海华中文阅读理解比赛梳理 文文言文古诗词现代诗词
1 字词解释 2 标点符号作用 3 句子解释 4 填空 5 选择正读音 6 推理总结 7 态度情感 8 外部知识
不需要先验知识的问题
如一个问题能够在文档中进行匹配,回答起来就几乎不需要先验知识需要先验知识的问題
1、关于语言的知识:需要词汇/语法知识,例如:习语、谚语、否定、反义词、同义词语法转换
2、特定领域的知识:需要但不限于些事实上的知识,这些事实与特定领域的概念概念定义和属性,概念之间的关系
3、一般世界的知识:需要有关世界如何运作的一般知识,或者被称为常识。比如百科全书中的知识
这个赛题的难点是有些预训练语言模型没有学到的先验知识怎么学
赛题概述
train 训练集提供了6313条数据数据格式是和中小学生做的阅读题一样,一篇文章有两到三个问题每个问题有两到四个答案选项。
validation 验证集提供了1000条数据。
原始单条数据格式如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 { "ID" : "0001" , "Content" : "春之怀古张晓风春天必然曾经是这样的:从绿意内敛的山头,一把雪再也撑不住了,噗嗤的一声,将冷面笑成花面,一首澌澌然的歌便从云端唱到山麓,从山麓唱到低低的荒村。。。。。很多省略。" , "Questions" : [ { "Q_id" : "000101" , "Question" : "鸟又可以开始丈量天空了。”这句话的意思是 ( )" , "Choices" : [ "A.鸟又可以飞了。" , "B. 鸟又要远飞了。" , "C.鸟又可以筑巢了。" ], "Answer" : "A" }, { "Q_id" : "000102" , "Question" : "本文写景非常含蓄,请读一读找一找哪些不在作者的笔下有所描述" , "Choices" : [ "A.冰雪融化" , "B. 蝴蝶在花间飞舞" , "C.白云在空中飘" , "D.小鸟在空中自由地飞" ], "Answer" : "C" } ] }
EDA 与预处理 将原始数据每个问题抽出来以 [文章- 问题 -答案] 作为一条数据。
1 2 3 4 5 6 7 8 9 10 11 12 { "Question" : "下列对这首诗的理解和赏析,不正确的一项是" , "Choices" : [ "A.作者写作此诗之时,皮日休正患病居家,闭门谢客,与外界不通音讯。" , "B.由于友人患病,原有的约会被暂时搁置,作者游春的诗篇也未能写出。" , "C.作者虽然身在书斋从事教学,但心中盼望能走进自然,领略美好春光。" , "D.尾联使用了关于沈约的典故,可以由此推测皮日休所患的疾病是目疾。" ], "Answer" : "A" , "Q_id" : "000101" , "Content" : "奉和袭美抱疾杜门见寄次韵 陆龟蒙虽失春城醉上期,下帷裁遍未裁诗。因吟郢岸百亩蕙,欲采商崖三秀芝。栖野鹤笼宽使织,施山僧饭别教炊。但医沈约重瞳健,不怕江花不满枝。" }
训练集从6313变为15421条数据,相当于有15421个问题
验证集从1000变为2444条数据,相当于有2444个问题
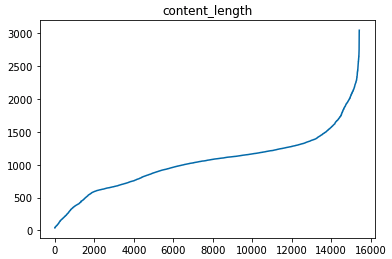
接下来看看文章的长度如何?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 count 15421.000000 mean 1039.781272 std 435.583878 min 38.000000 25% 744.000000 50% 1067.000000 75% 1251.000000 max 3047.000000 Name: content_len, dtype: float64 count 2444.000000 mean 927.508592 std 481.552693 min 40.000000 25% 596.000000 50% 938.000000 75% 1179.500000 max 3047.000000 Name: content_len, dtype: float64
发现content文章都非常长,绝大多数都超过了512。
使用预训练模型bert的话,如何训练很长的文章是是个提高的点。
我的想法是bert模型一个这个提高的点、看看最近比较火的Longformer怎么做,再用几个和长度无关的模型像lstm等最后做集成。
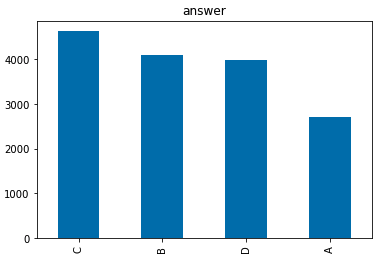
答案中选C的居多,点歌都选C。。。
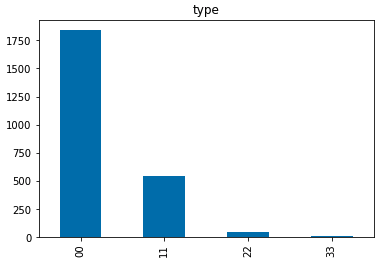
在提供的测试集中有一个特别的地方,赛方给出了文章的类型。
00 现代文 11文言文 22 古诗词 33现代诗词
测试集还给了难度,使用想法:
可以训练一个模型预测文本的难度和类型,标注训练集,可能会有提升。
接下来将标签从ABCD转成0123
1 2 3 train_df['label' ] = train_df['Answer' ].apply(lambda x:['A' ,'B' ,'C' ,'D' ].index(x)) test_df['label' ] = 0
Baseline 分词器 采用transformers提供的bert分词器
1 tokenizer = BertTokenizer.from_pretrained('model' )
这里我试过如果要将bert改成roberta,分词器还是要采用BertTokenizer,如果用RobertaTokenizer会报错。
参考关于transformers库中不同模型的Tokenizer
由于中文的特殊性不太适合采用byte级别的编码,所以大部分开源的中文Roberta预训练模型仍然采用的是单字词表,所以直接使用BertTokenizer读取即可, 不需要使用RobertaTokenizer。
模型部分 BertForMultipleChoice https://huggingface.co/transformers/model_doc/bert.html#bertformultiplechoice
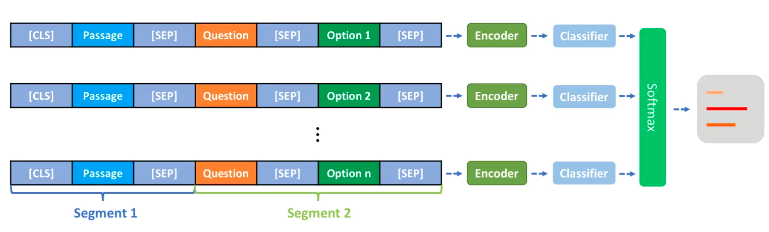
把每个问题和文章的不同选项拆开拼成一个输入。如下图第一行
baseline采用transformers提供的调包,封装好的BertForMultipleChoice (多项选择任务),它的源码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 class BertForMultipleChoice (BertPreTrainedModel ): def __init__ (self, config ): super ().__init__(config) self.bert = BertModel(config) self.dropout = nn.Dropout(config.hidden_dropout_prob) self.classifier = nn.Linear(config.hidden_size, 1 ) self.init_weights() def forward ( self, input_ids=None , attention_mask=None , token_type_ids=None , position_ids=None , head_mask=None , inputs_embeds=None , labels=None , ): num_choices = input_ids.shape[1 ] input_ids = input_ids.view(-1 , input_ids.size(-1 )) attention_mask = attention_mask.view(-1 , attention_mask.size(-1 )) if attention_mask is not None else None token_type_ids = token_type_ids.view(-1 , token_type_ids.size(-1 )) if token_type_ids is not None else None position_ids = position_ids.view(-1 , position_ids.size(-1 )) if position_ids is not None else None outputs = self.bert( input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids, position_ids=position_ids, head_mask=head_mask, inputs_embeds=inputs_embeds, ) pooled_output = outputs[1 ] pooled_output = self.dropout(pooled_output) logits = self.classifier(pooled_output) reshaped_logits = logits.view(-1 , num_choices) outputs = (reshaped_logits,) + outputs[2 :] if labels is not None : loss_fct = CrossEntropyLoss() loss = loss_fct(reshaped_logits, labels) outputs = (loss,) + outputs return outputs
做bert方面的模型扩展可以参考上面,其实就是BertModel加上了线性层。
制造模型输入数据 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class MyDataset (Dataset ): def __init__ (self, dataframe ): self.df = dataframe def __len__ (self ): return len (self.df) def __getitem__ (self, idx ): label = self.df.label.values[idx] question = self.df.Question.values[idx] content = self.df.Content.values[idx] choice = self.df.Choices.values[idx][2 :-2 ].split('\', \'' ) if len (choice) < 4 : for i in range (4 -len (choice)): choice.append('D.不知道' ) content = [content for i in range (len (choice))] pair = [question + ' ' + i[2 :] for i in choice] return content, pair, label
$61536 = 15325\times 4 + 71 \times3+ 25\times2 $
数据将变成61536条
如果用五折交叉验证: 训练集 49228 验证集12307
如果Using 8 dataloader workers every process
每个batch 8条数据的话 约等于每个epoch 训练集运行772次,验证集193次
(这个地方不知道算的对不对)
将数据做成bert需要的三种编码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 def collate_fn (data ): input_ids, attention_mask, token_type_ids = [], [], [] for x in data: text = tokenizer(x[1 ], text_pair=x[0 ], padding='max_length' , truncation=True , max_length=Param['max_len' ], return_tensors='pt' ) input_ids.append(text['input_ids' ].tolist()) attention_mask.append(text['attention_mask' ].tolist()) token_type_ids.append(text['token_type_ids' ].tolist()) input_ids = torch.tensor(input_ids) attention_mask = torch.tensor(attention_mask) token_type_ids = torch.tensor(token_type_ids) label = torch.tensor([x[-1 ] for x in data]) return input_ids, attention_mask, token_type_ids, label
DataLoader
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 train_set = utils.MyDataset(train) val_set = utils.MyDataset(val) """单卡直接写""" train_loader = DataLoader(train_set, batch_size=CFG['train_bs' ], collate_fn=collate_fn, shuffle=True , num_workers=CFG['num_workers' ]) val_loader = DataLoader(val_set, batch_size=CFG['valid_bs' ], collate_fn=collate_fn, shuffle=False , num_workers=CFG['num_workers' ]) """多卡写法""" train_sampler = DistributedSampler(train_set) val_sampler = DistributedSampler(val_set) train_batch_sampler = torch.utils.data.BatchSampler(train_sampler, batch_size=args.batch_size, drop_last=True ) train_loader = DataLoader(train_set, batch_sampler=train_batch_sampler, pin_memory=False , collate_fn=collate_fn, num_workers=2 ) val_loader = DataLoader(val_set, batch_size=args.batch_size, sampler=val_sampler, pin_memory=False , collate_fn=collate_fn, num_workers=2 )
DistributedSampler/BatchSampler:
四Sampler源码
(TORCH.NN.PARALLEL.DISTRIBUTEDDATAPARALLEL)时,DISTRIBUTEDSAMPLER(DATASET)用法解释
Dataloader 中的 num_workers:
加快训练进程
训练过程 优化配置 多层不同学习率
1 2 3 4 5 6 7 8 9 10 11 12 fc_para = list (map (id , model.module.classifier.parameters())) lstm_para = list (map (id , model.module.lstm.parameters())) gru_para = list (map (id , model.module.gru.parameters())) base_para = filter (lambda p: id (p) not in fc_para, model.module.parameters()) params = [{'params' : base_para}, {'params' : model.module.lstm.parameters(), 'lr' : args.other_lr}, {'params' : model.module.gru.parameters(), 'lr' : args.other_lr}, {'params' : model.module.classifier.parameters(), 'lr' : args.fc_lr}] scaler = GradScaler() optimizer = AdamW(model.module.parameters(), lr=args.lr, weight_decay=args.weight_decay) criterion = utils.LabelSmoothingCrossEntropy().cuda(local_rank)
梯度累积 由于机器显存限制,不得不用梯度累积来达到目的batch数。
用多次小的 mini-batch 来模拟一个较大的 mini-batch,即:global_batch_size = batch_size*iter_size
batch size 和 learning rate 要等比例放大。但需要注意:特别大的 batch size 还需要再加上其他 trick 如 warmup 才能保证训练顺利(因为太大的初始 lr 很容易 train 出 nan)。
1 2 3 4 5 6 7 loss = criterion(output, y) / args.accum_iter if ((step + 1 ) % args.accum_iter == 0 ) or ((step + 1 ) == len (train_loader)): scaler.step(optimizer) scaler.update() scheduler.step() optimizer.zero_grad()
苏神: 用时间换取效果:Keras梯度累积优化器
loss计算与warmup warmup顾名思义就是热身,在刚刚开始训练时以很小的学习率进行训练,使得网络熟悉数据,随着训练的进行学习率慢慢变大,到了一定程度,以设置的初始学习率进行训练,接着过了一些inter后,学习率再慢慢变小;学习率变化:上升——平稳——下降;
warm up setp(一般等于epoch*inter_per_epoch),当step小于warm up setp时,学习率等于基础学习率×(当前step/warmup_step),由于后者是一个小于1的数值,因此在整个warm up的过程中,学习率是一个递增的过程!当warm up结束后,学习率以基础学习率进行训练,再学习率开始递减
1、当网络非常容易nan时候,采用warm up进行训练,可使得网络正常训练;
2、如果训练集损失很低,准确率高,但测试集损失大,准确率低,可用warm up;具体可看:https://blog.csdn.net/u011995719/article/details/77884728
[LR Scheduler]warmup
模型保存与加载 这里有个小地方要注意,因为多卡并行时model用DistributedDataParallel包装了,所以在save时不时直接的model.state_dict(),而是model.module.state_dict()。 这个问题当时困扰了我好久,模型保存完的都是没经过学习的参数。
1 2 3 4 5 6 if val_acc > best_acc: best_acc = val_acc print("best:" , best_acc) if distribute_utils.is_main_process(): torch.save(model.module.state_dict(), 'spawn_adv_pgd_{}_fold_{}.pt' .format (args.model.split('/' )[-1 ], fold))
提升点 更长的文本(512、sliding window、xinet、longformer)
滑动窗口把文章截成很多段然后取平均softmax
xlnet 不限制长度,时间长
longformer 4096 transformers有提供
更好的模型(roberta、large、DUMA)
更多的数据(爬虫、C3)
先训练C3中文的有提升 但新改了规则说不让用外部数据了。
比赛复盘海华阅读理解比赛复盘
遇到的问题
五折交叉验证有的轮次收敛有的轮次不收敛
数据shuffle过,要加warmup用cosine lr,学习率往小调从2e-5调到1e-5
还有一种情况是因为label不均衡造成的,每折数据不一样
验证集loss和acc都上涨
现象很常见,原因是过拟合或者训练验证数据分布不一致造成。就是在训练后期,预测的结果趋向于极端,使少数预测错的样本主导了loss,但同时少数样本不影响整体的验证acc情况。
可能用到的外部数据 1、RACE datasethttps://github.com/zengjunjun/ChineseSquad https://github.com/ymcui/cmrc2018
1、 爬取中学语文阅读理解试题(全部选项、无标注) https://github.com/sz128/ext_data_for_haihua_ai_mrc (内含网盘下载链接)https://github.com/nlpdata/c3
MacBERT (https://github.com/ymcui/MacBERT )https://github.com/ymcui/Chinese-BERT-wwm) https://github.com/ymcui/Chinese-ELECTRA )https://github.com/brightmart/albert_zh )https://github.com/Ethan-yt/guwenbert );
 wechat
wechat alipay
alipay