主动学习Active Learning调研
主动学习调研
主动学习概念与目标
主动学习是一种通过主动选择最有价值的样本进行标注的机器学习或人工智能方法。
其目的是使用尽可能少的、高质量的样本标注使模型达到尽可能好的性能,即最大限度地减少 oracle 和主动学习者之间的相互作用。也就是说,主动学习方法能够提高样本及标注的增益,在有限标注预算的前提下,最大化模型的性能,是一种从样本的角度,提高数据效率的方案,因而被应用在标注成本高、标注难度大等任务中。
下图是经典的基于池的主动学习框架。在每次的主动学习循环中,根据任务模型和无标签数据的信息,查询策略选择最有价值的样本交给专家进行标注并将其加入到有标签数据集中继续对任务模型进行训练。主动学习方法是一个迭代式的交互训练过程,主要由五个核心部分组成,包括:未标注样本池(unlabeled pool,记为U)、筛选策略(select queries,记为Q)、标注者(human annotator,记为S),标注数据集(labeled training set,记为L),目标模型(machine learning model,记为G)。
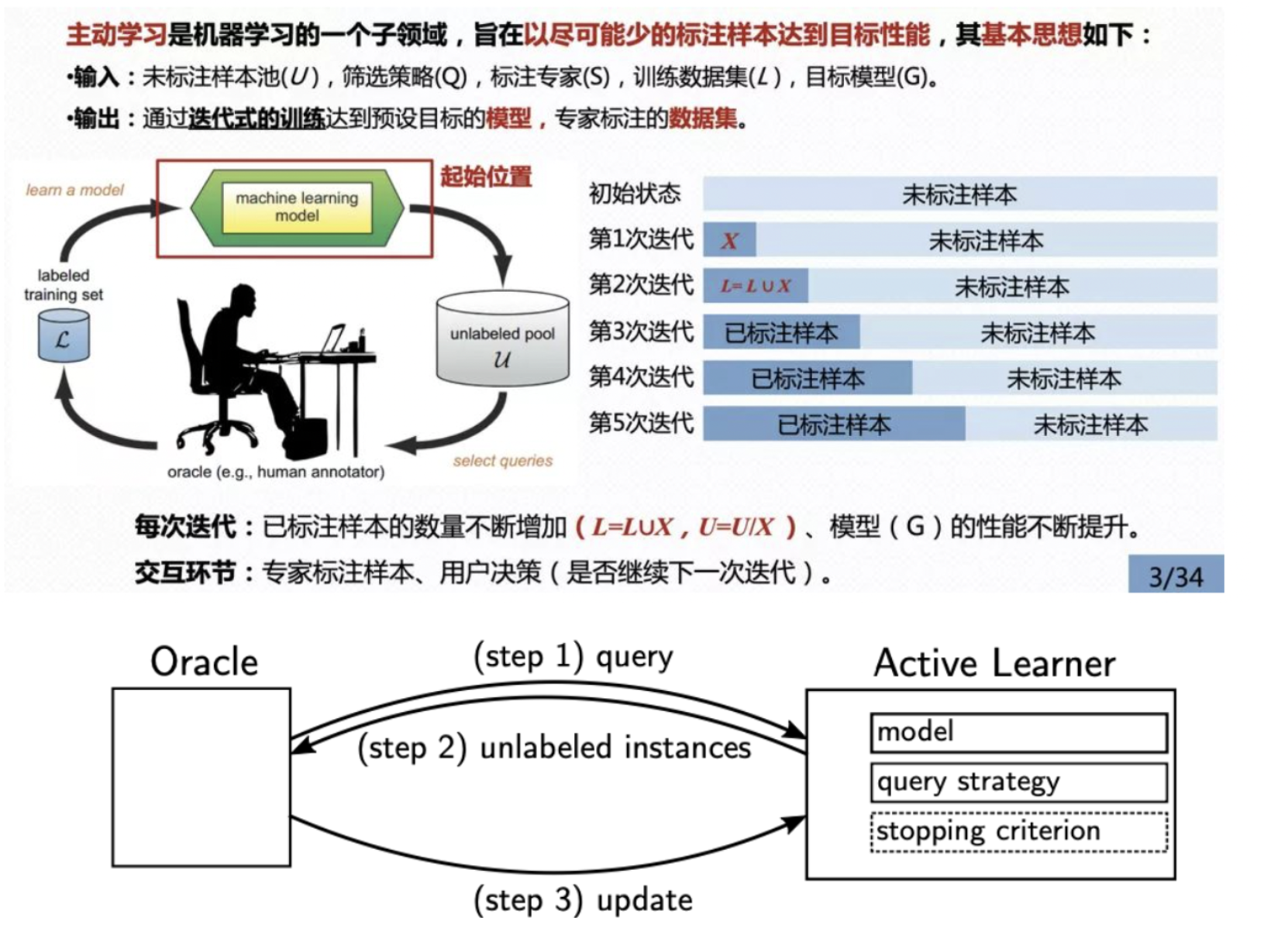
oracle 从主动学习者那里请求未标记的实例(查询,step 1),然后由主动学习者(根据选定的查询策略)选择这些实例并传递给oracle(step 2)。随后,这些实例被 oracle 标记并返回给主动学习者(更新,step 3)。在每个更新步骤之后,主动学习者的模型被重新训练,这使得这个操作至少和基础模型的训练一样昂贵。这个过程不断重复,直到达到停止标准(例如,最大的迭代次数或分类精度变化的最小阈值)。
AL模型分类
根据应用场景,主动学习的方法可以被分为 membership query synthesis, stream-based and pool-based 三种类型。
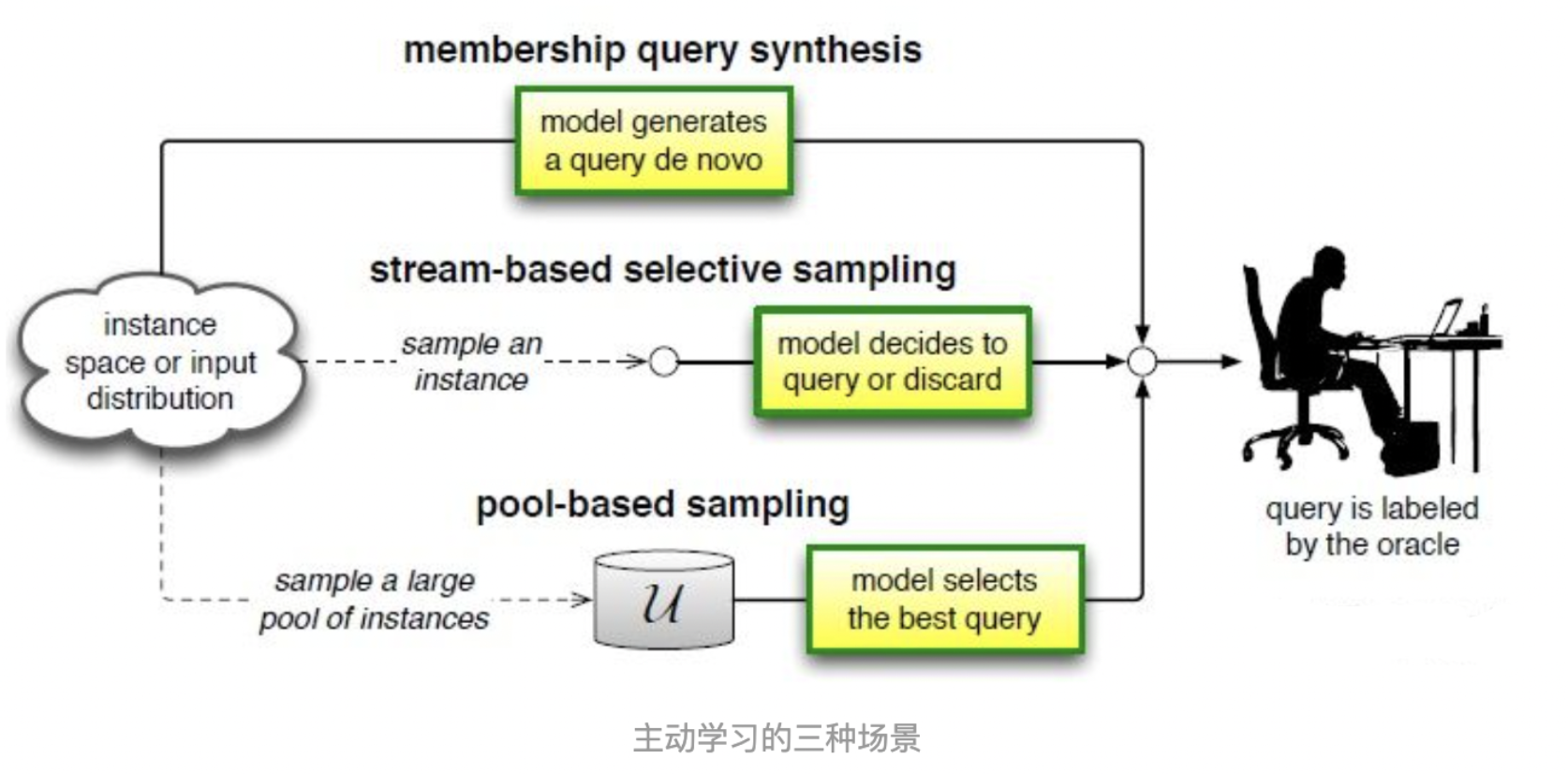
- pool-based : 每次给算法输入一个批量的无标签样本,然后算法根据策略挑选出一个或几个样本交给 oracle 进行标注。这样的场景在生活中更容易出现,算法也可以根据这一批量样本进行互相比较和综合考虑。是最常见的场景,并且由于深度学习基于 batch 训练的机制,使得 pool-based 的方法更容易与其契合。
- membership query synthesis : 算法可能挑选整个无标签数据中的任何一个交给 oracle 标注,典型的假设是包括算法自己生成的数据。但是有时候,算法生成的数据无法被 oracle 识别,例如生成的手写字图像太奇怪,oracle 也不能识别它属 于 0~9?或者生成的音频数据不存在语义信息,让 oracle 也无法识别。
- stream-based 的场景中,每次只给算法输入一个无标签样本,由算法决定到底是交给 oracle 标注还是直接拒绝。有点类似流水线上的次品检测员,过来一个产品就需要立刻判断是否为次品,而不能在开始就根据这一批产品的综合情况来考量。
基本查询策略
在主动学习框架中,最重要的就是如何设计一个查询策略来判断样本的价值,即是否值得被 oracle 标注。
而样本的价值并不是一成不变的,它不仅与样本自身有关,还和任务和模型等因素有关。
不确定性采样(Uncertainty Sampling):最简单直接也最常用的策略。算法只需要查询最不确定的样本给 oracle 标注,通常情况下,模型通过学习不确定性强的样本的标签能够迅速提升自己的性能。例如,学生在刷题的时候,只做自己爱出错的题肯定比随机选一些题来做提升得快。对于一些能预测概率的模型,例如神经网络,可以直接利用概率来表示不确定性,或概率值排名第一和第二的差值,熵值等等。
多样性采样(Diversity Sampling):从数据的分布考虑的常用策略。算法根据数据分布确保查询的样本能够覆盖整个数据分布以保证标注数据的多样性。例如,老师在出考试题的时候,会尽可能得出一些有代表性的题,同时尽可能保证每个章节都覆盖到,这样才能保证题目的多样性全面地考察学生的综合水平。
在多样性采用的方法中,也主要分为以下几种方式:
- 基于模型的离群值:采用使模型低激活的离群样本,因为现有数据缺少这些信息;
- 代表性采样:选择一些最有代表性的样本,例如采用聚类等簇的方法获得代表性样本和根据不同域的差异找到代表性样本;
- 真实场景多样性:根据真实场景的多样性和样本分布,公平地采样。
预期模型改变(Expected Model Change):EMC 通常选择对当前模型改变最大、影响最大的样本给 oracle 标注,一般来说,需要根据样本的标签才能反向传播计算模型的改变量或梯度等。在实际应用中,为了弱化需要标签这个前提,一般根据模型的预测结果作为伪标签然后再计算预期模型改变。当然,这种做法存在一定的问题,伪标签和真实标签并不总是一致的,他与模型的预测性能有关。
委员会查询(Query-By-Committee):QBC 是利用多个模型组成的委员会对候选的数据进行投票,即分别作出决策,最终他们选择最有分歧的样本作为最有信息的数据给 oracle 标注。
此外,有些研究者将多种查询策略结合起来使用混合策略进行查询,例如即考虑不确定性又考虑多样性的。还有一些其他的查询策略,例如预期误差减少、方差减少、密度加权法等。
应用场景
由于主动学习解决的是如何从无标签数据中选择价值高的样本进行标注,所以在数据标签难以获得、标注成本大的场景和实际问题中被广泛应用。
互联网大数据相关的应用:在互联网的大数据场景中,无标签的数据不计其数,但是又不可能把所有的数据都打上标签。在有限的资金和时间下,最有效的方法就是利用主动学习挑选最有价值的样本交给人去打标签。
数据量本身就少的话,就没必要应用主动学习了,因为在有限的样本下,即使都标注都很难达到一个满意的性能,更别说去做选择了。
真正有需求的场景是:
- 有大量的无标签数据,需要从中选择有价值的进行标注
- 真正实现基本性能,能够落地部署后,仍需要长期在使用过程中收集数据,进行标注,但是由于这个过程是一直持续下去,长久的工作,所以对于这样大量的无标签数据也需要进行主动学习选择标注。
- 有监督+无监督结合,半监督:既不可能完全放弃标签,也不可能放弃无标注数据,而主动学习恰恰能够提供一个较合理的权宜之计,既要标注有价值的数据,又不需要全部标注,选择性地标注。
实际应用可能存在的问题
标注成本不确定:AL一大优势就是节省标注者的标注成本,但实车数据常是简短的指令性数据可能标注成本不高,应用AL可能不划算。
性能不稳定:制约主动学习最大的问题就是性能不稳定。主动学习是根据自己指定的选择策略从样本中挑选,那么这个过程中策略和数据样本就是影响性能的两个很重要的因素。
对于非常冗余的数据集,主动学习往往会比随机采样效果要好,但是对于样本数据非常多样,冗余性较低的数据集,主动学习有的时候会存在比随机采样还差的效果。
数据样本的分布还影响不同主动学习的方法,比如基于不确定性的方法和基于多样性的方法,在不同数据集上的效果并不一致,这种性能的不稳定是制约人们应用主动学习的一个重要因素。
在实际应用中,需要先根据主动学习进行数据选择和标注,如果此时的策略还不如随机采样,人们并不能及时改变或者止损,因为数据已经被标注了,沉没成本已经产生了。而优化网络结构和性能的这些方法就不存在这个问题,人们可以一直尝试不同的方法和技巧使得性能达到最好,修改和尝试的损失很小。
要求苛刻:设计好的策略拿来直接应用就必须要 work 才行,如果不 work,那些被选择的样本还是被标注了,还是损失时间和金钱。苛刻的要求和不稳定的性能导致人们还不如省下这个精力,直接采用随机的标注方式。
脏数据的挑战:现在几乎所有的论文都在公开的数据集、现成的数据集上进行测试和研究。而这些数据集其实已经被选择和筛选过了,去除了极端的离群值,甚至会考虑到样本平衡,人为的给少样本的类别多标注一些,多样本的类别少标注一些。而实际应用中,数据的状况和这种理想数据集相差甚远。主动学习常用不确定性的选择策略,不难想象,噪声较大的样本甚至离群值总会被选择并标注,这种样本可能不仅不会提升模型的性能,甚至还会使性能变差。
实际中还存在 OOD(out of distribution)的问题,例如想训练一个猫狗分类器,直接从网络中按关键字搜索猫狗收集大量图片,里边可能存在一些老虎、狮子、狼等不在猫狗类别的无关样本,但是他们的不确定性是非常高的,被选中的话,并不会提升模型的性能。
难以迁移 :主动学习是一种数据选择策略,那么实际应用中必然需求更通用、泛化性更好的主动学习策略。由于不同任务的数据分布特点可能不一样,不同任务的难易不一样,无法保证主动学习的策略能够在不同数据不同任务中通用,往往需要针对固定的任务设计一个主动学习策略。而目前的主动学习策略难以在不同域、不同任务之间进行迁移,比如设计了一个猫狗分类任务的主动学习策略,基于不确定性或多样性,达到了较好的性能,现在需要做一个新的鸡鸭分类的任务,那么是否还需要重新设计一个策略?
交互:数据选择策略与标注过程联系紧密,理想的流程是,有一个整合的软件能够提供主动数据选择,然后提供交互界面进行标注,这就是将主动学习流程与标注软件结合。仅有高效的主动学习策略,而不方便标注交互,也会造成额外的精力浪费。比如,人们标注的时候,模型既不能训练,主动学习也不进行其他操作,是个串行的过程,需求等待人工标注结束后,才能进行接下来的训练。标注和模型互相等待对方的操作这样的流程就不那么方便和高效。
Question
- 主动学习为什么有时还能提升分类模型的准确率?
《主动学习算法研究进展》给出的解释是:标注样本可能存在低质量的样本,会降低模型的鲁棒性(模型过渡拟合噪声点)。如何高效地筛选出具有高分类贡献度的无类标样例进行标注,并补充到已有训练集中逐步提高分类器精度与鲁棒性是主动学习亟待解决的关键问题。
- 不确定性策略具体怎么实现?
重点关注每个样本预测结果的最大概率值:p_pred_max。初步认为 p_pred_max>0.5 的情况表示当前模型对该样本有个确定的分类结果(此处分类结果的正确与否不重要);反之,当前模型对该样本的判断结果模棱两可,标记为hard sample;比如:模型进行第一次预测,得到10个概率值,取其最大的概率 p_pred_max;对P(real lable) < p_threshold(此处的10分类任务取p_threshold=0.5)的样本进行排序,取前N个样本加入集合train_samples中;
参考文献
《A Survey on Active Deep Learning- From Model-Driven to Data-Driven》
《A Survey of Active Learning For Text Classification Using Deep Neural Networks》
《Variational Adversarial Active Learning》
《Task-Aware Variational Adversarial Active Learning》
 wechat
wechat alipay
alipay


