第五届达观杯——风险事件标签识别比赛复盘
第五届达观杯Rank4——风险事件标签识别比赛复盘
成绩:A榜第5,B榜第4,最终分数分别为:0.62411600、0.58140504
比赛链接:https://www.datafountain.cn/competitions/512
代码:https://github.com/Coding-Zuo/DaguanFengxian
赛题任务
这个比赛的全名是叫:基于大规模预训练模型的风险事件标签识别,在技术层面上可以提取为两个任务,一个是预训练一个是文本分类。
针对预训练赛题方给了一个70g的无标注预训练文本,训练集有14009条,测试集6004条(包含AB榜数据)
赛题全部为脱敏数据(所有文字都转换成了数字表达)脱敏前的数据样例为:
| 资讯文本 | 风险事件标签 |
|---|---|
| 新冠肺炎疫情给美国劳动力市场造成巨大冲击,首次申请失业救济人数已经连续19周超过100万人,约为疫情暴发前平均水平的6倍 | 宏观_经济数据下滑 |
| 石化公司双苯厂发生爆炸事故,造成大量苯类污染物进入江河水体,造成重大环境污染 | 事故_生产设施 |
| 市场监管局执法人员对5家品牌奶茶店进行了检查,发现多家门店存在工作人员健康证不齐全、原材料管理不善等问题 | 卫生_食品安全 |
| 脱敏后 | |
| 210 21048 4210 751252 10 21048 4210 75 125210 21048 4210 75125….. | 1-3 |
在标签列可以看到样本有一级和二级标签之分,共有10个一级,35个二级标签。评价指标为macro F1。
我们尝试过一级标签和二级标签的联合预测,效果不好。
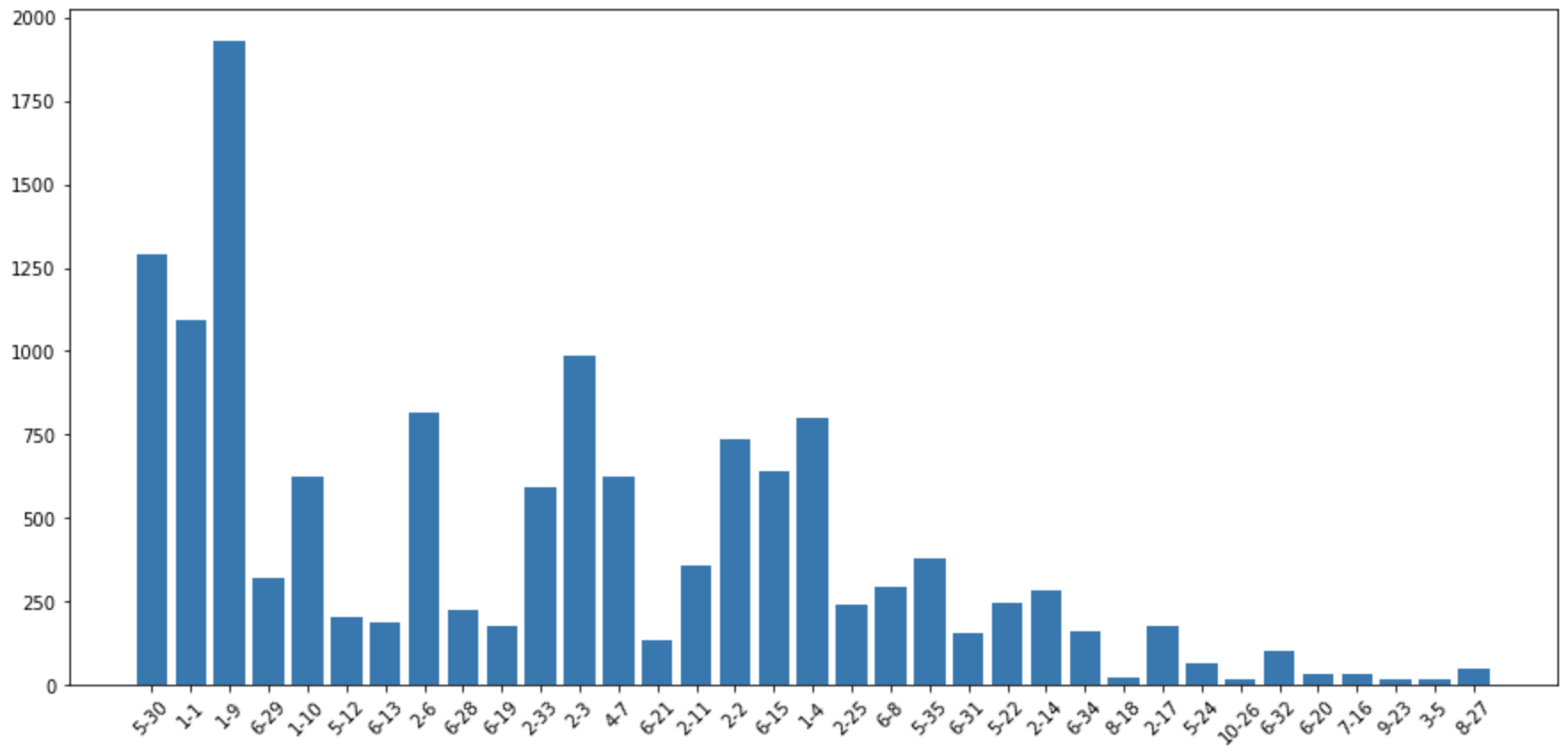
标签类别很多而且不平衡,多的类别上千条,少的类别只有十几个:
接下来我将分别从预训练模型、模型结构、提分技巧、模型融合复盘整个比赛过程。
预训练模型
预训练模型百度网盘地址:链接:https://pan.baidu.com/s/1GCs1m6HiXenurGbjUBetFw 提取码:fxth
对应代码部分:https://github.com/Coding-Zuo/DaguanFengxian/tree/main/bert_model/pretrain
运行过程 处理数据 process_data —> 构建词表 build_vocab —> run pretrain
我们在无标注数据中根据cosine距离选择了四万条和训练集中样本相似的数据进行预训练。
分别预训练了bert-base模型 nezha-base模型,nezha与bert的区别主要是
nezha相比于google开源中文bert使用了更大的预训练语料,还使用了相对位置编码是一种有效的位置编码方案,全字掩蔽策略,混合精度训练和LAMB优化器。
nezha首次将函数型的相对位置编码加入了模型中。好处:主要是因为它可以使模型外推到比训练中遇到的序列长的序列长度。Bert针对每个位置合并了绝对位置编码,该绝对位置编码是嵌入向量,并且直接添加到token embedding。
我们对每种模型保存不同训练步数的checkpoint,可以用于后面的模型融合。
其实预训练策略可以做很多花样的文章,但由于机器有限,我们将主要的精力放在了微调方面。预训练策略只是遵循mlm和nsp。
我们主要使用过的预训练模型有:
- Bert-base-wwm-ext : 哈工大开源版本
- Nezha-wwm-base: 哪吒官方开源版本
- Bert120k: 预训练12万step
- Bert150k: 预训练15万step
- Bert80k: 预训练8万step
- Nezha80k:预训练8万step
- Nezha110k:预训练11万step
- Nezha150k:预训练15万step
最一开始是使用了word2vec在语料库上进行训练,代码:https://github.com/Coding-Zuo/DaguanFengxian/tree/main/baseline/src/classic_models/word2vec 线上第一次提交是 48点多分 排了七十多名。
然后开始使用bert等开源的权重,那么问题来了脱敏数据里词都是那样的,bert词表用不了怎么办?
- 统计脱敏数据的词频,将对应词频与开源词表上的词频进行对换 (最开始使用的是这种) 线上可达50分左右
- 将word2vec训练好的embedding替换到bert上
虽然无法还原句子,但频率估计可以还原一部分词,两个频率高的文本,在同一种语境下出现的概率更大,从语义相关性角度来说,可能会有一些语义相关性,改用明文后就可以随便用预训练语言模型了。
模型结构
我们最终的模型结构大致是:
Bert —> BiLSTM 1层 —> BiGRU 1层 —> bert_pooler + 胶囊网络 —> Multi-Sample Dropout预测输出
同时加BiLSTM和BiGRU大概有接近一个点的提高。胶囊网络有的预训练模型有一点点提高,但有的有负效果。
还尝试过 用 max_pooling + avg_pooling + 胶囊网络 + bert_pooling等组合,效果均不如直接使用bert_pooler和胶囊网络。
提分技巧
面对不均衡 dice loss & focal loss & cross entropy loss
代码位置:https://github.com/Coding-Zuo/DaguanFengxian/tree/main/bert_model/training
样本不均衡会带来什么问题呢?
模型训练的本质是最小化损失函数,当某个类别的样本数量非常庞大,损失函数的值大部分被样本数量较大的类别所影响,导致的结果就是模型分类会倾向于样本量较大的类别。
通过类别加权Loss解决, 下图截自香侬科技的论文《Dice Loss for Data-imbalanced NLP Tasks》,分别列举了加权loss,Focal loss(FL)和他们提出的dice loss。我们的实验效果是:FL < Weigth CE < dice loss。所以主要采用了weight ce和dice loss。
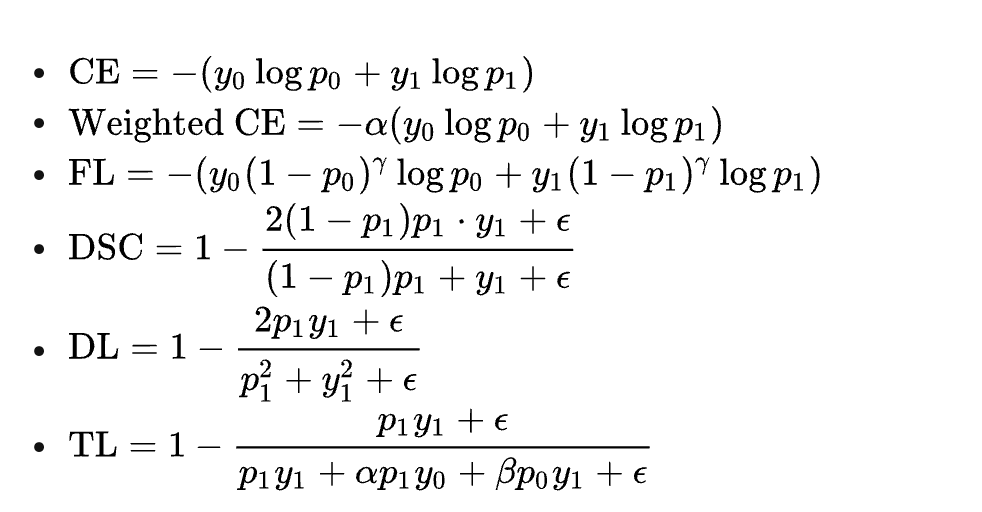
Weight CE通过基于类别的加权的方式可以从不同类别的样本数量角度来控制Loss值,从而一定程度上解决了样本不均衡的问题。
基于类别加权Loss虽然在一定程度上解决了样本不均衡的问题,但是实际的情况是不仅样本不均衡会影响Loss,而且样本的难易区分程度也会影响Loss。
何恺明在论文《Focal Loss for Dense Object Detection》中提出了的Focal Loss,上图第三个公式。对于模型预测为正例的样本也就是p>0.5的样本来说,如果样本越容易区分那么(1-p)的部分就会越小,相当于乘了一个系数很小的值使得Loss被缩小,也就是说对于那些比较容易区分的样本Loss会被抑制,同理对于那些比较难区分的样本Loss会被放大,这就是Focal Loss的核心:通过一个合适的函数来度量简单样本和困难样本对总的损失函数的贡献。
dice loss香侬科技的这篇论文可以参考:Dice Loss for Data-imbalanced NLP Tasks
交叉熵“平等”地看待每一个样本,无论正负,都尽力把它们推向1(正例)或0(负例)。但实际上,对分类而言,将一个样本分类为负只需要它的概率<0.5即可,完全没有必要将它推向0。Dice Loss的自适应损失——DSC,在训练时推动模型更加关注困难的样本,降低简单负例的学习度,从而在整体上提高基于F1值的效果。
对比学习
代码位置:https://github.com/Coding-Zuo/DaguanFengxian/blob/main/bert_model/models/modeling_nezha1.py
对比损失可以关注判别更困难的样本。
Feature学习是各类深度学习模型的一个基础、重要的功能。好的feature,将有助于文本任务性能的提升。
表示学习的目标是为输入x 学习一个表示 z,那么如何衡量一个表示z 的好坏可以通过互信息的形式;
互信息:代表我们知道了 z 之后 x的信息量减少了多少,
InfoNCE (又称ntxent loss)
实质:核心是通过计算样本表示的距离,拉近正样本,拉远负样本
自监督的时候可以自行构造正负样本,那么有监督的时候就可以根据不同的样本标签来构建正负样本。
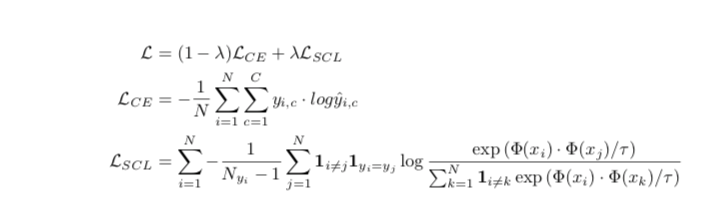
最大化相同标签的样本相似度,让不同样本标签的相似度比较小。
参考论文 《Supervised Contrastive Learning》、《SUPERVISED CONTRASTIVE LEARNING FOR PRE-TRAINED LANGUAGE MODEL FINE-TUNING》
对抗训练
代码位置:https://github.com/Coding-Zuo/DaguanFengxian/blob/main/bert_model/training/Adversarial.py
很多人反映对抗训练没有效果,我最一开始的结果也是这样的。在开源版的nezha和bert上都会降分。
但随着预训练模型越来越多,模型越来越稳定,对抗训练就可以提分了。在预训练后的nezha上基本上是pgd比较好,但比较耗时,在bert上fgm有时会好一点。每个预训练模型的使用效果都不太一样。
我们还尝试了,不仅在bert的word_embedding上做扰动,还在encoder的第0层做扰动,同时随机在某个batch上不扰动,效果相差不多。
在验证集的效果对比:
- Nezha110k_noAdv: 0.5598
- Nezha110k_fgm: 0.5639
- Nezha110k_pgd: 0.5687
- Bert80k_noAdv: 0.5542
- Bert80k_fgm:0.5557
- Bert80k_pgd:0.5650
- Bert80k_fgm_advEncoder_random:0.5585
- Bert80k_pgd_advEncoder_random:0.5684
Multi-Exit
代码位置:https://github.com/Coding-Zuo/DaguanFengxian/blob/main/bert_model/models/modeling_bert_pabee.py
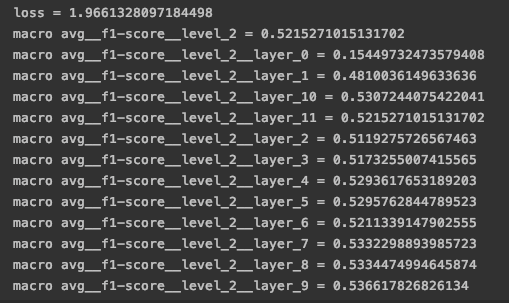
Bert 究竟在哪一层做输出会比较好呢?下图是在nezha80k上进行的实验,普遍发现在第layer9,也就是第10层的输出下普遍较好。其实实验下来发现整体效果不好就放弃了,但后来想想可能是因为12层输出联合训练导致的F1值偏低。其实发现第10层可能比较好,就干脆只用第十层的输出计算loss就好。但后来没有继续尝试。
flooding洪泛法
在最开始使用开源未经预训练的bert进行探索的过程中发现,验证集loss上升,acc也上升。但随着预训练模型的越来越稳定,这种现象就不存在了。
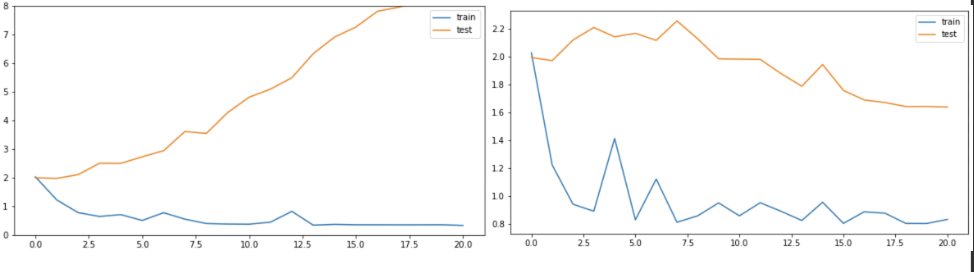
这种现象很常见,原因是过拟合或者训练验证数据分布不一致导致,即在训练后期,预测的结果趋向于极端,使少数预测错的样本主导了loss,但同时少数样本不影响整体的验证acc情况。ICML2020发表了一篇文章:《Do We Need Zero Training Loss After Achieving Zero Training Error?》,描述了上述现象出现的原因,同时提出了一种flooding策略,通过超参数b控制训练loss不要过小,阻止进一步过拟合,在此情况下,使model”random walk”至一个泛化能力更好的结果,参考 我们真的需要把训练集的损失降到零吗? 。上图左是加洪泛之前, 上图右是加洪泛之后的,训练集验证集每轮的loss。超参数b的值大概0.2左右小一些。对于模型效果来说,整体影响不大,训练的稍微稳定一点,比赛后期没有再用。
Multi-sample Dropout
代码位置:https://github.com/Coding-Zuo/DaguanFengxian/blob/main/bert_model/models/layers.py
dropout目前是NLP任务中很流行的数据扩充手段。Multi-Sample Dropout是对Dropout方法的一种改进,是2019年的一篇工作。Multi-Sample Dropout相比于dropout加快了模型训练过程的收敛速度和提高了泛化能力。
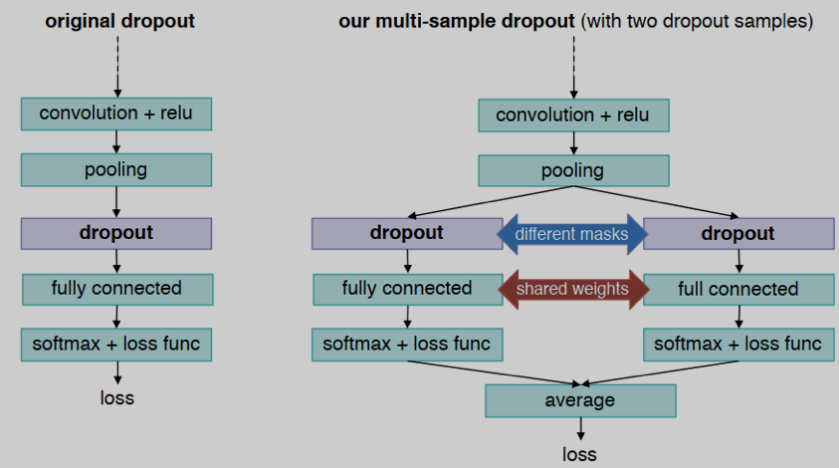
假设样本经过网络的编码层部分进行编码后得到一个向量表征。这时候,传统的Dropout会对向量表征作用一次,然后输入到分类层进行预测。而Multi-sample Dropout由多个Dropout操作完成。对一个向量表征进行多次dropout后,相当于形成了向量表征的多个版本的。这些不同版本的向量表征通过分类器得到标签的不同概率预测,最终的预测概率分布通过求和或者平均得到。
在比赛的实验中发现,dropout的数量为4,聚合的方式以加和的形式比average效果要好。dropout_rate最开始设为0.4。但后来慢慢发现有时,模型训着训着F1直接变成0了,而且只在bert模型上出现这种问题。找了几天原因发现dropout_rate不能设的太大,改成了0.2。
伪标签
关于伪标签,我个人认为总体指标达不到八十以上的比赛可能不太好管用。尤其这个赛题还是样本极其不均匀的就更不适合。因为第一,模型预测的把握度不大,根据我们线上59分的模型,预测概率为百分之40以上的测试集数据不到1500条,这在伪标签准确度上带来了不确定性。第二样本不均匀,如果直接把这1500条插入到训练集,可能会破坏训练集的一些分布,造成模型不稳定,学跑偏了。
测试结果:线上58.7的模型,在伪标签上重新训练后是58.3分。
模型融合
代码位置: https://github.com/Coding-Zuo/DaguanFengxian/tree/main/bert_model/ensemble
stacking
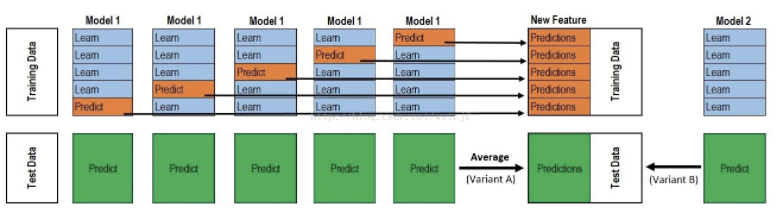
跑了四折的四种预训练模型的stacking。最后的第二层预测使用的是xgboost,整体效果没有达到预期,线上得分仅0.5707
四折的四种模型效果如下:
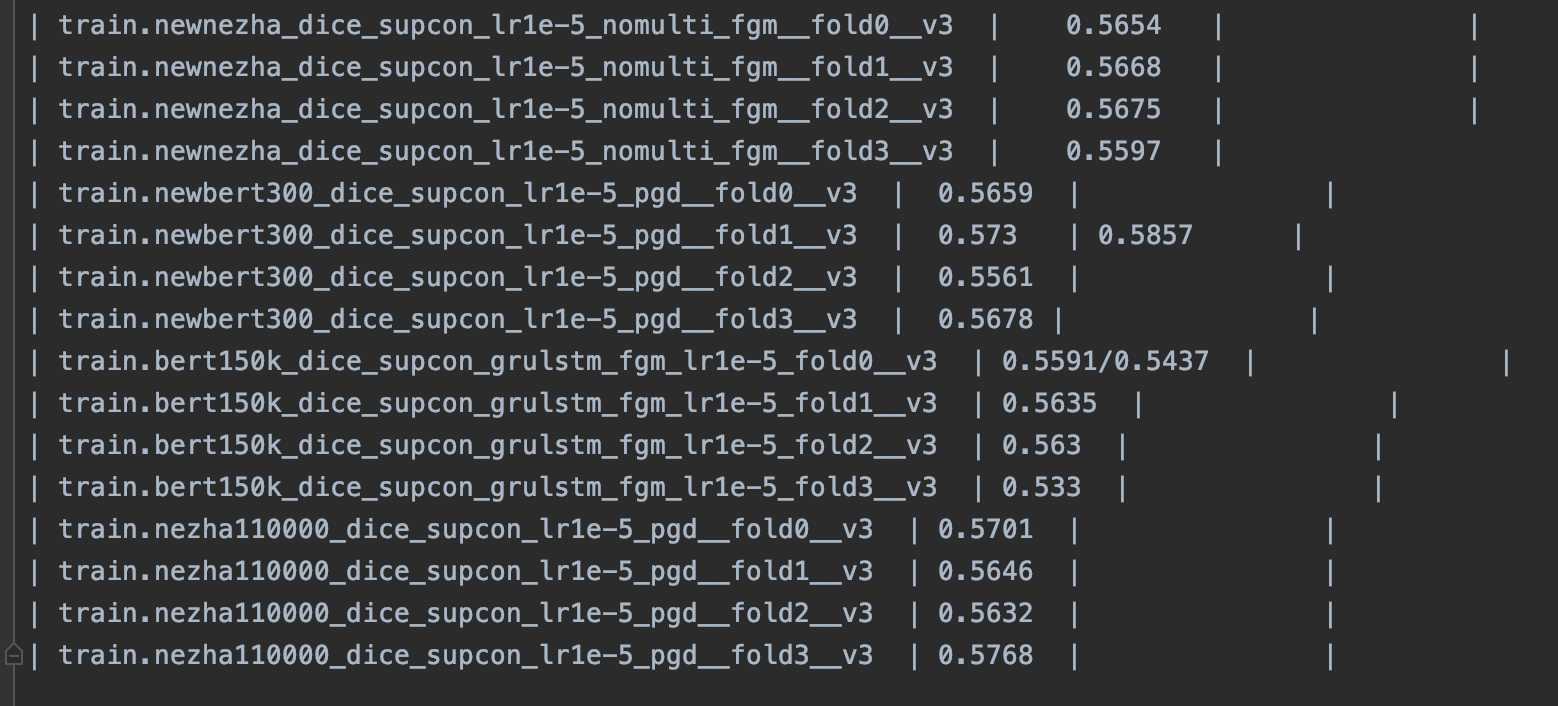
效果不佳的原因可能和拆分四折的数据分布有关,导致单模分数不是很高。由于样本不均衡,原先的拆分方法是针对不同类别有放回的随机取样做五折,随机性比较大,不容易过拟合。
为了让模型凑齐所有训练集的预测特征,且不让数据有重复,我使用了无放回的采样,针对不同类别的样本,按顺序分段提取每折样本,并且根据数据id去了一遍重。 在实验的时候发现不同折的数据分布对模型效果影响还蛮大的。
投票+rank/概率平均
投票在这次比赛效果非常好。
第一次融七个模型,模型平均分大概五十四五。
- 投票线上结果:0.5809
- 投票,针对票数相同的结果,选择结果在每个模型的预测rank最靠前的作为结果:0.5852
- 投票,针对票数相同的结果,选择每个预测结果的概率平均值最大的作为结果:0.5850
- 根据七个模型的logits选最大的作为预测结果:0.5549
- 根据预测的概率加和取平均的线上结果:0.5618
模型平均分大概57.5分左右
- 投票+rank :0.6201
最后将所有线上得分超过60分的测试集结果再放到一起,再进行投票得到最后的最终成绩:0.6241
参考
https://github.com/823316627bandeng/2021-Daguan-Cup
 wechat
wechat alipay
alipay