协同注意力和自注意力的区别(DCN+)
协同注意力和自注意力的区别(DCN+)
读阅读理解QA的论文发现co-attention没见过,self-attention和attention又忘得差不多了。
就先读了一下DCN和DCN+的论文
DYNAMIC COATTENTION NETWORKS FOR QUESTION ANSWERING
DCN+: MIXED OBJECTIVE AND DEEP RESIDUAL COATTENTION FOR QUESTION ANSWERING+
注意力机制有很多种变形,这里我只考虑最近接触可能会用的。
- soft&hard attention
- key-value pair attention
- self-attention
- Multi-head attention
- co-attention
attention
注意力机制就是计算机模仿人的注意力,对信息分配一个权重,对关注的信息分配较大的权重,不重要的信息反之。
例如,我们的视觉系统倾向于关注图像中辅助判断的部分信息,并忽略掉不相关的信息。同样,在涉及语言或视觉的问题中,输入的某些部分可能会比其他部分对决策更有帮助。例如,在翻译和总结任务中,输入序列中只有某些单词可能与预测下一个单词相关。同样,在image-caption问题中,输入图像中只有某些区域可能与生成caption的下一个单词更相关.
soft和hard的区别
Soft attention是一种全局的attention,其中权重被softly地放在源图像所有区域
Hard attention一次关注图像的一个区域,采用0-1编码,时间花费较少,但是不可微分,所以需要更复杂的技术来进行训练
在机器学习中soft 常常表示可微分,比如sigmoid和softmax机制,而hard常常表示不可微分
soft hard attention机制是在图像生成标题任务中被提出的,其原始任务如下:

上面是soft 下面是hard,我们可以看到,soft的权重是每次被放置在整张图像上,注重强调的部分(越白)的数值越接近1,越黑越接近0
下面的一排非黑即白,白色区域为1,黑色区域为0。
现在主流用soft比较多,其主要步骤有两个:
针对输入$X=[x_1,x_2…x_3]$ (提取对象)
- 1计算输入信息熵的注意力分布
- 2根据注意力分布计算输入信息的加权平均
计算注意力分布
给定一个和任务相关的查询向量q,用注意力变量$z \in [1,N]$ 表示被选择信息的索引位置,即 z=i,表示选择了第i个输入信息。
其中查询向量q可以是动态生成的,也可以是可学习的参数。
Soft-attention计算分布
在给定输入信息x的查询变量q下,选择第i个输入信息的概率。
其中$\alpha_i$ 为注意力分布,$s(x_i,q)$ 为打分函数。
常用的打分函数:
- 加性模型: $s(x_i,q) = v^Ttanh(Wx_i+Vq)$
- 双线性:$s(x_i,q)=x_i^TWq$
- 点积:$s(x_i,q)=x_i^Tq$
- 缩放点积:$s(x_i,q)= \frac{x_i^Tq}{d^{\frac{1}{2}}}$
加权平均
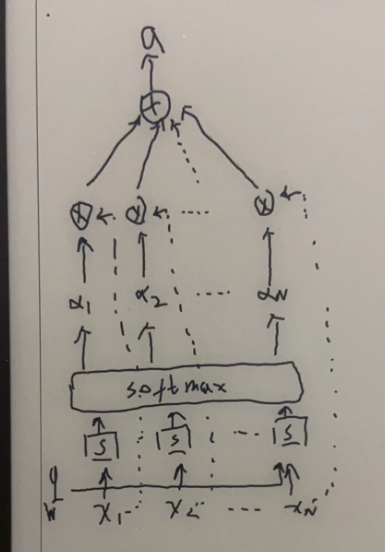
key-value pair attention
其实就是输入信息是(k,v)键值对形式。$(K,V)=[(k_1,v_1),(k_2,v_2),…,(k_n,v_n)]$
其中键用来计算注意力分布$\alpha_i$,值用来计算聚合信息
当K=V时,键值对注意力=柔性注意力
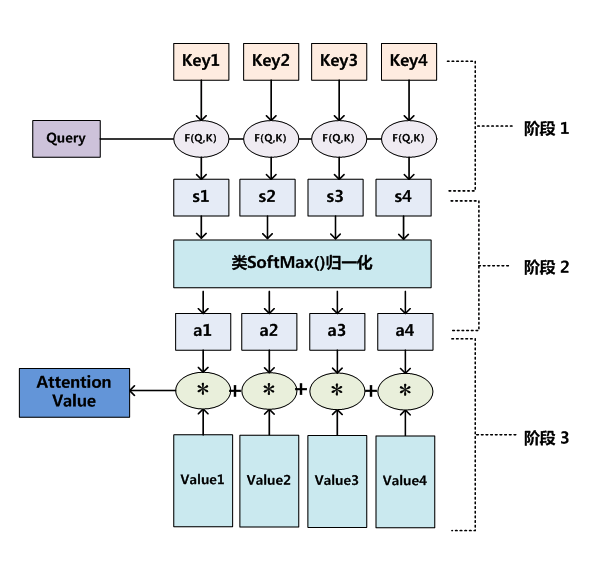
如上图,计算注意力分布
self-attention
查询向量q、键向量k、值向量v , 都等于输入向量序列。
可参考下面的多头自注意力
multi-head self attention
查询向量Q、键向量K、值向量V , 都等于输入向量序列的线性表示。
假设输入序列 $X=[x_1,x_2,…,x_n]\in R^{d_1\times R}$,输出的是$H=[h_1,h_2,…,h_n]\in R^{d_2\times R}$
其中$i,j\in[1,N]$ 为输出和输入的向量序列位置
Transformer里用的是上面的缩放点积打分函数s
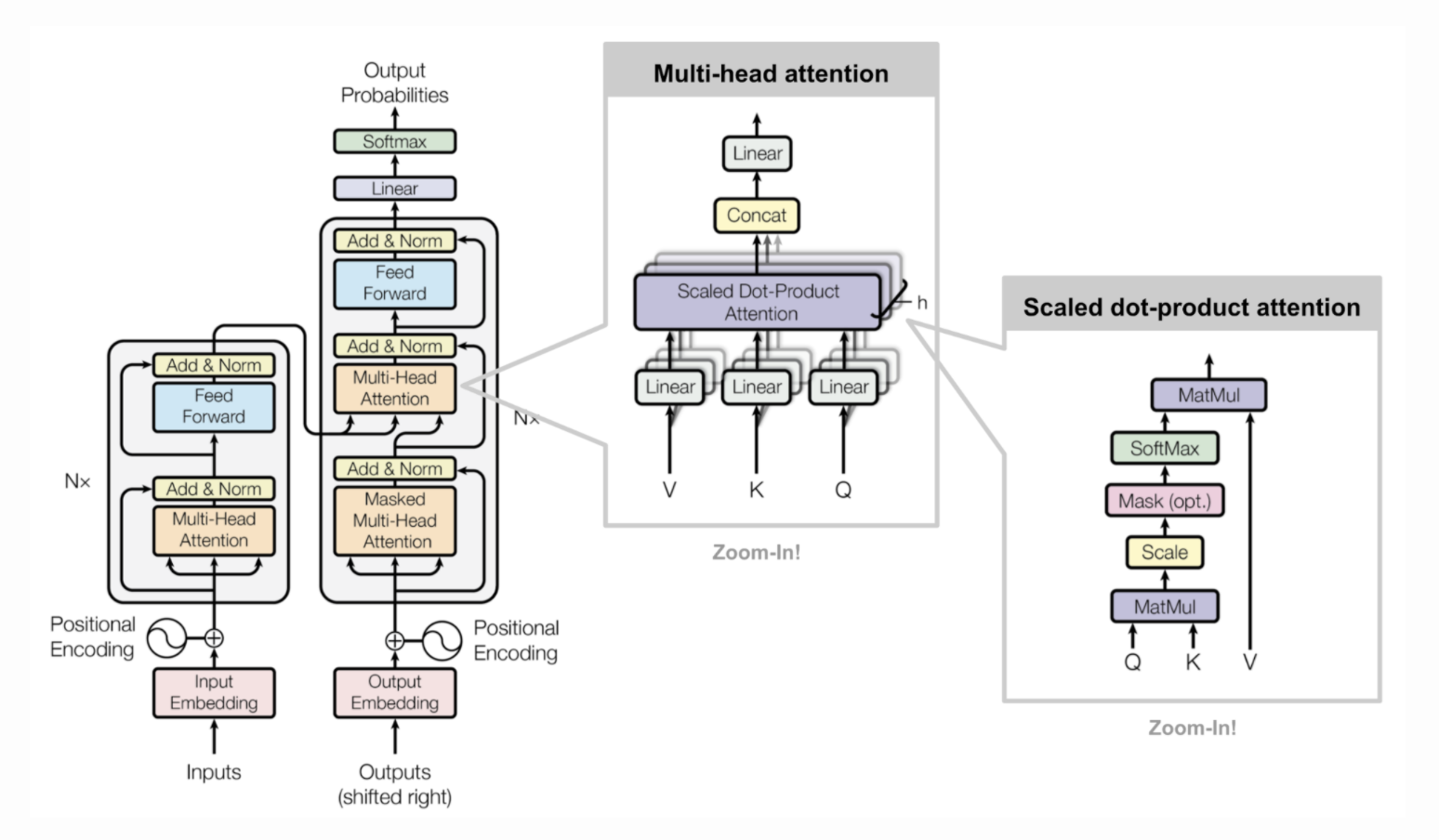
如果在encoder-decoder架构中
attention一般用在encoder和decoder之间做衔接的部分
self-attention 一般在块内部
比如在翻译任务中,Sourse和Target内部通常用self-attention提取特征,两者之间用attention
DCN
Co-attention 共同注意力机制就从DCN讲起,DCN是一个QA模型,为了解决然而,问答场景中单次通过的性质,对于不正确答案的局部最大值恢复的问题。它首先融合了问题和文档的共同依赖表示,以便集中于两 者的相关部分。然后,动态指向解码器迭代潜在的答案跨度,该迭代过程使模型能够从对应于不正确答案的初始局部最大值中恢复。这个是论文的话,其实不是coattention来恢复的,是动态指向解码器。
其实就是因为一段内容里可能多多个正确答案,但是我们在模型输出的时候选的是最大概率的开始和结尾,DCN用一种迭代的方式,以找到局部极值概率点来当做答案。
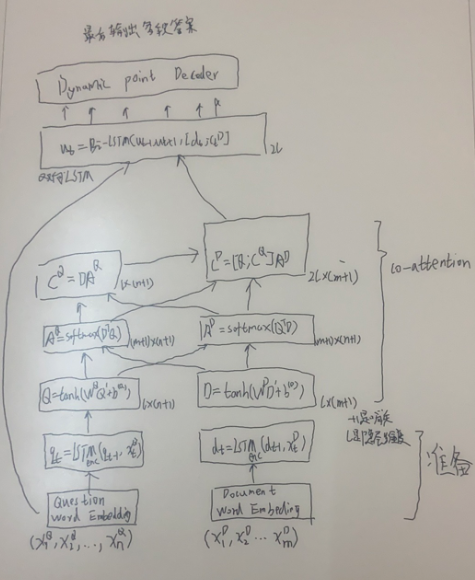
所以,co-attention就是带着问题去阅读,融合问题和文档的特征调整的attention机制。
Dynamic Decoder
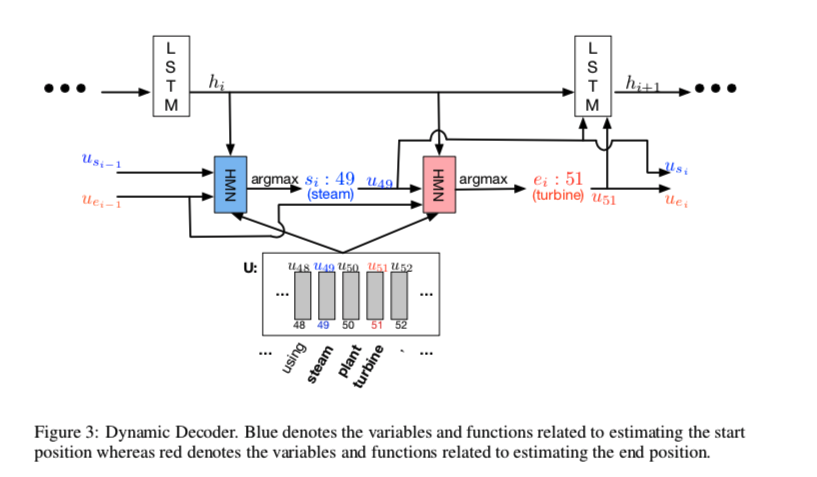
HMN
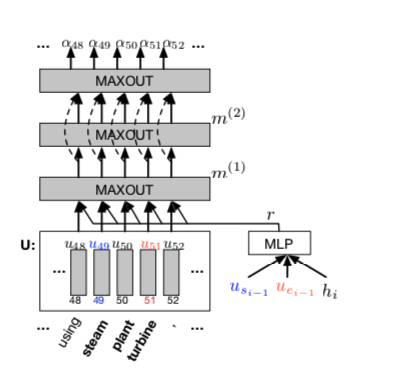
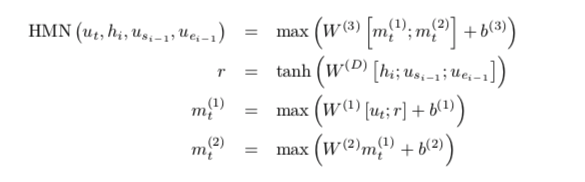
max运算计算张量第一维上的最大值。第一个maxout层和最后一个maxout层的输出之间存在高速连接。
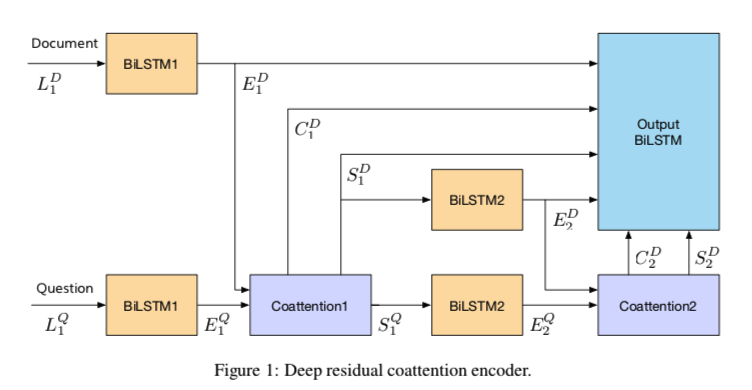
DCN+
 wechat
wechat alipay
alipay





