Unsupervised Multi-hop Question Answering by Question Generation
Unsupervised Multi-hop Question Answering by Question Generation
第一个研究无监督多跳QA的。
MQA-QG致力于探索在不参考任何人工标记的多跳问答对的情况下训练性能良好的多跳QA模型的可能性。
无标签数据源分为同构和异构,即作者考虑了两种数据源,一种是结构化的表格文本数据,一种是纯文本数据。
如果推理链中只有一种数据源的叫同构,两种数据源的叫异构。
仅使用生成的训练数据,和有监督的性能做对比,对于Hybridge QA和HotpotQA数据集分别有61%和83%的有监督学习性能。其中hotpotQA(同构数据),Hybridge QA(异构数据)。
大体过程
从每个数据源中选择或生成相关信息,将多个信息整合成一个问题。
首先定义一系列operators去检索或生成相关信息。
然后定义六个推理图每个对应于一种类型的多跳问题,且是建立在operators之上的计算图。
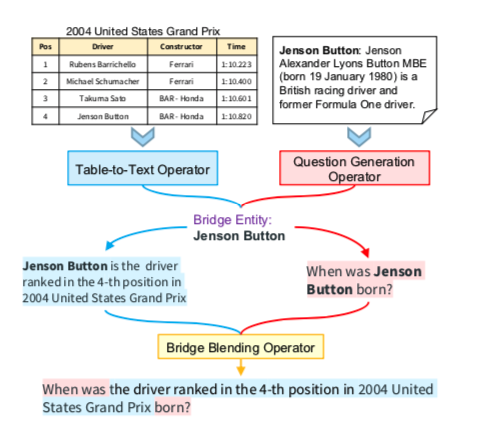
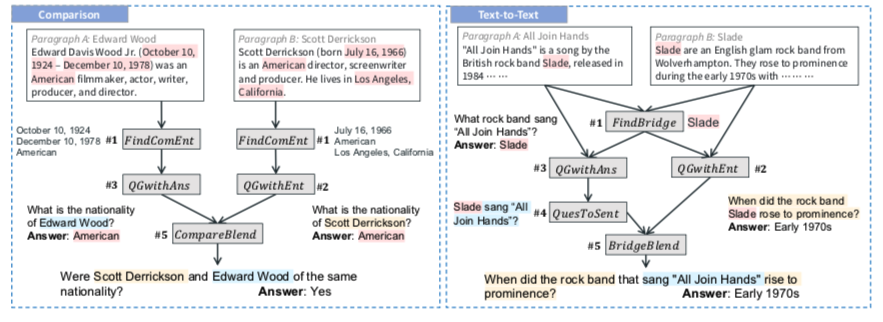
如上图,是生成table2text的问题。给出输入$(table, text)$ ,桥梁实体Jenson Button被operators找出来,他链接了文本数据和表格数据。
然后再用一个叫 (QGwithEnt operator)的操作生成了右边的一个简单的问题:简森巴顿是什么时候出生?
左边被 (DescribeEnt operator) 生成了一个描述桥梁实体的句子:简森巴顿是2004年美国大奖赛排名第4位的车手。
最后再由 BridgeBlend operator 混合成一个多跳问题:2004年美国大奖赛排名第四的车手是什么时候出生的?
具体方法
给一个问题 q 和一系列文本 $C = {C_1,…,C_n}$ 其中 $C_i$ 可能是文章、table,如果推广到多模态还可能是image。
QA model 表示为 $p_{\theta}(a|q,C)$
在本文中,作者只考虑两跳问题,并将所需的上下文表示为 $C_i$ 和 $C_j$。
主要有三个成分分别是
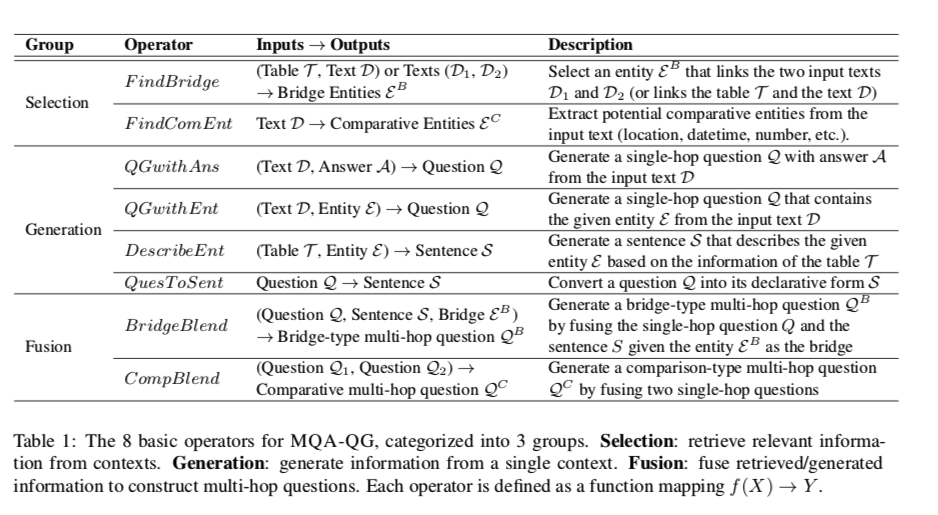
- operators:由规则或现成的预训练模型实现的原子操作,用于从输入上下文 $(C_i、C_j)$ 检索、生成或融合相关信息。
- reasoning graphs:不同的推理图定义了不同类型的以operators构建的多跳QA推理链。通过执行推理图生成训练 (q,a) 对。
- question filtration:去除不相关和不自然的(q,a)对,给出多跳问答的最终训练集D。
Operators
定义了8个基本operator ,分为三种类型:
- 选择:从单个上下文中检索相关信息
- 生成:从单个上下文中生成信息
- 融合:将多个检索或生成的信息进行融合,以构造多跳问题。
FindBridge
大多数多跳问题依赖于连接不同输入上下文的实体整合多条信息,即桥梁实体。
FindBridge将两个上下文 $(C_i、C_j)$ 作为输入,并提取出现在 $C_i$ 和 $C_j$ 中的实体作为桥实体。如在第一个图中,提取“Jenson Button”作为桥实体。
FindComEnt
在生成比较类型的多跳问题时,我们需要决定为桥实体比较什么属性。
Find-Coment提取潜在的可比性,从文本中提取具有NER类型的实体作为比较属性(国籍、位置、日期时间和数字)。
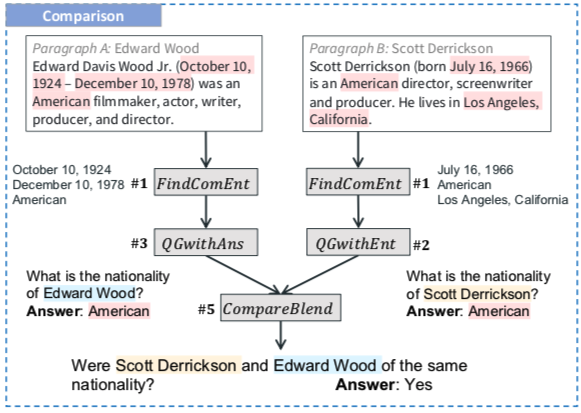
如上图的 #1 步骤
QGwithAns和QGwithEnt
这两个都是生成简单的单跳问题的, 随后会被用来合成多跳问题。
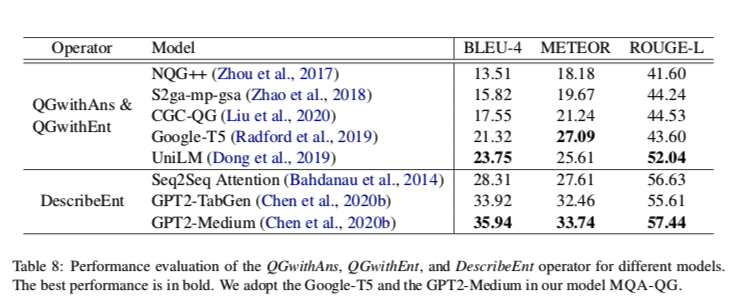
作者使用预培训好的Google T5模型微调在SQuAD来实现这两个操作员。给定上下文-问题-答案三元组训练集D={(c,q,a)},我们在两个任务上联合微调模型。给定上下文-问题-答案三元组训练集 $D={(c,q,a)}$ ,在两个任务上联合微调模型。
- QGwithAns的目标是生成一个问题Q,其中a为答案,给定(c,a)为输入。
- QGwithEnt旨在生成包含特定实体e的问题Q,给定(c,e)作为输入。
CompBlend
基于两个单跳问题Q1和Q2组成比较型多跳问题。这两个问题询问两个不同实体e1和e2的相同比较属性p。我们通过将p、e1和e2填入预定义模板来形成多跳问题。
DescribeEnt
给定table $T$ 和表中的目标实体 e,DescribeEnt operator 基于T中的信息生成描述实体 e 的语句。使用GPT-TabGen模型,该模型首先使用模板将T 变成文档 $P_T$,然后将 $P_T$ 送到GPT-2生成输出句子 Y
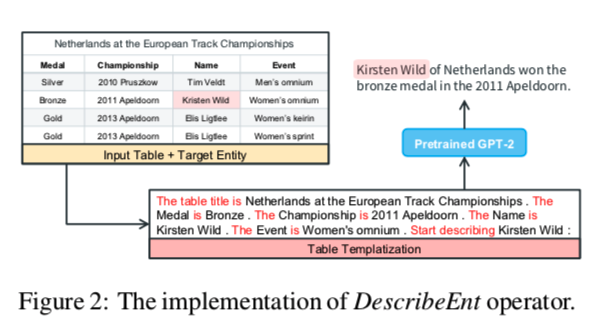
为了避免 $P_T$中存在不相关信息,应用了一个仅描述目标实体所在行的模板。然后,在 ToTTo 数据集上通过最大化 $p(Y|P_T;β)$ 的来微调模型,β表示模型参数。ToTTo 数据集是一种受控的表格到文本生成的大规模数据集。
QuesToSent
通过应用《Transforming question answering datasets into natural language inference datasets》定义的语言规则将问题Q转换成其陈述形式s。
BridgeBlend
基于1)桥接实体e。2)包含e的单跳问题q。3)描述e的句子s。组成桥接型多跳问题。

作者通过应用简单但有效的规则来实现这一点,该规则将 Q中的桥接实体 e替换为 “the [MASK] that s”,并采用预训练的Bert-Large来填充[MASK]。
Reasoning Graphs
基于以上的operators ,作者定义了6种类型的推理图,生成不同类型的问题。
每个问题都是有向无环图 G,每个G对应一个operator。
一共有四类:
- Table-to-Text:表格和文本之间的桥接式问题,答案来自文本。
- Text-to-Table :表格和文本之间的桥接式问题,答案来自表格。
- Text-to-Text : 桥接类型,两边都是文本。
- Comparison:基于两篇文章的比较型问题。
通过执行每个推理图来生成QA对。通过定义新的算子和推理图,可以很容易地扩展到其他模态和推理链。
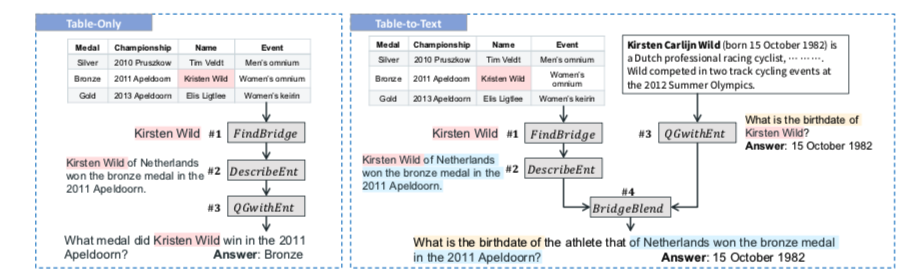
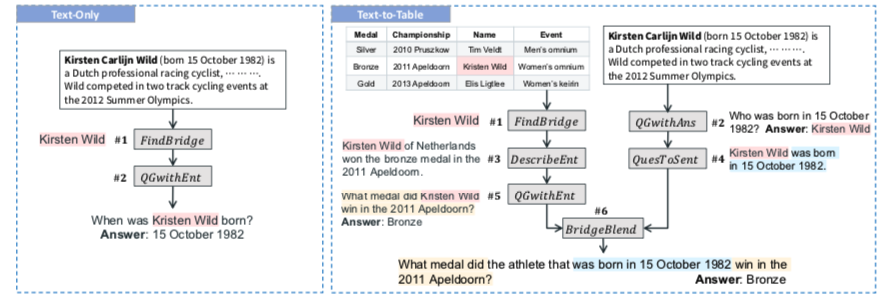
Question Filtration
使用了两种方法来提炼生成的QA对的质量
- Filtration:使用预先训练的gpt-2模型来过滤解决那些不流利或不自然的问题。选择困惑度最低的前N个样本作为生成的数据集来训练多跳QA模型。
- Paraphrasing:基于BART模型训练一个问题解释模型来解释每个生成的问题。
实验表明,过滤给QA模型带来了明显的改进。然而,在实验中展示了释义产生了更多类似人类的问题,但是引入了语义漂移问题,从而损害了QA性能。
为了生成更自然的问题,我们试图训练一个基于BART的问题释义模型,以对每个生成的问题进行语法分析。观察到,通过将原问题的冗余部分改写成更简洁的表达,释义确实产生了更多的流行性问题。然而,释义引入了“语义漂移”问题,即释义后的疑问句改变了原疑问句的语义。我们认为这会影响QA性能,因为它会产生问答不一致的嘈杂样本。
作者认为在无监督多跳问答中,对于生成的问题,语义的忠实性比流利性更重要。这就解释了为什么设计手工制作的推理图来保证语义的忠实性。然而,如何在保持语义忠实性的同时生成流畅的类人问题是未来的一个重要方向。
实验
对于Hybridge QA,问题按其答案是来自表格(56%)还是来自段落(44%)进行划分。大约80%的Hybridge QA问题需要桥接式推理。
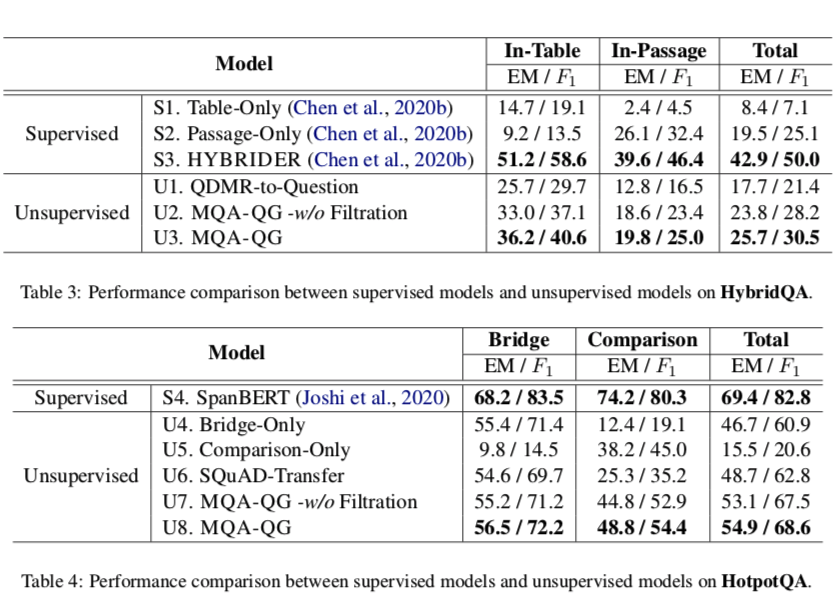
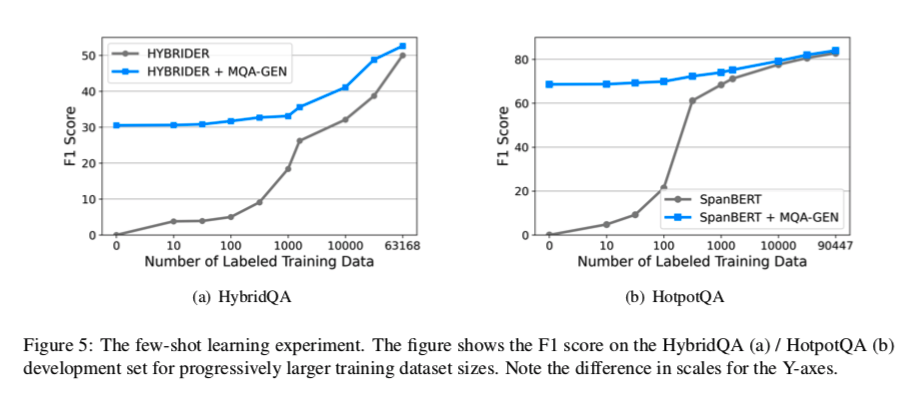
在Hybridge QA和HotpotQA上的QA性能。
 wechat
wechat alipay
alipay





