Multi-hop Reading Comprehension across Multiple Documents by Reasoning over Heterogeneous Graphs
Multi-hop Reading Comprehension across Multiple Documents by Reasoning over Heterogeneous Graphs
京东出品19年采用异质图网络的一篇多跳阅读理解,这篇是在WikiHopQA数据集上,在没有使用预训练语言模型的情况下第一次超过人类表现。20年还有一篇在HotpotQA上的,过两天准备也读一读。前一阵子用京东在线客服和智能语音客服的时候,感觉效果不错,果然发现这两篇文章。
先说一下WikiHopQA
训练集43,738个样本,开发集5129个。候选答案个数2-79个之间,平均19.8个。文档数3-63个,平均13.7篇。每篇文档的字数4-2046字,平均100.4个字。该数据集的难度在于,要从多篇文章中找相关文档,还要依据多篇文章做推理。推理跳数的增加,与问题的相关性越来越小,统计距离较远,非参数化的检索方法如传统的TF-IDF,无法搜索到最终答案所在的上下文。如下图:

每个样本包含字段:dict_keys([‘answer’, ‘id’, ‘candidates’, ‘query’, ‘supports’])
目前主要做法有三种思路:构造推理链,一般用RNN网络进行链式推理;从网络模型角度改进;构造graph,利用GCN,GAT等方法在图上推理。
和HotpotQA一样都是属于多跳阅读理解数据集。针对一个问题给出多个支撑文档,来做推理。可看之前的文章HotpotQA数据集
不同的是,WikiHopQA给出了候选答案,可以看成是多项选择题。
创新点
提出Heterogeneous Document-Entity graph (HDE graph) ,可以从候选答案、文档和实体中,聚合不同级别的信息粒度。
使得不同类型的节点之间能够进行丰富的信息交互,从而便于精确的推理。不同类型的节点与不同类型的边相连,以突出查询、文档和候选之间呈现的各种结构信息。
如何设计
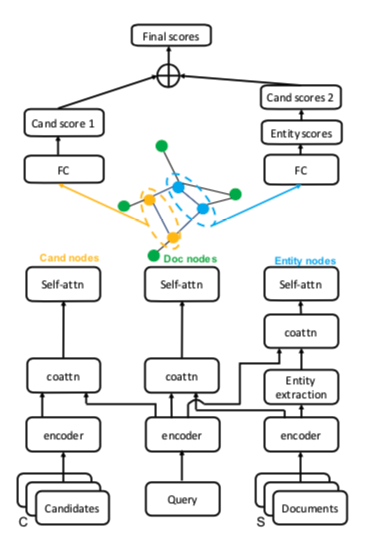
数据集提供的是候选答案、问题和一系列文档。分布作为输入,分别表示为:$C_q, q(s,r,?), S_q $
其中,$q(s,r,?)$ 内分别表示为主体、关系和位置客体。任务是预测查询的正确答案$a^*$。
首先将这些输入文字,映射成词向量,分别为 $X_q\in R^{l_q\times d}$ 、$X_s^i\in R^{l_s^i\times d}$ 其中i为第i个词、 $, X_c^j\in R^{l_c^j\times d}$ 其中j为第j个词。
$l$ 为每段文字长度 ,d为词向量维度。
这就是上图中的最下面一层。
再往上一层encoder采用的是双向GRU,分别对C/q/S 的上下文信息进行编码。
编码后的维度是 $ H_q\in R^{l_q\times h}$ 、 $H_s^i\in R^{l_s^i\times h}$ 、 $H_c^j\in R^{l_c^j\times h}$ 其中h是RNN输出维度。
再观察上图,发现在encoder上面一层,Documents上面和其他两个地方不同,中间加了一个实体提取。
是作者发现有些通过查询query和候选答案C,在文档中提取被提及的实体。提取到每个mentions的开始位置和结束位置。
每一次提及都被视为一个实体Entiry。第i个文档提出的实体表示为 $H_s^i, M\in R^{l_m\times h}$ , $l_m$ 是实体长度。
再向上一层,是co-attention协同注意力机制,特意读了下协同注意力DCN那篇文章协同注意力和自注意力的区别(DCN+)
用到这个任务上其实就是一个协同每两个特征来提取新特征。
通俗上讲,Q和S 相互co-attention就是带着问题看文章,读完文章看问题。C和Q做带着选项看问题。
拿RNN输出的问题序列$H_q \in R^{l_q\times h}$ 和文档$H_s^i\in R^{l_s^i\times h}$为例计算过程如下:
得到查询和每个字的点积打分。
为简化起见,在后面的上下文中,我们使用上标i,它表示对第i个文档的操作。
进一步使用GRU ,f 对共同参与的文档上下文进行编码
最终拼接
同样的co-attention应用在query和候选,query和实体得到 $C{CA},E{ca}$ 。
注意,作者不在查询和对应于查询主题的实体之间共同关注,因为查询主题已经是查询的一部分。为了保持维度的一致性,应用了一个具有tanh激活函数的单层多感知器(MLP),将查询主题实体的维数增加到2h。
这个查询主题query subject到底是什么我有点疑问。
再往上是一个自注意力池化。
当co-attention产生文档的查询感知上下文表示时,自关注集合被设计为通过选择重要的查询感知信息将顺序上下文表示转换为固定维度的非顺序特征向量。
同样,对每个实体和候选,可得到 $c{sa}, e{sa}$ 。
再接下来就是构建异质图了。
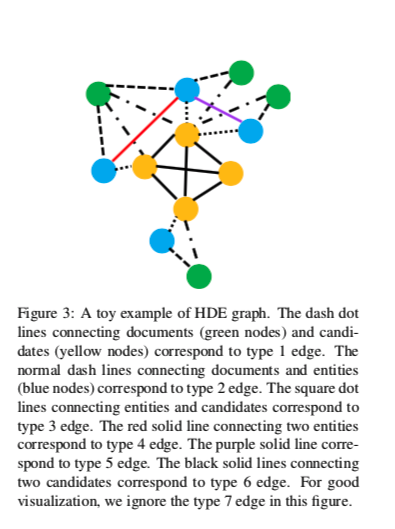
一共三种类型的节点,绿色是文档节点、蓝色是实体节点、黄色是候选答案节点。
七种建边规则:
- 文档节点和候选节点:如果候选节点在文档中出现时建立一条边。
- 文档节点和实体节点:如果实体节点从这个文档中提取出来建立一条边。
- 候选节点和实体节点:如果实体节点被候选答案提及建立一条边。
- 两个实体节点之间:如果他们在同一个文档中被提取时建立一条边。
- 两个实体节点之间: 如果他们被相同的候选或问题提及,且实体在不同的文档中时建立一条边。
- 所有的候选节点相互连接
- 不满足以上条件的不进行相连。
HGN传播聚合机制
信息传递
其中R 是所有边的类型
$N_i^r$ 是 第i个节点边类型是r的邻居集合
$h_j^k$ 是第j个邻居节点的第k层表达
$h_j^0$ 是self-attention的输出
$f_r$ 是MLP
$z_i^k$ 是第i个节点第k层的局和信息
可以与变换更新后的节点i:
$f_s$ :MLP
为了解决多层GNN的过平滑问题,作者采用了加门控的方式。
$\odot$ :element-wise product = element-wise multiplication = Hadamard product
含义:两个矩阵对应位置元素进行乘积
以上的$f$ 都是单层MLP 输出维度为2h
最终预测
使用候选节点和与候选提及相对应的实体节点的最终节点表示来计算分类分数:
$H^C \in R^{C\times 2h}$ , C是候选数量
$H^M \in R^{M\times 2h}$ , M是节点数量
$f_C,f_E$ 两层MLP
$ACC_{max}$ :是对属于同一候选者的实体的分数取最大值的操作。
隐含层大小为输入维的一半,输出维数为1,我们将可预测节点和实体节点的得分直接相加,作为多个候选者的最终得分。因此,输出分数向量$a∈r^{c×1}$给出了所有候选的分布。由于任务是多类分类,采用交叉熵损失作为训练目标,以a和标签作为输入。
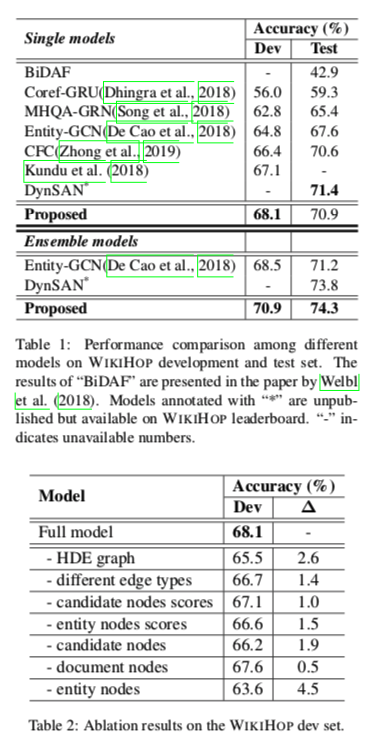
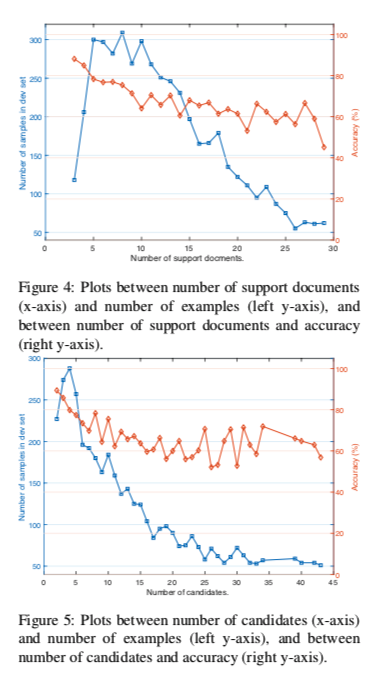
实验
 wechat
wechat alipay
alipay





