nlp中的对抗训练&与bert结合
nlp中的对抗训练学习
PPT : https://coding-zuo.github.io/adversary/index.html
由于深度神经网络强大的表示学习能力,在许多领域都取得了很大的成功,包括计算机视觉、自然语言处理、语音识别等。然而,在其卓越性能的背后,深度神经网络作为一个黑箱,缺乏可解释性与鲁棒性,使得它易受到对抗攻击而对抗性攻击的存在可能是深度学习模型的一个固有弱点。
深度学习的对抗一般有两种含义:
- 一是生成对抗网络(Generative Adversarial Network,GAN) 代表一大类先进的生成模型。(这方面我不是很了解)
- 另一个则是跟对抗攻击、对抗样本相关的领域。(主要关心模型在小扰动下的稳健性)
方法介绍
在CV领域,我们需要通过对模型的对抗攻击和防御来增强模型的稳健型,比如在自动驾驶系统中,要防止模型因为一些随机噪声就将红灯识别为绿灯。
在NLP领域,类似的对抗训练也是存在的,不过NLP中的对抗训练更多是作为一种正则化手段来提高模型的泛化能力!
这使得对抗训练成为了NLP刷榜的“神器”之一,前有微软通过RoBERTa+对抗训练在GLUE上超过了原生RoBERTa。
对抗样本
要认识对抗训练,首先要了解“对抗样本”,它首先出现在论文《Intriguing properties of neural networks》之中。简单来说,它是指对于人类来说“看起来”几乎一样、但对于模型来说预测结果却完全不一样的样本,比如下面的经典例子:

“对抗攻击”,其实就是想办法造出更多的对抗样本。
“对抗防御”,就是想办法让模型能正确识别更多的对抗样本。
所谓对抗训练,则是属于对抗防御的一种,它构造了一些对抗样本加入到原数据集中,希望增强模型对对抗样本的鲁棒性;同时,如本文开篇所提到的,在NLP中它通常还能提高模型的表现。
用对抗训练的思路来提升NLP模型,有两个实现角度:
因为nlp的输入通常是one-hot向量,两个one-hot向量其欧式距离恒为$\sqrt 2$ ,理论上不存在微小的扰动,不想cv图像那样可以对连续实数向量来做。比如,$\Delta x$ 是实数向量,$x+\Delta x$还是一个有意义的图。所以很多研究都是在embedding层上做扰动的,因为embedding层是我们自己训练的,所以不太可能出现认为的恶意对抗攻击。
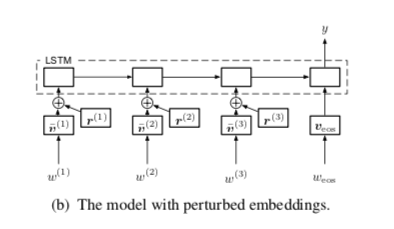
这种角度不知道还算不算对抗,但可以说是一种数据增强手段。如上图中下面的问题,经过缩写,添加标点,或者同义词近义词替换等等。通过辅助模型提升鲁棒性。
Min-Max
对抗训练可以统一写成如下格式:
其中$D$ 代表训练集,x代表输入,y代表标签,θ是可学习模型参数,L(x,y;θ)是单个样本的loss,Δx是对抗扰动,Ω是扰动空间。
理解为:
$max_{\Delta x\in \Omega}L(x+\Delta x,y;\theta)$ ,往输入x中注入扰动$\Delta x$, 目的是希望 $ L(x+\Delta x,y;\theta)$ 损失越大越好,也就是让现有模型的预测出错;
当然$\Delta x$ 不能太大、无约束,否则达不到“看起来几乎一样”的效果,所以$Δx$要满足一定的约束,常规的约束是$‖Δx‖≤ϵ$,其中$ϵ$是一个常数;
构造好对抗样本后,用$x+\Delta x,y$作为数据去最小化loss,来更新参数$\theta$ (梯度下降)
- 重复执行1.2.3步。
整个对抗训练优化过程是一个max和min交替执行的过程:通过注入max损失,在梯度下降让损失变min。
如何计算$\Delta x$——快速梯度FGM
$\Delta x$的目的是增大Loss,而我们知道让loss减少的方法是梯度下降,那反过来,让loss增大的方法自然就是梯度上升,因此可以简单地取
求loss对x的梯度,然后根据梯度给Δx赋值,来实现对输入的干扰,完成干扰之后再执行常规的梯度下降。
为了防止$\Delta x$过大,通常要对 $∇xL(x,y;θ)$ 标准化,常见方式为:
采用右边的取扰动值的算法叫FGSM(ICLR2015),理解为扰动是沿着梯度方向向损失值的极大值走。
采用左边取扰动值的算法叫FGM(ICLR2017),理解为在每个方向上都走相同的一步找到更好的对抗样本。
有了$\Delta x$,得到:
这就构成了一种对抗训练方法,被称为Fast Gradient Method(FGM),它由GAN之父Goodfellow在论文《Explaining and Harnessing Adversarial Examples》首先提出。
此外,对抗训练还有一种方法,叫做Projected Gradient Descent(PGD),其实就是通过多迭代几步来达到让$L(x+Δx,y;θ)$更大的$Δx$(如果迭代过程中模长超过了$ϵ$,《Towards Deep Learning Models Resistant to Adversarial Attacks》。在后文….
梯度惩罚
假设已经得到对抗扰动 $\Delta x$ ,更新 $\theta$ 时,对 L 进行泰勒展开:
对应的 $\theta$ 的梯度为:
代入 $ \Delta x = ϵ∇_xL(x,y;θ)$:
这个结果表示,对输入样本施加 $ϵ∇xL(x,y;θ)$ 的对抗扰动,一定程度上等价于往loss里边加入“梯度惩罚”
如果对抗扰动是$ϵ‖∇xL(x,y;θ)‖$ ,那么对应的梯度惩罚项则是$ϵ‖∇xL(x,y;θ)‖$(少了个1/2,也少了个2次方)。
几何图像
事实上,关于梯度惩罚,我们有一个非常直观的几何图像。以常规的分类问题为例,假设有n个类别,那么模型相当于挖了n个坑,然后让同类的样本放到同一个坑里边去:
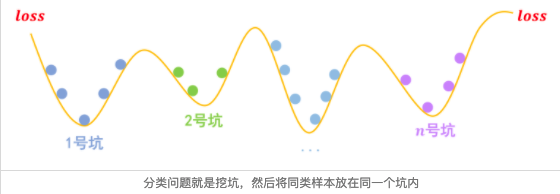
梯度惩罚则说“同类样本不仅要放在同一个坑内,还要放在坑底”,这就要求每个坑的内部要长这样:
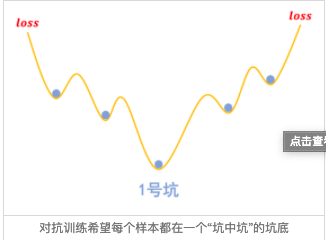
为什么要在坑底呢?因为物理学告诉我们,坑底最稳定呀,所以就越不容易受干扰呀,这不就是对抗训练的目的么?
那坑底意味着什么呢?极小值点呀,导数(梯度)为零呀,所以不就是希望‖∇xL(x,y;θ)‖‖∇xL(x,y;θ)‖越小越好么?这便是梯度惩罚的几何意义了。

苏神代码基于keras的:
Projected Gradient Descent (PGD)
内部max的过程,本质上是一个非凹的约束优化问题,FGM解决的思路其实就是梯度上升,那么FGM简单粗暴的“一步到位”,是不是有可能并不能走到约束内的最优点呢?当然是有可能的。于是,一个很intuitive的改进诞生了:Madry在18年的ICLR中,提出了用Projected Gradient Descent(PGD)的方法,简单的说,就是“小步走,多走几步”,如果走出了扰动半径为$\epsilon$的空间,就映射回“球面”上,以保证扰动不要过大:
其中$\mathcal{S}={r\in\mathbb{R}^d:||r||_2 \leq \epsilon}$ 为扰动的约束空间,$\alpha$为小步的步长。
作者将这一类通过一阶梯度得到的对抗样本称之为“一阶对抗”,在实验中,作者发现,经过PGD训练过的模型,对于所有的一阶对抗都能得到一个低且集中的损失值,如下图所示:
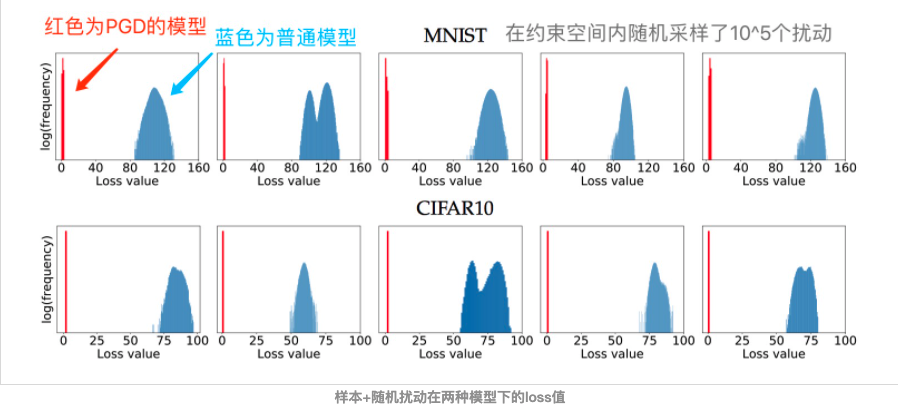
我们可以看到,面对约束空间 $\mathcal{S}$ 内随机采样的十万个扰动,PGD模型能够得到一个非常低且集中的loss分布,因此,在论文中,作者称PGD为“一阶最强对抗”。也就是说,只要能搞定PGD对抗,别的一阶对抗就不在话下了。
1 | 对于每个x: |
基于PGD的对抗性训练被广泛认为是最有效的,因为它在很大程度上避免了模糊的梯度问题。它将一类对抗性训练算法转化为求解交叉熵损失的极大极小问题,该问题可以通过多次投影梯度上升步骤和随后的SGD步骤可靠地实现。
Virtual Adversarial Training
除了监督训练,对抗训练还可以用在半监督任务中,尤其对于NLP任务来说,很多时候输入的无监督文本多的很,但是很难大规模地进行标注,那么就可以参考[13]中提到的Virtual Adversarial Training进行半监督训练。
首先,我们抽取一个随机标准正态扰动($d\sim \mathcal{N}(0, I)\in \mathbb{R}^d$),加到embedding上,并用KL散度计算梯度:
然后,用得到的梯度,计算对抗扰动,并进行对抗训练:

实现方法跟FGM差不多
FreeAT & YOPO & FreeLB
优化的主要方向有两点:得到更优的扰动 & 提升训练速度
其实PGD效果不错但是它迭代多步计算开销很大,所以出现了这些针对效率上的优化,并且结合预训练语言模型。
具体的就搜这些论文来看吧。
FGSM: Explaining and Harnessing Adversarial Examples
FGM: Adversarial Training Methods for Semi-Supervised Text Classification
FreeAT: Adversarial Training for Free!
YOPO: You Only Propagate Once: Accelerating Adversarial Training via Maximal Principle
FreeLB: Enhanced Adversarial Training for Language Understanding
SMART: Robust and Efficient Fine-Tuning for Pre-trained Natural
参考文献
【炼丹技巧】功守道:NLP中的对抗训练 + PyTorch实现
TAVAT: Token-Aware Virtual Adversarial Training for Language Understanding
Adversarial Training Methods for Semi-Supervised Text Classification
Adversarial Text Classification原作实现
 wechat
wechat alipay
alipay





