海华阅读理解比赛复盘
海华阅读理解比赛复盘
比赛详情、EMA、Baseline,本文主要记录提分点和模型改进的验证
参考上文 海华中文阅读理解比赛梳理/多卡并行/transformers
数据增强
数据增强的办法很多参考 https://zhuanlan.zhihu.com/p/145521255
我只采用了句子乱序和数据回译,都是将增强数据和原始数据挨着放到数据集中,在训练的时候停用shuffle。(可能有其他方法:每条数据根据概率来选择性增强),我这种可能会让数据集臃肿,质量下降。
句子乱序
没有提分,也没有降很多。
原因参考:从知觉谈中文乱序不影响阅读的原因
代码:https://github.com/Coding-Zuo/MRC_multiChoice/blob/main/train/data_process.py 中的data_enhancement_sentence_order
数据回译
和句子乱序一样和回译到的数据和原始数据挨着放到数据集,没有提分,可能是回译到的数据质量不好。
使用的是百度API,百度限制一个账户免费200万字符,如果超了就多注册几个账户薅羊毛。
代码:https://github.com/Coding-Zuo/MRC_multiChoice/blob/main/TranslateAPI.py
在训练集上打伪标签
由于时间问题,没有直接提交伪标签训练的结果,就直接模型融合。验证集有提高。
用训练好的模型去inference测试集,取了模型认为有百分之85概率认为是正确答案的数据打上伪标签,加入到训练集训练。
优化训练
EMA
滑动平均exponential moving average
没有提分,反而效果变差。具体原因,还在探索,可能和优化方法有关?
我一直使用的都是adamw,比较Adam 和Adamw 一文告诉你Adam、AdamW、Amsgrad区别和联系,AdamW是在Adam+L2正则化的基础上进行改进的算法。
可以和sgd搭配看看效果。(这方面因为时间问题没有尝试充足)
指数移动平均EMA是用于估计变量的局部均值的,它可以使变量的更新不只取决于当前时刻的数据。
而是加权平均了近期一段时间内的历史数据,是的变量的更新更平滑,不易受到某次异常值的影响。
labelSmoothing
精度提升不明显,但是缓解了验证集的loss上升。
1 | class LabelSmoothingCrossEntropy(nn.Module): |
对抗训练
提升两个点以上
可参考我的 ppt 和以前文章
主要使用了fgm和pgd两个,都有提升的效果
但有时候pgd并没有提升,可能是在有些参数和加了伪标签的数据情况下,学习困难?
早停
bert的早停不太好控制,有时候一两个epoch之后还会更新,可能跟参数有关。
模型改进
尝试用LongFormer
因为文本比较长,但因为没有时间测试而没有跑,不过已经基本调通,日后跑一跑。
复现DUMA
用co-attention 来分别处理 bert输出的文章编码和问题答案对编码,分别送到co-attention中。
我的方法是分别为文章和问题答案设置一个maxlen, 多的截掉,因为我机器只能最大总长度跑到400,而数据文章又比较长,可能这也会导致学习瓶颈的出现。
我的另一个实现想法但是没有时间做的是,把文章和问题答案拼在一起用sep分割送入bert,输出时只要找到sep的timesteps进行分割,对于得到的两个不等长的向量,在经过对其。送入co-attention。
训练刚开始有一个比较好的提分劲头,但随着深入训练后期效果乏力。可能是因为参数没有调好?DUMA那篇论文没有复现细节。
尝试其他比赛前排模型
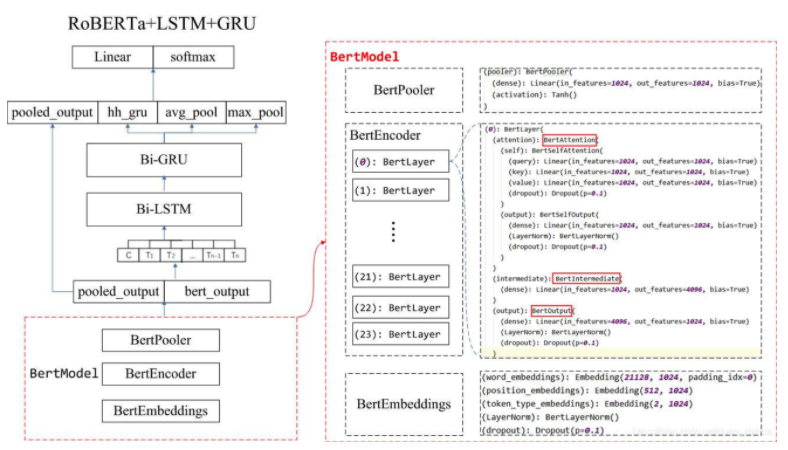
移植后问题:训练集准确率很低,具体问题还需探究。
尝试在bert后加self-attention层
用pool_output,投入自注意力,没有明显提升
在bert后加多层线性也没有明显提升。不过可以尝试加highway network。
模型融合
组合不同参数和结构的打包模型,用argmax的方法融合了九个,达到最好的51.7分,晋级分数最终为52分,遗憾落榜。
还尝试用实现vote投票来融合,并没有最终提交。
以后将会尝试实现bert的stacking融合。
遇到的难题
bert换成roberta后始终不收敛,因为没有经验,学习率试过1e-5, 1e-6, 2e-5,和不同batch32、64、128进行组合都不收敛(浪费了很多时间)。最终发现学习率在1e-5,2e-5 ,batch 在8或16才会收敛。
并参照roberta论文附录中的参数,收敛了,但是效果没有达到预期,不过听说好多人也是用了roberta。
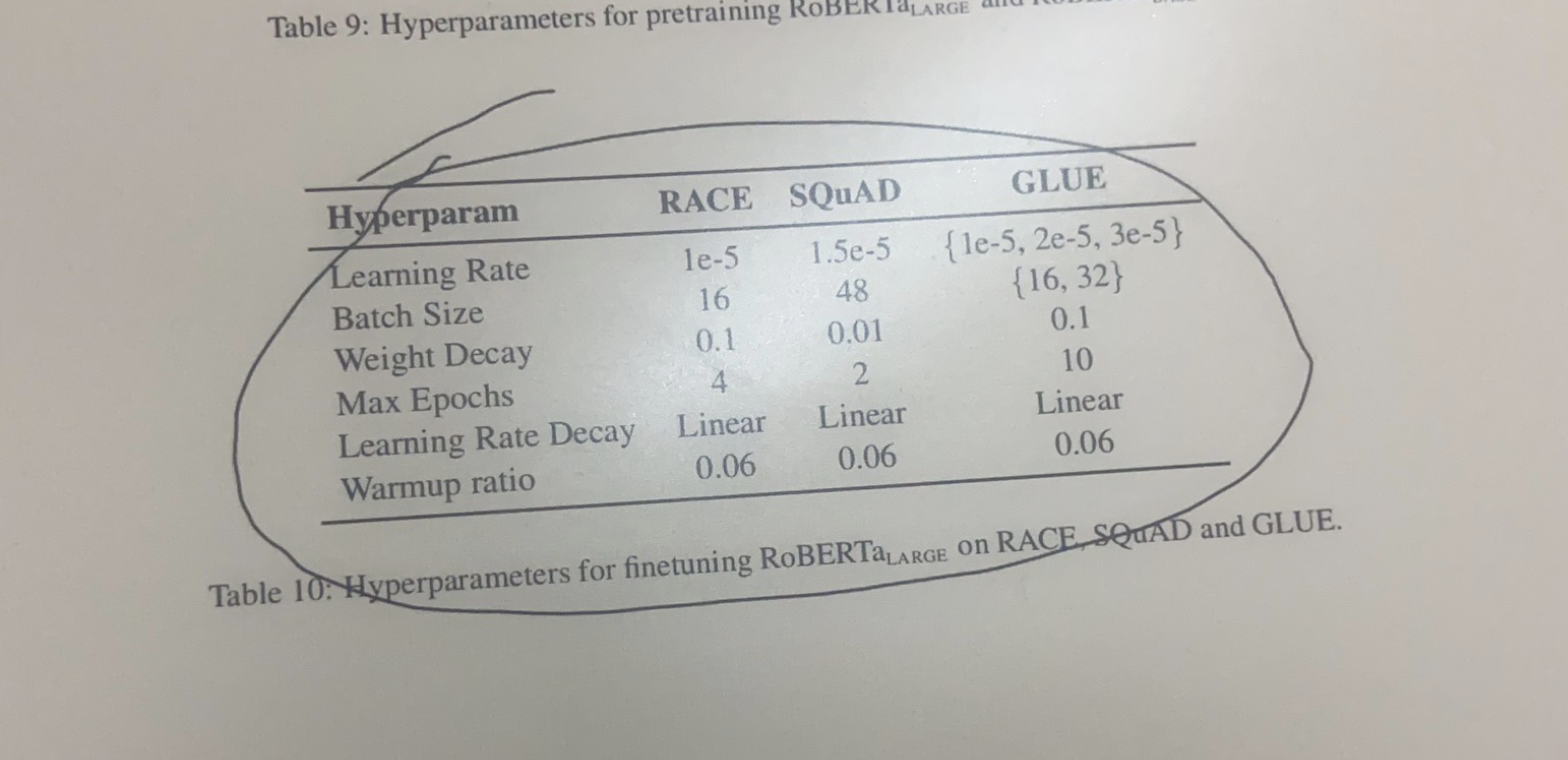
- 调参没经验,浪费了很多时间。
总结
用了将近一个月的时间来做这个比赛,对模型训练体系、模型理解、微调下游任务、多卡并行、对抗训练。还有好多理论需要通过实践来加深理解。
 wechat
wechat alipay
alipay