Pytorch RNN之pack_padded_sequence()和pad_packed_sequence()
Pytorch RNN之pack_padded_sequence()和pad_packed_sequence()
为什么有pad和pack操作?
先看一个例子,这个batch中有5个sample
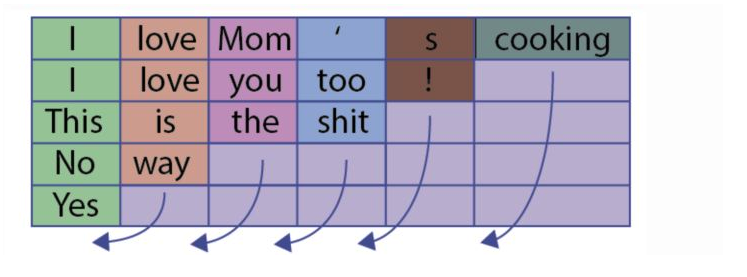
如果不用pack和pad操作会有一个问题,什么问题呢?
比如上图,句子“Yes”只有一个单词,但是padding了多余的pad符号,这样会导致LSTM对它的表示通过了非常多无用的字符,这样得到的句子表示就会有误差,更直观的如下图:
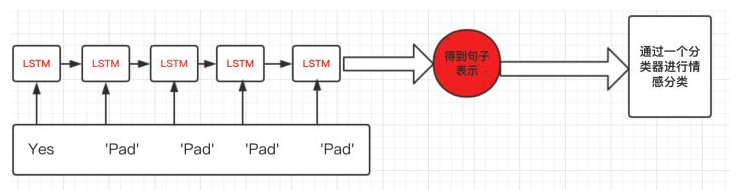
那么我们正确的做法应该是怎么样呢?
在上面这个例子,我们想要得到的表示仅仅是LSTM过完单词”Yes”之后的表示,而不是通过了多个无用的“Pad”得到的表示:如下图:
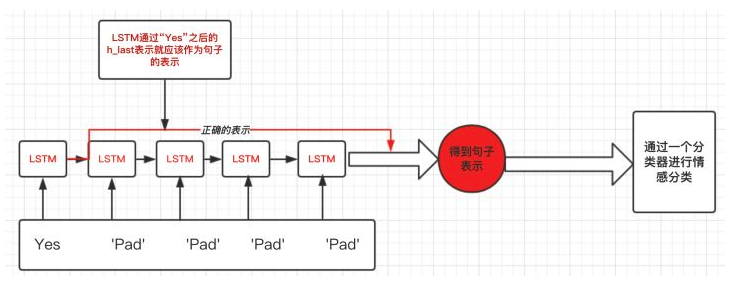
torch.nn.utils.rnn.pack_padded_sequence()
这里的pack,理解成压紧比较好。 将一个 填充过的变长序列 压紧。(填充时候,会有冗余,所以压紧一下)
其中pack的过程为:(注意pack的形式,不是按行压,而是按列压)
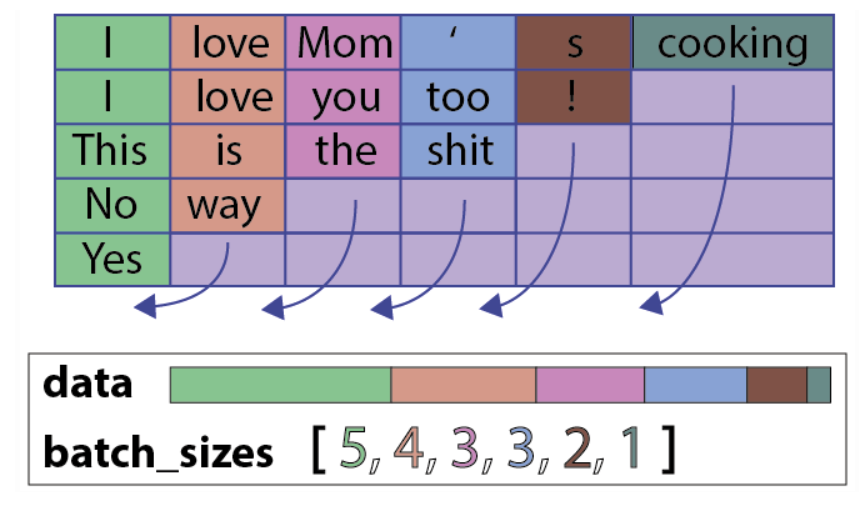
(下面方框内为PackedSequence对象,由data和batch_sizes组成)
pack之后,原来填充的 PAD(一般初始化为0)占位符被删掉了。
输入的形状可以是(T×B× )。T是最长序列长度,B是batch size,`代表任意维度(可以是0)。如果batch_first=True的话,那么相应的input size就是(B×T×*)`。
Variable中保存的序列,应该按序列长度的长短排序,长的在前,短的在后。即input[:,0]代表的是最长的序列,input[:, B-1]保存的是最短的序列。
NOTE:只要是维度大于等于2的input都可以作为这个函数的参数。你可以用它来打包labels,然后用RNN的输出和打包后的labels来计算loss。通过PackedSequence对象的.data属性可以获取Variable。
参数说明:
- input (Variable) – 变长序列 被填充后的 batch
- lengths (list[int]) –
Variable中 每个序列的长度。 - batch_first (bool, optional) – 如果是
True,input的形状应该是B*T*size。
返回值:
一个PackedSequence 对象。
torch.nn.utils.rnn.pad_packed_sequence()
填充packed_sequence。
上面提到的函数的功能是将一个填充后的变长序列压紧。 这个操作和pack_padded_sequence()是相反的。把压紧的序列再填充回来。填充时会初始化为0。
返回的Varaible的值的size是 T×B×*, T 是最长序列的长度,B 是 batch_size,如果 batch_first=True,那么返回值是B×T×*。
Batch中的元素将会以它们长度的逆序排列。
参数说明:
- sequence (PackedSequence) – 将要被填充的 batch
- batch_first (bool, optional) – 如果为True,返回的数据的格式为
B×T×*。
返回值: 一个tuple,包含被填充后的序列,和batch中序列的长度列表
例子
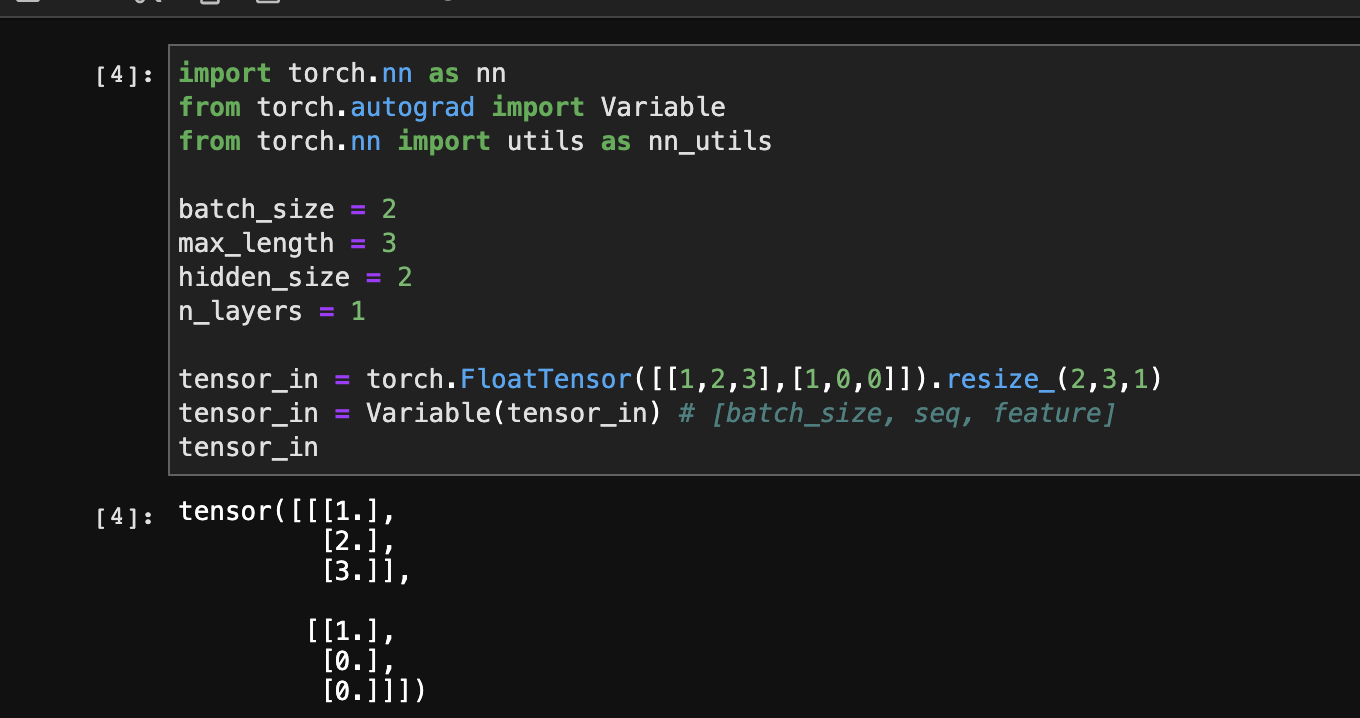
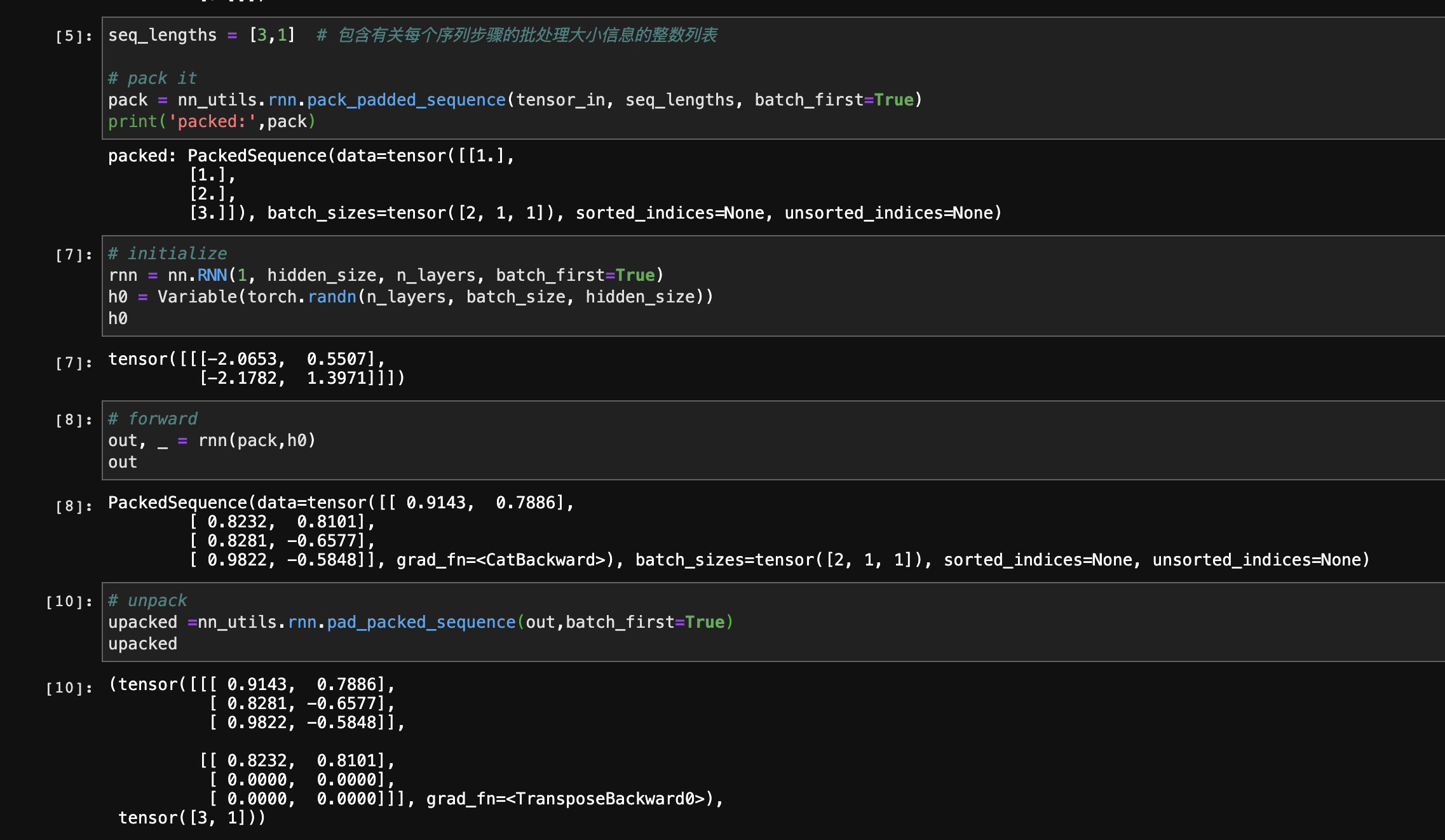
此时PackedSequence对象输入RNN后,输出RNN的还是PackedSequence对象
参考
 wechat
wechat alipay
alipay