Cognitive Graph for Multi-Hop Reading Comprehension at Scale(ACL2019)
Cognitive Graph for Multi-Hop Reading Comprehension at Scale(ACL2019)
ppt : https://coding-zuo.github.io/CogQA_RevealJS/
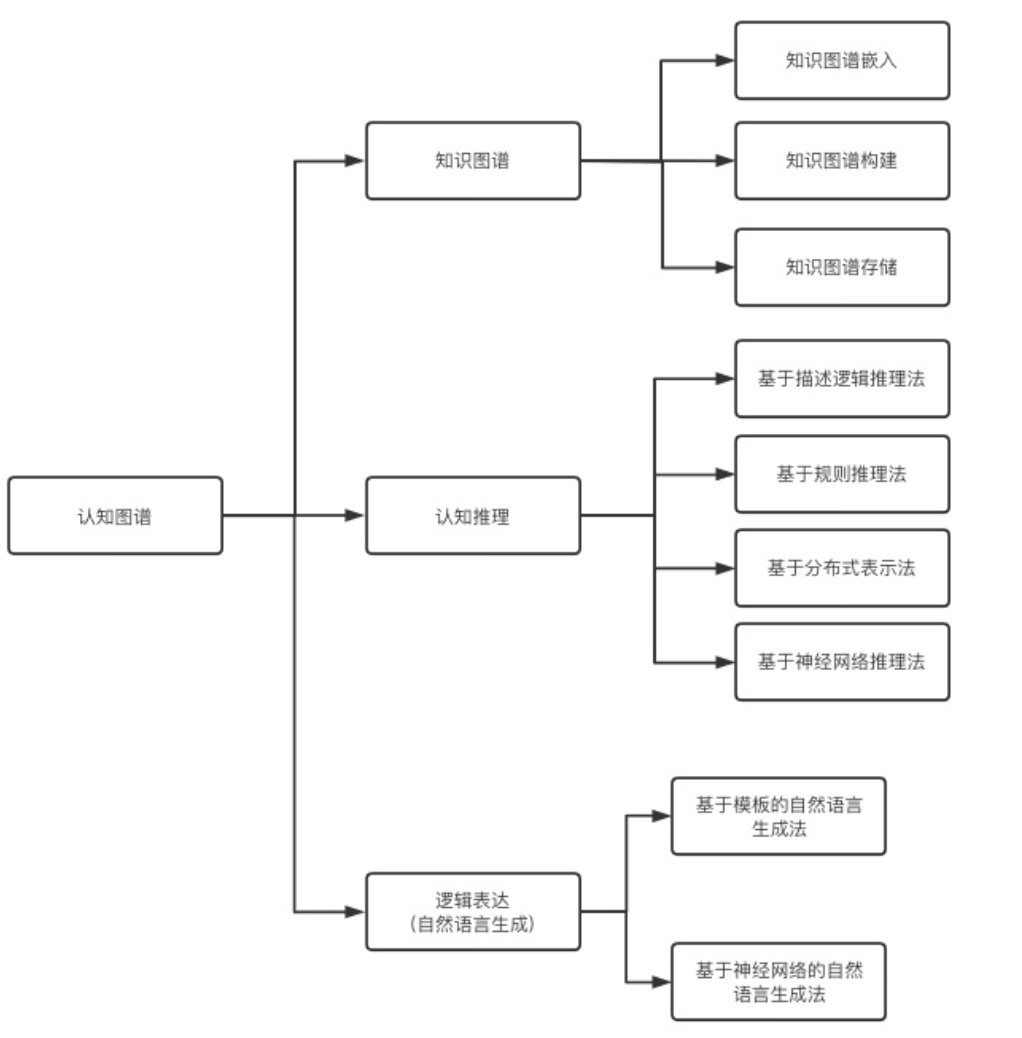
认知图谱
知识图谱+认知推理+逻辑表达。
认知图谱依据人类认知的双加工理论,动态构建带有上下文信息的知识图谱并进行推理。
认知图谱可以被解释为“基于原始文本数据,针对特定问题情境,使用强大的机器学习模型动态构建的,节点带有上下文语义信息的知识图谱”。
认知图谱和知识图谱的区别?
认知图谱是包含知识图谱的相关技术的。知识图谱的任务主要是包括知识图谱的表示、构建和存储。这些是构建知识库的过程。认知推理的底层是知识推理,而知识图谱目的是完善知识。面向知识图谱的认知推理可以基于已有的知识推理出新的知识,或者发现错误矛盾的知识。认知图谱是为了解决复杂理解问题或少样本知识图谱推理问题如歧义问题、链接困难、关系的冗余与组合爆炸等。认知推理其实更具有人脑特性,相对更动态一些,可以基于知识感知来调整推理,也可以基于推理来调整知识和感知。交叉了认知科学对人类知识的总结,有助于划分和处理知识图谱的相关问题。
认知图谱主要有三方面创新,分别对应人类认知智能的三个方面:
1.(长期记忆)直接存储带索引的文本数据,使用信息检索算法代替知识图谱的显式边来访问相关知识。
2.(系统1推理)图谱依据查询动态、多步构建,实体节点通过相关实体识别模型产生。
3.(系统2推理)图中节点产生的同时拥有上下文信息的隐表示,可通过图神经网络等模型进行可解释的关系推理。
本质上,认知图谱的改进思路是减少图谱构建时的信息损失(两元一谓),将信息处理压力转移给检索和自然语言理解算法,同时保留图结构进行可解释关系推理。
摘要
- 提出新的多跳QA框架CogQA
- 基于双过程理论System1:隐式提取,System2:显式推理
- 可以给出答案的解释路径
- 基于Bert和GNN处理HotpotQA数据集
- 评估指标F1 score
Introduction
现在的单段阅读理解机器已经超过人了,像SQuAD。但要跨过机器阅读理解和人阅读理解的鸿沟还很难。
主要有三个主要挑战:
- 理解能力:如对抗性测试所揭示的那样,单段问答模型倾向于在与问题匹配的意义中寻找答案,这不涉及复杂的推理。因此多跳阅读是要克服的。
- 可解释性:显式推理路径能够验证逻辑严格性,对质量保证系统的可靠性至关重要。数据集中给出的是无序的句子级别的解释,但我们人可以通过逻辑一步一步给出有序的、实体级别的解释。
- 大规模的(时间成本):任何QA系统都要处理大规模的知识。现在已有的DrQA是通过预检索来减少规模到几个段落的范围。这个框架是单段阅读和多段阅读的结合,但和人脑中大量记忆和知识而言是一种折中的做法。时间成本不会随着段落增加而增加。
两个系统的工作
隐式提取System1:模仿大脑通过隐式注意提取相关信息,是直觉和无意识的系统。
从段落中提取与问题相关的实体和答案日期,并对其语义信息进行编码。
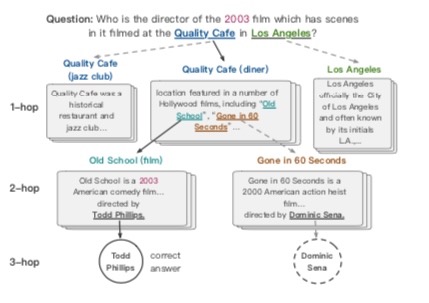
如上图,系统一从段落和语义信息中提取问题相关的实体和答案候选。
显式推理System2:在System1基础上进行有意识的的可控的推理。
系统一根据提出的问题提供给系统二资源,系统二根据信息进行深度推理,挖掘相关信息。两个系统协作,迭代的给出快慢思考。
在信息一提出出的信息图上,搜集线索。并且指导系统一更好的提取下一跳实体。
迭代直到所有可能的答案都被找到,再由系统二推理出最终答案。
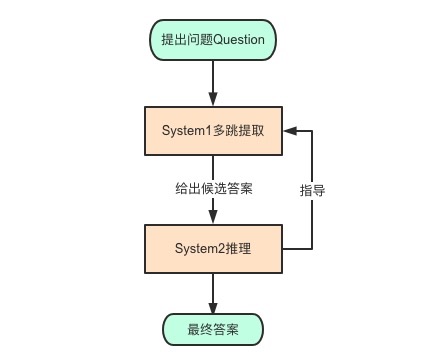
系统1(system 1)负责经验性的直觉判断,这一黑盒过程提取重要信息,并动态构建认知图谱;系统2(system 2)则在图上进行关系推理,由于认知图谱保留了实体节点上语义信息的隐表示,所以在符号逻辑之外,比如图神经网络等深度学习模型也可以大显身手。

这块有一个缺点,GCN在有节点新加入的时候要重新训练图模型?这个要等我研究研究源码
前沿节点(frontier node)有两种:
- 新添加的节点
- 图中新添加边的节点(需重新访问)
系统1在线索和问题Q的指导下读取para[x],提取跨度并生成语义向量sem[x,Q,clues]。同时,系统2更新隐藏表示X,并为任何后继节点y准备线索clues[y,G]。基于X进行最终预测。
算法流程
1.提取在问题Q中提到的实体作为认知图的初始化,并且标记为前沿节点。
2.重复下面过程直到21(在每一步中,我们访问一个前沿节点x)
3.从前沿节点中跳出一个节点x
4.从前沿节点收集线索clues[x,G],例如线索可以是提及x的句子。(线索句可以是提到的x的句子)
5.在词库W中找到包含x的段落para[x]
6.system1生成语义向量sem[x,Q,clues],初始化X[x]
7.如果x是一个hop节点
8.system1在para[x]中找到hop和answer的局部
9.遍历hop内容,每个内容为y
10.如果内容y不在G内并且y在词库W内
11.用y创建一个新的hop节点
12.如果y属于G,并且x和y的边不在图内
13.在图中添加x和y的连线
14.让节点y作为一个前沿节点
15.循环结束
16.答案部分,每个答案是y
17.添加一个新的答案节点y和edge(x,y)到G中
18.循环结束
19.x过程结束
20.用System2更新隐含X的表示
21.直到G中没有前沿节点或G足够大;
22.返回答案节点中概率最大的节点作为最终答案。
关于可解释性,认知图谱有显式的路径,除了简单的路径,认知图还可以清楚地显示联合或循环推理过程。
在这些过程中,可能会带来关于答案的新线索。
尺度可伸缩性,框架理论上是可伸缩的,因为引用所有段落的唯一操作是通过标题索引访问哪些段落。
对于多跳问题,传统的检索-抽取框架可能会牺牲后续模型的潜力,因为距离问题多跳的段落可能共享的常用词很少,与问题的语义关系也很小,导致检索失败。然而,这些段落可以通过在我们的框架中使用线索迭代展开来发现。
实施方案
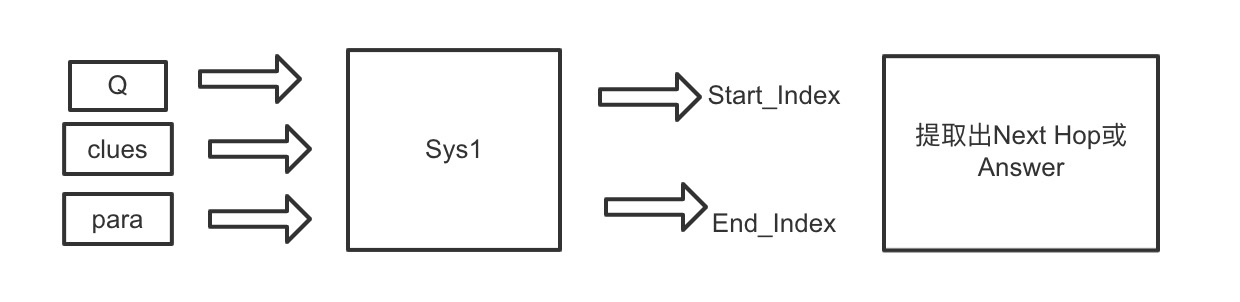
System1
系统1的作用,在线索clues和问题Q的指导下提取spans并生成语义向量sem[x,Q,clus]。
clues是前置节点段落的句子,从文中直接提取原始句子,这样做方便BERT训练。
Bert的输入句子分为A和B两部分:
[CLE]:放在每个句子的第一位,classification用于下游分类任务。
为什么用CLS?因为self-attention,[CLS]的output含有整句话的完整信息。在每个词的时候,对自己这个词的评分会很大。用无意义的CLS可以公平的反应整个句子的特征。
[SEP]:separator分隔连接token序列的符号。
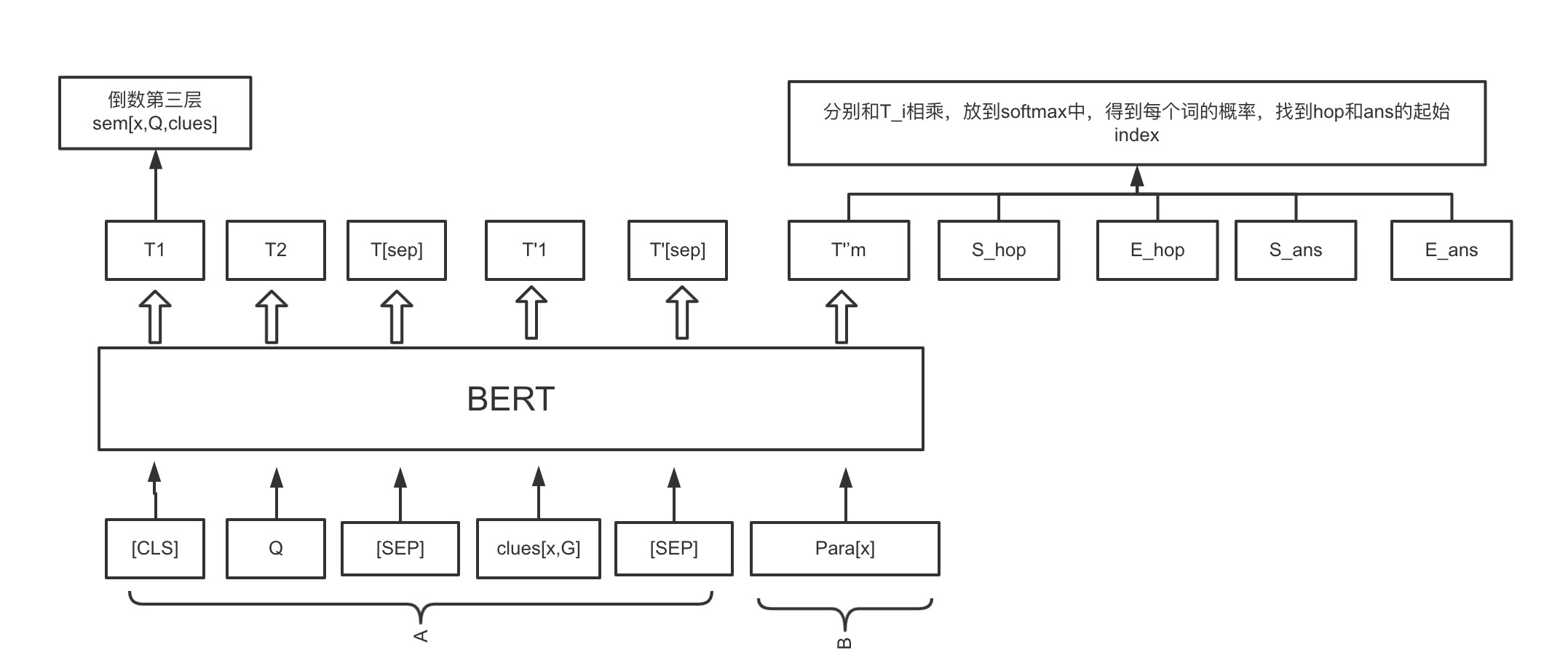
$S{hop}$、$E{hop}$、$S{ans}$、$E{ans}$ :可学习的参数,用来预测目标span。
$T\in R^{L\times H}$:是bert的输出向量,L是输入序列长度,H是隐层维度。
$P^{start}_{ans}[i]$:是第i个输入token到ans范围内开始位置的概率。
我们只聚焦topK开始的概率${start_k}$,对于每个k的结束位置$end_k$:
maxL:是最大概率的span长度。
$P^{end}_{ans}[j]$:是第j个输入token到ans范围内结束位置的概率。
文章说是这么区分下一跳和答案的:
答案和下一跳协议具有不同的属性。答案提取在很大程度上依赖于问题所指示的字符。例如,“纽约市”比“2019”更有可能是WHERE问题的答案,而下一跳实体通常是其描述与问题中的语句相匹配的实体。
为了识别不相关的段落,利用在§3.4.1中引入负抽样进行训练,系统1生成负阈值。在顶部
k个跨度,起始概率小于负阈值将被丢弃。因为对第0个token[CLS]进行预训练以合成
用于下一句预测的所有输入标记任务Pstart[0]充当ANS这是我们实施过程中的一个阈值。
System2
系统2,更新隐藏表示X,并为任何后继节点y准备clues[y,G]。基于X输出最终预测结果。
第一个功能是为前沿节点准备clues[x,G],我们将其实现为收集提到x的x个前置节点的原始语句。
第二个功能是更新隐含表示X,这是系统2的核心功能。隐含表示$X∈R^{n×H}$代表G中所有n个实体的理解。要完全理解实体x与问题q之间的关系,仅仅分析语义sem[x,Q,clues]是不够的。由于图结构的归纳偏差,GNN已被提出用于对图进行深入学习,特别是关系推理。
$W_1,W_2 \in R^{H\times H}$:权重矩阵
$\sigma(XW_1)$ 左乘$(AD^{-1})^T$(列归一化A):可以解释为局部化光谱过滤.
在访问边界节点x的迭代步骤中,其隐藏表示X[x]按照公式(4)(5)更新。
在实验中发现“异步更新”在性能上没有明显的差别,在G最终确定后,将所有节点的X一起分多步更新,效率更高,在实践中被采用。
训练细节
模型采用负采样,在训练集的段落中预先提取下一跳hop和answer span。
对于每个para[x]和问题Q有下面这种字典数据。
$start_i$和$end_i$ 是在para[x] 中根据一个实体或者答案$y_i$模糊匹配出来的。
任务1:Span Extraction
基于$D[x,Q]$,得到$P^{start}{ans}$,$P^{end}{ans}$,$P^{start}{hop}$,$P^{end}{hop}$
在每个段落中最多出现一个$answer(y,start,end)$
因此,定义一个one-hot向量$g{ans}^{start}$ ,其中$g{ans}^{start}[start]=1$。然而,一个段落中可能出现多个不同的ans next-hop spans,因此$g_{hop}^{start_i}[start]=1/k$ ,其中k是下一跳跨度的数量。
为了能够区分不相关的段落,在G中预先增加了不相关的negative-hop节点。
任务2:预测答案节点
实验
数据集
使用HotpotQA的全维基设置来构建实验。基于维基百科文档中的第一段图,众包收集了112,779个问题,其中84%的问题需要多跳推理。数据被分成训练集(90,564个问题)、发展集(7,405个问题)和测试集(7,405个问题)。开发和测试集中的所有问题都是困难的多跳案例。
总结&展望
系统2的推理如何实现?现在的方法(如图神经网络)虽然使用关系边作为归纳偏置,却仍然无法执行可控、可解释、鲁棒的符号计算。系统1如何为现有的神经-符号计算方法提供可行前续工作?
文本库应该如何预处理或预训练,才能有助于访问相关知识的检索?
另辟蹊径?本文介绍的认知图谱是基于认知科学的双通道理论,是否还存在其他支撑理论?或者直接构建一个符号推理和深度学习相结合的新型学习架构?
如何与人类记忆机理相结合?人类记忆机理包括长期记忆和短期记忆,但其工作模式和工作机理并不清楚。长期记忆可能存储的是一个记忆模型,记忆模型不再是一个概念的网络,而是一个计算模型的网络。
认知图谱如何与外界反馈相结合是一个全新的问题。当然这里可以考虑通过反馈强化学习来实现,但具体方法和实现模式还需要深入探讨。
参考文献
浅谈多跳阅读理解
BERT的[CLS]有什么用
从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史
从知识图谱到认知图谱:历史、发展与展望
图神经网络及其在知识图谱中的应用
还在用[CLS]?从BERT得到最强句子Embedding的打开方式!
 wechat
wechat alipay
alipay





