
已知后序序列构建二叉搜索树
已知后序序列构建二叉搜索树思路:
[2,4,3,6,8,7,5]
最后一个是根节点,从后往前找,第一个比根小的数是左子树的根,根前面的数是右子树的根。
就变成了子问题,已知他们的根,怎么构建左子树和右子树
时间复杂度$O(N^2)$
优化用二分法,找比根小的节点,一直找到无法二分。就可以找到有序的部分。遍历行为替换成二分。
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475public class PosArrayToBST { public static class Node { public int value; public Node left; public Node right; public Node(int v) { value = ...

HotpotQA数据集
HotpotQA数据集:A Dataset for Diverse, Explainable Multi-hop Question Answering官方地址:https://hotpotqa.github.io/index.html
为解决当前QA数据集不能训练系统回答复杂问题和提供可解释的答案问题而提出。
摘要HotpotQA基于113k(十一万三千)个维基百科问答对,有四个特点:
问题需要对多个支持文档进行查找和推理才能回答
问题是多样的,不受任何预先存在的知识库或知识模式的限制
提供句子级别的推理所需的事实支持,允许QA系统在强有力的监督下进行推理和解释预测
提供了一种新型的拟事实比较问题来测试QA系统提取相关事实和进行必要比较的能力。
所构建的多跳问答数据集样式
贡献构建维基百科超链接图使用整个英文维基百科做为语料库。
维基百科文章中的超链接通常自然地涉及上下文中的两个(已经消除歧义的)实体之间的关系,这可能被用来促进多跳推理。
每篇文章的第一段通常包含许多可以有意义地查询的信息。
基于这些观察,我们从所有维基百科文章的第一段中提取了所有的超链接。用这些超链接,构建 ...
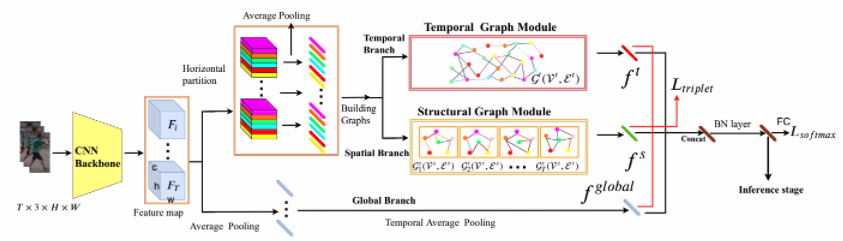
Spatial-Temporal Graph Convolutional Network for Video-based Person Re-identification(CVPR2020)
Spatial-Temporal Graph Convolutional Network for Video-based Person Re-identification(CVPR2020)我做的ppt:https://coding-zuo.github.io/re-id-ppt/index.html
行人重识别行人重识别(PersonRe-identification),简称为ReID,是利用计算机视觉技术判断图像或者视频序列中是否存在特定行人的技术。广泛被认为是一个图像检索的子问题。给定一个监控行人图像,检索跨设备下的该行人图像。
方法分为以下几类:
基于表征学习的ReID方法
基于度量学习的ReID方法
基于局部特征的ReID方法
基于视频序列的ReID方法
基于GAN造图的ReID方法
本文基于视频序列的ReID方法通常单帧图像的信息是有限的,因此有很多工作集中在利用视频序列来进行行人重识别方法的研究(本篇论文就是)。基于视频序列的方法最主要的不同点就是这类方法不仅考虑了图像的内容信息,还考虑了帧与帧之间的运动信息等。
CNN&RNN利用CNN来提取图像的 ...

LeetCode470随机函数返回等概率的值
LeetCode470随机函数返回等概率的值
问题描述:
给定一个随机函数f,等概率返回1~5中的一个数字,这是唯一可以是使用的随机机制,如何实现等概率返回1~7中的一个数字。
给定一个随机函数f,等概率返回a~b中的一个字母,这是唯一可以是使用的随机机制,如何实现等概率返回a~d中的一个数字。
这种做法一般考虑用二进制的方法,等概率的返回0和1。
如有一个等概率返回12345的函数f
f’:如果是1和2返回0,4或5返回1,如果是3重新调用f’。
用0和1拼出一个数这样就可以实现等概率。
只有两个二进制位,可以等概率返回0到3。00、01、10、11
三个二进制位,可以等概率返回0到7。000,001,010,011,100,101,110,111
Leetcode:
12345678910111213141516171819class Solution extends SolBase { public int rand10() { int ans = 0; do { ans = (rand01 ...
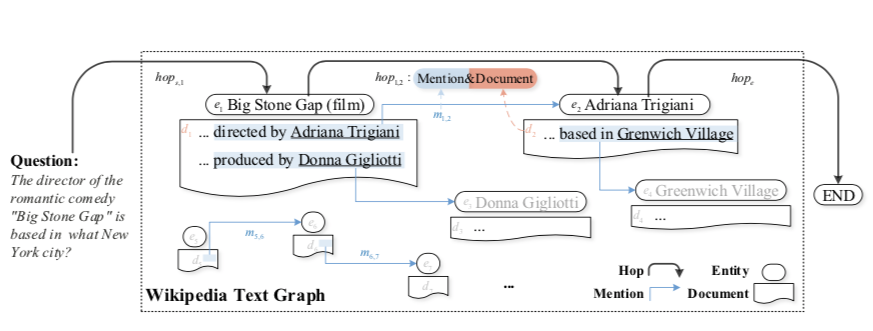
HopRetriever:Retrieve Hops over Wikipedia to Answer Complex Questions(AAAI2020)
HopRetriever:Retrieve Hops over Wikipedia to Answer Complex Questions(AAAI2020)https://arxiv.org/abs/2012.15534
摘要
大型文本语料库中收集支持证据对于开放领域问答(QA)是一个巨大的挑战。
本文方法:
将hop定义为超链接和出站链接文档的组合
超链接编码成提及嵌入,相当于在上下文被提及的结构知识,表示出站链接实体建模。
出站链接文档编码成文档嵌入,相当于非结构化的知识。
使用Hotpot数据集,该数据集文章我在这里写过[TODO]
me:想要更好的检索,光用匹配一种检索方式不好,可以结合相关语义信息同时进行检索,会更准确。
那么难点就是如何找到相关部分提取语义信息用于检索。
介绍多跳问答任务需要从多个支持文档中搜集分散的证据,来提取答案。最近主流方法是将多跳证据收集视为迭代文档检索问题。
在开放域下,多跳QA的一个关键部分是从整个知识源中检索证据路径,分解成几个单步文档检索。
另一part是在基于知识库KB下,并尝试像虚拟结构化知识库(KB)那样遍历文本数据,专注于提到 ...
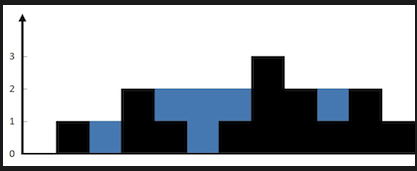
LeetCode面试17_21直方图装水
直方图装水
思路
如果用程序来描述直方图高度的话不好描述
问题可以想成,每个数组下标下当前列中可以放多少水
每个横坐标下的最大存水量=min(当前的左边最大高度,当前右边的最大高度)
如果我当前高度比左右两边最大值都大,那么我横坐标上肯定没水
当前i水量=min{max左,max右} - arr[i] > 0 ? 当前i水量 : 0
总的存水量=每个横坐标上能存水量的加和
第0个和最后一个就肯定无水
优化普通方法,像上面的思路,到每个i位置都会向左向右遍历一个最大值,复杂度有点高。
技巧:预处理数组,为的是不用每次都遍历去求最大最小值,用的时候直接取
比如原始数组为[3,1,6,7,2,4,3]
从左到右,从右到左,正反遍历此数组,如果当前数比之前的数小就取之前的值作为当前值,当前数比钱已给数大就还选本来的值。
从左到右遍历后为[3,3,6,7,7,7,7]
从右到左遍历后为[7,7,7,7,4,4,3]
以空间换时间,还不是最优
技巧二:(最优)
声明两个指针,L和R。因为数组两端点不会有水L=1,R=N-2。
再声明两变量,LMax:L扫过的部分的最大值,RMax:R扫过的 ...

阅读理解数据集综述
阅读理解数据集综述1. 阅读理解任务定义阅读理解任务可以被当作是一个有监督学习问题,具体来说,该任务可 以详细描述为:给定一个数据集 T,其中 T 的每一个样本都以下的三元组来表示:
T = {(P_i, Q_i, A_i)}_{i=1}^n其中,$P_i$ 代表第 $i$ 个样本中的文章片段,$Q_i$ 代表第 $i$ 个样本中的问题,$A_i$ 代表第 $i$ 个样本中根据文章和问题所回答的答案。阅读理解的任务是通过学习得到一个预测函数 $f$ ,使得我们能够通过给定的 $P_i$ 与 $Q_i$ 来预测出 $A_i$ :
f(P_i, Q_i) \to A_i通俗来讲,阅读理解任务就是通过给定一个文章片段,给定一个问题,要求计算机能够通过文章片段与问题来获得答案。
2. 阅读理解任务类型阅读理解有多种类型,其划分的一个主要依据是根据答案的类型进行划分,这么区分的主要原因在于答案的不同使得模型输出层,损失函数,评估方式等发生很大变化。
目前来看,阅读理解任务根据具体答案形式的不同可以大致区分为以下四类:
填空式阅读理解。
填空式阅读理解有一个很明显的特点:答案往往是一 ...

天池赛题:天猫重复购学习笔记(我的EDA模板)
highlight_shrink:天池赛题:天猫重复购学习笔记(我的EDA模板)字段解释都在:这里代码在GitHub:这里
复购率 = 重复购买用户数量/用户样本数量
复购率 = 重复购买行为次数(或 交易次数)/用户样本数量
[TOC]
EDA步骤1.看数据类型、数量、样例无疑是一些pd.readcsv()和data.info()、data.head()。大致看一看查看是否有单一值变量
12345#查看训练集测试集中特征属性只有一值的特征train_one_value = [col for col in train.columns if train[col].nunique() <= 1]test_one_value = [col for col in test.columns if test[col].nunique() <= 1]print('one value featrues in train:',train_one_value)print('one value featrues in test: ',test_one_ ...
High-Order Information Matters Learning Relation and Topology for Occluded Person Re-Identification(CVPR2020)(泛读)
High-Order Information Matters: Learning Relation and Topology for Occluded Person Re-Identification(CVPR2020)(泛读)https://arxiv.org/abs/2003.08177
解决方案主要解决遮蔽现象。整体思路可以再各种跟验证相关的任务中去套用。
针对遮蔽数据集Occluded-DukeMTMC提出三阶段模型:
关键点局部特征提取 (关键点数据集或者关键点识别模型)
图卷积融合关键点特征
基于图匹配的方式来计算相似度并训练模型完成特征提取,重点解决遮蔽问题。
关键点可以学习人体走路运动的先验知识。
1、关键点局部特征提取关键点数据集或者关键点识别模型
2、图卷积融合贯机电特征传统算法是点与点进行匹配,但当两个图像遮蔽位置不一致时,就没法进行对比关键点。图卷积就会好好利用未被遮挡的区域。
3、基于图匹配的方式来计算相似度并训练模型匹配图像中哪些能用哪些不能用,能用的该怎么用,不能用的该怎么减少。计算U匹配矩阵(13x13)关键点。
第一阶段S(关键点局部特征提取)根 ...




