交互。
我们将这些MHA层称为post-level attention层。因此,这将改变 $X’ =(x_1’,x_2’,…,x_n’)$ 为 $U=(u_1,u_2,…,u_n)$
最后,使用注意力机制对推文进行插值,然后通过一个全连接层进行预测。
Structure Aware Post-Level Attention Network (StA-PLAN)
模型的一个可能的局限性是,我们通过以线性结构组织推文来丢失结构信息。转换树中固有存在的结构化信息对于假新闻检测可能仍然有用。
树模型在这方面更优越,因为结构信息是显式建模的。为了将树模型的优点和自我注意机制结合起来,对计划模型进行了扩展,使其显式地包含了结构信息。
$a^V{ij}$ 和 $a^K{ij}$ 都是代表tweet对之间五种可能的结构关系(即parent, child, before, after, self)之一的向量
Structure Aware Hierarchical Token and Post-Level Attention Network (StA-HiTPLAN)
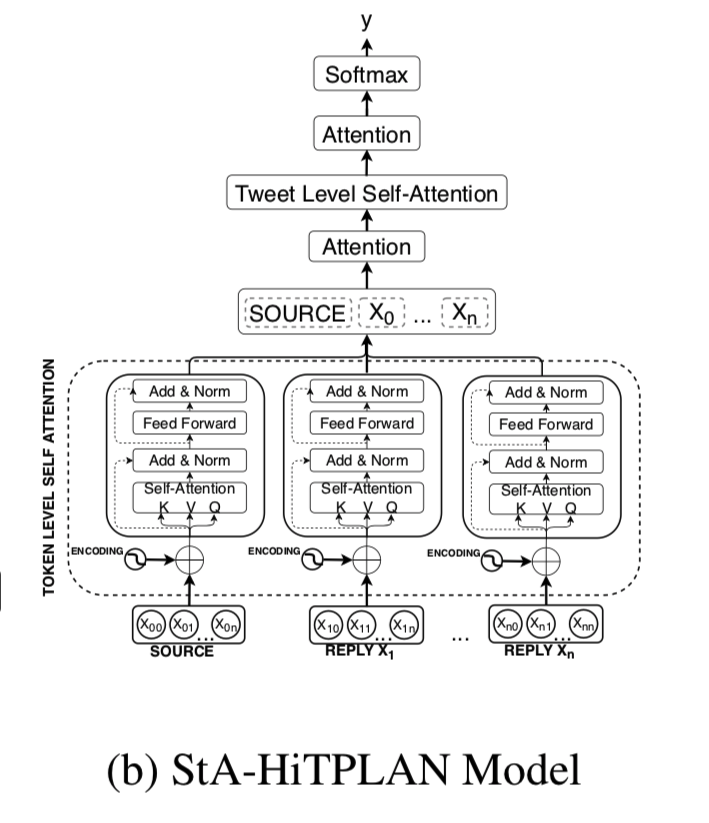
PLAN模型执行最大池化,以获得每条推文的句子表示。
然而,让模型学习单词向量的重要性可能会更理想。因此,提出了一种分层的注意模型—token-level的注意和post-level的注意力。分层模型的概述如图所示。
在使用注意机制插入输出之前,我们执行token-level自注意力,而不是使用最大池化来获得句子表示。
每条推文可以表示为一系列单词记号$xi=(x{i,1},x{i,2},…,x{i,|xi|})$。我们在一条推文中通过MHA层传递了单词token的序列。这允许tweet中的token之间进行交互,将这些层称为token-level关注层。
Time Delay Embedding
在不同的时间间隔创建的推文可以有不同的解释。首次创建源claim时表示不相信的推文可能很常见,因为claim可能尚未经过验证。然而,在传播的后期阶段,可疑的推文可能表明消息来源的说法是假的倾向很高。
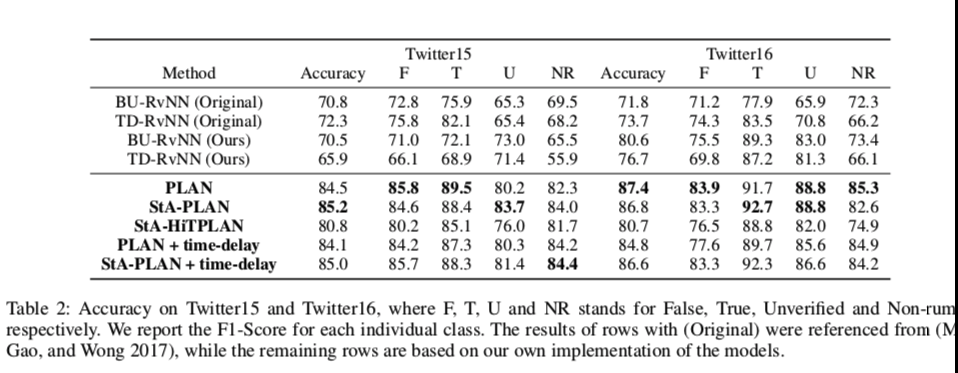
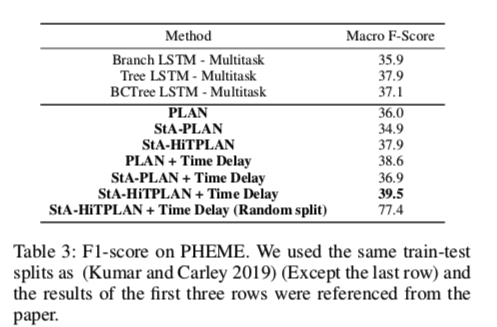
因此,提出的三个模型PLAN、STA-PLAN和STA-HiTPLAN研究了带有时延信息的Tweet编码的实用性。
为了包括每个tweet的时间延迟信息,根据从源tweet创建时起的延迟将tweet绑定。
将时间箱的总数设置为100,每个箱代表10分钟的间隔。延迟超过1000分钟的推文将落入最后一个时间段。
其中pos表达为时间bin,$pos\in[0,100)$
实验
数据集
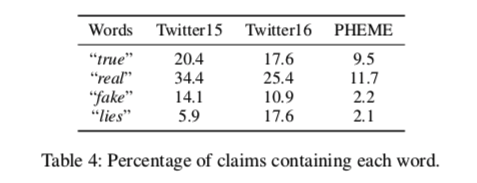
- Twitter15 and Twitter16 :对于Twitter15和Twitter16的数据集,每个声明中都有很大比例的转发:Twit-15和Twitter16分别为89%和90%。因为作者假设转发不会给模型带来新信息,所以删除了Twitter15和Twitter16的所有转发。在删除转发后,观察到少数索赔将只剩下来源Claim。既然作者的方法背后的原则是,我们可以利用人群的信号来侦测谣言,那么没有任何回复的说法就应该是“未经核实的(unverified)”。因此,在训练数据中修改了这类说法的标签为“未经证实”
 wechat
wechat alipay
alipay





