Prompt tuning 调研
[TOC]
Prompt tuning调研
基本介绍
在海量数据上预训练 PLM,将其调整为下游任务,这已经成为NLP的典型范式(Fine tuning/微调/精调)。传统上,它通过特定任务的监督,优化PLM的所有参数。
然而,随着 PLM 参数的持续增长,全参数微调对于典型的范式和模型存储都变得难以承受。为了弥补这一缺陷,人们提出了许多参数高效的 tuning 方法,这些方法只调整几个参数,而保持大部分PLM参数的冻结。
在这些具有参数效率的微调变体中,Prompt Tuning 得到了广泛的关注,这是由 GPT-3 激发的。 它通过在输入文本之前给每个任务预留一个文本提示,并让 PLM 直接生成答案,从而展示了显著的【少样本】与【跨任务/domain迁移】性能。
Prompt 的突然兴起,主要是因为学者们把任务扩展到了NLU,之前大部分是做生成和信息抽取,而在统一了方法之后,现在可以做分类任务和匹配任务了,同时在少样本甚至全样本,能追上微调的效果。
Prompt的思想:设计不同的输入形态,激发语言模型的潜力,得到任务相关的输出,从而避免微调模式带来的灾难性遗忘问题。引用刘鹏飞博士放在博客里的图:
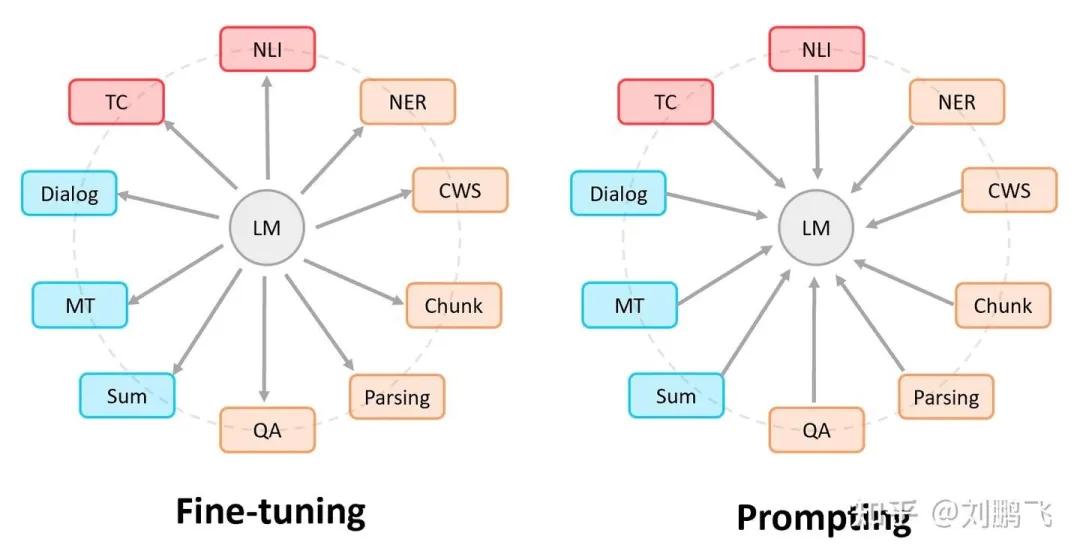
Prompt兴起之前做NLP任务的大致流程,即”Pre-train, Fine-tune”,如上图,可看做是由预训练模型(PLM)迁就下游任务。Prompt的模式大致可以归纳成”Pre-train, Prompt, and Predict”。在该模式中,可看成由下游任务迁就 PLM,下游任务被重新调整成类似预训练任务的形式。例如,MLM(Masked Language Model),在文本情感分类任务中,对于”I love this movie”这句输入,可以在后面加上Prompt:”the movie is _“,组成如下这样一句话:
I love this movie, the movie is _
然后让 PLM 用表示情感的答案(例如”great”、”terrible”等)做完形填空,最后再将该答案转换为情感分类的标签。这样一来,我们就可以通过构造合适的【模板】,控制模型的输出空间,从而训练 PLM 来解决各种各样的下游任务。
Prompt 更严谨的定义如下:
Prompt is the technique of making better use of the knowledge from the pre-trained model by adding additional texts to the input.
Prompt 是一种为了更好的使用预训练语言模型的知识,采用在输入段添加额外的文本的技术。
- 目的:更好挖掘预训练语言模型的能力
- 手段:在输入端添加文本,即重新定义任务(task reformulation)
Prompt 优势是什么
从四个角度进行分析:Level 1. Prompt Learning 角度;Level 2. Prompt Learning 和 Fine-tuning 的区别;Level 3. 现代 NLP 历史;Level 4. 超越NLP
Level 1. Prompt tuning 使得所有的NLP任务成为一个语言模型的问题
Prompt tuning 可以将所有的任务归化为预训练语言模型的任务
避免了预训练和Fine tuning 之间的gap,几乎所有 NLP 任务都可以直接使用,不需要训练数据。
更少的调整参数、提升参数效率
在少样本的数据集上,能取得超过微调的效果,未来也有希望在全方位超过微调。
使得所有的任务在方法上变得一致,在多任务、多领域场景下使得迁移学习变得更加自然且容易,如下图:
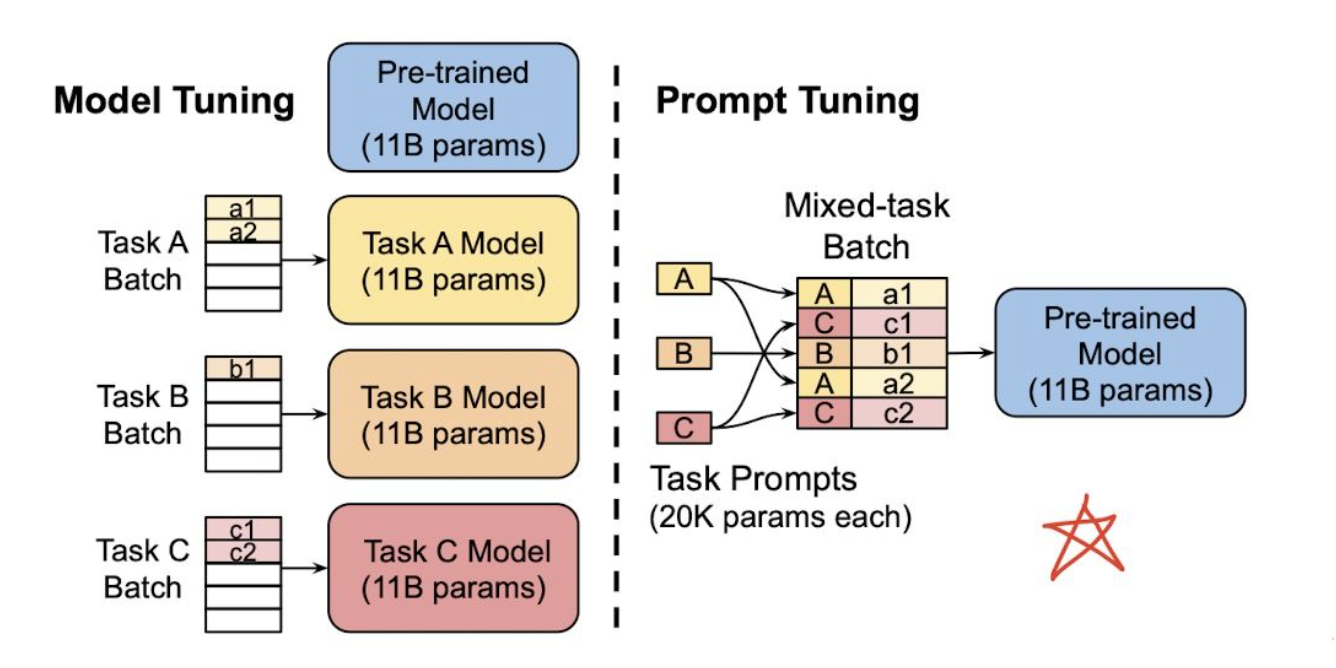
左边是传统的 Model Tuning(Fine tuning) 的范式:对于不同的任务,都需要将整个预训练语言模型进行精调,每个任务都有自己的一整套参数。右边是Prompt Tuning,对于不同的任务,仅需要插入不同的prompt 参数,每个任务都单独训练Prompt 参s数,不训练预训练语言模型,这样子可以大大缩短训练时间,也极大的提升了模型的使用率。
Level 2. Prompt tuning 和 Fine tuning 的范式区别
- Fine tuning 是使得预训练语言模型适配下游任务
- Prompting 是将下游任务进行任务重定义,使得其利用预训练语言模型的能力,即适配语言模型
Level 3. 现代 NLP 第四范式
Prompting 方法是现在NLP的第四范式。其中现在NLP的发展史包含
- Feature Engineering:即使用文本特征,例如词性,长度等,在使用机器学习的方法进行模型训练。(无预训练语言模型)
- Architecture Engineering:在W2V基础上,利用深度模型,加上固定的embedding。(有固定预训练embedding,但与下游任务无直接关系)
- Objective Engineering:在bert 的基础上,使用动态的embedding,在加上Fine tuning。(有预训练语言模型,但与下游任务有gap)
- Prompt Engineering:直接利用与训练语言模型辅以特定的prompt。(有预训练语言模型,但与下游任务无gap)
我们可以发现,在四个范式中,预训练语言模型,和下游任务之间的距离,变得越来越近,直到最后Prompt Learning是直接完全利用LM的能力。

Level 4. 超越NLP的角度
Prompt 可以作为连接多模态的一个契机,例如 CLIP 模型,连接了文本和图片。相信在未来,可以连接声音和视频,这是一个广大的待探索的领域。

Prompt 的工作流
Prompt 的工作流包含以下4部分:
- Prompt 模版(Template)的构造
- Prompt 答案空间映射(Verbalizer)的构造
- 文本代入template,并且使用预训练语言模型进行预测
- 将预测的结果映射回label。
具体的步骤如下图,接下来将一步步进行拆解分析。
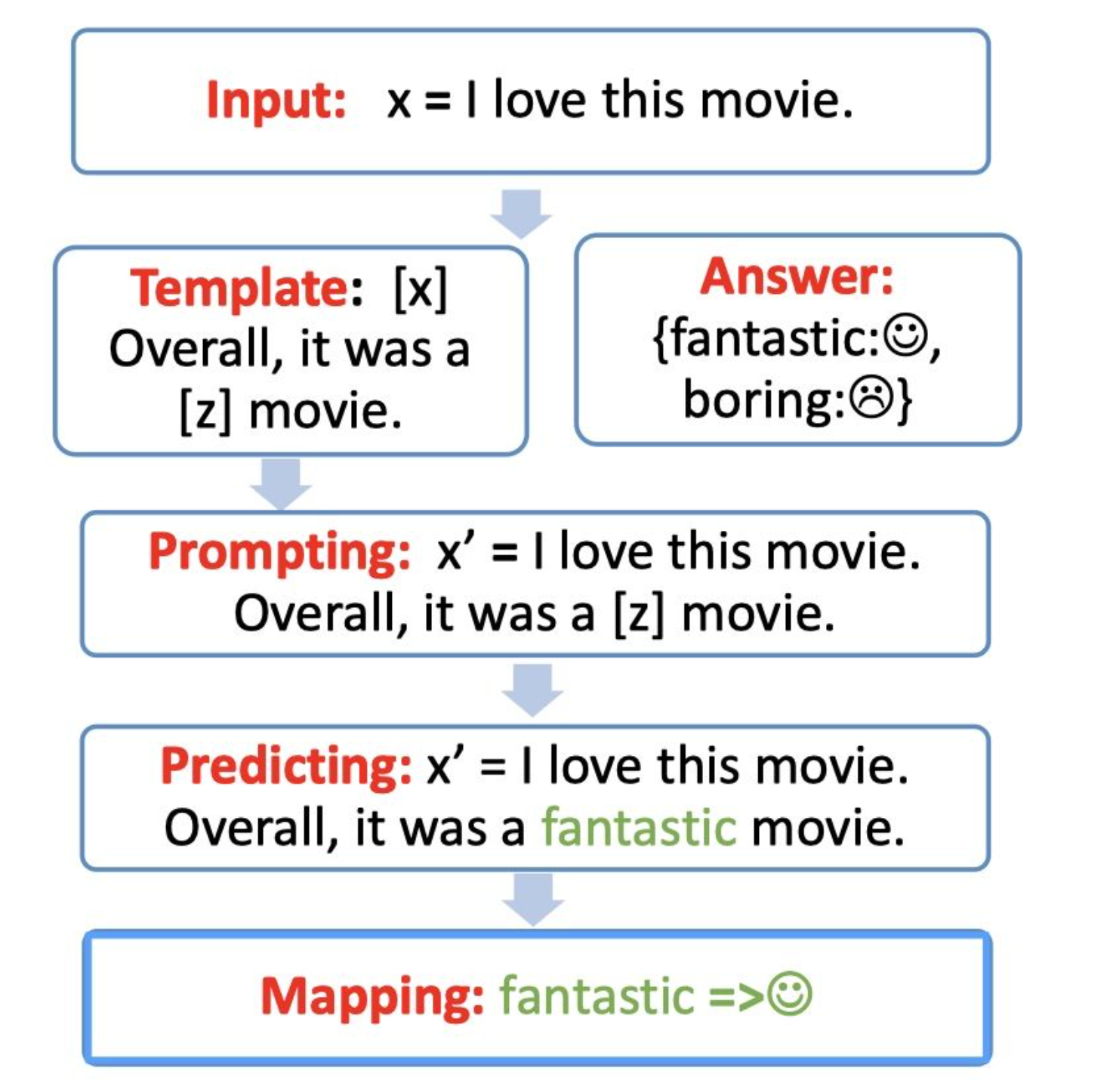
Step 1: prompt construction【Template】
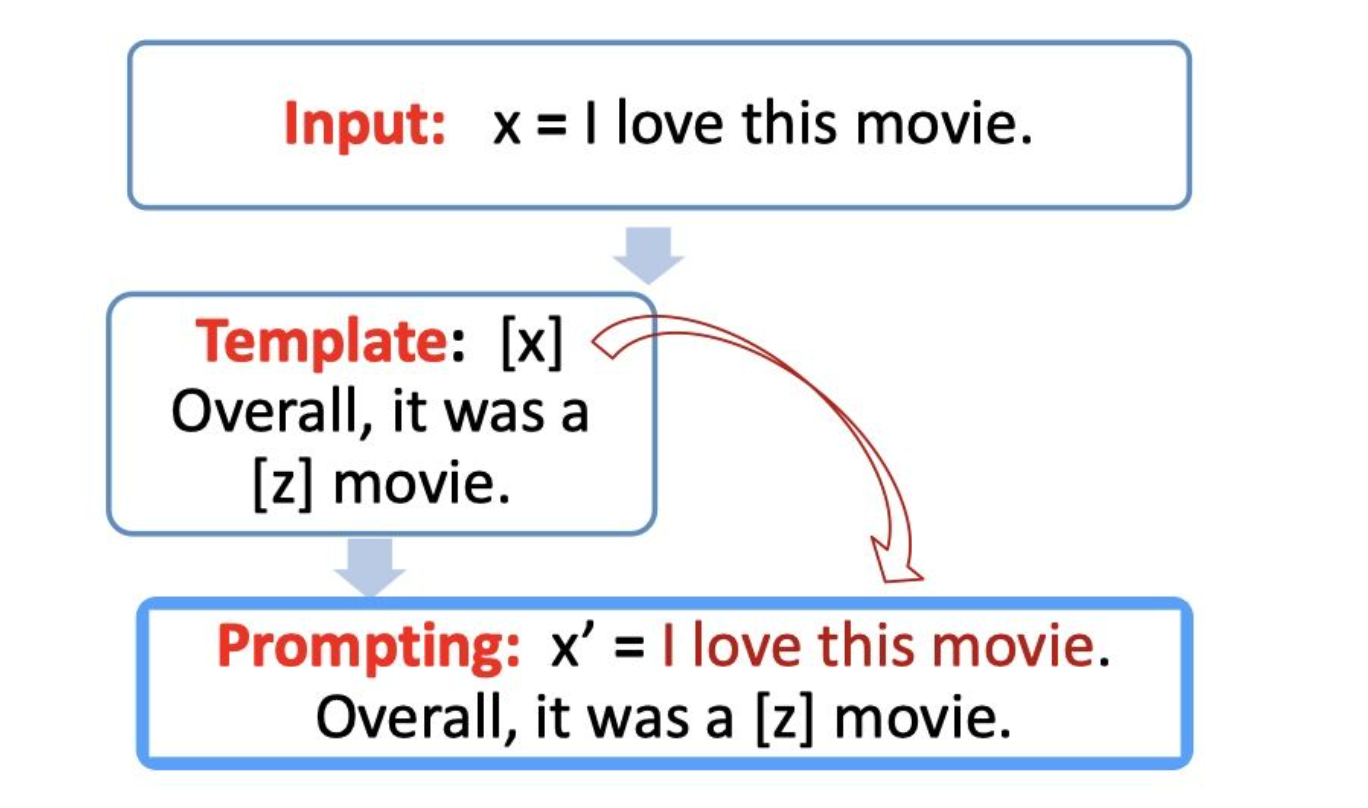
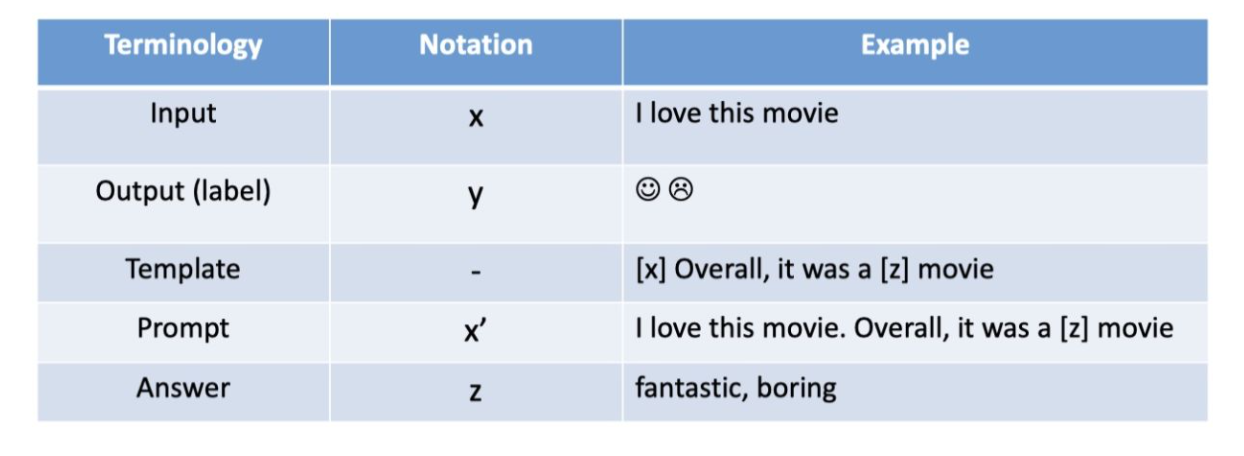
首先我们需要构建一个模版Template,模版的作用是将输入和输出进行重新构造,变成一个新的带有mask slots的文本,具体如下:
- 定义一个模版,包含了2处代填入的slots:[x] 和 [z]
- 将 [x] 用输入文本代入
例如:
- 输入:x = 我喜欢这个电影。
- 模版:[x] 总而言之,它是一个 [z] 电影。
- 代入(Prompt):我喜欢这个电影。总而言之,它是一个[z]电影。
以上介绍的为离散的Prompt(手工构造Prompt),这浪费人力并且往往是次优的性能。目前普遍采用的是连续的Prompt 将Prompt 向量化进行调优,在经典工作中将会涉及此类工作。
Step 2: answer construction【Verbalizer】
对于我们构造的prompt,我们需要知道我们的预测词和我们的label 之间的关系,并且我们也不可能让 z 是任意词,这边我们就需要一个映射函数(mapping function)将输出的词与label进行映射。
例如,输出的 label 有两个,一个【是】 ,一个【不是】 ,我们可以限定,【是】这个预测词是fantastic 对应 ,【不是】则对应 boring 。
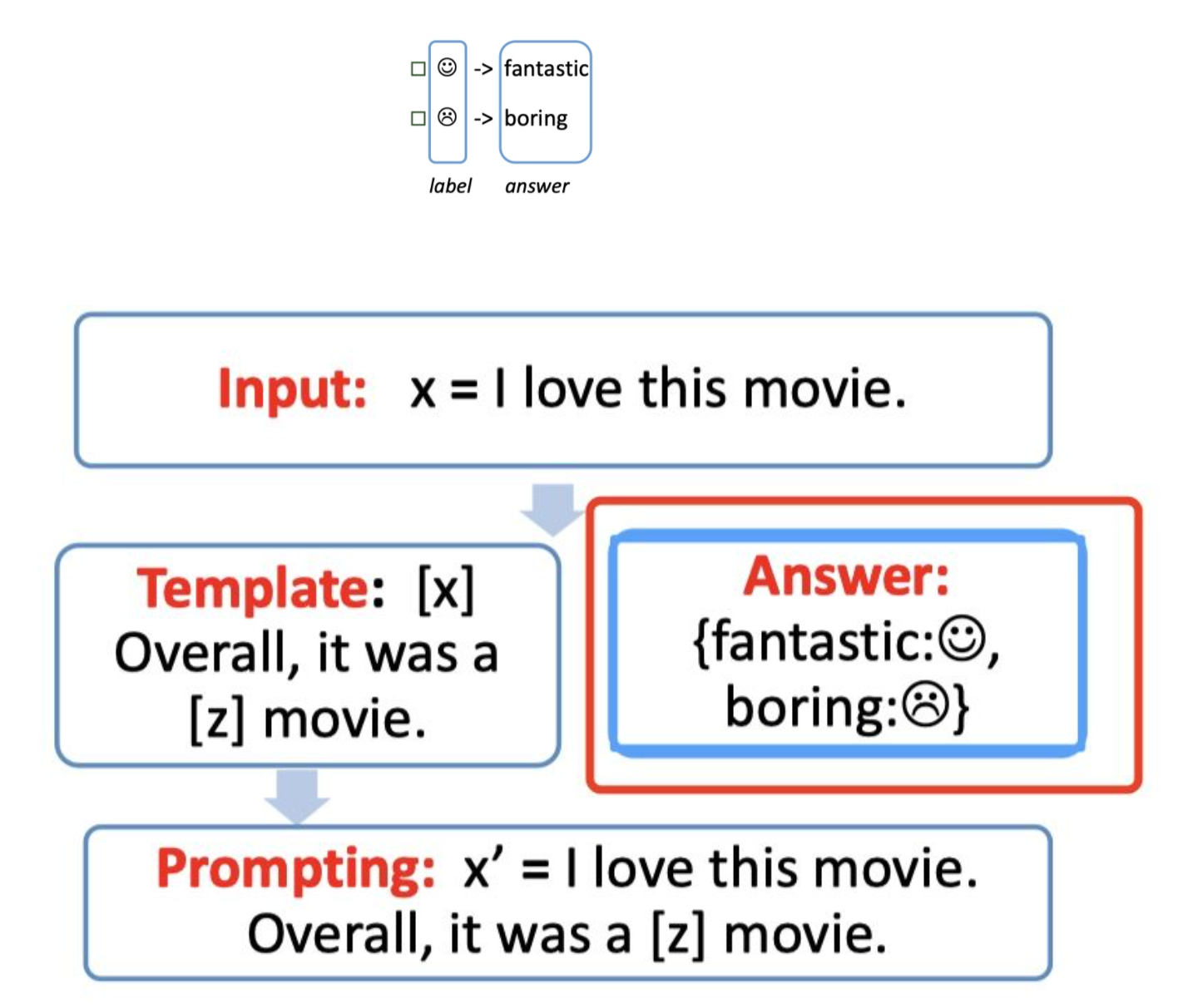
Step 3: answer prediction【Prediction】
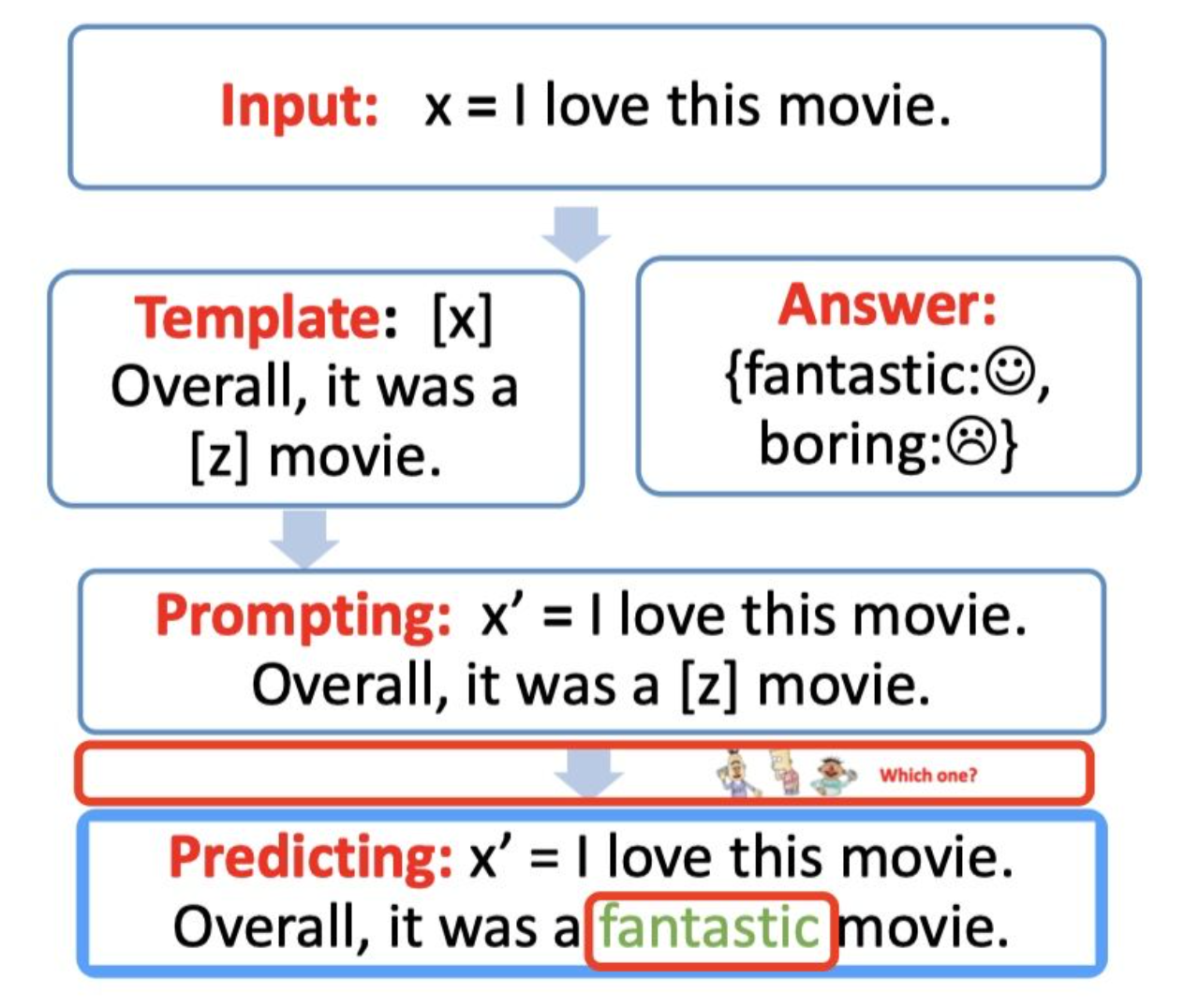
选择合适的预训练语言模型,然后进行mask slots [z] 的预测。例如下图,得到了结果 fantastic, 我们需要将其代入 [z] 中。
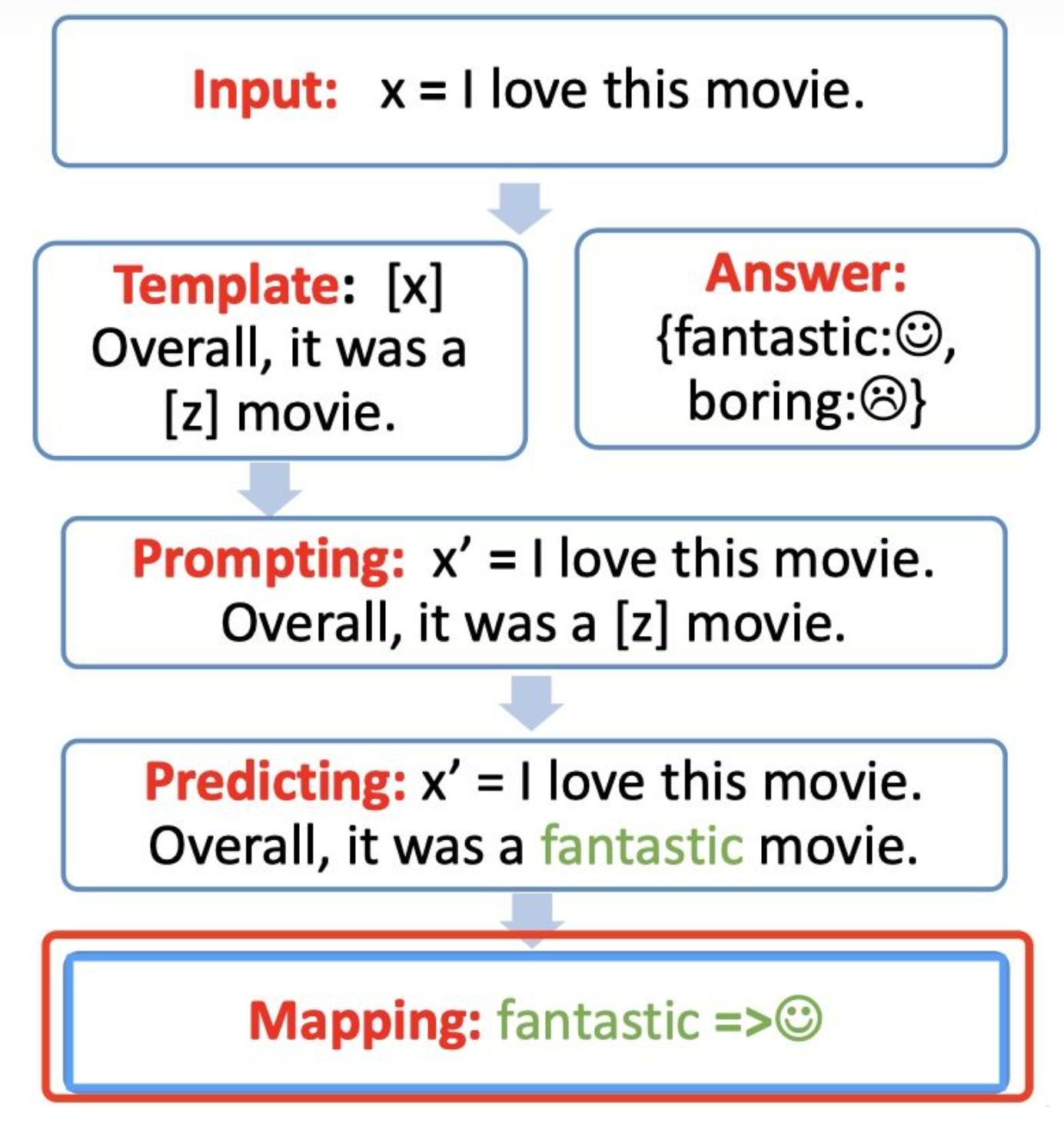
Step 4: answer-label mapping【Mapping】
第四步骤,对于得到的 answer,我们需要使用 Verbalizer 将其映射回原本的label。
例如:fantastic 映射回 label:
总结
经典工作与方法(持续更新…)
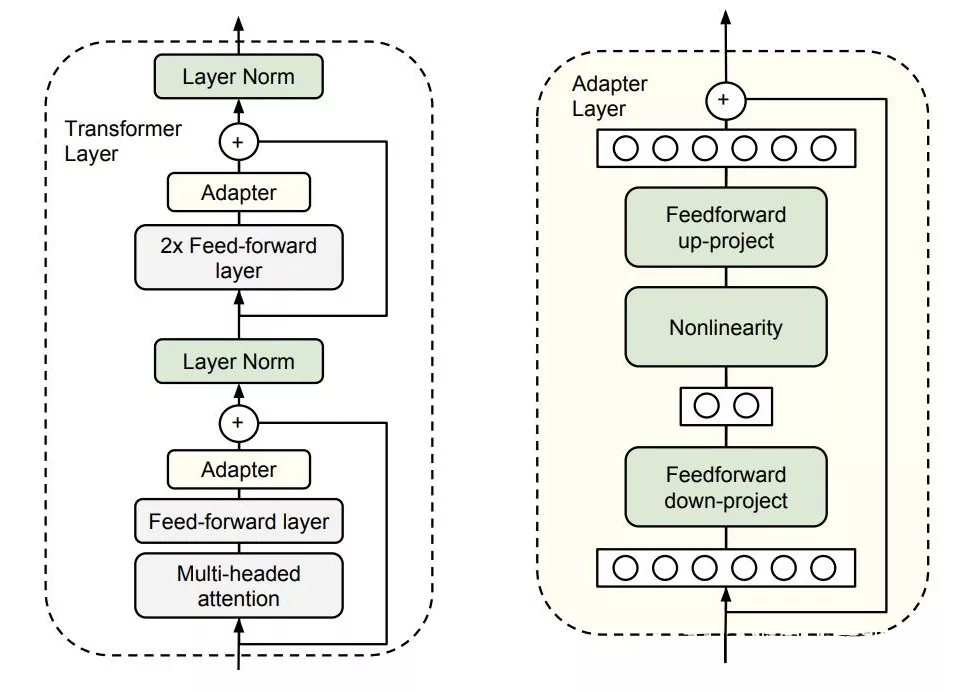
Parameter-Efficient Transfer Learning for NLP (ICML 2019) -2019.2.2
- motivation: 将 adapter 加入到 transformer 中,在针对某个下游任务微调时,改变的仅仅是 adapter 的参数。
- method:
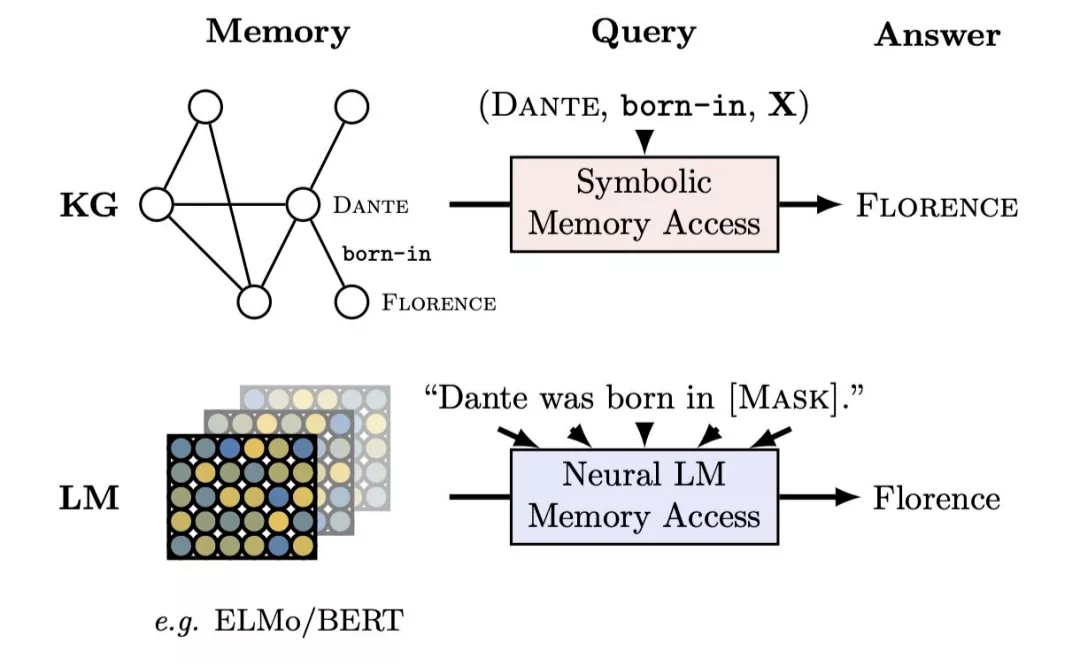
Language Models as Knowledge Bases? (ACL 2019) -2019.9.3
motivation : 语言模型可以作为关系知识的潜在表示形式,对预先训练的现成语言模型(例如 ELMo 和 BERT)中已经存在的关系知识提取。在 kownledge-base complete 任务上利用语言模型预测的分数,完成知识提取,相比 elmo 等模型表现要好。需要人工标注 query 也就是模板。
method:
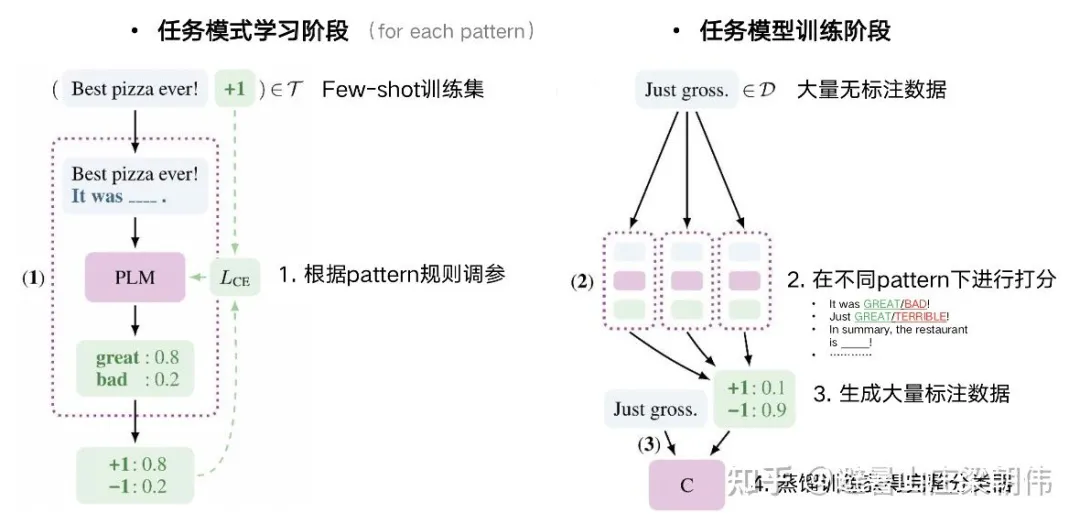
Exploiting Cloze Questions for Few Shot Text Classification and Natural Language Inference (EACL 2021) - 2020.1.21
motivation: 如何用较小的预训练模型充分发挥预训练模型作为语言模型的作用,做 few shot learning,做法是分类转化为完形填空
method:
It’s Not Just Size That Matters: Small Language Models Are Also Few-Shot Learners (NAACL 2021) -2020.9.15
- motivation: 解决 label mask 预测多 token 问题。
- method: 选择分数最高的一个 token 为基准计算,替代多个 token 完形填空的分数计算
Parameter-Efficient Transfer Learning with Diff Pruning -2020.12.14
- motivation : adapter 的延续,将原来的参数上增加新参数(L0 正则约束稀疏性)
Prefix-Tuning: Optimizing Continuous Prompts for Generation (ACL 2021) -2021.1.1
motivation : 提出了 Prefix-Tuning,一种轻量级 fintune 替代方法,用于对 NLG 任务进行微调,在使语言模型参数冻结的同时,去优化一个参数量少的 continuous task-specific vector(称为 prefix),用词表中的词初始化较好,并且和类别相关。在大多数任务上比 finetune 好。
method: 根据不同的模型结构定义了不同的 Prompt 拼接方式,在 GPT 类的自回归模型上采用 [PREFIX, x, y],在 T5 类的 encoder-decoder 模型上采用 [PREFIX, x, PREFIX’, y]。
把预训练大模型 freeze 住,因为大模型参数量大,精调起来效率低,毕竟 prompt 的出现就是要解决大模型少样本的适配。
直接优化 Prompt 参数不太稳定,加了个更大的 MLP,训练完只保存 MLP 变换后的参数就行了。
- 实验证实只加到 embedding 上的效果不太好,因此作者在每层都加了 prompt 的参数,改动较大。
PADA: A Prompt-based Autoregressive Approach for Adaptation to Unseen Domains -2021.2.24
- motivation: 利用 t5 的 embedding,选择领域的代表关键词(利用互信息),然后进行领域迁移(挖掘领域共现关键)
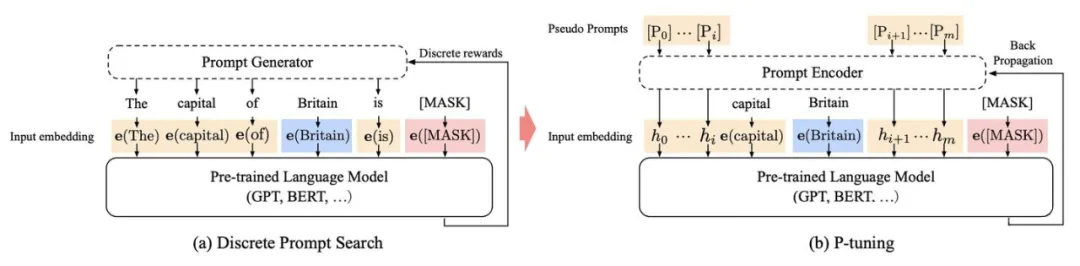
GPT Understands, Too -2021.3.18
motivation: P-tuning 重新审视了关于模版的定义,放弃了“模版由自然语言构成”这一常规要求,从而将模版的构建转化为连续参数优化问题,虽然简单,但却有效。
KnowPrompt: Knowledge-aware Prompt-tuning with Synergistic Optimization for Relation Extraction -2021.4.15
motivation: 融入外部知识(实体,关系)的 embedding 当做参数,将关系分类设置成模板,采用 MASK 的方式训练,同时增 KE 的 loss 。
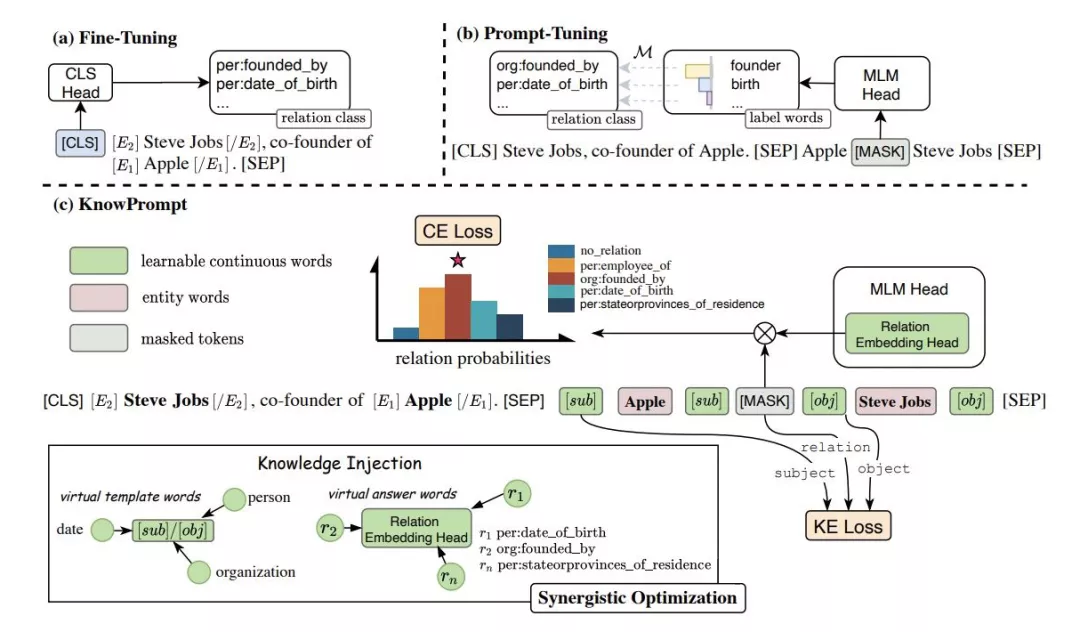
The Power of Scale for Parameter-Efficient Prompt Tuning (2021.4.18)
motivation: 对 prefix tuning 的进一步简化 : prefix tuning 会训练所有与 prefix prompt 相关的层。而这篇文章 : 针对每个下游任务,只调输入文本前面的一些 tokens (soft prompt)。另外,这篇文章还提出了 Prompt Ensembling。
method: 总体上 Prompt Tuning 与 P-Tuning ( P-tuning-GPT Understands, Too) 较为相似。但 Prompt Tuning 的 prompt 参数全部置于左侧,并且论文将注意力集中在了冻结模型权重的一系列实验上,更好的验证了 prompt 的效果。初始化prompt: sampled vocab:从 5000 个 T5 字典最常用的 token 中提取。
class label:从任务 label 对应的 token 中提取。由于任务 label 通常数量较少,当任务 label 不够满足 prompt 参数长度时,使用 sampled vocab 进行填充。当一个 label 存在 multi-token 时,取其平均值。简单的 ensemble 能提升 prompt-tuning 的效果。
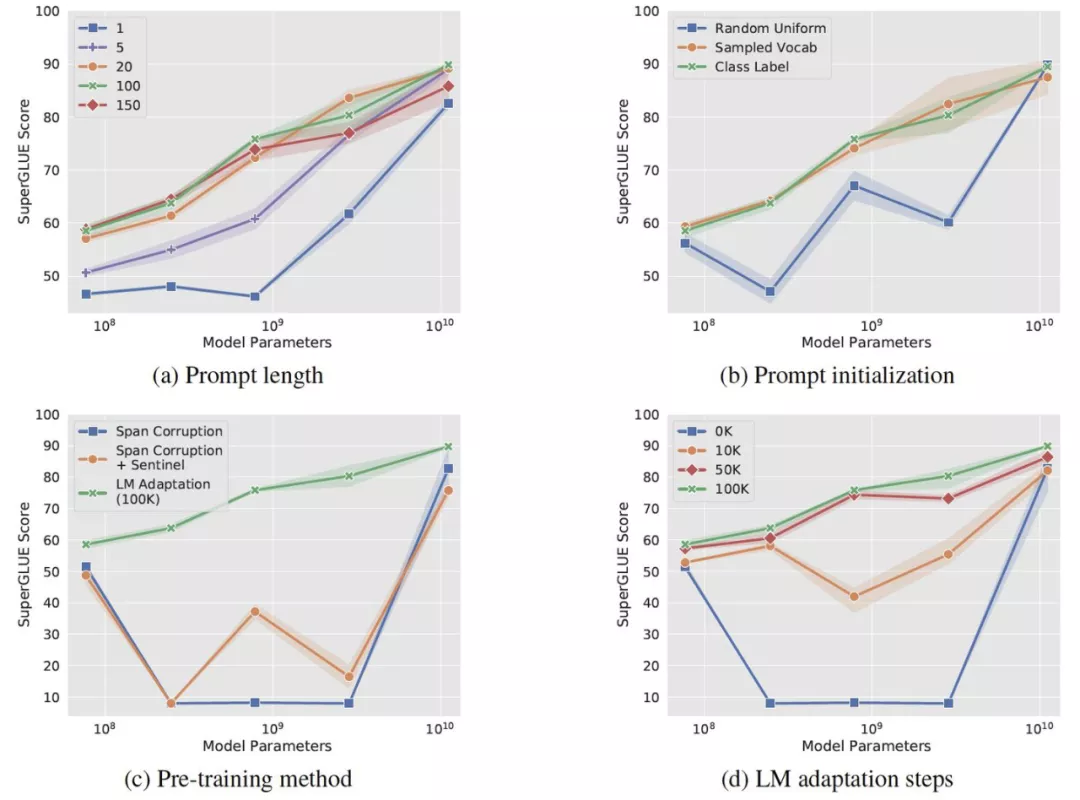
Multimodal Few-Shot Learning with Frozen Language Model -2021.7.3
motivation: 如何使用冻结参数的语言模型进行多模态任务
method: 冻结 LM 参数,只调输出以及视觉的 Vision Encoder(图中粉色部分)。LM 使用的是自回归的语言模型。视觉编码器基于 NF-ResNet-50,但是在视觉编码器之上套了一层线性映射,让其变成 Vision Prefix,类似于 Prefix Tuning [1] 的 Prefix (不过这里的 Prefix 是可以训练的)。这样,Image 就可以转变成 LM 可以理解的形式。
Knowledgeable Prompt-tuning: Incorporating Knowledge into Prompt Verbalizer for Text Classification (2021.8.4)
- motivation: 对标签词进行扩展,相当于引入外部知识。
Finetuned Language Models Are Zero-Shot Learners -2021.9.3
motivation: 简称FLAN, 另称 : Instruction Tuning。改善语言模型的 zero-shot 学习的能力。
method:作者先收集整理了一系列任务集合(task cluster),每个任务集合包含若干特定的数据集,有 NLU,也有 NLG,之后的 instruction tuning 就是在若干 task clusters 上训练的。tuning 方法有点像 GPT-3 的那种 prompting, 但是又有区别:
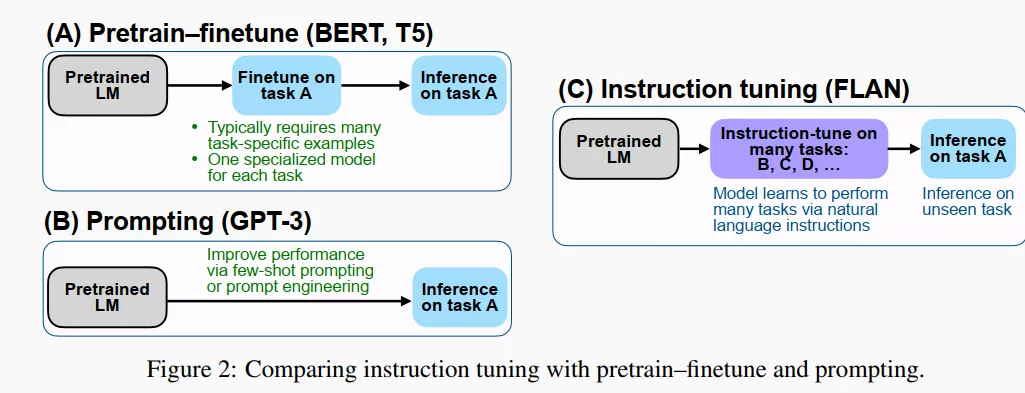
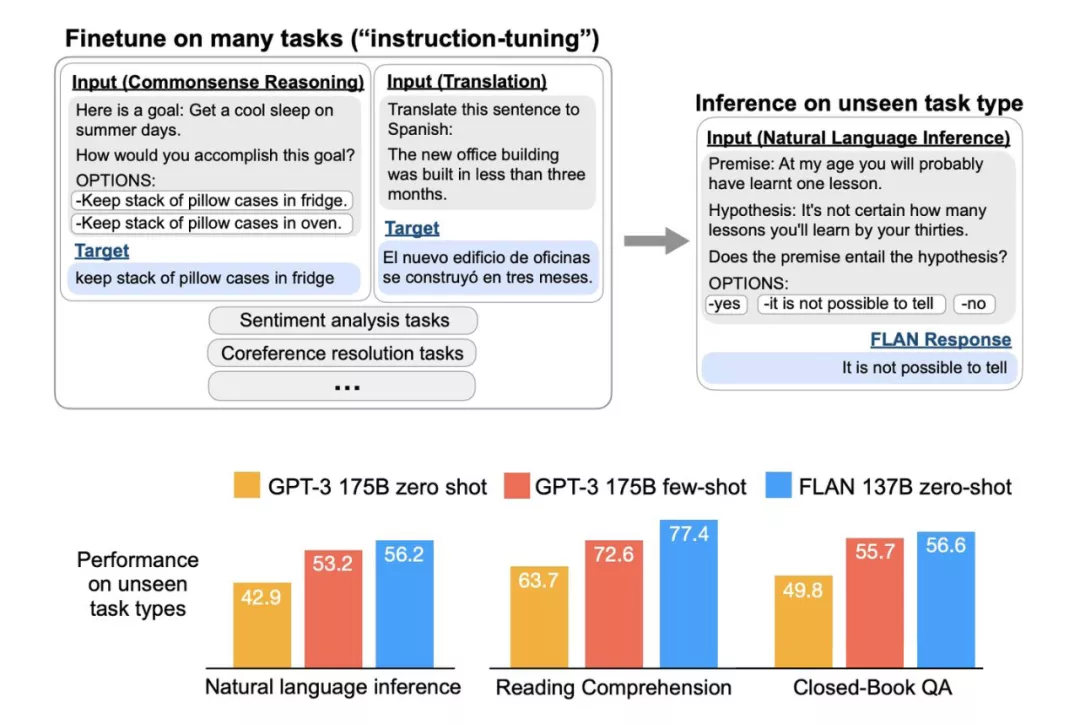
众所周知,GPT-3 不做进一步地精调,只是在 inference 时候,在开头提供一些 examples (instructions) 和 prompt,称作 in-context learning;但是这篇工作是要做精调的,把类似的 instruction 作为 tuning 时候的训练数据。
GPT-3 是单任务的,而这篇工作在 tuning 阶段使用多任务,每个任务都人工设计了一个 instruction template,把 template 填充之后就变成了 tuning 时候用的训练 examples。tuning 完成之后,把模型用于全新的 (unseen) 任务进行 inference, 这一次,不用 instructions (GPT-3), 就能达到很好的效果。
PPT: Pre-trained Prompt Tuning for Few-shot Learning -2021.9.9
- motivation: 通过预训练将 prompt tuning 用于下游任务,提供好的初始化 prompt,使得效果更稳定
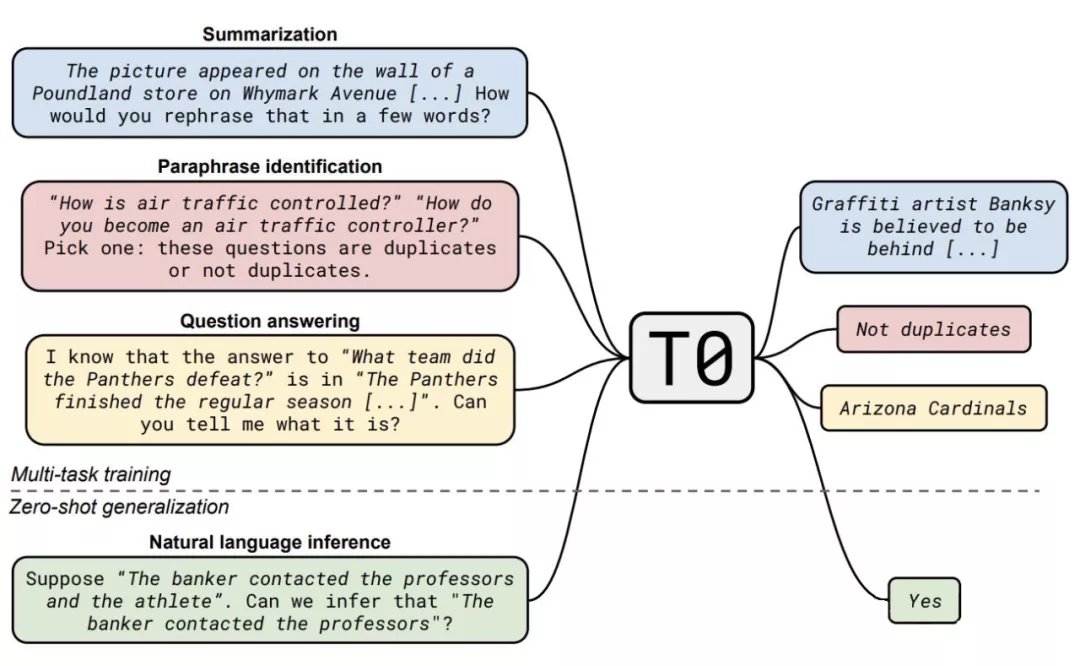
Multitask Prompted Training Enables Zero-Shot Task Generalization (EMNLP 2021) -2021.9.15
motivation: 大模型具有很好的零样本泛化能力 (zero-shot generalization),这取决于它隐式的多任务学习机制(也就是 GPT-3 的那种外循环机制)。那么能不能通过显式的多任务学习机制 (即带有 prompt engineering) 来激发大模型的零样本泛化能力呢?
粗暴、协作:多任务数据集达 171 个,Prompt 达 1939 个,模型也是超大的(T5, 11B)。和 FLAN 工作整体相似,区别是增加了任务和 prompt 数量,减小了模型参数,效果超过 FLAN,证明了多任务 prompt 学习能使模型更加鲁棒、泛化能力更强。
P-Tuning v2: Prompt Tuning Can Be Comparable to Finetuning Universally Across Scales and Tasks -2021.10.14
motivation: 之前的 soft prompt (google) 和 P-tuning 只对大模型有效,而且也仅仅用于解决一些简单的 NLU 任务。因此这个工作主要是扩展之前的 P-Tuning:适配小模型,适配复杂的 NLU 任务 (如序列标注等)。
method: 其实比起 P-tuning 或者 Google 的 soft prompt 的方式,这个更类似于 prefix tuning, 即和 prefix prompt 相关联的一系列层都能调。
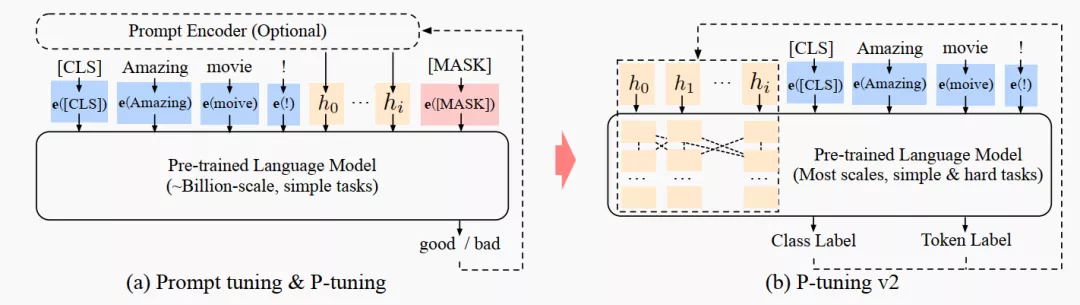
另外几点考虑是:
去掉了重参数化:比如 prefix tuning [1] 中的 MLP 以及 P-tuning 中的 LSTM,都不要了,因为这东西对效果提升不大。
多任务学习:这个挺有必要的,一方面可以减小 prompt 随机初始化的压力,另一方面可以更好地搞到跨任务/数据集的知识。
不用 verbalizer 了 : 其实对于复杂的 NLU 任务来说,verbalizer 的设计很不直观,那么就返璞归真,沿用原始的 [CLS]/token (hidden state) + MLP 就好。
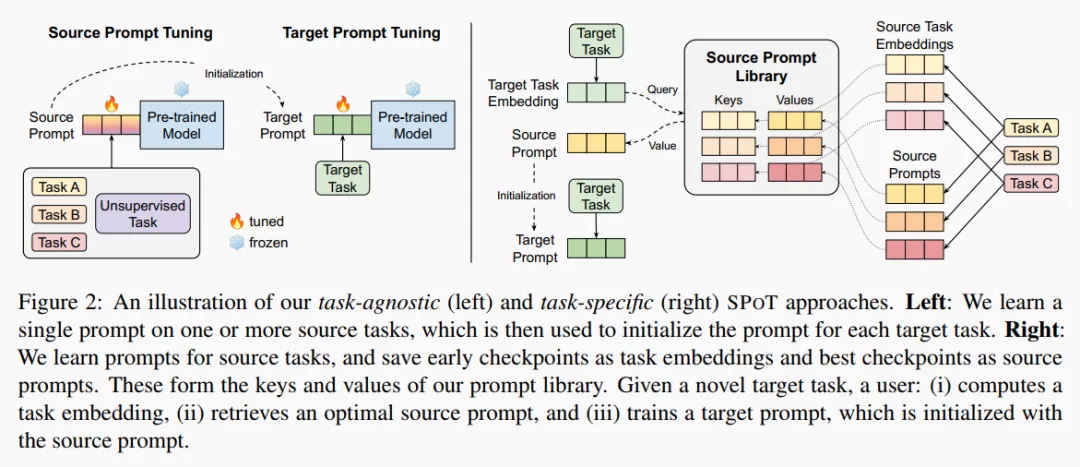
SPoT: Better Frozen Model Adaptation through Soft Prompt Transfer -2021.10.15
motivation: 还是为了增强模型在不同任务上的泛化性能,不过是基于 Prompt Tuning。换句话说:Transfer Learning + Prompt Tuning.
method: Task-Agnostic Approach : 先使用 multi-task training 得到一个 soft prompt, 用其作为目标任务的初始化。Task-Specific Approach : 为了进一步提高效率,作者做了一个 prompt library. 先在一系列源任务上进行学习,取早期的 embedding 作为键,相应的最优 soft prompt 作为值。当我们需要解决目标任务时,把目标任务的早期 embedding 作为 query,与库中的键计算余弦相似度,从而检索到相应的值 (soft prompt) 作为初始化,再对 target prompt 进行进一步的优化。
ZeroPrompt: Scaling Prompt-Based Pretraining to 1,000 Tasks Improves Zero-Shot Generalization -2022 1.18
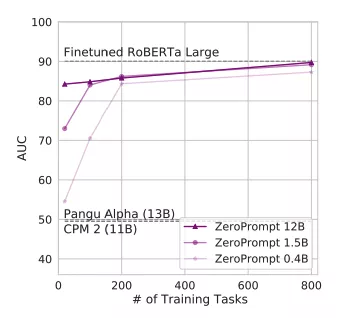
motivation : 继FLAN和T0之后,ZeroPrompt[9]实现了大规模多任务学习在中文领域“零的突破”。ZeroPrompt来自于XLNet作者杨植麟团队,共收集了1000个中文任务数据,整个测试任务上平均只相差4.7个点,而在部分测试任务上Zero-shot性能比有监督fine tuning还要好。
ZeroPrompt虽然数据规模庞大,但也证明一点:任务数据规模的拓展是模型缩放的一种有效替代手段,任务数量极大的情况下,模型大小对性能的影响很小。正如下图所示:随着多任务训练任务的增加,不同大小模型之间的Zero-shot性能趋近一致。
 wechat
wechat alipay
alipay


