Is Graph Structure Necessary for Multi-hop Question Answering?
Is Graph Structure Necessary for Multi-hop Question Answering?
图结构对多跳问答有多大贡献?
这是一篇只有6页的类似实验报告的论文。是在作者在做实验时发现,图结构和邻接矩阵都是与任务相关的先验知识,graph-attention可以看作是self-attention的特例。实验和可视化分析表明,self-attention和transformer可以代替graph-attention或整个图形结构,并且效果无明显变化,从而对图网络在自然语言处理任务上的应用能力提出了质疑。并希望未来引入图结构纳入自然语言处理任务的工作,应说明其必要性和优越性。
作者使用 Dynamically Fused Graph Network 那篇文章作为baseline开展了研究。
Baseline
首先描述baseline模型,证明了只有当预先训练的模型以feature-based的方式使用时,图结构才能发挥重要作用。虽然在fine-tuning方法中使用预先训练的模型,但图结构可能没有帮助。
作者复现了DFGN,并修改了预训练模型的使用。该模型首先利用检索器从候选集合中选择相关段落,并将其提供给基于图形的阅读器。实体图中的所有实体都由独立的NER模型抽取而来。
检索器:在HotpotQA任务中使用Roberta Large模型来计算查询与每个候选段落之间的相关得分。我们对得分小于0.1%的段落进行过滤,最大入选段落数为3,入选段落拼接为Context C
编码层:我们将查询Q和上下文C连接起来,并将序列提供给另一个Roberta,结果被进一步送到Bi-attention layer 以从编码层获得表示。
图形融合块:给定第 t-1 跳的上下文表达 $C{t-1}$ , 将token送入到mean-max pooling得到实体图$H{t-1}\in R^{2d\times N}$, 其中N是实体的数量。之后采用的是图注意力层更新节点表达:
还有查询实体关注、查询更新机制、弱监督等模块。
构建实体图:上下文中具有相同提及文本的实体被连接、同一句中出现的实体是相连的。
最终预测层
作者将将预训练语言模型的输出直接送到预测层,由于基线模型与DFGN的主要区别在于我们在fine-tuning方法中使用了large的预训练模型,而不是基于feature-based的方法,因此在两种不同的设置下进行了实验。在HotpotQA上提交的结果,并进行了消融实验对比如下:
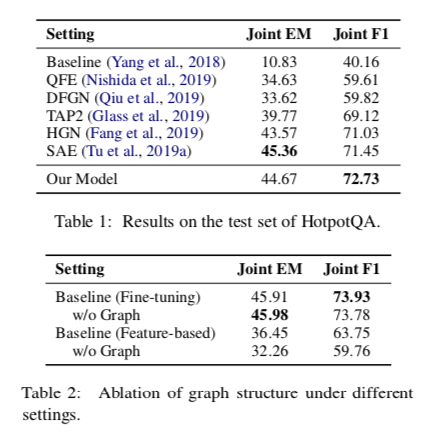
结果表明在fine-tuning下有没有图结构效果不明显,在feature-based下图结构是有明显作用的。
graph-attention是self-attention的一种特例
基于人工定义的规则和图结构的邻接矩阵可以看作是先验知识边,可以通过self-attention或Transformers来学习
基于以上的实验结果表明,自我注意或变形金刚在多跳问题回答中可能具有优势。
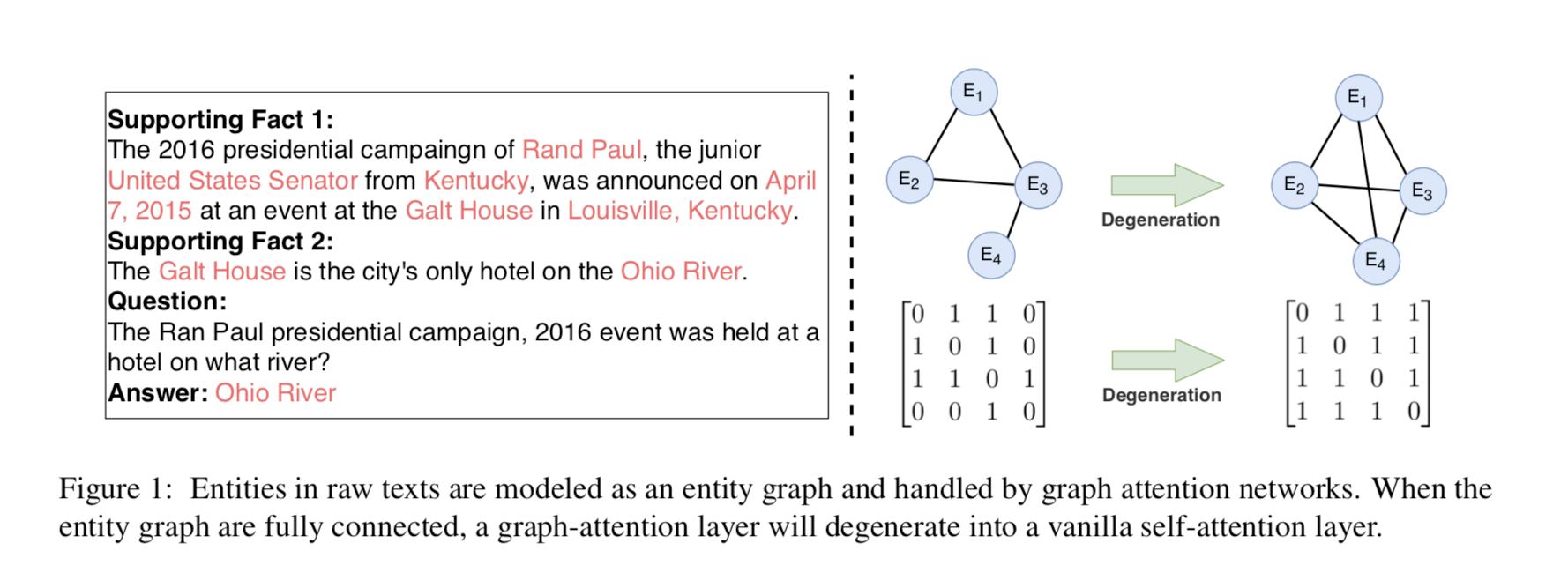
解决多跳问题的关键是通过查询在原文中找到对应的实体。然后,构建从这些起始实体到其他相同或共现实体的一条或多条推理路径。如图1所示,以前的工作通常从多个段落中提取实体,并将这些实体建模为实体图。邻接矩阵是由人工定义的规则构建的,这些规则通常是实体之间的共现关系。从这个角度看,图的结构和邻接矩阵都可以看作是与任务相关的先验知识。实体图结构限制了模型只能基于实体进行推理,邻接矩阵辅助模型忽略一跳中的非相邻节点。然而,可能是在没有任何先验知识的情况下,模型仍然可以学习实体到实体的注意模式。
此外从上文图注意力的公式来看,不难发现图注意力与自我注意具有相似的形式。在前向传播中,实体图中的每个节点都会计算与其他连接节点的关注度得分。如图1所示,当图中的节点完全连接时,图注意力将退化为普通的自我关注层。因此,图形注意可以看作是自我注意的一种特例。
基于以上的想法,作者将图结构做成全连接的实体和self-attention做了一次实验比较,为了验证整个图结构能否被transformer取代。
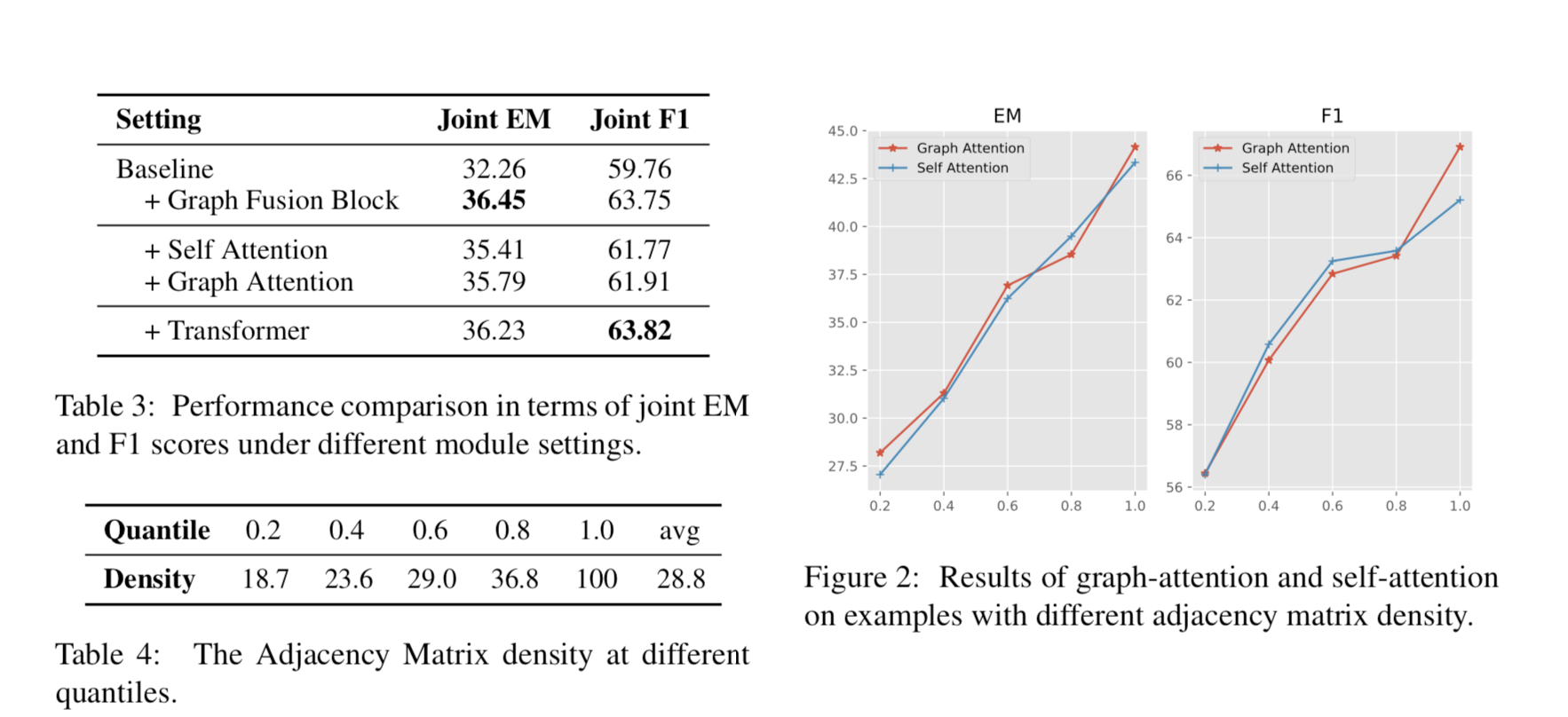
实验结果如图,与自我注意相比,图形注意并没有显示出明显的优势。
对于图形注意和自我注意在不同密度区间的结果。尽管邻接矩阵的密度不同,但图形注意与自我注意的结果是一致的。这意味着自我关注可以学会忽略不相关的实体。
此外,transformer显示出强大的推理能力。只有叠加两层变压器才能获得与DFGN相当的效果。
并且作者分布从Entity2Entity、Attribute2Entity、Coreference2Entity、Entity2Sentence角度可实话了注意力权重在预训练语言模型中效果:

认为基于实体的图网络忽略了后三种链接的信息,我认为可能异质图更多的解决这个问题。
 wechat
wechat alipay
alipay





