RoBERTa & Albert
RoBERTa & Albert
2021年了,bert的改进体也越来越多,Roberta和Albert是比较出名的两个改进体。
Roberta主要针对bert的预训练任务如NSP,mask进行改进。并且扩大了batchsize和使用更长的序列训练,这两点可能在长文本竞赛上有作用。
Albert主要针对bert参数量太大,训练慢来进行改进。引入了跨层参数共享,embedding解绑分解,取消dropout和添加SOP预训练任务。
RoBERTa
- 使用更大的batch在更大的数据集上对Bert进行深度训练
- 不再使用NSP(Next Sentence Prediction)任务
- 使用更长的序列进行训练
- 动态改变训练数据的MASK模式
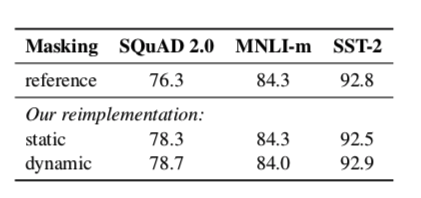
静态Masking vs 动态Masking
- 静态Masking:在数据预处理期间Mask矩阵就已经生成好了,每个样本只会进行一次随机Mask,每个epoch都是相同的。
- 修改版静态Masking: 在预处理时将数据拷贝10份,每一份拷贝都采用不同的Mask,也就是说,同样的一句话有十种不同的mask 方式,然后每份数据都训练N/10个epoch
- 动态Masking:每次向模型输入一个序列时,都会生成一种新的Mask方式,即不在预处理的时候进行mask,而是在向模型提供输入时动态生成Mask。
取消NSP任务
RoBERTa 实验了 4 种方法:
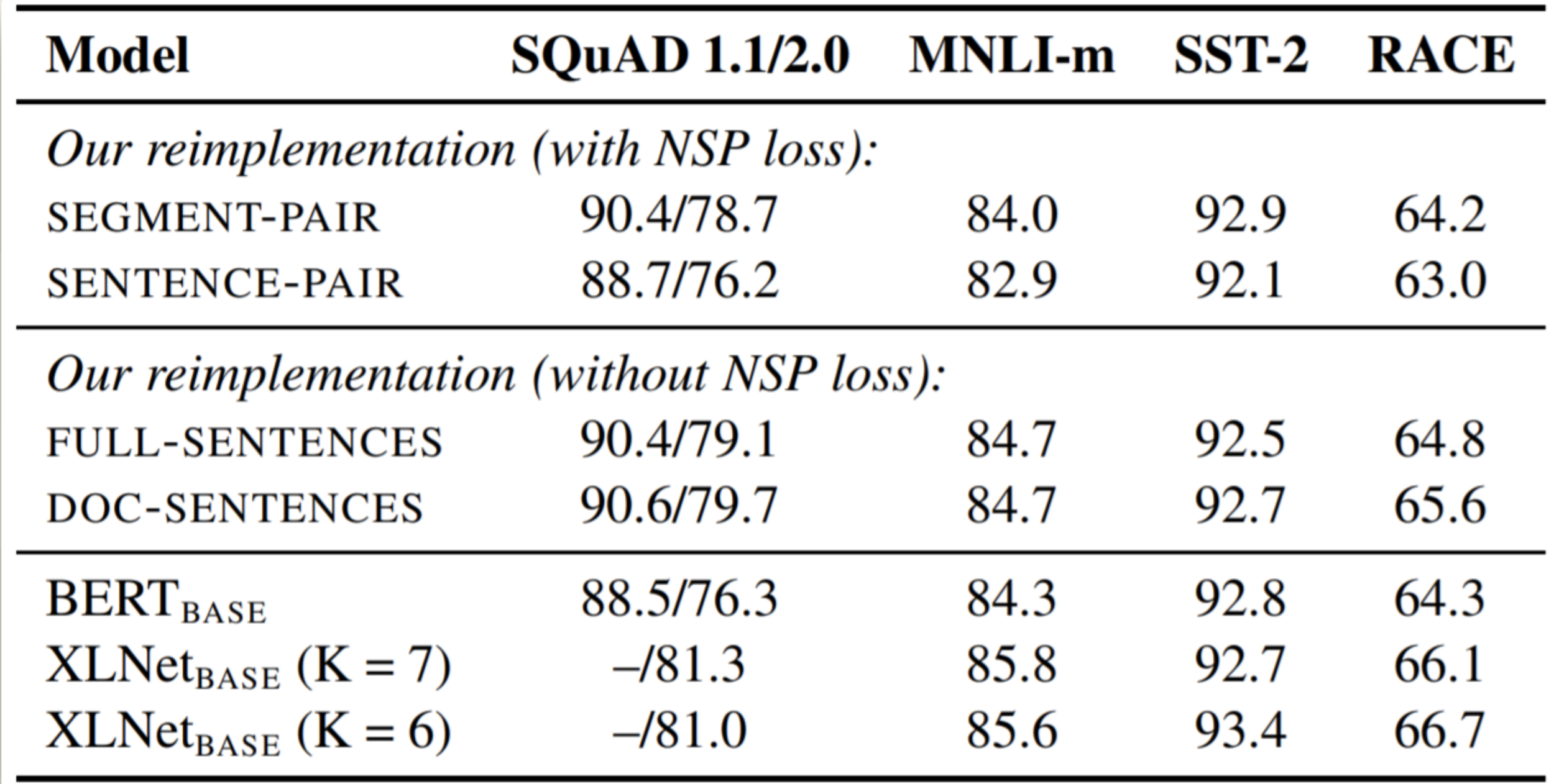
- SEGMENT-PAIR + NSP:输入包含两部分,每个部分是来自同一文档或者不同文档的 segment (segment 是连续的多个句子),这两个 segment 的 token 总数少于 512 。预训练包含 MLM 任务和 NSP 任务。这是原始 BERT 的做法
- SENTENCE-PAIR + NSP:输入也是包含两部分,每个部分是来自同一个文档或者不同文档的单个句子,这两个句子的 token 总数少于 512 。由于这些输入明显少于 512 个 tokens,因此增加 batch size 的大小,以使 tokens 总数保持与 SEGMENT-PAIR + NSP 相似。预训练包含 MLM 任务和 NSP 任务
- FULL-SENTENCES:输入只有一部分(而不是两部分),来自同一个文档或者不同文档的连续多个句子,token 总数不超过 512 。输入可能跨越文档边界,如果跨文档,则在上一个文档末尾添加标志文档边界的 token 。预训练不包含 NSP 任务
- DOC-SENTENCES:输入只有一部分(而不是两部分),输入的构造类似于 FULL-SENTENCES,只是不需要跨越文档边界,其输入来自同一个文档的连续句子,token 总数不超过 512 。在文档末尾附近采样的输入可以短于 512 个 tokens, 因此在这些情况下动态增加 batch size 大小以达到与 FULL-SENTENCES 相同的 tokens 总数。预训练不包含 NSP 任务
扩大Batch Size
公认的因素:降低batch size会显著降低实验效果,具体可参考BERT,XLNet目录的相关Issue。
Roberta 作者也证实了这一点。
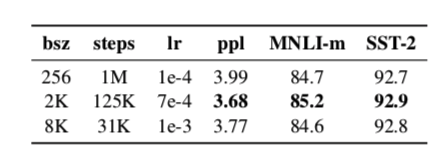
其中,bsz 是 Batch Size;steps 是训练步数(为了保证 bsz*steps 近似相同,所以大 bsz 必定对应小 steps);lr 是学习率;ppl 是困惑度,越小越好;最后两项是不同任务的准确率。
文本编码
- 基于 char-level :原始 BERT 的方式,它通过对输入文本进行启发式的词干化之后处理得到。
- 基于 bytes-level:与 char-level 的区别在于bytes-level 使用 bytes 而不是 unicode 字符作为 sub-word 的基本单位,因此可以编码任何输入文本而不会引入 UNKOWN 标记。
Albert
最近在 NLP 领域的研究趋势是使用越来越大的模型,以获得更好的性能。ALBERT 的研究表明,无脑堆叠模型参数可能导致效果降低
在论文中,作者做了一个有趣的实验
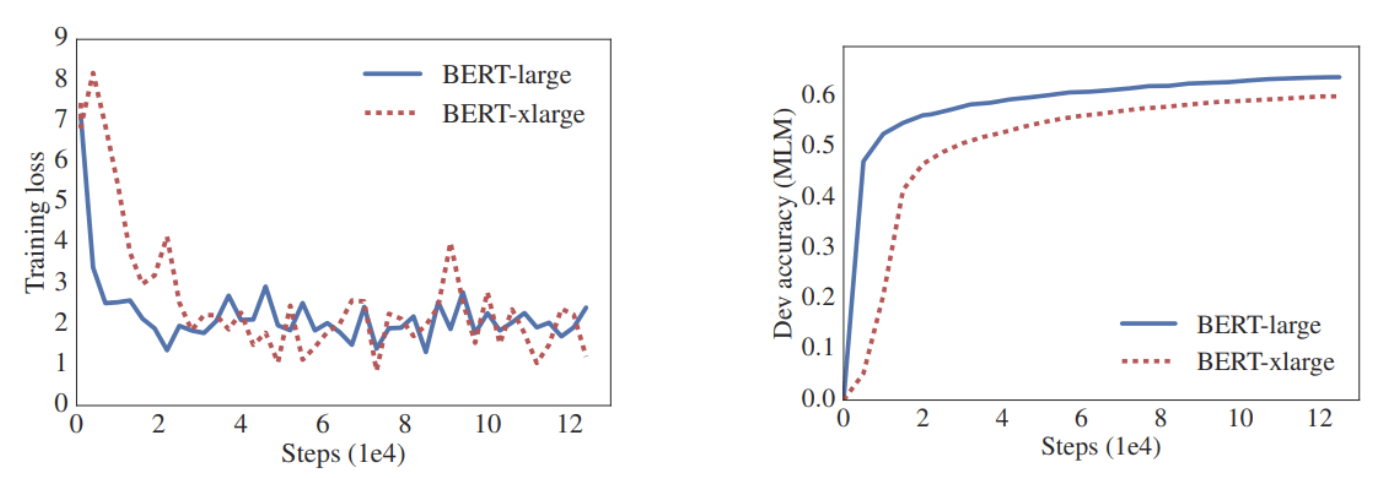
如果更大的模型可以带来更好的性能,为什么不将最大的 BERT 模型 (BERT-large) 的隐含层单元增加一倍,从 1024 个单元增加到 2048 个单元呢?
他们称之为 “BERT-xlarge”。令人惊讶的是,无论是在语言建模任务还是阅读理解测试(RACE)中,这个更大的模型的表现都不如 BERT-large
概述
ALBERT 利用了参数共享、矩阵分解等技术大大减少了模型参数,用 SOP(Sentence Order Prediction) Loss 取代 NSP(Next Sentence Prediction) Loss 提升了下游任务的表现。但是 ALBERT 的层数并未减少,因此推理时间(Inference Time)还是没有得到改进。不过参数减少的确使得训练变快,同时 ALBERT 可以扩展到比 BERT 更大的模型(ALBERT-xxlarge),因此能得到更好的表现
具体的创新部分有三个:
- embedding 层参数因式分解
- 跨层参数共享
- 将 NSP 任务改为 SOP 任务
Factorized Embedding Parameterization
原始的 BERT 模型以及各种依据 Transformer 的预训连语言模型都有一个共同特点,即 E=H,其中 E 指的是 Embedding Dimension,H 指的是 Hidden Dimension。这就会导致一个问题,当提升 Hidden Dimension 时,Embedding Dimension 也需要提升,最终会导致参数量呈平方级的增加。
所以 ALBERT 的作者将 E 和 H 进行解绑,具体的操作就是在 Embedding 后面加入一个矩阵进行维度变换。E 的维度是不变的,如果 H 增大了,我们只需要在 E 后面进行一个升维操作即可
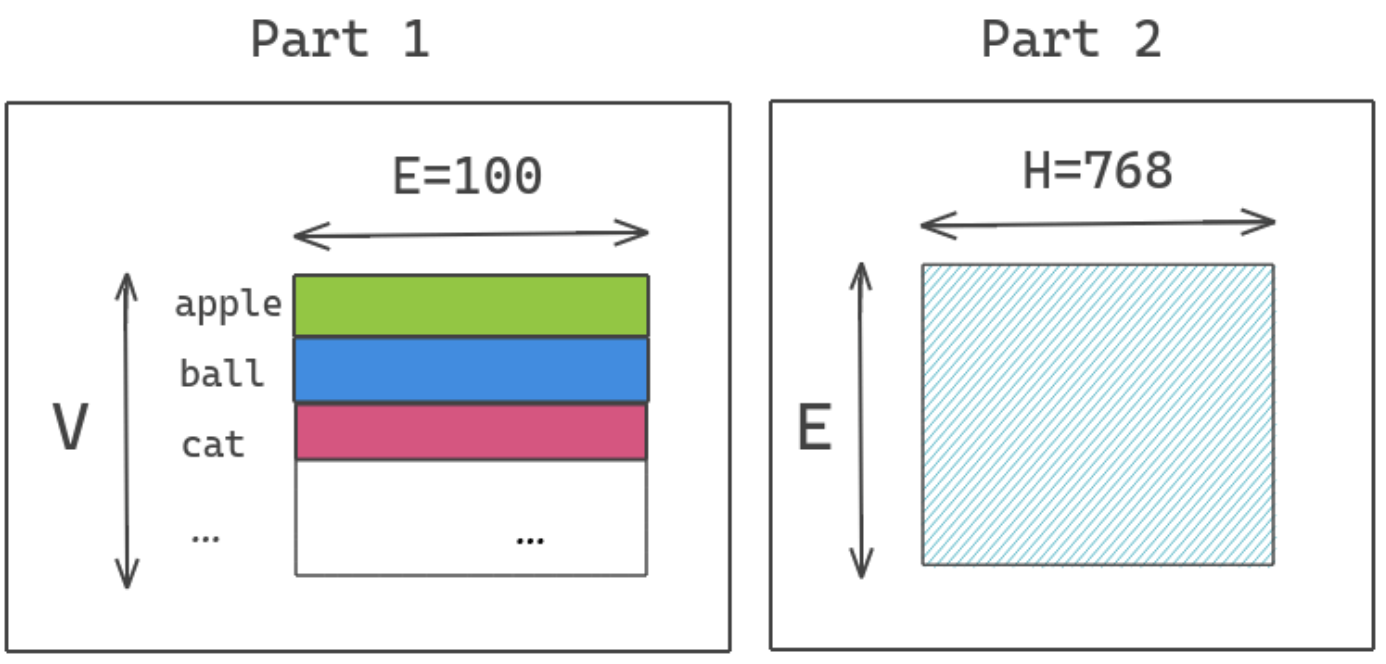
所以,ALBERT 不直接将原本的 one-hot 向量映射到 hidden space size of H,而是分解成两个矩阵,原本参数数量为 V∗H,V 表示的是 Vocab Size。分解成两步则减少为 V∗E+E∗H,当 H 的值很大时,这样的做法能够大幅降低参数数量
V∗H=30000∗768=23,040,000
V∗E+E∗H=30000∗256+256∗768=7,876,608
举个例子,当 V 为 30000,H 为 768,E 为 256 时,参数量从 2300 万降低到 780 万
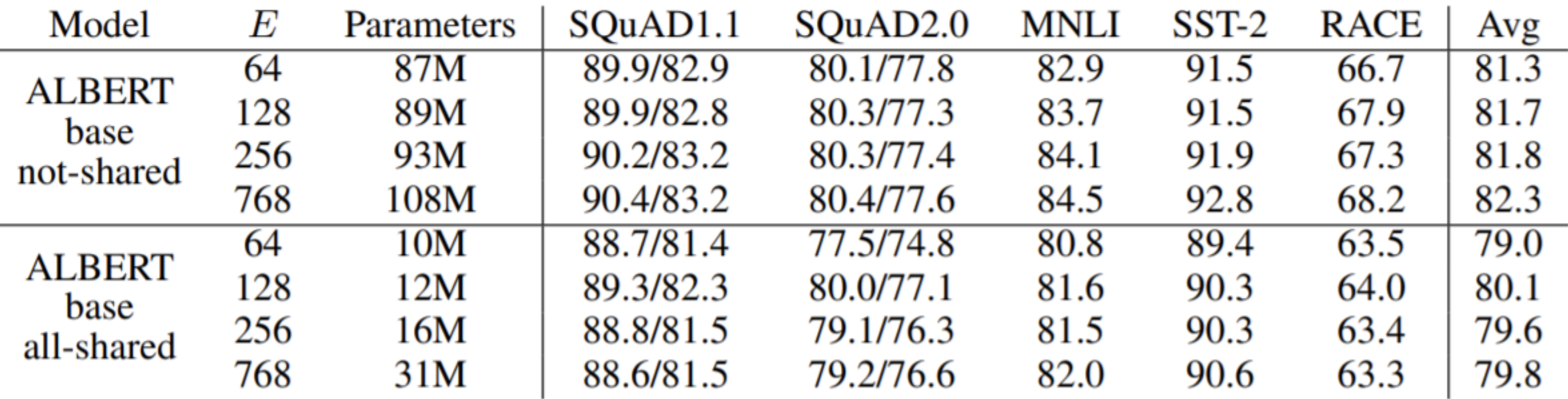
通过因式分解 Embedding 的实验可以看出,对于参数不共享的版本,随着 E 的增大,效果是不断提升的。但是参数共享的版本似乎不是这样,E 最大并不是效果最好。同时也能发现参数共享对于效果可能带来 1-2 个点的下降
1 | def __init__(self): |
Cross-Layer Parameter Sharing
传统 Transformer 的每一层参数都是独立的,包括各层的 self-attention、全连接。这样就导致层数增加时,参数量也会明显上升。之前有工作试过单独将 self-attention 或者全连接层进行共享,都取得了一些效果。ALBERT 作者尝试将所有层的参数进行共享,相当于只学习第一层的参数,并在剩下的所有层中重用该层的参数,而不是每个层都学习不同的参数
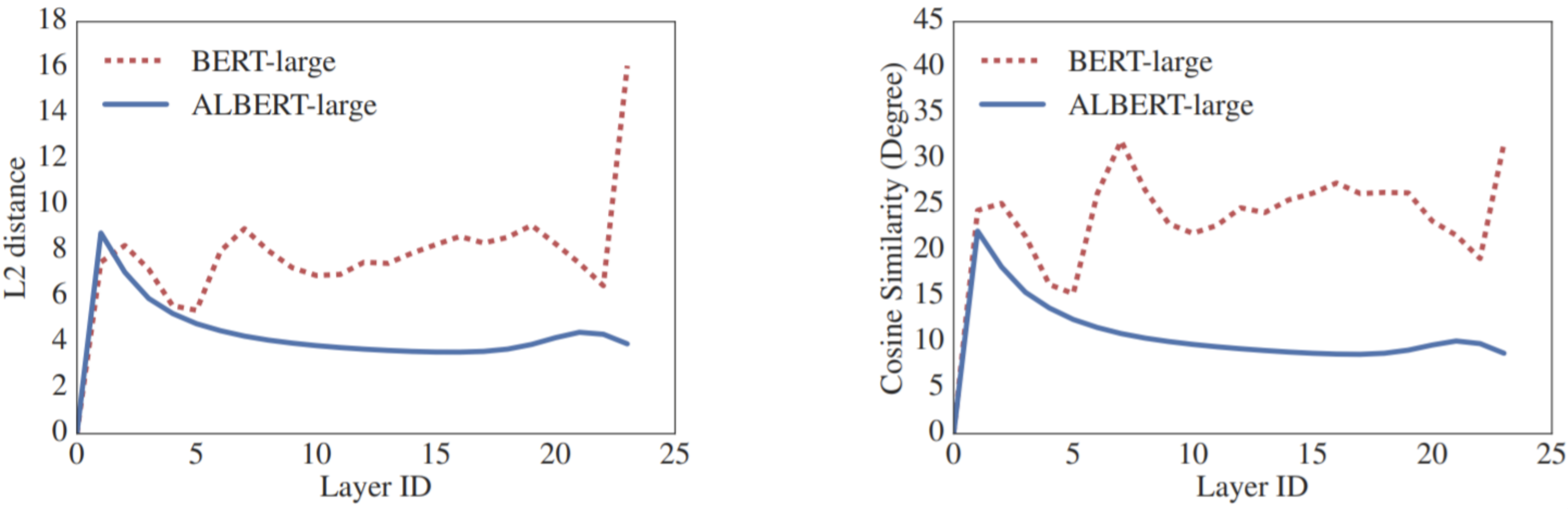
使用参数共享提升了模型 的稳定性,曲线更平滑了。
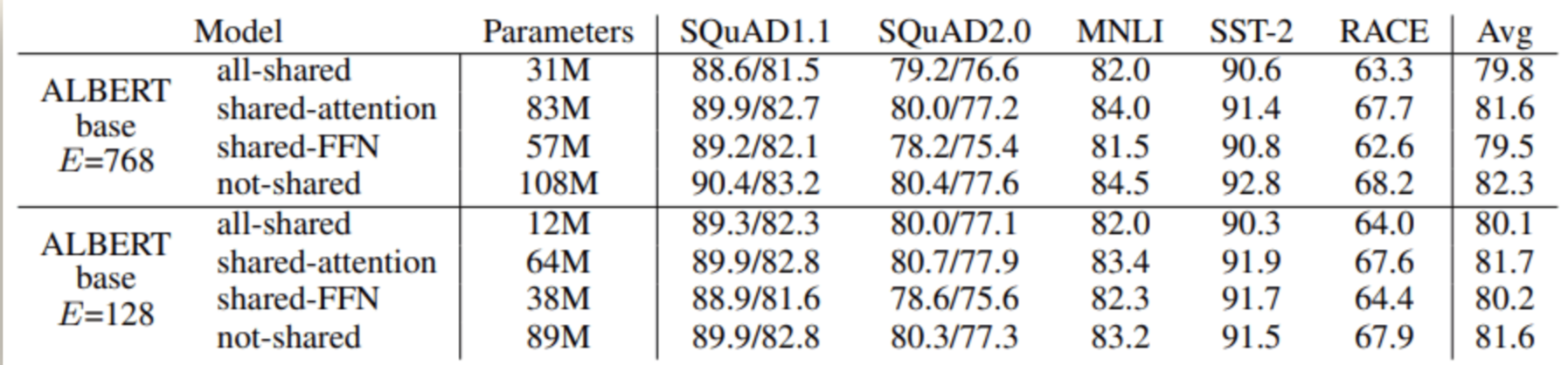
BERT-base 和 ALBERT 使用相同的层数以及 768 个隐藏单元,结果 BERT-base 共有 1.1 亿个参数,而 ALBERT 只有 3100 万个参数。通过实验发现,feed-forward 层的参数共享会对精度产生比较大的影响;共享注意力参数的影响是最小的
1 | # 参数共享例子 |
Sentence-Order Prediciton (SOP)
BERT 引入了一个叫做下一个句子预测的二分类问题。这是专门为提高使用句子对,如 “自然语言推理” 的下游任务的性能而创建的。但是像 RoBERTa 和 XLNet 这样的论文已经阐明了 NSP 的无效性,并且发现它对下游任务的影响是不可靠的
因此,ALBERT 提出了另一个任务 —— 句子顺序预测。关键思想是:
- 从同一个文档中取两个连续的句子作为一个正样本
- 交换这两个句子的顺序,并使用它作为一个负样本

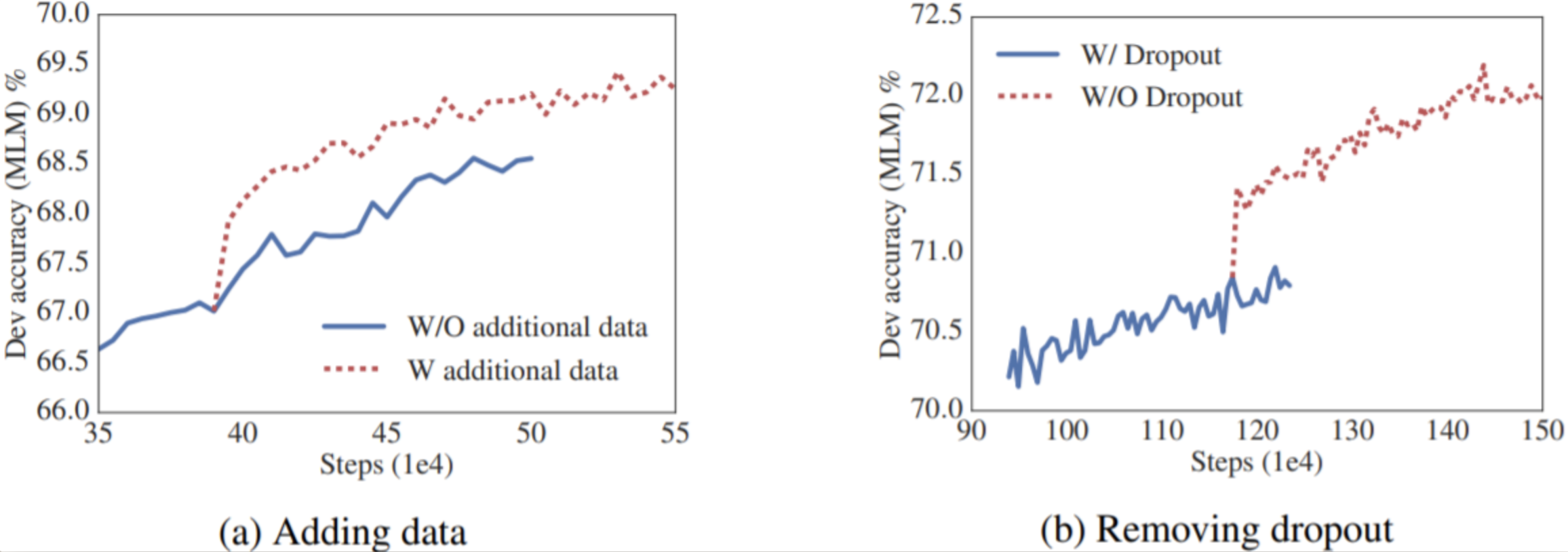
Adding Data & Remove Dropout
以上 ALBERT 都是使用跟 BERT 相同的训练数据。但是增加训练数据或许可以提升模型的表现,于是 ALBERT 加上 STORIES Dataset 后总共训练了 157G 的数据。另外,训练到 1M 步的时候,模型还没有对训练集 Overfit,所以作者直接把 Dropout 移除,最终在 MLM 验证集上的效果得到了大幅提升
Conclusion
刚开始看这篇文章是很惊喜的,因为它直接把同等量级的 BERT 缩小了 10 + 倍,让普通用户有了运行可能。但是仔细看了实验后才发现参数量的减小是需要付出代价的
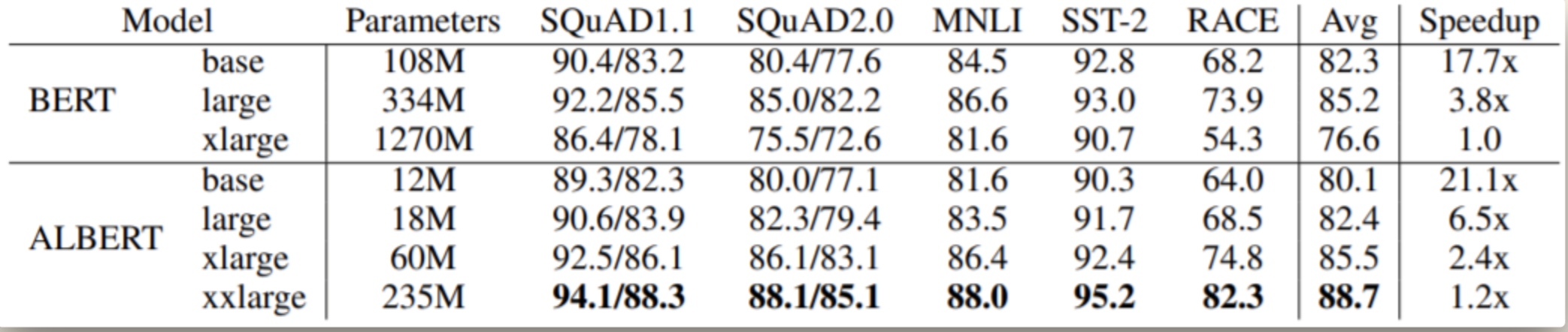
需要注意的是,Speedup 是训练时间而不是 Inference 时间。Inference 时间并未得到改善,因为即使是使用了共享参数机制,还是得跑完 12 层 Encoder,故 Inference 时间跟 BERT 是差不多的
实验用的参数如下
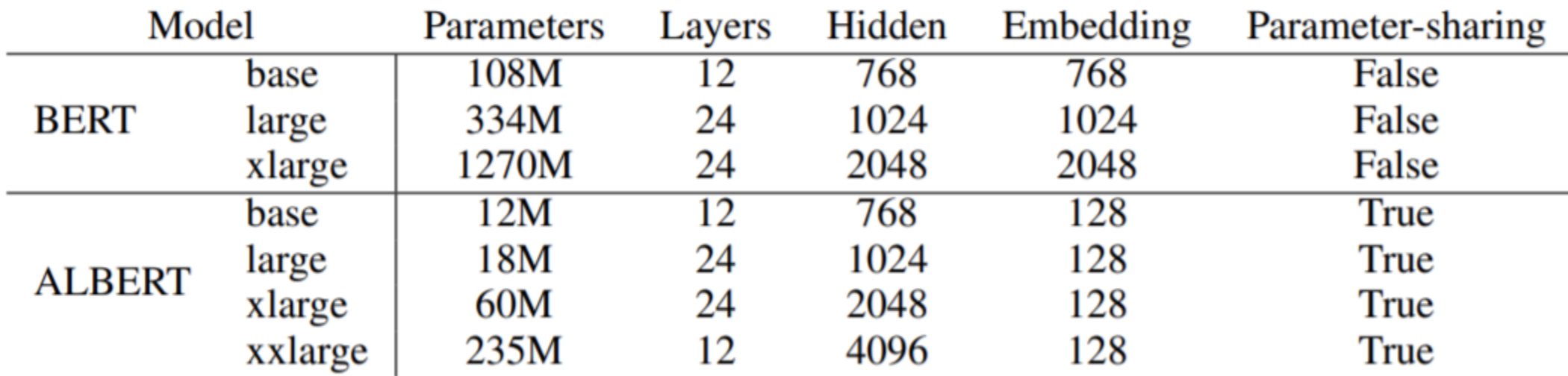
可以得出的结论是:
- 在相同的训练时间下,ALBERT 得到的效果确实比 BERT 好
- 在相同的 Inference 时间下,ALBERT base 和 large 的效果都没有 BERT 好,而且差了 2-3 个点,作者在最后也提到了会继续寻找提高速度的方法(Sparse attention 和 Block attention)
另外,结合 Universal Transformer 可以想到的是,在训练和 Inference 阶段可以动态地调整 Transformer 层数(告别 12、24、48 的配置)。同时可以想办法去避免纯参数共享带来的效果下降,毕竟 Transformer 中越深层学到的任务相关信息越多,可以改进 Transformer 模块,加入记忆单元、每层个性化的 Embedding
 wechat
wechat alipay
alipay





