HotpotQA数据集
HotpotQA数据集:A Dataset for Diverse, Explainable Multi-hop Question Answering
官方地址:https://hotpotqa.github.io/index.html
为解决当前QA数据集不能训练系统回答复杂问题和提供可解释的答案问题而提出。
摘要
HotpotQA基于113k(十一万三千)个维基百科问答对,有四个特点:
- 问题需要对多个支持文档进行查找和推理才能回答
- 问题是多样的,不受任何预先存在的知识库或知识模式的限制
- 提供句子级别的推理所需的事实支持,允许QA系统在强有力的监督下进行推理和解释预测
- 提供了一种新型的拟事实比较问题来测试QA系统提取相关事实和进行必要比较的能力。

所构建的多跳问答数据集样式
贡献
构建维基百科超链接图
使用整个英文维基百科做为语料库。
- 维基百科文章中的超链接通常自然地涉及上下文中的两个(已经消除歧义的)实体之间的关系,这可能被用来促进多跳推理。
- 每篇文章的第一段通常包含许多可以有意义地查询的信息。
基于这些观察,我们从所有维基百科文章的第一段中提取了所有的超链接。用这些超链接,构建了一个有向图G,edge(a,b) 表示超链接从文章的第一段a 到 文章b。
生成候选段落对
为了生成用于与超连接图G的多跳问题回答的有意义的段落对,引入了一个桥梁实体“bridge entity”。
比如问题是:when was the singer and songwriter of Radiohead born?
为了回答这个问题,我们需要推理出 “singer and songwriter of Radiohead”是“Thom Yorke”
在从文章中计算出他的生日。“Thom Yorke”就是桥梁实体。
对于G中的edge(a,b)。桥梁实体通常是链接a和文档b的桥梁
也就是说打开维基百科,第一段全是超链接的段就是a,超链接上面的名字通常是桥梁实体,链接过去的文章就是b。
文章b通常确定a和b之间共享上下文的主题,但并不是所有文章b都适合收集多跳问题。例如,像国家这样的实体在维基百科中经常被提及,但与所有传入链接不一定有太多共同之处。
比较问题
收集了新一种类型的多跳问题——比较问题。
其主要思想是,比较来自同一类别的两个实体通常会产生有趣的多跳问题
例如:Who has played for more NBA teams, Michael Jordan or Kobe Bryant?
还在比较问题中引入了是/否问题子集。
回答这些问题通常需要算术比较,例如比较给定的出生日期的年龄。
收集支持事实
为了增强问答系统的可解释性,我们希望它们在生成答案时输出一组得出答案所需的支持事实。
这些佐证事实可以作为关注哪些判决的有力监督。此外,现在可以通过将预测的支持事实与基础事实进行比较来检验模型的解释能力。
处理和基准设置
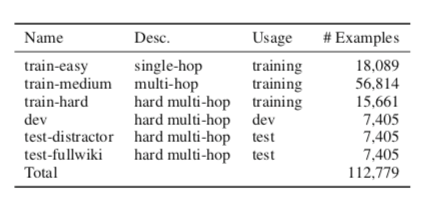
train_easy: 单跳问题 18089 个。
train_medium: 56,814个,占多跳示例的60% ,是baseline可以回答正确的问题。
把难的问题分为四个子集:
train_hard: 15661个
dev : 7405个
test-distractor :7405个
test-fullwiki : 7405个
Test-distractor 和 Test-fullwiki 是两个基线,官网上的两个表单。
Distractor
用tfidf检索8个段落作为干扰项,混合两个gold段落(用来收集问题和答案) shuffle构成干扰设置。()
Fullwiki
要求模型回答所有维基百科文章的第一段(没有指定黄金段落)来充分测试模型定位相关事实以及对它们进行推理的能力。
(真正的野外推理)
两个test不能同时用,答案会泄露。
数据集分析
分析数据集中涵盖的问题类型、答案类型和多跳推理类型。
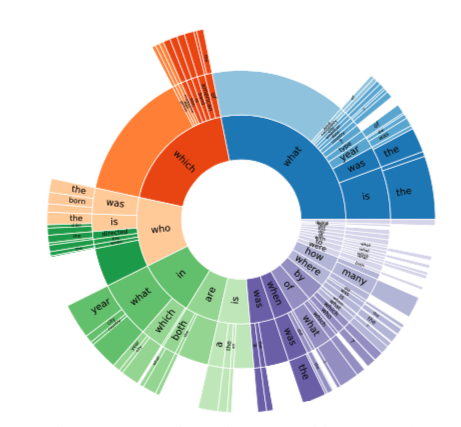
问题类型
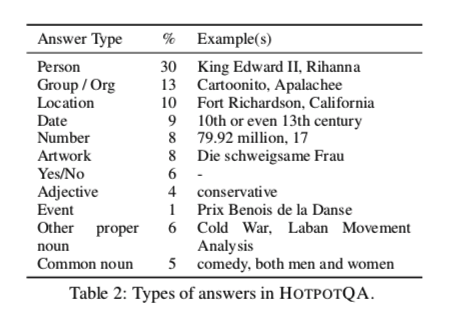
答案类型
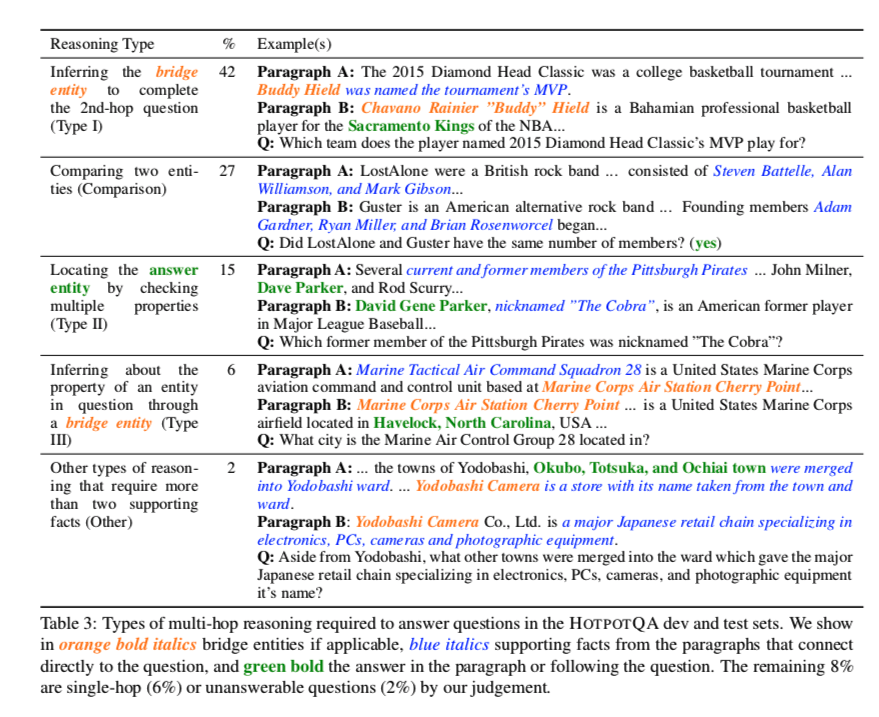
推理类型
 wechat
wechat alipay
alipay





