
数组范围内计数
数组范围内计数数组为 3,2,2,3,1, 查询为(0,3,2)。
意思是在数组里下标 0-3 这个范围上,有几个 2?
假设给一个数组 arr,对这个数组的查询非常频繁请返回所有查询的结果。
给出:arr[ ]
要查多个范围:
[[0,3,2],
[1,4,0]]
结果返回:[第一个数组结果,第二个数组结果]
暴力解法直接遍历肯定不可以。
解法一、做一个map映射,遍历一遍数组,将每个值和每个值出现的下标位置数组做成key-value
在根据查询的V,在所在值的数组内做二分查找。
1234567891011121314151617181920212223242526272829303132333435363738394041public static class QueryBox2 { private HashMap<Integer, ArrayList<Integer>> map; public QueryBox2(int[] arr) { map = new HashMap< ...

海华中文阅读理解比赛梳理/多卡并行/transformers
海华中文阅读理解比赛梳理文文言文古诗词现代诗词
1 字词解释 2 标点符号作用 3 句子解释 4 填空 5 选择正读音 6 推理总结 7 态度情感 8 外部知识
不需要先验知识的问题
如一个问题能够在文档中进行匹配,回答起来就几乎不需要先验知识需要先验知识的问題
1、关于语言的知识:需要词汇/语法知识,例如:习语、谚语、否定、反义词、同义词语法转换
2、特定领域的知识:需要但不限于些事实上的知识,这些事实与特定领域的概念概念定义和属性,概念之间的关系
3、一般世界的知识:需要有关世界如何运作的一般知识,或者被称为常识。比如百科全书中的知识
这个赛题的难点是有些预训练语言模型没有学到的先验知识怎么学
赛题概述
train 训练集提供了6313条数据数据格式是和中小学生做的阅读题一样,一篇文章有两到三个问题每个问题有两到四个答案选项。
validation 验证集提供了1000条数据。
原始单条数据格式如下:
123456789101112131415161718192021222324252627{ "ID": "0001", ...

bfprt算法
bfprt算法 求TopK中位数的中位数算法 最坏时间复杂度 $O(n)$
在做topk问题时,最容易想到的就是先对所有数据进行一次排序,然后取其前k个。但问题有二:
快排时间复杂度 $O(nlogn)$ ,但最坏时间复杂度 $O(n^2)$
我们只要前k大的,而对其余的数也进行了排序,浪费了大量排序时间。
除了这种方法堆排序也是一个比较好的选择,可以维护一个大小为k的堆,时间复杂度为 $O(nlogk)$
堆排序topk
Heap是一种数据结构具有以下的特点:1)完全二叉树;2)heap中存储的值是偏序;
Min-heap: 父节点的值小于或等于子节点的值;Max-heap: 父节点的值大于或等于子节点的值;
一般都用数组来表示堆,i结点的父结点下标就为(i–1)/2。它的左右子结点下标分别为2 i + 1和2 i + 2
堆中每次都删除第0个数据。为了便于重建堆,实际的操作是将最后一个数据的值赋给根结点,然后再从根结点开始进行一次从上向下的调整。
1234567891011121314151617181920212223242526272829303132# 大根堆比较器 ...

RoBERTa & Albert
RoBERTa & Albert2021年了,bert的改进体也越来越多,Roberta和Albert是比较出名的两个改进体。
Roberta主要针对bert的预训练任务如NSP,mask进行改进。并且扩大了batchsize和使用更长的序列训练,这两点可能在长文本竞赛上有作用。
Albert主要针对bert参数量太大,训练慢来进行改进。引入了跨层参数共享,embedding解绑分解,取消dropout和添加SOP预训练任务。
RoBERTa
使用更大的batch在更大的数据集上对Bert进行深度训练
不再使用NSP(Next Sentence Prediction)任务
使用更长的序列进行训练
动态改变训练数据的MASK模式
静态Masking vs 动态Masking
静态Masking:在数据预处理期间Mask矩阵就已经生成好了,每个样本只会进行一次随机Mask,每个epoch都是相同的。
修改版静态Masking: 在预处理时将数据拷贝10份,每一份拷贝都采用不同的Mask,也就是说,同样的一句话有十种不同的mask 方式,然后每份数据都训练N/10个epoch
动态 ...

Heterogeneous Graph Neural Network
Heterogeneous Graph Neural Network摘要挑战:不仅是因为需要合并由多种类型的节点和边组成的异质结构(图)信息,而且还因为需要考虑与每个节点相关联的异质属性或内容(例如,文字或图像)。
方法:C1引入了一种带重启的随机游走策略,对每个节点的固定大小的强相关异构邻居进行采样,并根据节点类型对它们进行分组。
接下来,设计一个包含两个模块的神经网络体系结构,用来聚合那些采样的相邻节点的特征信息。
第一个模块C2:对异构内容的“深度”特征交互进行编码,并为每个节点生成内容Embedding。
第二个模块C3:聚合不同相邻组(类型)的内容(属性)嵌入,并通过考虑不同组的影响来进一步组合它们,以获得最终的节点嵌入。
HetGNN用途:在边链接预测、推荐、节点分类和聚类以及归纳节点分类和聚类等各种图挖掘任务
异质图
学术图中,
关系:作者与论文(写作)、论文与论文(引文)、论文与期刊(出版)
此外,该图中的节点携带属性 如作者有id属性、文本有论文摘要属性。
挑战
1:现有的GNN大多只聚合直接(一阶)相邻节点的特征信息,特征传播过程可能会削弱远邻节点的影响。此外,“ ...

Cognitive Graph for Multi-Hop Reading Comprehension at Scale(ACL2019)
Cognitive Graph for Multi-Hop Reading Comprehension at Scale(ACL2019)ppt : https://coding-zuo.github.io/CogQA_RevealJS/
认知图谱知识图谱+认知推理+逻辑表达。认知图谱依据人类认知的双加工理论,动态构建带有上下文信息的知识图谱并进行推理。认知图谱可以被解释为“基于原始文本数据,针对特定问题情境,使用强大的机器学习模型动态构建的,节点带有上下文语义信息的知识图谱”。
认知图谱和知识图谱的区别?认知图谱是包含知识图谱的相关技术的。知识图谱的任务主要是包括知识图谱的表示、构建和存储。这些是构建知识库的过程。认知推理的底层是知识推理,而知识图谱目的是完善知识。面向知识图谱的认知推理可以基于已有的知识推理出新的知识,或者发现错误矛盾的知识。认知图谱是为了解决复杂理解问题或少样本知识图谱推理问题如歧义问题、链接困难、关系的冗余与组合爆炸等。认知推理其实更具有人脑特性,相对更动态一些,可以基于知识感知来调整推理,也可以基于推理来调整知识和感知。交叉了认知科学对人类知识的总结,有助于 ...

Multi-hop Reading Comprehension across Multiple Documents by Reasoning over Heterogeneous Graphs
Multi-hop Reading Comprehension across Multiple Documents by Reasoning over Heterogeneous Graphs京东出品19年采用异质图网络的一篇多跳阅读理解,这篇是在WikiHopQA数据集上,在没有使用预训练语言模型的情况下第一次超过人类表现。20年还有一篇在HotpotQA上的,过两天准备也读一读。前一阵子用京东在线客服和智能语音客服的时候,感觉效果不错,果然发现这两篇文章。
先说一下WikiHopQA
训练集43,738个样本,开发集5129个。候选答案个数2-79个之间,平均19.8个。文档数3-63个,平均13.7篇。每篇文档的字数4-2046字,平均100.4个字。该数据集的难度在于,要从多篇文章中找相关文档,还要依据多篇文章做推理。推理跳数的增加,与问题的相关性越来越小,统计距离较远,非参数化的检索方法如传统的TF-IDF,无法搜索到最终答案所在的上下文。如下图:
每个样本包含字段:dict_keys([‘answer’, ‘id’, ‘candidates’, ‘query’, ‘sup ...
Pytorch多GPU并行实例
Pytorch Train_Multi_GPUhttps://pytorch.org/tutorials/intermediate/ddp_tutorial.html
两种方式:
DataParallel(DP):Parameter Server模式,一张卡位reducer,实现也超级简单,一行代码。
DistributedDataParallel(DDP):All-Reduce模式,本意是用来分布式训练,但是也可用于单机多卡。
最后还有一个pycharm远程服务器的配置,还有如何在pycharm里配置run参数为:
1python -m torch.distributed.launch --nproc_per_node=4 --use_env train_multi_gpu_using_launch.py
这个行运行命令是用DistributedDataParallel时的,指定的运行参数。具体介绍在后面写。
DataParallel vs DistributedDataParallel
如果模型太大而无法容纳在单个GPU上,则必须使用 model parallel 将 ...
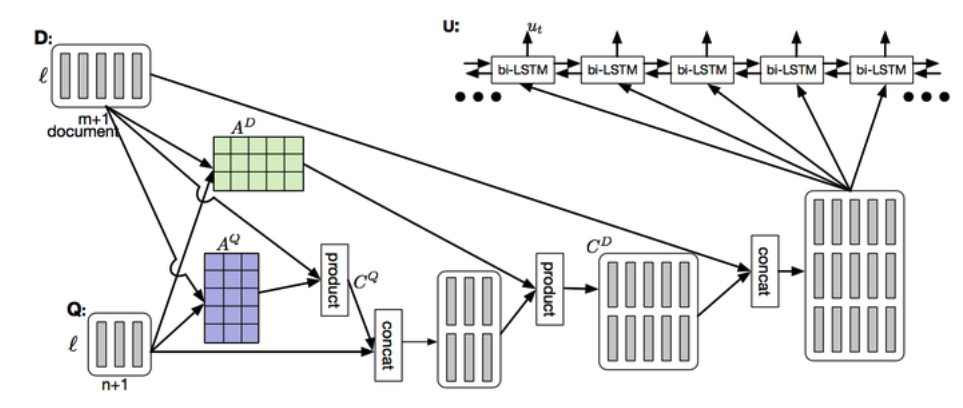
协同注意力和自注意力的区别(DCN+)
协同注意力和自注意力的区别(DCN+)读阅读理解QA的论文发现co-attention没见过,self-attention和attention又忘得差不多了。
就先读了一下DCN和DCN+的论文
DYNAMIC COATTENTION NETWORKS FOR QUESTION ANSWERING
DCN+: MIXED OBJECTIVE AND DEEP RESIDUAL COATTENTION FOR QUESTION ANSWERING+
注意力机制有很多种变形,这里我只考虑最近接触可能会用的。
soft&hard attention
key-value pair attention
self-attention
Multi-head attention
co-attention
attention注意力机制就是计算机模仿人的注意力,对信息分配一个权重,对关注的信息分配较大的权重,不重要的信息反之。
例如,我们的视觉系统倾向于关注图像中辅助判断的部分信息,并忽略掉不相关的信息。同样,在涉及语言或视觉的问题中,输入的某些部分可能会比其他部分对决策更有帮助。例如,在翻译 ...

字符串无序匹配
给定长度为 m 的字符串 aim,以及一个长度为 n 的字符串 str 问能否在 str 中找到一个长度为 m 的连续子串,使得这个子串刚好由 aim 的 m 个字符组成,顺序无所谓返回任意满足条件的一个子串的起始位置,未找到返回-1。
思路:
找到一个串和aim排序对比
123456789101112131415161718192021222324252627282930313233public static void main(String[] args) { Scanner input = new Scanner(System.in); while (input.hasNext()) { String aim = input.next(); String str = input.next(); int m = aim.length(); int i = 0; int j = m - 1; char[] ...




