public List<List<Integer>> combinationSum(int[] candidates, int target) { int len = candidates.length; List<List<Integer>> res = new ArrayList<>(); if (len == 0) { return res; }
public List<List<Integer>> combinationSum(int[] candidates, int target) { int len = candidates.length; List<List<Integer>> res = new ArrayList<>(); if (len == 0) { return res; }
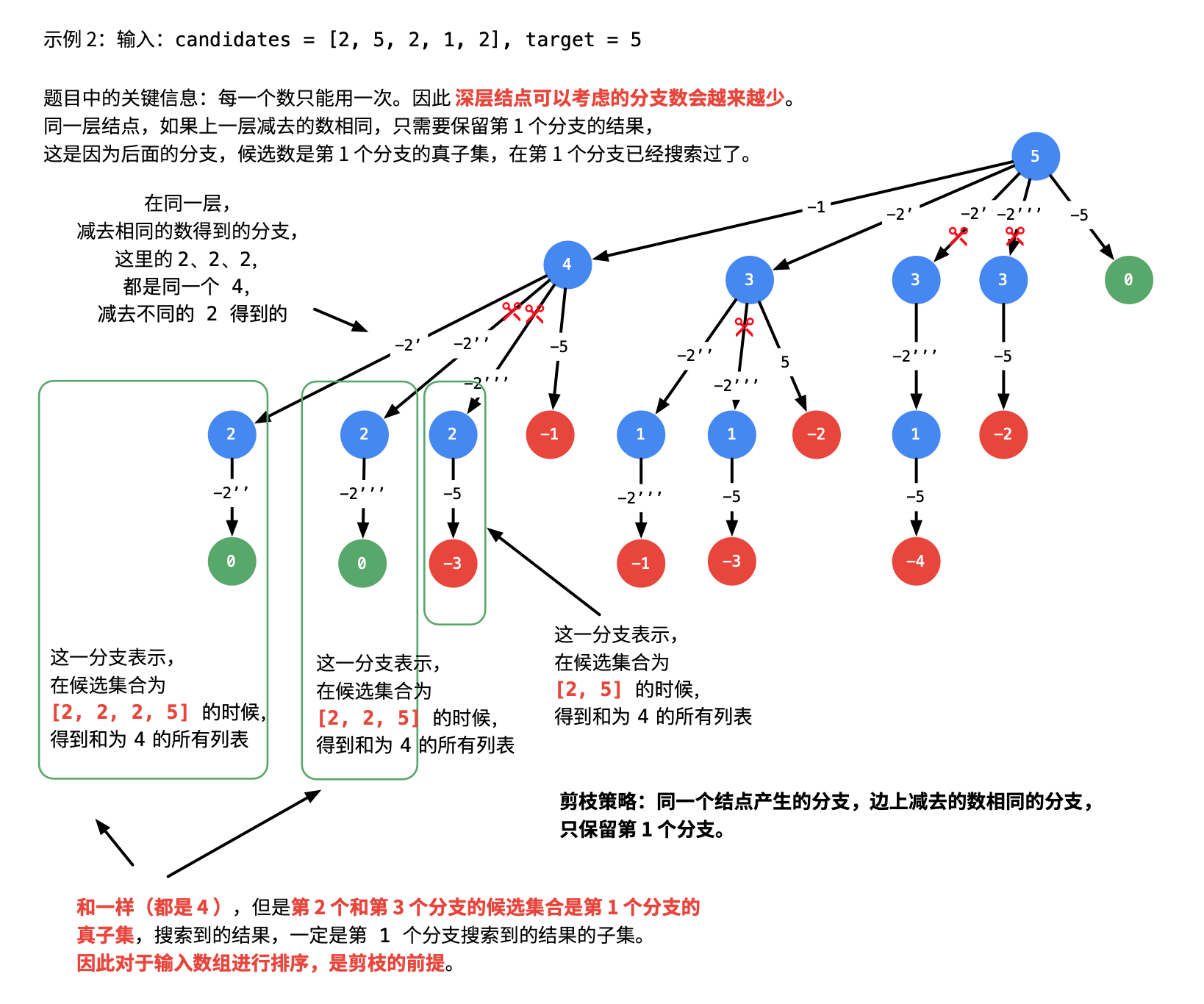
classSolution{ public List<List<Integer>> combinationSum2(int[] candidates, int target) { List<List<Integer>> res = new ArrayList<>(); if(candidates.length==0) return res;
int n = candidates.length; Deque<Integer> path = new ArrayDeque<>();
Arrays.sort(candidates);
dfs(candidates, 0, n, path, target,res); return res; }
privatevoiddfs(int[] candidates, int begin, int n, Deque<Integer> path, int target, List<List<Integer>> res){ if(target == 0){ res.add(new ArrayList<>(path)); return; }
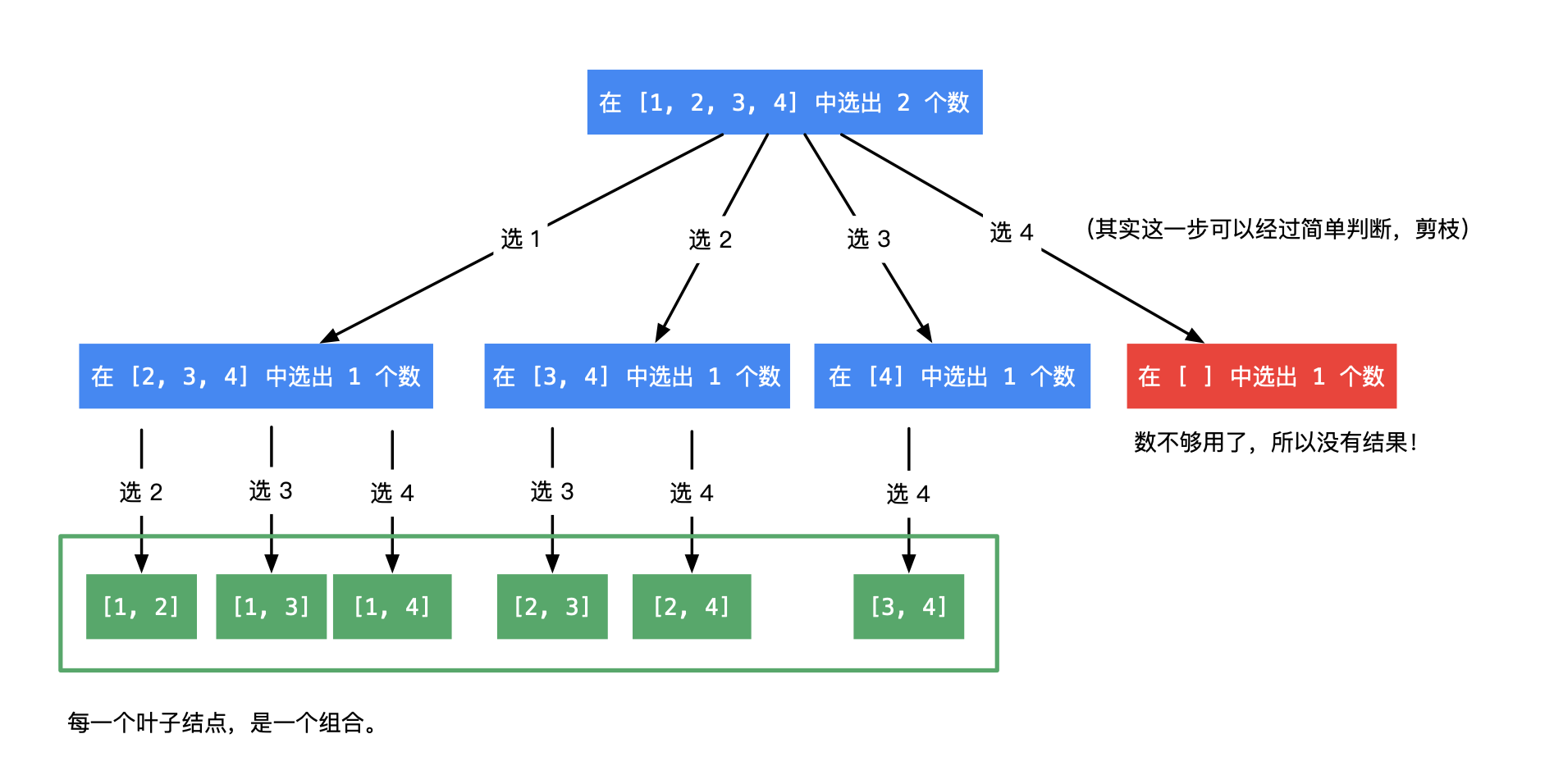
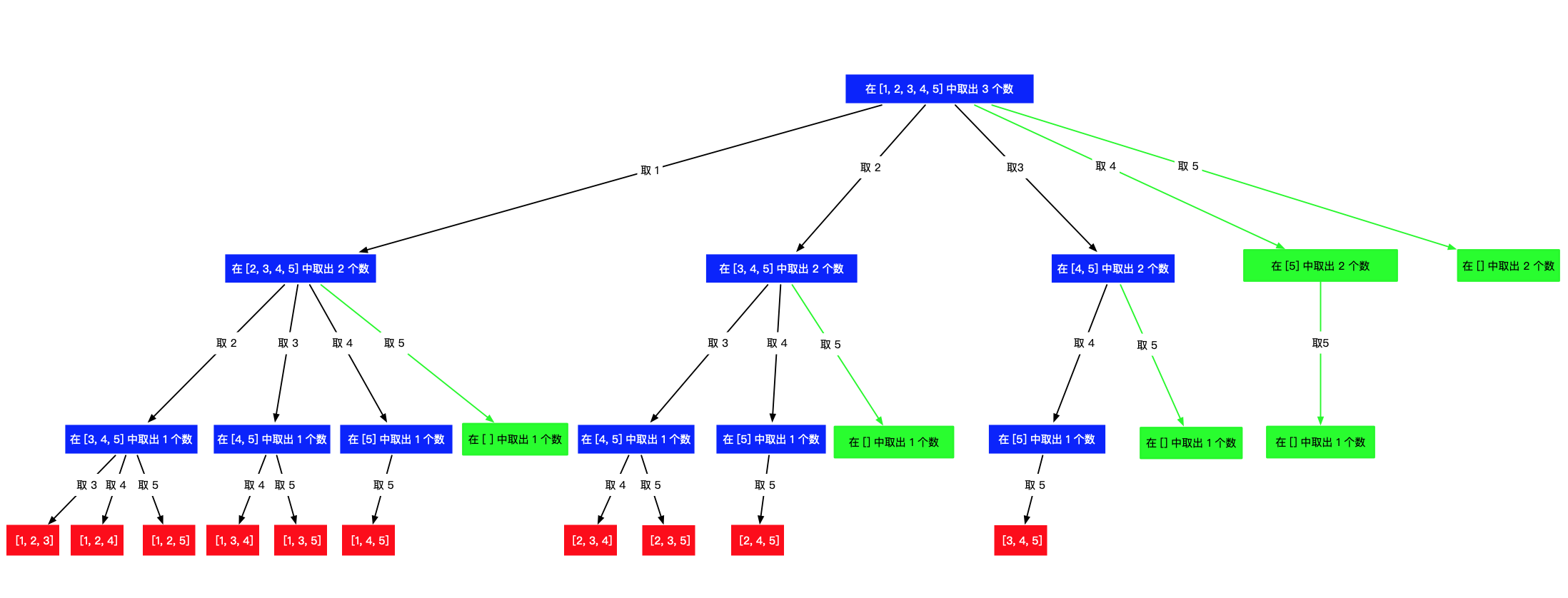
public List<List<Integer>> combine(int n, int k) { List<List<Integer>> res = new ArrayList<>(); if (k <= 0 || n < k) { return res; } // 从 1 开始是题目的设定 Deque<Integer> path = new ArrayDeque<>(); dfs(n, k, 1, path, res); return res; }
privatevoiddfs(int n, int k, int begin, Deque<Integer> path, List<List<Integer>> res){ // 递归终止条件是:path 的长度等于 k if (path.size() == k) { res.add(new ArrayList<>(path)); return; }
// 遍历可能的搜索起点 for (int i = begin; i <= n; i++) { // 向路径变量里添加一个数 path.addLast(i); // 下一轮搜索,设置的搜索起点要加 1,因为组合数理不允许出现重复的元素 dfs(n, k, i + 1, path, res); // 重点理解这里:深度优先遍历有回头的过程,因此递归之前做了什么,递归之后需要做相同操作的逆向操作 path.removeLast(); } } }
剪枝
上面的代码,搜索起点遍历到 n,即:递归函数中有下面的代码片段:
1 2 3 4 5 6
// 从当前搜索起点 begin 遍历到 n for (int i = begin; i <= n; i++) { path.addLast(i); dfs(n, k, i + 1, path, res); path.removeLast(); }
classSolution{ public List<List<Integer>> subsets(int[] nums) { List<List<Integer>> res = new ArrayList<>(); if(nums.length==0){ return res; } int n = nums.length; Deque<Integer> path = new ArrayDeque<>();
dfs(0, n, nums, path, res);
return res; }
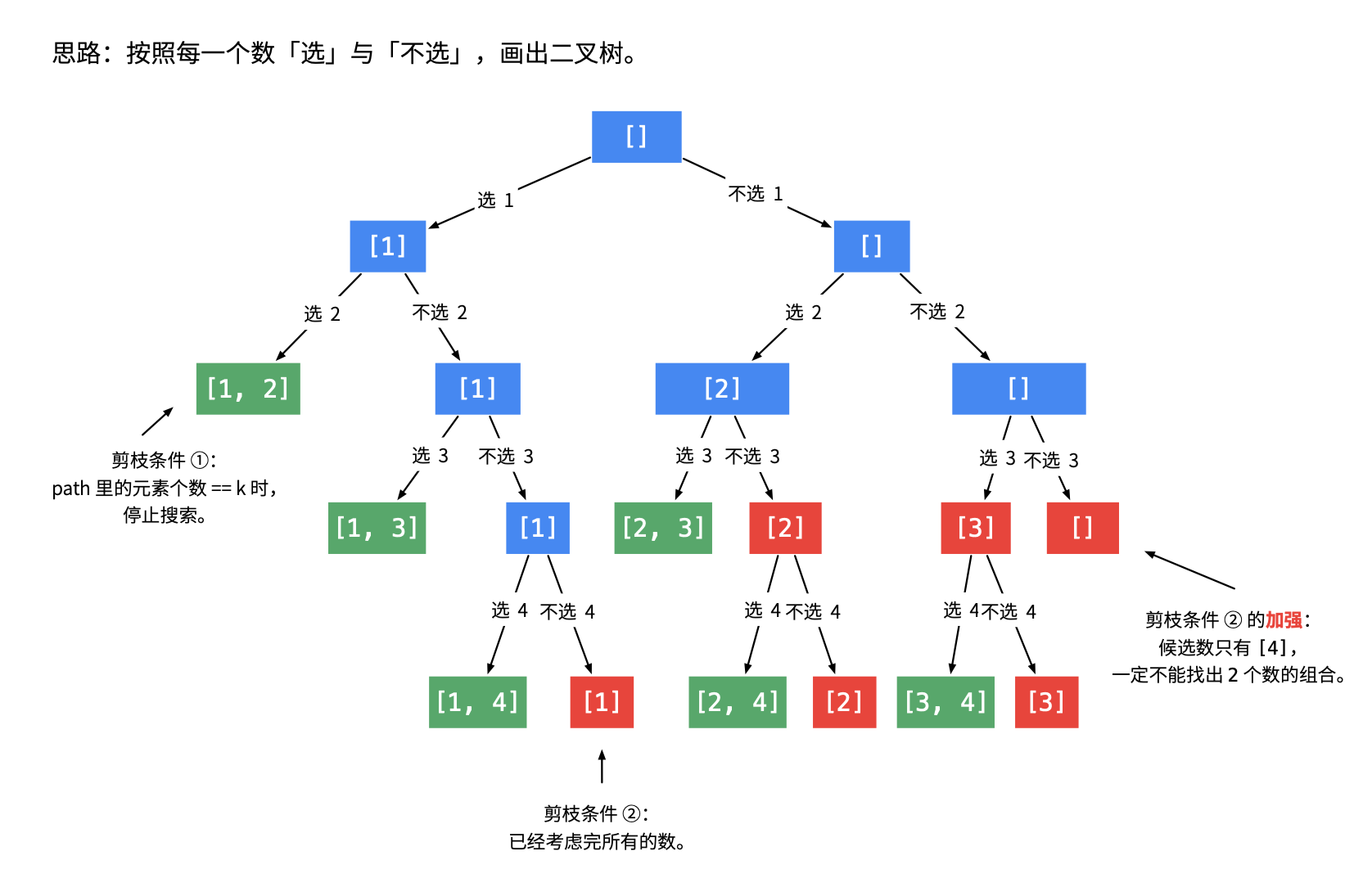
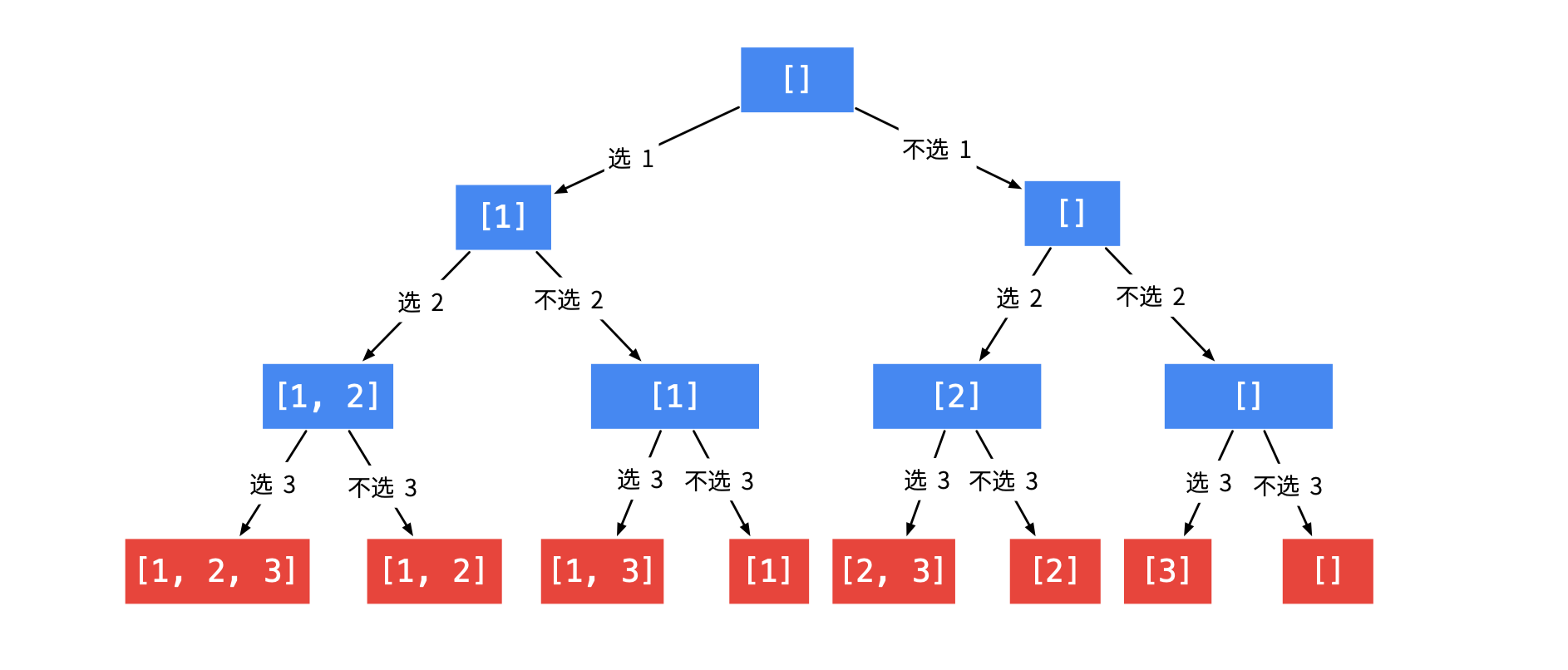
privatevoiddfs(int begin, int n, int[] nums, Deque<Integer> path, List<List<Integer>> res){ if(begin == n){ res.add(new ArrayList<>(path)); return; } // 当前数可选 也可以不选
// 不选 直接进入下一层 dfs(begin+1, n, nums, path, res); // 选了,进入下一层 path.add(nums[begin]); dfs(begin+1, n, nums, path, res); path.removeLast(); }
public List<List<Integer>> subsets(int[] nums) { List<List<Integer>> res = new ArrayList<>(); int len = nums.length; if (len == 0) { return res; } Stack<Integer> stack = new Stack<>(); dfs(nums, 0, len, stack, res); return res; }
privatevoiddfs(int[] nums, int index, int len, Stack<Integer> stack, List<List<Integer>> res){ if (index == len) { res.add(new ArrayList<>(stack)); return; } // 当前数可选,也可以不选 // 选了有,进入下一层 stack.add(nums[index]); dfs(nums, index + 1, len, stack, res); stack.pop();
// 不选,直接进入下一层 dfs(nums, index + 1, len, stack, res); }
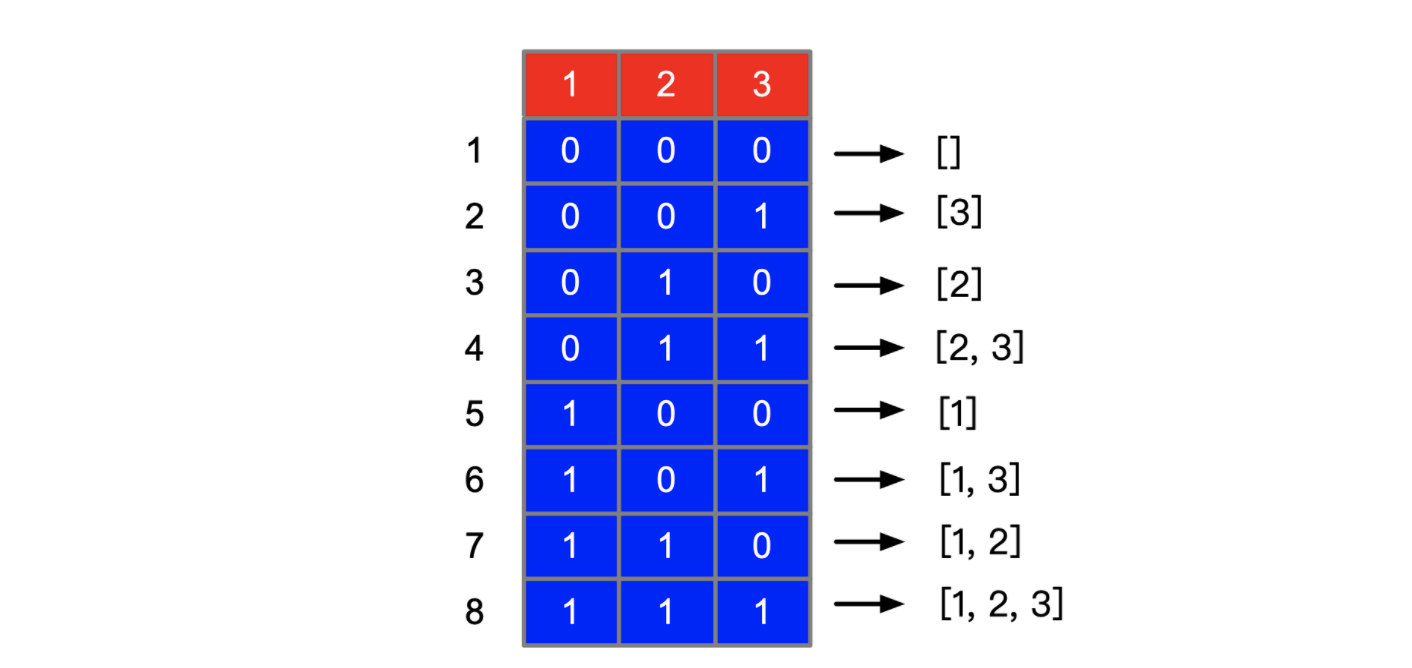
classSolution{ public List<List<Integer>> subsets(int[] nums) { int size = nums.length; int n = 1 << size; List<List<Integer>> res = new ArrayList<>();
for(int i =0;i<n;i++){ List<Integer> cur = new ArrayList<>(); for(int j=0;j<size;j++){ if( ((i>>j) & 1) ==1){ cur.add(nums[j]); } } res.add(cur); }
classSolution{ public List<List<Integer>> subsetsWithDup(int[] nums) { List<List<Integer>> res = new ArrayList<>(); if(nums.length==0){ return res; } int n = nums.length; Deque<Integer> path = new ArrayDeque<>(); Arrays.sort(nums); dfs(0, false, n, path, nums, res); return res; }
privatevoiddfs(int begin,boolean choose, int n, Deque<Integer> path, int[] nums, List<List<Integer>> res){ if(begin==n){ res.add(new ArrayList<>(path)); return; }
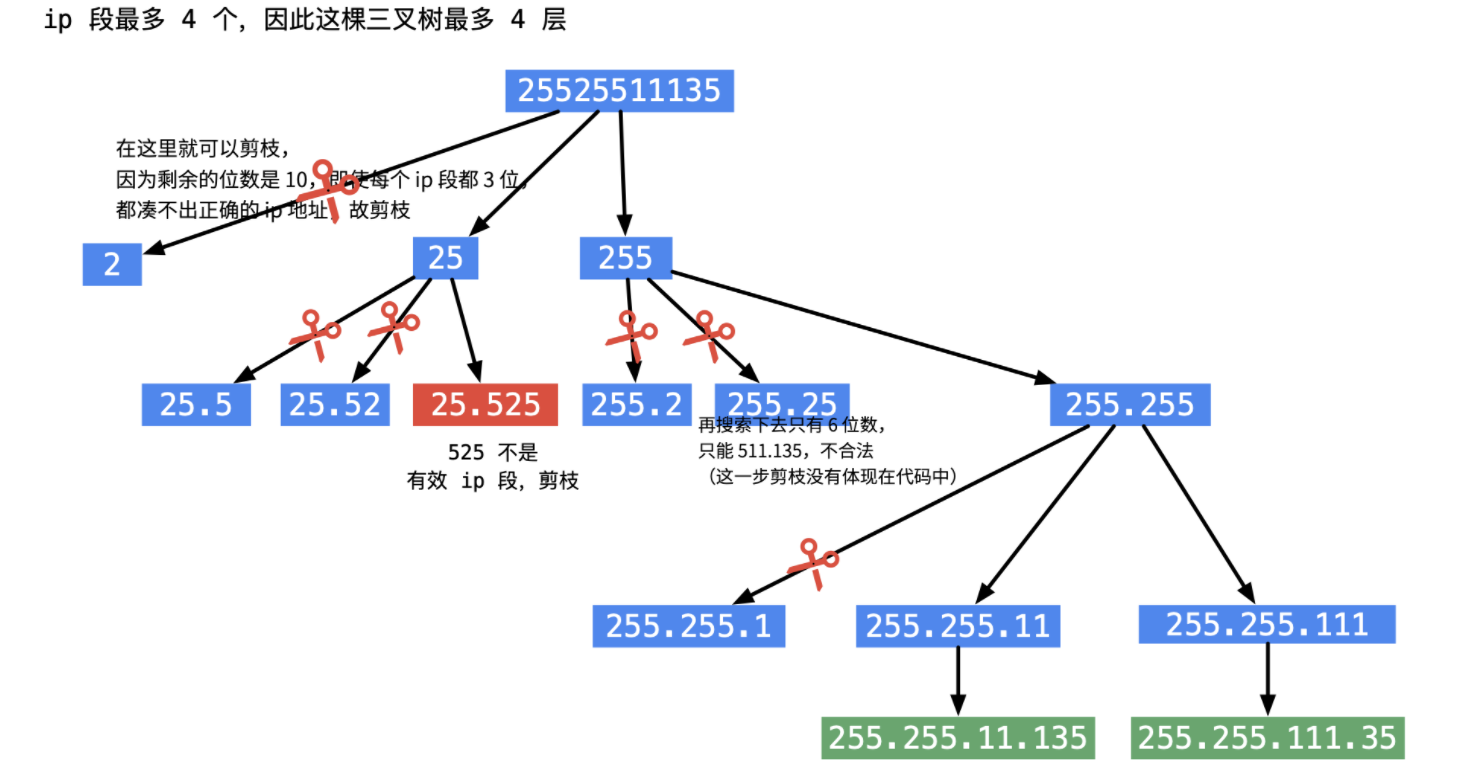
classSolution{ public List<String> restoreIpAddresses(String s){ int n = s.length(); List<String> res = new ArrayList<>(); if (n < 4 || n>12){ return res; } Deque<String> path = new ArrayDeque<>(4); dfs(0,0, n, path, s, res); return res; }
privatevoiddfs(int begin, int splitTimes, int n, Deque<String> path, String s, List<String> res){ if(begin == n){ if(splitTimes == 4){ res.add(String.join(".",path)); } return; }
// 看到剩下的不够就退出,n-begin 表示剩余的还未分割的字符串的位数 if(n - begin < (4-splitTimes) || n - begin > 3*(4-splitTimes)){ return; }
for(int i=0;i<3;i++){ if(begin + i >= n){ break; } int ipSegment = judgeIFIpSegemnt(s, begin, begin+i); if(ipSegment != -1){ // 在判断是ip段的情况下,采取截取 path.addLast(String.valueOf(ipSegment)); dfs(begin+i+1, splitTimes+1, n, path, s, res); path.removeLast(); } }
}
// 判断s的子区间 [left, right] 是否能构成一个 ip段 privateintjudgeIFIpSegemnt(String s, int left, int right){ int len = right - left + 1; // 大于1 位的时候,不能以0开头 if(len>1 && s.charAt(left) == '0'){ return -1; }
// 转成int 类型 int res = 0; for(int i=left; i<=right; i++){ res = res*10 + s.charAt(i) - '0'; }


 wechat
wechat alipay
alipay




