Strategies for Pre-training Graph Neural Networks
Strategies for Pre-training Graph Neural Networks
目前深度学习各个领域的预训练都搞的热火朝天,GNN也是肯定要搞的。那么预训练之后下一个热潮会是什么呢?
ICLR2020 首次系统的探索了大规模GNN预训练
提出了一种结合节点级和图级表示的预训练方法来训练模型。
在节点级,使用了两种自监督方法,即上下文预测和属性预测。
在图形级,使用有监督的图级属性预测和结构相似性预测
同时作者建立了两个新的预训练数据集,2M graph的化学数据集和一个有395K graph的生物数据集。
接下来介绍作者这么做的理由
发现
因为对于特定任务的有标签数据是很稀少的,但无标签数据却有很多,所以为了充分利用无标签数据,各种自监督方法开始兴起。
所以作者分别在图级和节点级层面上提出了两大类预测方法
- 属性预测:属性mask(节点)、有监督的属性预测(图级)
- 结构预测:上下文预测(节点)、结构相似性预测(图级)
以往的一些研究表明(Xu et al., 2017; Ching et al., 2018; Wang et al., 2019),一个成功的迁移学习不仅仅是增加与下游任务来自同一领域的标注好的预训练数据集的数量。相反,它需要大量的领域专业知识来仔细选择与感兴趣的下游任务相关的示例和目标标签。否则,知识从相关的预训练任务转移到新的下游任务可能会损害泛化,这被称为负迁移(Rosenstein等人,2005年),并极大地限制了预训练模型的适用性和可靠性。
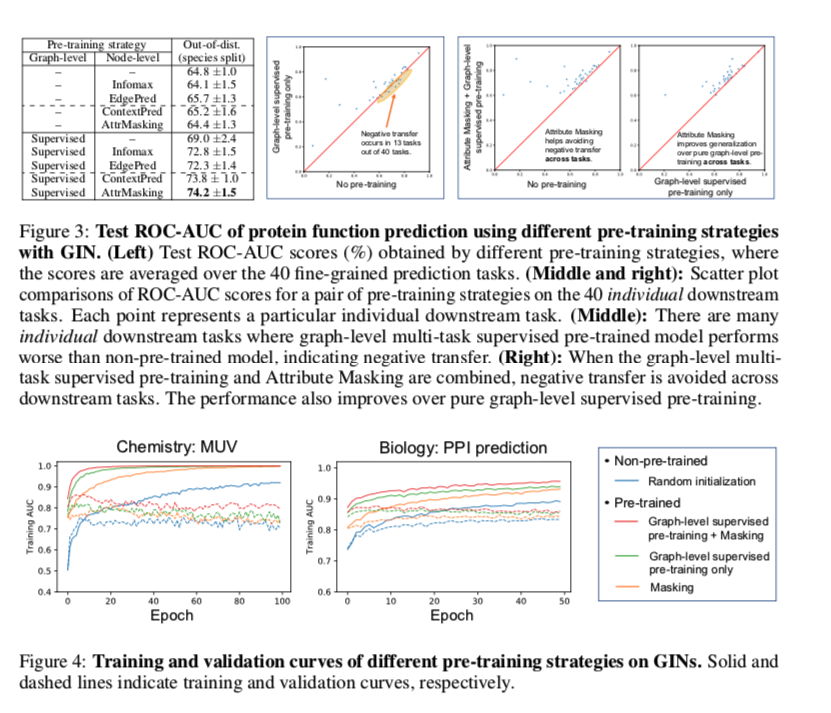
作者研究发现朴素的策略要么在整个图的层面上预先训练GNN,要么在单个节点层面上预先训练GNN,所给出的改进有限,甚至可能导致许多下游任务的负迁移。在只有图级的预训练下大约有1/4的任务出现了负迁移。
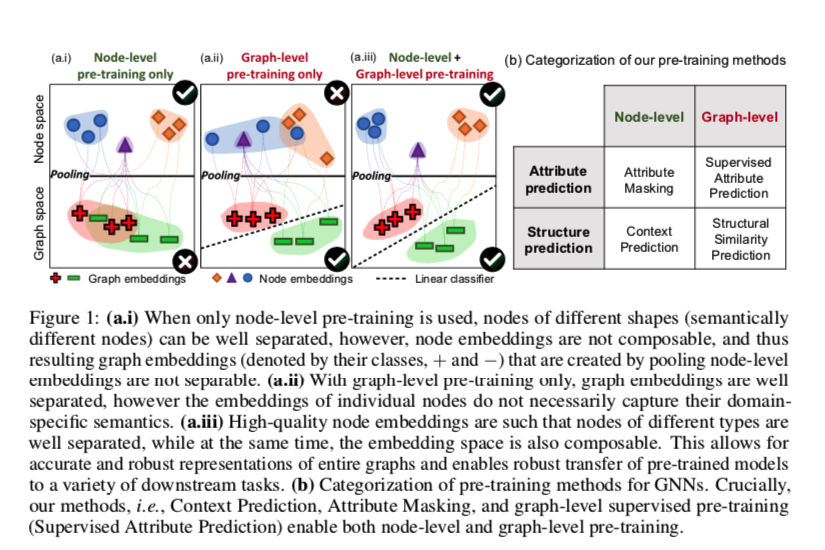
图(a.i)当仅使用节点级预训练时,可以很好地分离不同形状的节点(语义上不同的节点),但汇集节点级嵌入创建的结果,图嵌入是不可分离的(图嵌入由+和−表示)
图(a.ii)仅在图级预训练的情况下,图嵌入可以很好地分离,但是单个节点的嵌入并不一定捕获它们特定于领域的语义。
图(a.iii) 高质量的节点嵌入使得不同类型的节点能够很好地分开,同时嵌入空间也是可组合的。这允许对整个图形进行准确和健壮的表示,并允许将预先训练的模型健壮地传输到各种下游任务。
预训练策略
在预训练策略的技术核心是在单个节点以及整个图的级别预先训练。这一概念鼓励GNN在两个级别捕获特定域的语义。
节点级预训练
两种自监督方法,上下文预测和属性mask。
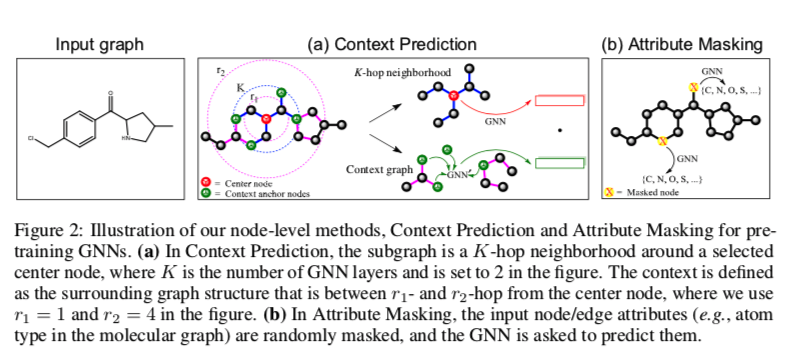
图(a)在上下文预测中,子图是所选中心节点周围的K跳邻域,其中K是GNN层的数量,上图中设置为K=2。环境定义为中心节点r1-和r2-Hop之间的周围图结构,上图中使用r1=1和r2=4。
图(b) 在属性mask中,输入节点/边属性(例如,分子图中的原子类型)被随机mask,并且要求GNN预测它们。
上下文预测:利用图结构的分布性
使用子图来预测其周围的图结构。目标是预先训练GNN,以便它将出现在类似结构上下文中的节点映射到附近的嵌入。
通过三个步骤:
邻居节点和上下文图
对于每个节点v,定义v的邻居和上下文图。因为GNN信息聚合的是K层邻居,所以节点v的嵌入$h_v$ 依赖于距离v至多k跳节点。上下文图由两个超参数r1和r2来描述,并且它表示远离v的r1跳和r2跳之间的子图(即它是宽度为r2−r1的环)。并且r1<K,以便在邻域和上下文图之间共享一些节点,我们将这些节点称为上下文锚节点。这些锚节点提供关于邻居图和上下文图如何彼此连接的信息。
使用一个辅助GNN把上下文编码成固定向量
由于图的组合性,直接预测上下文图是很困难的。这与自然语言处理不同,在自然语言处理中,单词来自固定和有限的词汇表。为了实现上下文预测,将上下文图编码为固定长度的向量。为此,引入一个上下文GNN作为辅助编码,就是图中的GNN‘。首先用其获得上下文图中的节点嵌入,然后对上下文锚点的嵌入进行平均,得到固定长度的上下文嵌入。对于图G中的节点v,将其对应的上下文嵌入表示为$c^G_v$
负采样
主要的GNN编码邻居节点获取节点的embedding—— $h_v^{(K)}$ ,上下文GNN编码上下文图获取上下文embedding——$c^G_v$。学习目标是一个二分类:是否特定邻域和特定上下文图是否属于同一节点。
让v‘=v并且G’=G(即正例),或者我们从随机选择的图G‘中随机抽样v’(即负例)。
属性mask:利用图属性的分布性
目标是通过学习图结构上节点/边属性的分布规律来获取领域知识。
属性mask有节点mask和属性mask两类
工作原理:掩蔽节点/边缘属性,然后让GNN基于相邻结构预测这些属性,这参考了bert的mask。
具体地说,通过用特殊的屏蔽指示符替换输入节点/边属性(例如分子图中的原子类型)来随机屏蔽它们。然后应用GNNs来获得相应的节点/边嵌入(边嵌入:为边的端点的节点嵌入之和来获得)。
最后,在嵌入的基础上应用线性模型来预测被mask的节点/边属性。有趣的是bert的mask其实相当于在全连通的token图上应用了消息传递。
在图结构数据中是对非全连通图进行操作,目的是捕捉节点/边属性在不同图结构上的分布规律。
图级别预训练
我们的目标是确保节点和图嵌入都是高质量的,以便图嵌入是健壮的,并且可以跨下游任务传输。
有两个用于图级预训练的选项:预测整个图的特定于域的属性(监督标签),或者预测图结构。
有监督的图级属性预测
由于图形级表示 $h_G$ 直接用于对下游预测任务进行微调,希望将特定于域的信息直接编码成 $h_G$。
考虑了一种对图表示进行预训练的实用方法:图级多任务监督预训练,用于联合预测单个图的不同监督标签集。例如,在分子性质预测中,我们可以预先训练GNN来预测到目前为止实验测量的分子的所有性质。在蛋白质功能预测中,目标是预测给定的蛋白质是否具有给定的功能,我们可以预先训练GNN来预测到目前为止已经验证的各种蛋白质功能的存在。
重要的是,单独进行大量的多任务图级预训练可能无法给出可转移的图级表示。(问题来了)
这是因为一些有监督的预训练任务可能与下游感兴趣的任务无关,甚至会损害下游的绩效(负迁移)。一种解决办法是选择“真正相关的”有监督的训练前任务,只对这些任务进行训练前GNN训练。然而,这样的解决方案成本极高,因为选择相关任务需要大量的领域专业知识,并且需要针对不同的下游任务分别进行预训练。
为了缓解这个问题,作者的见解是,多任务监督的预训练只提供图形级的监督;因此,创建图形级嵌入的本地节点嵌入可能没有意义。这种无用的节点嵌入可能会加剧负迁移问题,因为许多不同的预训练任务在节点嵌入空间中更容易相互干扰。受此启发,在执行图级预训练之前,先通过上文描述的节点级预训练方法在单个节点级别对GNN进行正则化。正如作者所料,组合策略产生了更多可转移的图形表示。并且在没有专家选择监督的预训练任务的情况下稳健地改善了下游性能。
结构相似性预测
目标是对两个图的结构相似性进行建模
此类任务的示例包括对图形编辑距离进行建模(Bai等人,2019年)或预测图形结构相似性(Navarin等人,2018年)。
这里好像作者感觉比较难没有全部实现,留到了以后的工作中
总体预训练策略
预训练策略是首先进行节点级的自监督预训练,然后进行图级多任务监督的预训练。当GNN预训练完成后,我们对下游任务的预训练GNN模型进行微调。具体地说,我们在图级表示的基础上添加线性分类器来预测下游的图标签。随后以端到端的方式微调整个模型,即预先训练的GNN和下游线性分类器。
进一步相关工作
关于图中单个节点的无监督表示学习的文献非常丰富,大致分为两类。
第一类是使用基于局部随机行走的目标的方法(Grover&Leskovec,2016;Perozzi等人,2014;Don等人,2015)以及例如通过预测边的存在来重建图的邻接矩阵的方法。
在第二类中是诸如Deep Graph Infomax的方法,其训练最大化局部节点表示和聚集的全局图表示之间的互信息的节点编码器。(基于对比学习互信息的最近也要研究研究)
这两种方法都鼓励附近的节点具有相似的嵌入表示,最初是针对节点分类和链路预测提出和评估的。然而,这对于图级预测任务来说可能是次优的,在图级预测任务中,捕捉局部邻域的结构相似性通常比捕捉图中节点的位置信息更重要
所以该预训练策略既考虑了节点级的预训练任务,也考虑了图级的预训练任务,并且正如在实验中所显示的,为了使预训练模型获得良好的性能,必须同时使用这两种类型的任务。
实验
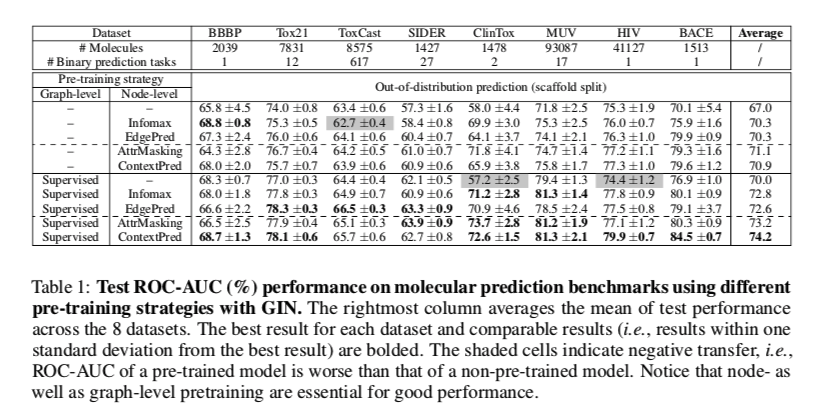
阴影单元格表示负迁移,即预训练模型的ROC-AUC比未预训练模型的ROC-AUC差。借此说明两个级别共用的重要性。
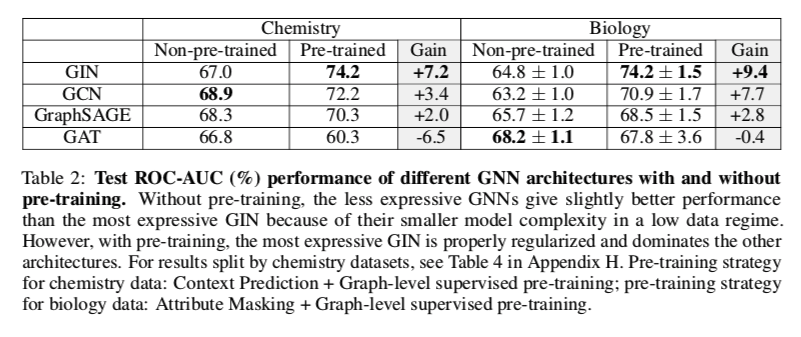
在有无预培训的情况下测试不同GNN架构的ROC-AUC(%)性能。
这里表达能力越强的结构预训练效果越好,表达能力较弱的GNN收益较小,甚至有时未负。这一发现证实了先前的观察结果(例如,Erhan等人)。(2010)),使用富有表现力的模型对于充分利用预培训至关重要,当用于表达能力有限的模型(如GCN、GraphSAGE和GAT)时,预培训甚至会影响性能。
并且GAT的表现反而下降了不少。作者认为GAT属于表达能力有限的模型,还有人认为GAT attention的参数比较多,模型结构比较复杂导致。
 wechat
wechat alipay
alipay





