Pytorch多GPU并行实例
Pytorch Train_Multi_GPU
https://pytorch.org/tutorials/intermediate/ddp_tutorial.html
两种方式:
- DataParallel(DP):Parameter Server模式,一张卡位reducer,实现也超级简单,一行代码。
- DistributedDataParallel(DDP):All-Reduce模式,本意是用来分布式训练,但是也可用于单机多卡。
最后还有一个pycharm远程服务器的配置,还有如何在pycharm里配置run参数为:
1 | python -m torch.distributed.launch --nproc_per_node=4 --use_env train_multi_gpu_using_launch.py |
这个行运行命令是用DistributedDataParallel时的,指定的运行参数。具体介绍在后面写。
DataParallel vs DistributedDataParallel
如果模型太大而无法容纳在单个GPU上,则必须使用 model parallel 将其拆分到多个GPU中。 DistributedDataParallel与模型并行工作; DataParallel目前不提供。
DataParallel是单进程、多线程的,只能在单机上工作,而DistributedDataParallel是多进程的,既可用于单机,也可用于多机。即使在一台机器上,DataParallel通常也比DistributedDataParallel慢,这是因为线程间的GIL争用、每次迭代复制模型以及分散输入和收集输出带来的额外开销。
DistributedDataParallel适用于模型并行;DataParallel目前不能。当DDP与模型并行相结合时,每个DDP进程使用模型并行,所有进程共同使用数据并行。
单机多卡理论基础
- 按照并行方式来分:模型并行 vs 数据并行
- 按照更新方式来分:同步更新 vs 异步更新
- 按照算法来分:Parameter Server算法 vs AllReduce算法
常见的多GPU使用
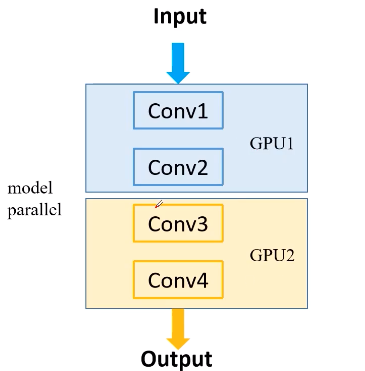
模型并行,将网络不同模块放到不同GPU上去运行。训练速度无提升,但可让非常大的模型分布在多块gpu。
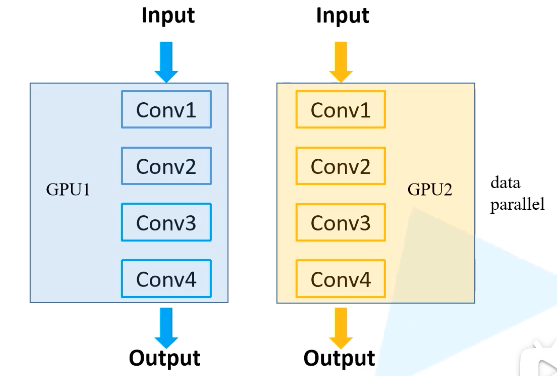
数据并行,将数据和模型同时放到多个GPU,同时进行正向传播和反向传播,并行输入样本进行训练, 相当于加大了batchsize,训练速度也加快了。
数据如何在不同设备间进行分配
误差梯度如何在不同设备间通信
多GPU训练常用启动方式
- torch.distributed.lauch : 代码量少,启动速度快。如果开始训练后,手动强制终止程序,有小概率会出现进程没有杀掉的情况。
- torch.multiprocessing: 拥有更好的控制和灵活性
DataParallel
https://pytorch.org/tutorials/beginner/blitz/data_parallel_tutorial.html
DistributedDataParallel(DDP)
DistributedDataParallel(DDP)在module级别实现数据并行性。它使用torch.distributed包communication collectives来同步梯度,参数和缓冲区。并行性在单个进程内部和跨进程均有用。在一个进程中,DDP将input module 复制到device_ids指定的设备,相应地按batch维度分别扔进模型,并将输出收集到output_device,这与DataParallel相似。
处理速度不同步时
在DDP中,Model, forward method 和 differentiation of the outputs是分布式的同步点。期望不同的过程以相同的顺序到达同步点,并在大致相同的时间进入每个同步点。否则,快速流程可能会提早到达,并在等待时超时。因此,用户负责进程之间的工作负载分配。有时,由于例如网络延迟,资源争用,不可预测的工作量峰值,不可避免地会出现不同步的处理速度。为了避免在这些情况下超时,请确保在调用init_process_group时传递足够大timeoutvalue
常见报错
subprocess.CalledProcessError: Command ‘[’/home/labpos/anaconda3/envs/idr/bin/python’, ‘-u’, ‘main_distribute.py’, ‘–local_rank=1’]’ returned non-zero exit status 1.
这个错出现是前面有代码写的不对,可以先在DistributedDataParallel 中加入find_unused_parameters=True。试试,一般不是分布式部分的错,是前面哪里写的不对。很可能是data_loader哪里仔细检查一下。
验证集loss和acc都上涨
验证集loss上升,acc也上升这种现象很常见,原因是过拟合或者训练验证数据分布不一致导致,就是在训练后期,预测的结果趋向于极端,使少数预测错的样本主导了loss,但同时少数样本不影响整体的验证acc情况。
问一下,这时如果设置早停,是不是以loss最小早停合理点?以前见过用准确率设置早停的。假设交叉熵损失,训练与验证集分布大概一致的条件下
答:准确率比较好
遇到问题
loss下降但最终效果不好,得到的模型结果像是只在四分之一数据做训练后的效果。
参考文献
 wechat
wechat alipay
alipay




